亚马逊AWS官方博客
750B MoE 模型从自建 RoCE 集群迁移至 AWS EFA:Prefill-Decode 分离推理的通信架构验证
摘要:客户在自建机房使用基于 ConnectX 系列网卡的 RoCE 集群运行 GLM-5.1-FP8(750B MoE)模型推理服务,采用 Prefill-Decode (PD) 分离架构:2 台 Prefill 节点 + 2 台 Decode 节点,每台 8×H200 GPU。期望利用 AWS 弹性算力扩展本地 GPU 计算资源,同时获得更快的硬件迭代能力,从而降低硬件采购和折旧风险。AWS EFA 能否在这种极端复杂的通信负载下,达到 ConnectX 系列 + RoCE 方案的性能水平?我们基于客户的实际部署需求进行了完整的理论分析和实际验证
目录
1. 引言
在 AWS P5en (H200 + EFA) 上部署 GLM-5.1 2P2D 分离推理,与客户自建 RoCE 集群进行端到端性能对比。
2. 背景与动机
2.1 客户现状
客户在自建机房使用基于 ConnectX 系列网卡的 RoCE 集群运行 GLM-5.1-FP8(750B MoE)模型推理服务,采用 Prefill-Decode (PD) 分离架构:2 台 Prefill 节点 + 2 台 Decode 节点,每台 8×H200 GPU。
网络方案对比
| 客户自建机房 | AWS 云上 | |
| NIC 硬件 | ConnectX 系列 (NVIDIA/Mellanox) | EFA (AWS Nitro 自研网卡) |
| 协议 | RoCE v2 (RDMA over Ethernet) | SRD (Scalable Reliable Datagram) |
业务诉求:利用 AWS 弹性算力扩展本地 GPU 计算资源,同时获得更快的硬件迭代能力,从而降低硬件采购和折旧风险。
2.2 迁移挑战
这不是一个简单的”换个环境跑起来”的迁移。PD 分离架构对跨节点网络(EFA)的要求远超传统推理:
- 传统单机推理:所有 GPU 通信走 NVLink,不涉及跨节点网络
- 2P2D 分离推理:跨节点通信成为关键路径——PP 激活传递、MoE All-to-All dispatch/combine、KV Cache RDMA 写入,三种不同特性的流量同时考验 EFA
核心问题:AWS EFA 能否在这种极端复杂的通信负载下,达到 ConnectX 系列 + RoCE 方案的性能水平?
2.3 验证策略
我们基于客户的实际部署需求来验证:
- 推理框架:SGLang(UC Berkeley / LMSYS 开发,原生支持 PD 分离,集成 DeepEP、EAGLE 等关键组件,客户生产环境同样使用)
- 模型:GLM-5.1-FP8,750B 参数,256 Expert MoE,top-k=8
- 输入:120K tokens(长文本,Prefill 和 KV Cache 传输压力最大)
- 架构:2P2D(4 台 P5en.48xlarge,每台 8×H200 + 16×EFA)
- 对比基准:客户生产环境的实际性能数据
3. 物理网络环境
PD 分离推理的性能高度依赖跨节点通信延迟。在讨论通信架构之前,需要先理解底层的物理网络条件:单台实例内部的总线拓扑决定了节点内通信能力,实例间的网络位置决定了跨节点通信的物理距离,而容量获取方式决定了能否保证理想的网络拓扑。
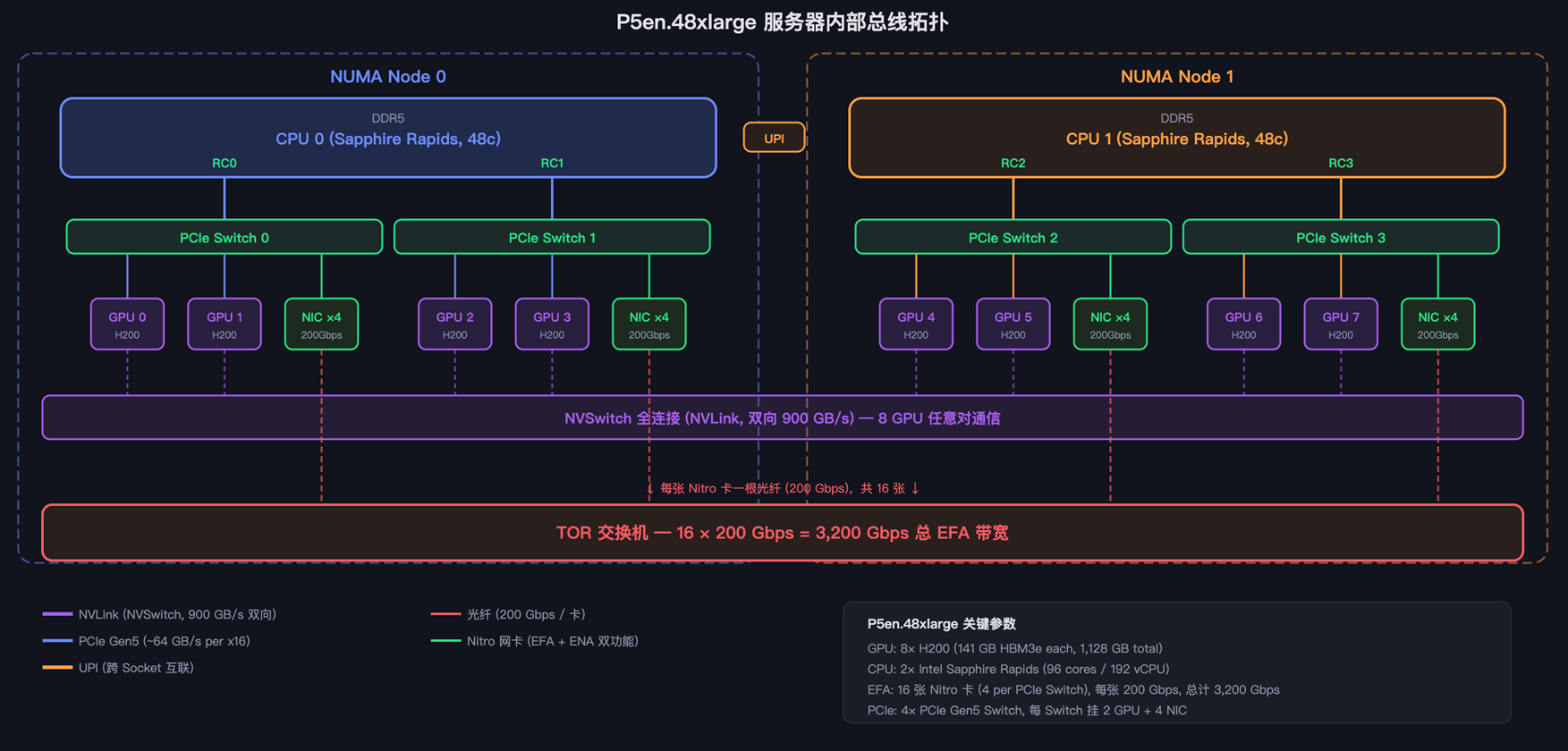
3.1 节点内硬件拓扑
要评估 EFA 能否替代 RoCE,首先需要了解 P5en.48xlarge 内部的硬件互联结构——它决定了哪些通信走高速 NVLink,哪些必须经过 EFA 出节点。
每台 P5en.48xlarge 配备:
- 8× NVIDIA H200 GPU(NVSwitch 全连接,节点内双向 900 GB/s)
- 16× Nitro 网卡(每张 200 Gbps,总带宽 3200 Gbps)
- 双路 Intel Sapphire Rapids(96 核 / 192 vCPU)
[图1] |
GPU 间通信路径
| 场景 | 物理路径 | 带宽 |
| 同节点 GPU↔GPU | NVSwitch 直连(全连接拓扑,任意对) | 双向 900 GB/s |
| 跨节点 GPU↔GPU | GPU → PCIe → Nitro NIC → TOR → 对端 Nitro → PCIe → GPU | 16×200 Gbps = 3,200 Gbps(总出口) |
同节点内 8 张 GPU 通过 NVSwitch 实现全连接,任意两张 GPU 之间无需经过 CPU 或 PCIe,延迟最低。跨节点通信则必须经过 PCIe 总线到 Nitro 网卡,走 EFA SRD 协议穿越 TOR 交换机到达对端节点。
3.2 节点间网络拓扑
跨节点通信性能不仅取决于单台实例的 EFA 带宽,还取决于多台实例之间的物理网络距离。我们需要验证测试集群的实际拓扑。
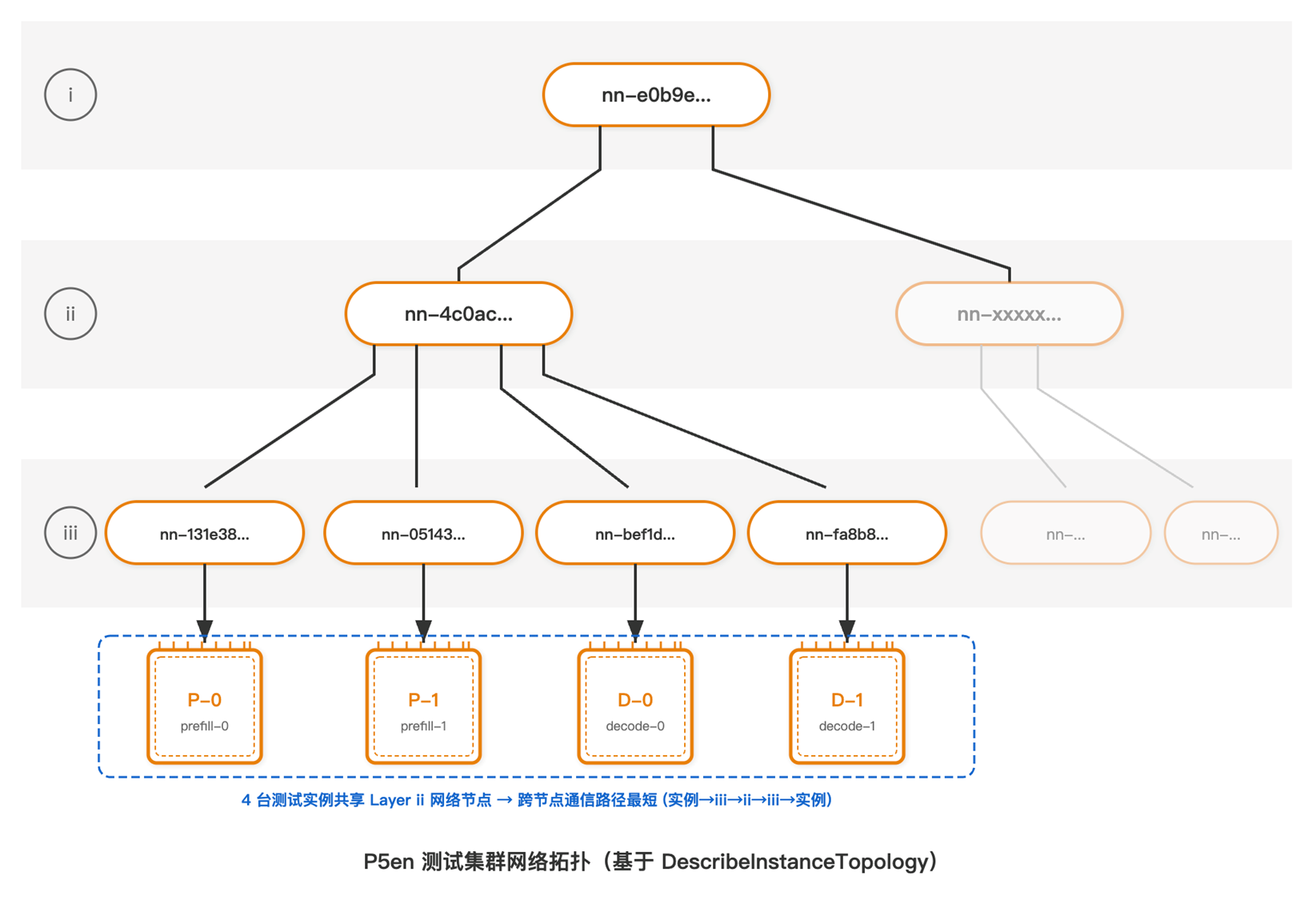
AWS 提供 DescribeInstanceTopology API 返回每台实例的 NetworkNodes 列表,自上而下地总览网络层次结构,底层节点会连接到实例。
判断实例间物理距离的规则:从底层(数组最后一个元素)开始向上比较,两台实例共享的最底层网络节点越深,物理距离越近。——AWS 官方文档
本次测试集群(eu-south-2a)4 台 P5en.48xlarge 的拓扑数据:
| 节点名称 | IP | Layer i (顶层) | Layer ii (中间) | Layer iii (底层,直连实例) |
| prefill-0 | 6.166.xxx.245 | nn-e0b9exxxbdd8d80 | nn-4c0acxxx606bbca1 | nn-131e3xxx6df4f93 |
| prefill-1 | 6.166.xxx.226 | nn-e0b9exxxbdd8d80 | nn-4c0acxxx606bbca1 | nn-05143xxx952561b76 |
| decode-0 | 6.166.xxx.15 | nn-e0b9exxxbdd8d80 | nn-4c0acxxx606bbca1 | nn-bef1dxxx8007f1c3 |
| decode-1 | 6.166.xxx.241 | nn-e0b9exxxbdd8d80 | nn-4c0acxxx606bbca1 | nn-fa8b8xxx166b592e |
根据如上的拓扑数据我们可以得到如下清晰的网络拓扑结构:
[图2] |
拓扑解读
- Layer iii(底层):每台实例各不相同——多台 P5en.48xlarge 很难被分配到同一个底层网络节点
- Layer ii(nn-4c0ac…):4 台实例全部相同——共享同一个中间层网络节点,跨节点通信路径为 实例→Layer iii→Layer ii→Layer iii→实例,仅经过 3 个网络节点
- Layer i(nn-e0b9e…):4 台实例全部相同——同属一个顶层域
这是 4 台 P5en 能获得的优化拓扑配置:虽然底层节点各异(大实例无法共享底层节点),但共享 Layer ii 意味着 P↔D 的 KV Cache RDMA 传输和 Decode 跨节点 MoE All-to-All 通信均走最短路径,不会上升到 Layer i 产生额外跳数。
3.3 如何在申请时获得优化拓扑
3.2 节验证了测试集群的实际拓扑是优化的,但这个结果是如何保证的?在生产环境中,我们不能依赖运气来获得好的拓扑配置。AWS 提供了 Cluster Placement Group (CPG) 和两种容量预留机制来解决这个问题。
