亚马逊AWS官方博客
AI 驱动的大数据工程:从平台驱动到 AIDLC 的范式迁移
摘要:本文阐述了数据工程正从”平台驱动”的数据中台范式向”AI 驱动”的 AIDLC 范式迁移,其核心在于控制面从平台功能转为知识资产、开发模式从过程式转为声明式、质量保障从后置扫描转为前置契约,并给出了落地成熟度模型与五步实施建议。
一、引言
过去十年,数据工程领域的核心命题是”数据存得下、算得动”。从开源大数据生态到数据中台产品,企业已经基本解决了计算和存储的规模化问题。然而,业务对数据的期待并没有停止增长,业务方今天的典型诉求不再是”数据能不能跑出来”,而是”指标口径是否正确”、”需求交付是否够快”、”同一份数据为何会有多个版本”。
这些问题的本质不在工具层,而在流程层。随着生成式 AI 和智能体(Agent)能力的成熟,我们观察到一个明显的趋势:数据工程正在从”平台驱动”向”