3.3.1 Cluster Placement Group (CPG)
AWS 通过 Cluster Placement Group 提供拓扑保证:
“Instances in the same cluster placement group enjoy a higher per-flow throughput limit for TCP/IP traffic and are placed in the same high-bisection bandwidth segment of the network.”— AWS Documentation
CPG 保证同组实例放置在同一高二分带宽网段内。但需注意:CPG 不保证同一机架(文档明确说 “Instances are not isolated to a single rack”)。结合 2.2 节的拓扑数据,CPG 的保证本质上对应”共享 Layer ii 网络节点”。
3.3.2 GPU 实例的两种容量获取方式
GPU 实例资源紧张,裸启动经常遇到 InsufficientCapacity。生产环境通常通过以下两种方式锁定容量:
| On-Demand Capacity Reservation (ODCR) | Capacity Block for ML | |
| 本质 | 立即生效的容量预留,持续占用直到取消 | 按时间段预约的 GPU 专属容量(最远 8 周后) |
| 计费 | 创建即开始按 On-Demand 价格计费(不论是否跑实例) | 仅在预约时间段内计费,提前锁定价格 |
| 取消 | 随时可取消 | 不可取消 |
| 适用场景 | 长期稳定需求、需要灵活扩缩容 | 短期 ML 任务(训练、测试),按天/周预约 |
3.3.3 两种容量获取方式与拓扑保证
| ODCR | Capacity Block | |
| 拓扑邻近方式 | 用户主动指定 CPG → 保证 high-bisection bandwidth segment | 无需指定 CPG——实例自动放入 UltraCluster,邻近性由 AWS 保证 |
| 网络保证 | high-bisection bandwidth segment(同高二分带宽网段) | low-latency、petabit-scale、non-blocking networking(官方原文) |
| 容量不足时 | create-capacity-reservation 返回 InsufficientCapacity 错误 | describe-capacity-block-offerings 返回空列表(无可用 offering) |
| 保证强度 | 定性承诺(同一高二分带宽网段),无量化数字 | 定性承诺(”placed close together inside UltraClusters”),无量化数字 |
本次测试使用的是 Capacity Block,4 台 P5en 被分配到同一 Layer ii 网络节点下,验证了 Capacity Block 的实际放置效果满足 2P2D 分离推理的通信需求。
在实际使用时,如果申请数量较多,难以同时满足数量和 CPG 拓扑约束,则可以先获取容量,再通过 DescribeInstanceTopology API 查询各实例的网络位置,对有跨节点通信需求的工作负载选择距离更近(共享更底层网络节点)的实例进行模型部署。
4. PD 分离架构与模型切分
4.1 为什么需要 Prefill-Decode 分离
大语言模型处理一次请求分为两个阶段:Prefill(预填充) 阶段一次性读入用户输入的所有 token,理解上下文;Decode(解码) 阶段逐个生成回答的 token,直到结束。这两个阶段对 GPU 的使用方式截然不同:
- Prefill 是计算密集型。
- 一次处理成千上万个 token(GLM-5.1 支持 200K context),GPU 的算力被充分利用。类比:一次性读完一整道题,然后集中思考。因此衡量 Prefill 效率使用 TTFT(Time To First Token)——从收到请求到输出第一个 token 的耗时,反映模型”理解输入”的速度。
- Decode 是访存密集型。
- 每次只生成 1 个 token,却需要加载整个模型的权重做一次完整 forward。GPU 大部分时间在等数据从显存搬到计算单元,算力严重空转。类比:一字一字写答案,每写一个字都要翻一遍全部笔记。因此衡量 Decode 效率使用 TPOT(Time Per Output Token)——生成每个 token 的平均耗时,反映模型”输出回答”的速度。
小模型两个阶段可以在同一组 GPU 上分时复用;但对 GLM-5.1 这种 750B MoE,混合部署的代价远大于收益,必须物理分离。原因有三:
1. 相互干扰:两阶段延迟目标相反(Prefill 优化 TTFT、Decode 优化 TPOT),混跑必然互相拖累——长文本 Prefill 阻塞 Decode 造成 TPOT 尖峰,反之又恶化 TTFT。
2. 可独立优化:分离后各自取最优配置——Prefill 用大 TP 压低计算延迟,Decode 用大 batch 提高显存带宽利用率。
3. Expert 放置物理冲突(MoE 特有,也是最关键的):Prefill 要 Expert 集中节点内(EP=8,走 NVLink 不出节点);Decode 要 Expert 分散到跨节点 16 卡(EP=16),腾显存给 dp-attention。集中 vs 分散,同一组 GPU 无法兼顾——这是物理冲突,不是调度能解决的。
分离的代价只有一次 KV Cache 跨节点传输,但收益远超于此。
下面的表格总结了两个阶段分离后各自的优化配置:
| 特征 | Prefill(预填充) | Decode(解码) |
| 计算模式 | 大批量 token 并行计算 | 逐 token 自回归生成 |
| GPU 利用率 | 高(计算密集) | 低(访存密集) |
| 延迟指标 | TTFT(首 token 延迟) | TPOT(每 token 延迟) |
| 优化的 Expert 布局 | 集中在节点内(EP=8,每卡 32 Expert) | 分散到多节点(EP=16,每卡 16 Expert) |
| 优化的 Attention 策略 | CP=8 切序列(复制权重,all-gather/reduce-scatter) | 复制完整权重,dp-attention 无通信 |
| 瓶颈 | 算力 | 显存带宽 + 网络延迟 |
4.2 整体部署架构与请求流转
PD 分离部署后,Prefill 和 Decode 各自是独立的推理进程,对外暴露不同端口。用户请求需要一个统一入口来协调两者——这就是 Router 的作用。Router 是 SGLang 提供的轻量路由组件(纯 CPU,不持有模型),负责:
- 接收用户请求,转发给 Prefill 集群处理输入
- 协调 KV Cache 从 Prefill 传输到 Decode(通过 bootstrap port)
- 将 Decode 生成的 token 流式返回给用户
4.2.1 Router 启动参数
–pd-disaggregation 启用 PD 分离模式,–mini-lb 使用轻量负载均衡策略。5555 是 Prefill 的 bootstrap port,用于 Prefill 和 Decode 之间协商 KV Cache RDMA 传输地址。
4.2.2 性能测试命令
测试使用 120K input + 1K output 的长文本场景,1024 个请求以 0.4 req/s 的恒定速率发送。在该速率下实际并发约 10~30 个请求,Prefill 和 Decode 均处于持续满载状态。
4.2.3 一次 120K 请求的完整流转
- Router 接收请求 → 转发给 Prefill 集群
- Prefill 处理(PP=2, Attention CP=8, MoE EP=8):2 节点协作,节点内 NVLink 完成 Attention 的 all-gather/reduce-scatter 和 MoE All-to-All,节点间仅 PP 传递中间激活值
- KV Cache 传输:Prefill 生成的 KV Cache 通过 Mooncake Transfer Engine / nixl(底层走 libfabric → EFA RDMA)直接写入 Decode 节点的显存,bypass 整个 K8s 网络栈
- Decode 生成(DP=16, EP=16):每张 GPU 独立处理 Attention(dp-attention),MoE 层通过跨节点 All-to-All 路由 token 到 Expert,逐 token 生成回答
- 流式返回 → 用户感知到每个 token 的输出
下面分别展开 Prefill 和 Decode 各自的切分配置。
4.3 实验中的 Prefill 切分方式与解读
本次实验使用的 Prefill 启动参数如下:
关键参数说明:
| 参数 | 值 | 含义 |
| –tp-size 8 | 8 | 本应是 Attention 的张量并行度(切 head);但因开启了 –enable-nsa-prefill-context-parallel,Attention 改为按序列切分(CP),tp-size 不再是”切 head 的并行度”,退化为”一个 PP stage 内的总卡数”。这 8 卡被分流为 Attention CP=8(切序列)+ MoE EP=8(切专家) |
| –pp-size 2 | 2 | 78 层平分,Stage 0 持有 Layer 0-38,Stage 1 持有 Layer 39-77 |
| –dp-size 1 | 1 | 不做数据并行,所有 GPU 协作处理同一批请求 |
| –moe-dense-tp-size 1 | 1 | Dense 层(前 3 层)的 FFN 不做 TP 切分,每 GPU 完整复制(注意:不控制 MoE 层的 shared expert——后者由 DeepEP 后端单独决定) |
| –deepep-mode normal | normal | DeepEP 吞吐优先模式(大 batch、高带宽利用) |
| –chunked-prefill-size 16384 | 16384 | 长序列按 16K token 分块处理,控制显存峰值 |
| –disaggregation-transfer-backend mooncake | mooncake | 使用 Mooncake Transfer Engine 做 KV Cache 跨节点 RDMA 传输 |
| –attention-backend nsa | nsa | Native Sparse Attention(模型架构决定) |
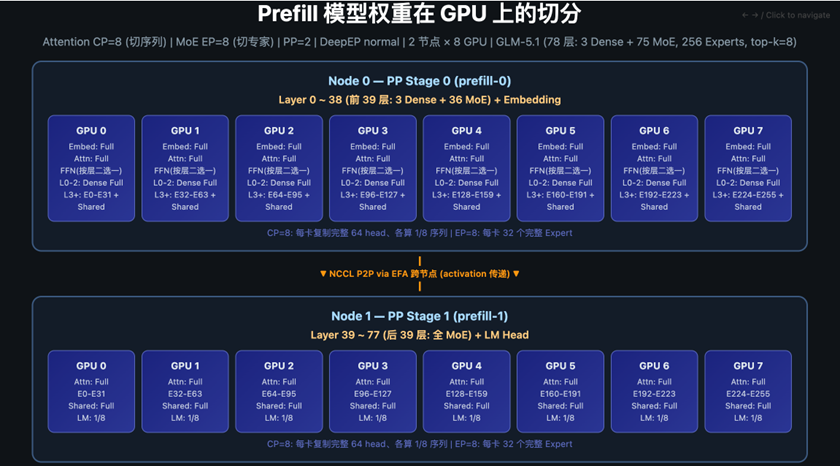
对应的模型切分如下图所示(PP=2, Attention CP=8, MoE EP=8, 2 节点 × 8 GPU):
[图3] |
4.3.1 一个 120K 请求在 Prefill 内部的处理过程
120K token 的输入不会一次性全部计算,而是按 chunked-prefill-size=16384 切分为约 8 个 chunk(每 chunk 16K token),逐 chunk 送入 Pipeline。以一个 chunk 在单个 Stage 内的处理流程为例:
1. Attention 层(CP=8,切序列)
本次 Prefill 开启了 –enable-nsa-prefill-context-parallel,Attention 走 Context Parallel(上下文并行)而非切 head 的 TP:每张 GPU 复制完整的 64 个 attention head 权重,但只负责其中 1/8 的 token——16K token 按序列被切成 8 份(逐 token 交错分配,均衡 causal 负载),每卡算 2K 个 token 的 attention。由于每个 token 要看到前面所有 token 的 K/V,8 张卡通过 all-gather / reduce-scatter(NVLink,节点内)沿序列维交换 K/V,而不是切 head 后做 AllReduce。
为什么长上下文 Prefill 用 CP 而非 TP:120K 长输入下,显存与计算的瓶颈在”序列长度”维(KV、激活、attention 计算量都随序列增长),而切 head 不分摊序列维;加上 GLM-5.1 的 MLA 把 KV 压成共享 latent、没有”按 head 切”的切面,切 head 也省不了 KV。所以改用切序列(CP),让每卡只扛 1/8 的 token。
2. MoE 层(Sparse,EP=8)
经过 CP 的 attention 后,每张 GPU 手里是自己负责的那 2K 个 token 的 hidden state(CP 已按序列把 16K token 分到 8 卡,每卡 2K,数据本就在本地,无需再搬运)。这 2K token 直接进入本卡的 MoE routing:
-
-
- 每卡对自己认领的 2K token 计算 Router Gate → 每个 token 选出 top-8 Expert ID
- All-to-All Dispatch:每卡根据路由结果,将 token 的 hidden state 发送到对应 Expert 所在的 GPU。由于每 token 路由到 8 个 Expert,每卡实际发出 2K × 8 = 16K 份 token 数据,分散到 8 张 GPU。注意接收端不是均分的——哪个 GPU 的 Expert 被选中更多,就收到更多 token(这也是 DeepEP normal 模式需要先统计 recv 数量再动态分配 buffer 的原因)
- 每张 GPU 上的 32 个 Expert 对收到的 token 执行 FFN 计算
- All-to-All Combine:计算结果返回给原始发送端的 GPU,加权求和
-
整个 All-to-All 过程全部在节点内 8 张 GPU 之间完成(NVLink),不出节点。
通信模式对比: AllReduce 是集合通信——8 张卡通过 Ring 或 Tree 算法协同传输,每卡发送量对称、目标固定。All-to-All Dispatch 是点对点路由——每卡根据路由结果向不同 GPU 发送不等量数据,通信模式非对称且消息大小不均匀,无法用 Ring 算法优化。All-to-All 的这种非对称路由和小消息特性使得 DeepEP 的 GPU-initiated 通信比 NCCL 的通用 All-to-All 实现更高效,这也是 MoE 通信使用专门的 DeepEP 库的原因。
3. Shared Expert(复制,无通信)
每张 GPU 各自对自己负责的 token 独立计算 Shared Expert FFN,结果与 MoE 输出相加。
4. PP 跨节点传递
一个 chunk 经过 Stage 0 的 39 层(每层重复上述 Attention + MoE 计算)后,生成的中间激活值通过 NCCL send/recv(aws-ofi-nccl → EFA)跨节点发送到 Stage 1 的对应 GPU。
5. Pipeline 并行
关键优势:120K 输入的所有 token 一开始就全部已知。Stage 0 处理完 chunk 1 发给 Stage 1 后,立刻开始处理 chunk 2——两个 Stage 几乎完全重叠工作,Pipeline 利用率接近 100%。
通信总结: Prefill 的所有高频通信(Attention 的 all-gather/reduce-scatter + MoE All-to-All)都在节点内完成(NVLink)。唯一的跨节点通信是 PP 层间激活传递——每个 chunk 仅一次 send/recv,数据量为一个中间层的 hidden state(16K token × 6144 hidden_dim × 2 Bytes ≈ 200 MB;权重虽用 FP8 量化,但层间激活值保持 BF16 精度以避免误差累积,故按 2 Bytes 计),频率低、对延迟不敏感。
4.4 实验中的 Decode 切分方式与解读
Prefill 的通信全部封闭在节点内 NVLink 完成,EFA 仅承担低频的 PP 传递。Decode 则完全不同——在本次 2P2D 配置下,Decode 横跨 2 个节点(EP=16,每卡 16 个 Expert),其核心通信(MoE All-to-All)必须跨节点走 EFA,且频率极高,是本次 EFA 迁移中真正的挑战所在。
在 Decode 开始逐 token 生成之前,它首先需要接收 Prefill 阶段产生的 KV Cache。Prefill 完成后,通过 Mooncake Transfer Engine(底层走 libfabric → EFA RDMA)将 KV Cache 直接写入 Decode 节点的 GPU 显存。KV Cache 就绪后,Decode 才开始自回归生成。
本次实验使用的 Decode 启动参数如下:
关键参数说明:
| 参数 | 值 | 含义 |
| –tp-size 16 | 16 | 张量并行度;启用 deepep 后端时 SGLang 将 EP 对齐为 tp_size(→ EP=16,每卡 16 个 Expert) |
| –dp-size 16 | 16 | 16 路数据并行,每 GPU 独立处理不同请求的 Decode |
| –enable-dp-attention | — | Attention 层走数据并行(每卡完整权重,消除 AllReduce) |
| –enable-dp-lm-head | — | LM Head 层也走数据并行,避免跨卡通信 |
| –deepep-mode low_latency | low_latency | DeepEP 低延迟模式(小 batch、延迟敏感) |
| –mem-fraction-static 0.74 | — | 静态分配给模型权重与 KV Cache 的显存占比(其余留给运行时开销) |
| –speculative-algorithm EAGLE | EAGLE | 投机解码:3 次 draft head forward + 1 次主模型 verify/cycle |
| –cuda-graph-max-bs 16 | 16 | CUDA Graph capture 的最大 batch size;batch ≤ 16 走预录的 Graph,超过则回退 eager(仍可运行,只是无 Graph 加速) |
| –max-running-requests 256 | 256 | 集群同时在飞的请求总数上限(16 GPU × 每卡 batch 约 16 个请求) |
TP/DP/EP 的关系说明: 本实验启用了 –moe-a2a-backend deepep,SGLang 在此模式下会自动将 Expert 并行度对齐到张量并行度(源码 server_args.py:self.ep_size = self.tp_size),因此 –tp-size 16 推导出 EP=16——256 个 Expert 均分到 16 张 GPU,每卡 16 个。同时 –dp-size 16 + –enable-dp-attention 使 Attention 层按 DP=16 运行:每张 GPU 持有完整 Attention 权重、独立处理各自请求,层内无跨卡通信。于是同一组 16 张 GPU 在 Attention 层是 DP 角色、在 MoE 层是 EP 角色,二者由 dp-attention 切换。
对应的模型切分如下图所示(TP=16, DP=16, EP=16, PP=1, 2 节点 × 8 GPU):

[图4] |
4.4.1 Decode 阶段的逐 token 生成过程
与 Prefill 一次性处理完整输入不同,Decode 每次只生成 1 个 token,然后将其追加到上下文中,再生成下一个 token。集群通过 dp-size=16 + continuous batching 同时处理多个请求——max-running-requests=256 意味着 16 张 GPU 各自同时处理约 16 个不同请求的 Decode。
以一个 token 的生成过程为例(每张 GPU 上约 16 个请求并行):
1. Attention 层(dp-attention,无通信)
每张 GPU 持有完整的 Attention 权重(–enable-dp-attention),独立处理自己负责的那批请求的 Attention 计算。16 张 GPU 之间完全不需要通信——这是与 Prefill 最大的区别。Prefill 与 Decode 的 attention 都复制完整权重,区别在”切什么”:Prefill 按序列切(CP=8,卡间要 all-gather/reduce-scatter 交换 K/V),而 Decode 按请求切(dp-attention,每卡独立处理各自请求、零通信)。
代价:每张 GPU 必须存储完整 Attention 权重(不切分)。
2. MoE 层(Sparse,EP=16 跨节点)
256 个 Expert 分布在 2 节点 × 8 GPU = 16 张卡上,每 GPU 持有 16 个 Expert。这是 Decode 通信复杂度的核心来源:
- 每张 GPU 对自己当前 batch(约 16 个请求的当前 token)计算 Router Gate → 每个 token 选出 top-8 Expert ID
- All-to-All Dispatch:每卡根据路由结果,将 token 的 hidden state 发送到对应 Expert 所在的 GPU。256 个 Expert 均匀分布在 2 节点 × 8 GPU 上,每个 token 路由到 8 个 Expert——目标 Expert 在同节点则走 NVLink,在另一节点则走 EFA。统计上约一半的 Expert 在对端节点,因此每次 All-to-All 都必然包含跨节点 EFA 通信(不像 Prefill 的 EP=8 可以全部在 NVLink 内完成)
- 16 张 GPU 上的 Expert 对收到的 token 执行 FFN 计算
- All-to-All Combine:计算结果沿原路返回——同节点走 NVLink,跨节点走 EFA
关键差异——频率与路径: 模型有 75 层 MoE,每层 2 次 All-to-All(Dispatch + Combine),因此每生成一个 token 就要 75 × 2 = 150 次跨节点通信。虽然每次通信的数据量很小(每 GPU 约 16 个 token 的 hidden state),但 150 次/token 的频率意味着对单次通信延迟极为敏感。这就是为什么 Decode 使用 –deepep-mode low_latency 而非 Prefill 的 normal 模式。同时,这也是跨节点 EFA 延迟对性能影响最大的场景——第 6.3 节将详细分析 IB IBGDA 与 EFA UCCL-EP 在此场景下的延迟差异。
3. DeepEP Low-Latency 模式
Prefill 的 normal 模式每卡处理 2K token,路由到 256 个 Expert 后分布不确定,必须先通信统计每张 GPU 实际会收到多少 token → CPU 介入为接收端分配对应大小的显存 buffer → 再执行实际数据传输。这套流程对 Prefill 没问题(大 batch 对延迟容忍度高),但 Decode 每卡 batch 很小、且每个 token 要经历 150 次 All-to-All,每次都等 CPU 介入是不可接受的。
low_latency 模式的核心思路:Decode 每卡的 token 数量极少,接收端 buffer 的上限是可预知的,因此可以跳过”先统计再分配”的步骤,按一个预设上限(SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK,本次设为 128)直接预分配固定 buffer。这带来三个好处:
- 无 CPU 同步:单个 CUDA kernel 完成整个 Dispatch/Combine,不需要 CPU 介入
- 兼容 CUDA Graph(–cuda-graph-max-bs 16):无 CPU 中断意味着整个 forward 的数百个 kernel 可以被 capture 并一次 replay,消除逐个 launch 的开销
- 预分配固定 buffer:用约 1 GB 显存换掉每次通信的动态统计延迟
通信总结: Decode 的唯一高频通信是 MoE All-to-All——每个 output token 触发 150 次跨节点 EFA 通信。单次数据量很小,但对延迟极度敏感。与 Prefill 形成鲜明对比:Prefill 的 All-to-All 走 NVLink(节点内),Decode 的 All-to-All 走 EFA(跨节点)。这正是本次 EFA 迁移中最具挑战的场景——IB RoCE 的 IBGDA 可在网卡侧完成 All-to-All 调度(GPU 直驱 NIC doorbell,零 CPU 参与),而 EFA 需要 UCCL-EP 在软件层通过 CPU Proxy 架构模拟类似行为(详见 6.3 节)。
5. 推理过程中的通信分解
PD 分离架构下,Prefill 和 Decode 的通信模式截然不同。下面按层类型分别列出两个阶段的通信机制。
5.1 Prefill 通信机制
| 层类型 | 并行方式 | 通信模式 | 通信库 | 物理路径 | 说明 |
| Attention (MLA) | CP=8 (切序列,每卡复制完整 head) | all-gather / reduce-scatter (沿序列) | — | NVLink (NVSwitch) | 8 GPU 节点内,双向 900 GB/s;非切 head 的 AllReduce |
| MoE Expert (Sparse) | EP=8 (切 expert 维度) | All-to-All × 2 (Dispatch + Combine) | UCCL-EP (normal) | NVLink (节点内) | EP=8 全在同一节点,走 NVLink,优化吞吐 |
| Shared Expert | 复制 (DeepEP 下每 EP rank 各一份) | 无 | — | — | 每 GPU 完整权重,无需通信 |
| PP Send/Recv | PP=2 (层平分) | Point-to-Point (activation 传递) | NCCL (aws-ofi-nccl) | EFA (跨节点) | Stage 0 → Stage 1,中间 activation |
| KV Cache 传输 | P → D (PD 分离) | RDMA Write | Mooncake TE / nixl | EFA (跨节点) | Prefill 完成后发送给 Decode 节点 |
5.2 Decode 通信机制
| 层类型 | 并行方式 | 通信模式 | 通信库 | 物理路径 | 说明 |
| Attention (Dense) | DP=16 (dp-attention,复制权重) | 无通信 | — | — | 每 GPU 完整权重,独立处理各自请求 |
| MoE Expert (Sparse) | EP=16 (切 expert 维度) | All-to-All × 2 (Dispatch + Combine) | UCCL-EP (low_latency) | NVLink + EFA | EP=16 跨 2 节点,高频小消息,延迟敏感 |
| Shared Expert | 复制 (DeepEP 下每 EP rank 各一份) | 无 | — | — | 每 GPU 完整权重,无需通信 |
| LM Head | DP (enable-dp-lm-head) | 无 | — | — | 每 GPU 完整权重,独立 sampling |
| KV Cache 接收 | D ← P (PD 分离) | RDMA Read | Mooncake TE / nixl | EFA (跨节点) | 从 Prefill 节点接收 KV Cache |
5.3 关键挑战
对比两张表可以看出:Prefill 的高频通信(Attention 的 all-gather/reduce-scatter + MoE All-to-All)全部走 NVLink,EFA 只承担低频的 PP 传递和一次性的 KV Cache 写入。而 Decode 的 dp-attention 消除了 Attention 通信后,唯一的高频通信就是 MoE All-to-All——每生成 1 个 token 需要 75 层 × 2 次 = 150 次跨节点通信。每次通信的消息很小,但对延迟极其敏感——这正是 ConnectX 系列 (IBGDA) 和 EFA 架构差异最显著的场景。
5.4 通信软件栈:各库的来源与适配关系
PD 分离推理涉及多个通信库协同工作,它们由不同团队开发,通过不同方式适配到 EFA 上:
| 通信库 | 开发者 | 定位 | 仓库 |
| NCCL | NVIDIA | GPU 集合通信标准库(AllReduce、Send/Recv) | github.com/NVIDIA/nccl |
| aws-ofi-nccl | AWS | NCCL → libfabric 的 API 翻译插件 | github.com/aws/aws-ofi-nccl |
| DeepEP | DeepSeek(深度求索) | MoE Expert Parallelism 专用 All-to-All 通信库 | github.com/deepseek-ai/DeepEP |
| UCCL-EP | UC Berkeley / UC Davis | DeepEP 的跨平台适配层——保留 DeepEP API,替换底层传输(支持 EFA、IB、Broadcom) | github.com/uccl-project/uccl |
| Mooncake | 月之暗面(Moonshot AI / Kimi) | PD 分离的 KV Cache 跨节点传输引擎 | github.com/kvcache-ai/Mooncake |
| NIXL | NVIDIA(Dynamo 项目) | 单边 RDMA KV Cache 传输抽象层 | github.com/ai-dynamo/nixl |
| libfabric | 开源社区(Intel 主导,OFIWG) | 跨厂商网络传输抽象库 | github.com/ofiwg/libfabric |
EFA 在用户态暴露两套接口,这些通信库分别走不同路径访问 EFA:NCCL(经 aws-ofi-nccl)、Mooncake、NIXL 走 libfabric,而 UCCL-EP 直接走 libibverbs,不经过 libfabric。两条路径最终在内核驱动 efa.ko 汇合,访问同一块 EFA 网卡。
概括来说:EFA 是 AWS 自研硬件,但它接入了现成的开源 RDMA 软件生态,而非另起炉灶。 生态里有两套通用 API(Verbs / libfabric),每套都用”通用接口 + 可插拔 provider”的设计来对接 EFA。延迟命门的 UCCL-EP 直接走最底层的 Verbs;要可移植、省事的 NCCL / Mooncake / NIXL 走 libfabric。两条路径在 rdma-core 汇合,向下经 efa.ko、EFA 网卡,底层都是 SRD 协议。
下图展示了完整的 EFA 通信软件栈分层,从上层应用到底层 SRD 协议的调用路径:
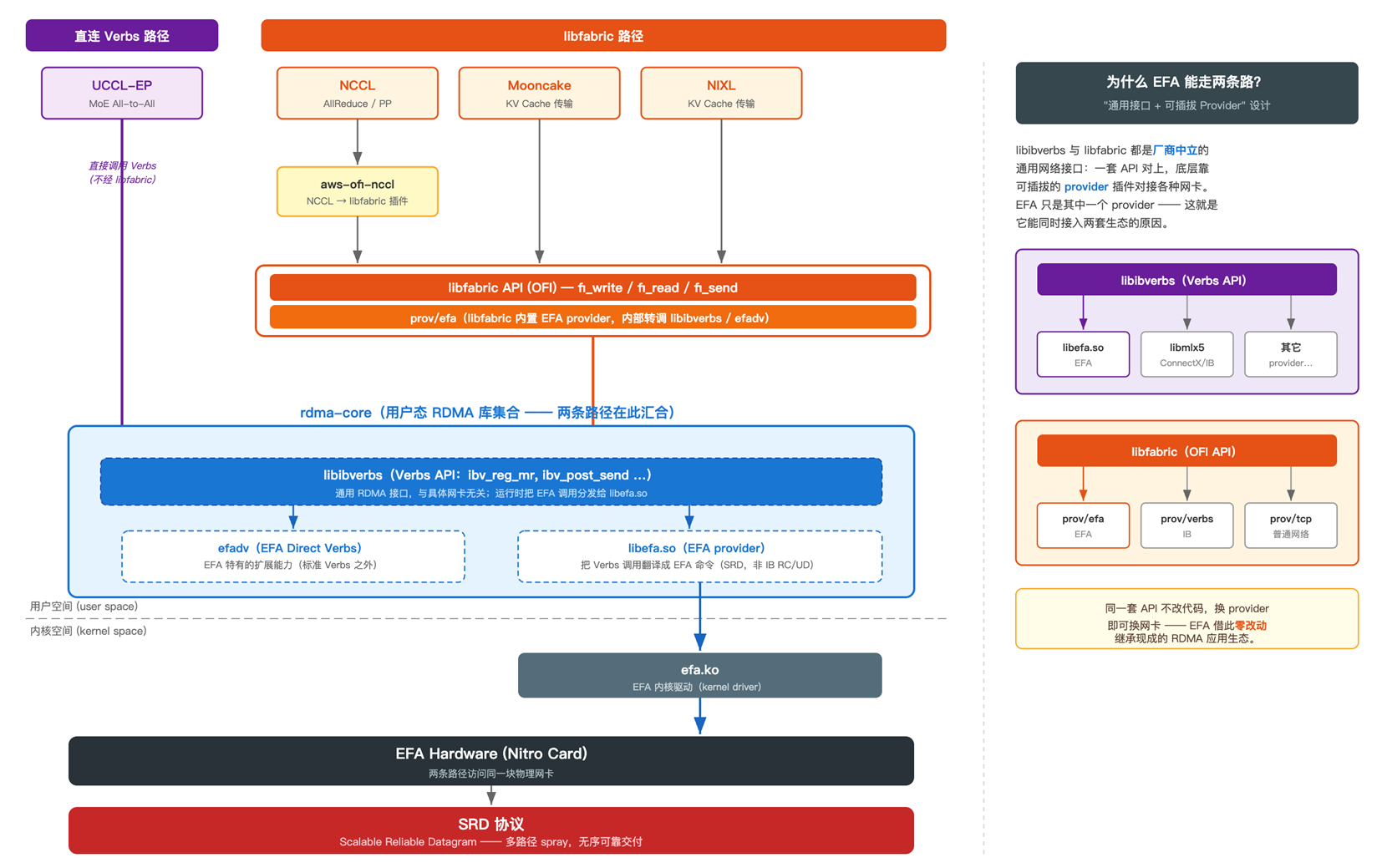
[图5] |
为什么会有两套通用接口? Verbs(libibverbs)源自 InfiniBand 时代,贴近硬件、控制力强,是 RDMA 的原生接口;libfabric 是后来 OFIWG 重新设计的更高层抽象,目标是用一套 API 罩住各种网络(RDMA、EFA、乃至普通 TCP),强调可移植与易用。两者并非取代关系——在 RDMA 网卡上,libfabric 的 provider 内部仍复用 Verbs,相当于在 Verbs 之上又包了一层更友好的门面。正因如此,对延迟极度敏感、需要精细控制发送队列的 UCCL-EP 直接走底层 Verbs,省去抽象层开销;而 NCCL、Mooncake、NIXL 看重跨硬件可移植和开发效率,走 libfabric 更划算。两条路最终都借助”可插拔 provider”机制对接 EFA——这正是 AWS 让自研网卡零改动接入现成 RDMA 生态的关键。
6. 性能实测:AWS EFA vs 客户自建 RoCE 集群
前面几章介绍了 PD 分离架构的通信需求和 EFA 软件栈的工作方式。本章直接给出端到端性能对比结果——在相同模型、相同架构、相同负载下,AWS EFA 与客户自建 ConnectX 系列 RoCE 集群的实际表现差异。
6.1 测试配置
| 参数 | 值 |
| 模型 | GLM-5.1-FP8 (78 层, 256 Expert, top-k=8, 750B) |
| 输入长度 | 120,000 tokens |
| 输出长度 | 1,000 tokens |
| 请求数 | 128 |
| Request Rate | AWS: 0.36 req/s / 客户: 0.4 req/s(对齐 TTFT) |
| 部署架构 | 2P2D (2 Prefill + 2 Decode, 各 2 节点 × 8 H200 GPU) |
| KV Cache 传输 | Mooncake Transfer Engine over EFA |
| MoE 通信 | DeepEP(EFA 传输后端:UCCL-EP) |
6.2 核心指标对比
以下所有延迟指标均为越低越好。
| 指标 | 客户 RoCE (ConnectX 系列) | AWS P5en EFA | 比较 | 分析 |
| Mean TTFT | 11,904 ms | 12,977 ms | AWS 高 9% | Prefill 计算密集,网络非瓶颈 |
| Mean TPOT | 13.80 ms | 18.05 ms | AWS 高 31% | MoE 150 次小消息累积 |
| Mean ITL | 42.75 ms | 54.92 ms | AWS 高 28% | 与 TPOT 趋势一致 |
| P99 ITL | 56.20 ms | 66.98 ms | AWS 高 19% | 尾部差距收窄 |
| Max ITL | 434.30 ms | 116.99 ms | AWS 低 73% | SRD 多路径优势 |
| Mean E2E | 25,686 ms | 31,006 ms | AWS 高 21% | TPOT 差距 × token 数累积 |
6.3 差距根因分析
6.3.1 TTFT 差距仅 9% — Prefill 不受 per-message 延迟影响
- Prefill 的 MoE All-to-All 走 NVLink(EP=8 全在节点内),不走 EFA
- 唯一走 EFA 的是 PP Send/Recv(仅在 Pipeline Stage 边界跨节点传输,每 token 仅 1 次)
- 9% 差距主要来自 PP 跨节点传输
6.3.2 TPOT 差距 31%
- Decode EP=16 跨 2 节点,每层 MoE 需 2 次跨节点 All-to-All
- 75 MoE 层 × 2 次/层 = 150 次,每次多 ~28μs → 累积 4.25ms 差距
6.3.3 Max ITL 低 73% — EFA 的结构性优势
- RoCE 单路径遇到拥塞时无法绕行,产生 434ms 极端毛刺
- EFA SRD 将每个数据包 spray 到多条路径,天然负载均衡
- 结果:极端尾延迟 AWS 比 RoCE 好 3.7 倍
7. EFA 与 ConnectX 系列:两种高性能网络的设计哲学
上一章的数据显示,EFA 在跨节点 MoE 通信密集的 Decode 阶段 TPOT 高出 31%,但极端尾延迟反而好 3.7 倍。为了深入理解这一性能差距的根因,我们回到两种网络的设计原点——它们从诞生之初就在解决根本不同的问题。
7.1 为什么 AWS 自研 EFA
ConnectX 系列(InfiniBand 或 RoCE)是 GPU 集群互联的事实标准,为何 AWS 不直接采购,而是自研 Nitro 网卡与 SRD 协议?AWS 在其 HPC 技术博客给出的核心理由是:传统 RDMA 为固定拓扑的专用集群而设计,而云要服务的是持续增长、始终在线、多租户共享的基础设施——两者的约束根本不同。具体体现在三点:
- 不依赖”专用无损网络”。 InfiniBand 需要专用交换机;RoCE 要跑出高性能,则依赖 PFC 无损流控、ECN、专用 VLAN 等特殊交换机配置,实质上形成一片不能与其他流量共用的专用 Fabric。而 AWS 的原话是:云上”不能搞一座座特殊连接的孤岛”(can’t do islands of specially connected CPUs)。AWS 在以太网上有巨额存量投入,于是选择在统一以太网 Fabric 上自研 SRD——EFA 与普通 VPC 流量共享同一张物理网络,GPU 实例弹性扩缩容无需改动网络拓扑或交换机配置。
- 用”放弃有序”换尾延迟。 InfiniBand/RoCE 强制 per-QP 有序交付:一个丢包会阻塞该队列后续所有包(队头阻塞),在共享网络里,偶发拥塞会让 P99 尾延迟急剧恶化。SRD 反其道而行——放弃有序交付,把一块数据的包同时 spray 到多条路径(AWS 称一次从数百上千条可用路径中选 64 条),单条路径拥塞不拖累其余包。AWS 实测:P99 尾延迟下降约 10 倍。而 AI/HPC 的实际性能恰由尾延迟决定,而非单包的微基准延迟。
- 为”始终在线”和弹性而生。 RoCE 的 PFC 无损机制在大规模下容易引发拥塞扩散,InfiniBand 依赖统一的 Subnet Manager 管理路由——这类设计对一个”始终在线”(AWS is always on)、规模不断膨胀的多租户云是沉重负担。SRD 跑在标准(有损)以太网上,无需 PFC,拥塞控制与丢包恢复由 Nitro 硬件完成、对应用透明;且 SRD 是无连接模型,集群规模越大、可选路径越多,扩展性反而更好。
参考文献: Shalev L, Ayoub H, Bshara N, Sabbag E. “A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC.” IEEE Micro, vol.40, no.6, pp.67-73, Nov-Dec 2020.
一句话: 传统 RDMA(IB/RoCE)为固定拓扑的专用集群而生,EFA/SRD 为共享、持续增长的云而生——不是谁更”好”,而是解决根本不同的约束。
7.2 协议层对比:RoCE v2 vs EFA/SRD
两种方案在协议层的设计选择差异,直接决定了 MoE 推理场景中的性能特征:
| 特性 | RoCE v2 (ConnectX 系列) | EFA/SRD |
| 流类型 | 消息 (Message) | 消息 (Message) |
| 消息顺序 | 有序 (per QP,需应用管理) | 无序(可通过应用层实现有序) |
| 路由 | ECMP(依赖交换机支持,路径选择受限) | ECMP 喷射的负载均衡(多路径自动切换) |
| 重传超时 | 静态配置(需用户设置,通常微秒~毫秒) | 动态估计超时(微秒级 RTT 估计) |
| 拥塞控制 | ECN + DCQCN(依赖交换机支持,基于 PFC/ECN) | 动态速率估计 + 拥塞感知(无 PFC 依赖) |
| 综合效能 | 中等可扩展性(QP 数量随节点增长,PFC 配置复杂) | 高可扩展性(无连接,QP 数量与集群大小无关) |
| 适用场景 | 企业级 RDMA、容器网络、低延迟高吞吐的局域网络 | 云原生通信、大规模 AI 训练、弹性容错集群 |
| 是否需专用交换机 | 是(需支持 ECN + PFC,配置复杂) | 否(运行于 UDP/IP 之上,无交换机硬要求) |
| 部署复杂度 | 中高(MTU、流控、PFC 错误配置风险大) | 低(无损、零配置依赖,易于大规模部署) |
| 可靠性模型 | 无内建端到端重传,依赖底层链路稳定或应用重试 | 应用级容错(如 NCCL 内部 retry,EFA 支持) |
核心设计哲学差异: InfiniBand / RoCE 追求单次操作的极限低延迟(有状态 NIC + 确定性路由 + GPU 直驱),代价是部署复杂度高、扩展性受限;EFA/SRD 追求大规模稳定性(无状态 NIC + 多路径 spray + 硬件拥塞控制),代价是 per-message 延迟略高。
7.3 MoE 通信的核心挑战与 UCCL-EP 的解决方案
理解协议差异后,回到本次测试的核心问题:MoE All-to-All 通信在两种网络上的实际表现差异。
7.3.1 问题定义
Decode 每生成一个 token,需要经过 75 层 MoE,每层执行一次 Dispatch(发送 token 到目标 Expert)+ 一次 Combine(接收 Expert 计算结果),共 150 次跨节点小消息通信。单条消息很小,但对延迟极度敏感——任何 per-message 开销都被 150 次累积放大。
7.3.2 DeepEP 原始方案:IBGDA 直驱
DeepSeek 开源的 DeepEP 库为 InfiniBand 设计,采用 IBGDA(InfiniBand GPUDirect Async)机制——GPU kernel 内的 warp 线程直接写 ConnectX NIC 的 doorbell 寄存器触发 RDMA 传输,全程不经过 CPU:
7.3.3 UCCL-EP 的跨平台适配:CPU Proxy 架构
EFA NIC(AWS 自研 Nitro 卡)尚未向 GPU 暴露 doorbell,IBGDA 无法使用。为了解决 DeepEP 无法在 EFA 上运行的问题,UC Berkeley / UC Davis 团队开发了 UCCL-EP(Mao Z, Zhang Y, et al. “UCCL-EP: Portable Expert-Parallel Communication.” arXiv:2512.19849, OSDI 2026),通过 CPU Proxy 架构实现跨平台适配:
数据路径不经过 CPU 内存(NIC 直接 DMA GPU 显存),CPU 只负责转发控制指令。
7.3.4 通信路径对比与延迟量化
| 步骤 | IBGDA (ConnectX) | UCCL-EP (EFA) | 差异来源 |
| GPU 发起 | 写 NIC doorbell (~ns) | 写 FIFO (~ns) | ≈0 |
| 指令到达 NIC | 立即(同一 PCIe 总线) | CPU poll FIFO → 解析 → 提交发送 | +3-10 μs |
| 网络传输 | 交换机确定性转发 | SRD 多路径 spray | ≈相同 |
| 接收端处理 | NIC 硬件检查 → 写 CQE | CPU poll CQ → 重排序 → 通知 GPU | +3-10 μs |
| 每次通信总计 | ~5-15 μs | ~20-40 μs | ~15-25 μs |
用本次实测 TPOT 反推:
~28μs 的 per-message 差距与路径分析完全吻合。这不是带宽问题——3,200 Gbps EFA 绰绰有余——纯粹是 CPU Proxy 中转的固定开销被高频小消息累积放大。
7.4 EFA 的结构性优势:尾延迟稳定性
EFA SRD 的 Packet Spray 多路径设计,在延迟的另一个维度上展现出了优势——per-message 略慢,但极端情况远好于单路径方案:
| 延迟指标 | RoCE (ConnectX 系列) | AWS EFA | 对比 |
| Mean ITL | 42.75 ms | 54.92 ms | EFA 高 28% |
| P99 ITL | 56.20 ms | 66.98 ms | EFA 高 19% |
| Max ITL | 434.30 ms | 116.99 ms | EFA 低 73% |
RoCE 的确定性单路径路由在平均情况下更快,但一旦某条链路拥塞,该 QP 上所有流量被阻塞,产生极端尾部毛刺(434ms)。EFA 的 SRD 逐包分散到多条路径,天然避免单点阻塞,极端延迟仅 117ms。
对生产环境的意义: 用户感知的是”最慢的那个 token”。Max ITL 从 434ms 降到 117ms,用户体验的最差情况改善了 3.7 倍。对于在线服务的 SLA 保障,尾延迟稳定性往往比中位延迟更关键。
7.5 EFA的持续演进
需要强调的是,本文的性能数据是当前软硬件栈下的一个快照,而非终点。
EFA 作为 AWS 自研的网络方案,已经过多年大规模生产打磨,并随每一代 Nitro 硬件和 SRD 协议栈持续迭代。本次测试跑在P5en 这一代硬件上,而 AWS的网络能力仍在快速演进——随着新一代实例硬件,以及通信软件栈(libfabric、aws-ofi-nccl,以及社区的 UCCL-EP / DeepEP等)的成熟,跨节点小消息通信的效率有望进一步提升。
具体到本文观察到的 Decode 阶段 TPOT 差距:这是软件栈成熟度的问题——随着 GPU-initiated 通信(如 GDAKI这类让 GPU kernel 直接发起、绕过 CPU的技术路线)在新硬件与软件栈上落地,这一跳的开销有望被消除,届时差距会进一步收窄。
换句话说,EFA 在 SRD 多路径上展现的尾延迟稳定性优势(Max ITL 好 3.7×)是结构性的、当下就成立;而平均延迟上的差距则是阶段性的、会随生态演进缩小。对一个持续投入、规模不断增长的云网络而言,这个方向值得期待。
8. 部署架构与生产化
8.1 GPU 节点软件栈分层
要在 EKS 上跑 MoE PD 分离推理,节点软件栈要解决两件事:让节点用上 GPU 和 EFA 这两类硬件,并把它们安全地分配给容器。围绕这一点,节点软件栈可以分为职责清晰的三层:
三层分工
| 层 | 核心职责 | 关键组件 |
| 容器层 | 封装应用软件栈,可独立于节点升级 | SGLang + NCCL/aws-ofi-nccl (AllReduce/PP) + UCCL-EP (MoE) + nixl/Mooncake TE (KV Cache) |
| 设备资源层 | 向 K8s 调度器注册非标准设备,安全分配给 Pod | NVIDIA Device Plugin (nvidia.com/gpu: 8) + EFA Device Plugin (vpc.amazonaws.com/efa: 16) |
| AMI 层 | 让操作系统识别硬件,节点启动即就绪 | NVIDIA Driver 580.x + nvidia-container-toolkit + EFA Driver (efa.ko) + libfabric + NVMe LVM |
为什么需要这样分层? EFA 和 GPU 都是”非标准”设备——不能像 CPU/内存一样被容器运行时自动发现。AMI 层让操作系统识别硬件;Device Plugin 让 K8s 调度器感知资源数量并安全分配给 Pod;容器层封装应用软件栈,通过声明 resources.limits 获取设备访问,可独立于 AMI 和节点进行升级迭代。
8.2 本次实验的软件栈部署方式
本次实验采用 EKS 自管节点组 + EKS-optimized accelerated AMI(AL2023 / NVIDIA) + 自建容器镜像的组合,不使用 GPU Operator。三层的分工如下图所示:
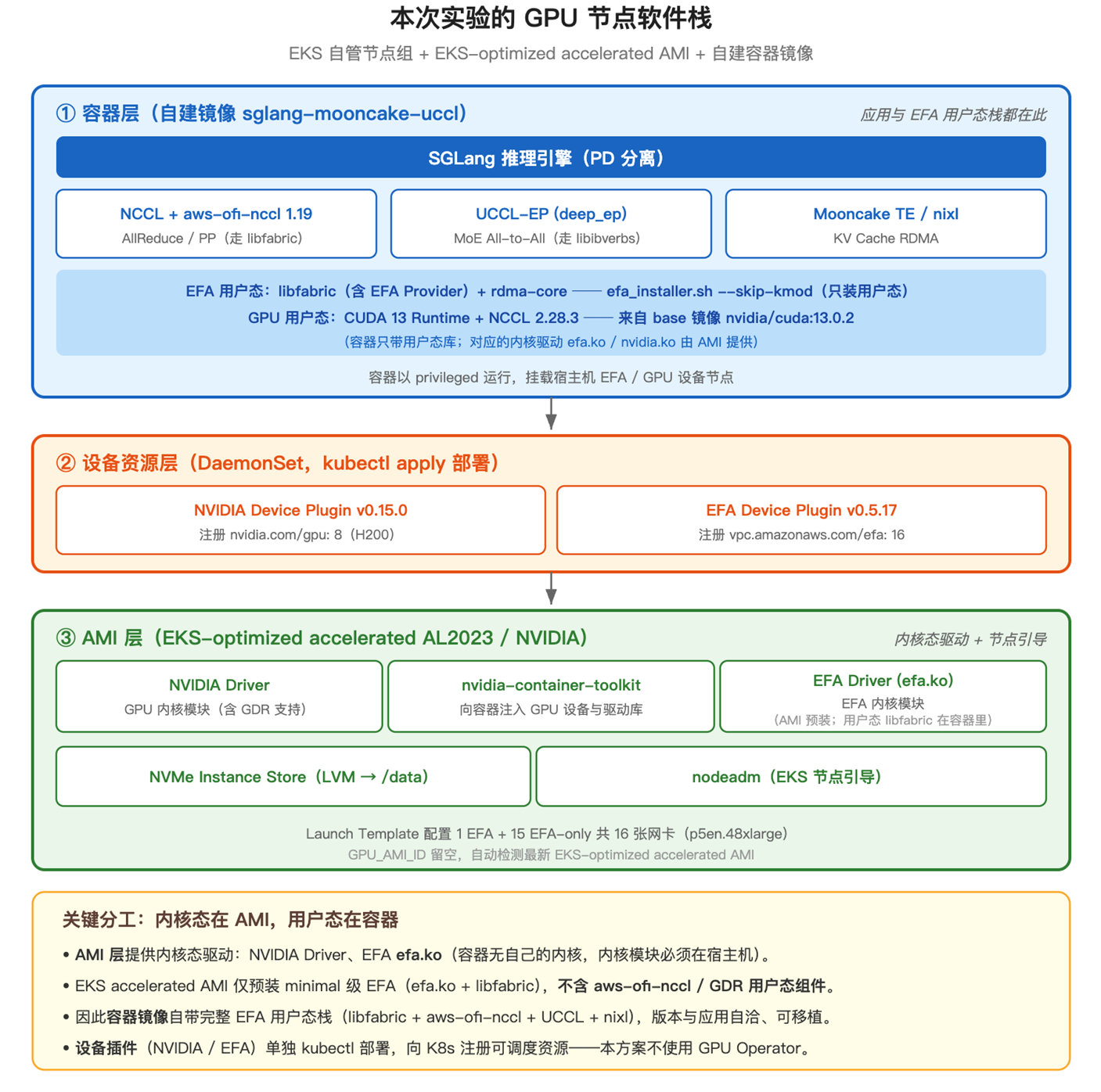
[图6] |
如上图,软件栈贯穿三层,核心是一条原则——内核态在 AMI,用户态在容器:内核驱动(efa.ko、NVIDIA Driver)随宿主机,由 AMI 提供;libfabric、aws-ofi-nccl、UCCL、CUDA runtime 等用户态库则随容器镜像走。
这套划分有两个值得强调的点:
- 为什么用户态栈要放进容器:EKS accelerated AMI 只预装了 minimal 级 EFA(efa.ko + libfabric),并不含 aws-ofi-nccl 等组件;与其依赖节点上的版本,不如让容器自带完整用户态栈(efa_installer.sh –skip-kmod 只装用户态),从而保证通信库与应用版本精确对齐、镜像可移植。
- 为什么不用 GPU Operator:本方案的 AMI 已预装 NVIDIA 驱动,无需 GPU Operator 在运行时安装;设备插件(NVIDIA / EFA)单独 kubectl 部署即可。叠加推理节点无状态(权重从 S3 拉取、可随时替换),AMI 预装驱动带来的确定性与启动速度成为更优选择。
9. 结论与展望
9.1 核心结论
回到第 1 章的核心问题——AWS EFA 能否在 MoE PD 分离推理这种复杂通信负载下,达到 ConnectX 系列 + RoCE 的水平? 本次测试覆盖了该场景的全部通信模式(TP AllReduce、PP Send/Recv、MoE All-to-All、KV Cache RDMA),涉及的通信库 NCCL(aws-ofi-nccl)、UCCL-EP、nixl/Mooncake TE 均达到生产可用级别,所有通信路径正常工作。
端到端对比下来:Prefill 计算密集、网络非瓶颈,TTFT 仅相差约 9%;Decode 高频跨节点小消息,TPOT 高约 31%——这一差距来自 CPU Proxy 中转的 per-message 开销,而非带宽瓶颈;而在尾延迟上,EFA SRD 的多路径设计反而带来 Max ITL 约 73% 的改善。 综合来看,对 Prefill 计算密集、以及对尾延迟稳定性敏感的场景,EFA 已可直接替代 RoCE;对 Decode 这类对单次延迟极敏感的场景,EFA 存在可量化、根因清晰的开销。
除了网络层的验证,本次工作还沉淀了一套从集群到节点的完整 EKS GPU 部署实践:私有化 EKS 集群、基于 DescribeInstanceTopology 的网络拓扑优化、p5en 的 EFA 多网卡 Launch Template、”内核态在 AMI、用户态在容器”的软件栈分层,以及 NVIDIA / EFA 设备插件的部署方式。这套实践可直接复用于在 AWS 上落地其它大模型 PD 分离推理负载。
9.2 展望
Decode 阶段的 TPOT 差距,根源在当前 EFA 上 GPU 间精细通信走的 CPU Proxy 中转——这是一个折中方案,而非 EFA 的带宽或协议短板。随着 EFA 软硬件栈与 GPU 间通信路径的持续演进,这一开销有望逐步收窄。
而 EFA/SRD “放弃有序、多路径 spray” 的设计在尾延迟上已展现出 RoCE 难以企及的稳定性——对在线推理服务而言,可预测的尾延迟往往比微基准的单包延迟更具生产价值。
➡️ 下一步行动:
相关产品:
- Amazon Connect — AI 客户体验解决方案
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon VPC — 隔离云网络
相关文章:
- 从IDC到云上GPU:基于 Amazon EKS 的大模型推理混合云弹性部署实践
- AWS Direct Connect 故障演练实战指南
- 基于 Prowler 与 GenAI 构建金融行业智能合规中枢
- Amazon Bedrock模型推理的Serverless 异步架构 – 处理在线多模态高负载案例
- 当 OpenClaw 学会”团队记忆”:一个面向多客户服务的企业级共享记忆系统设计
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
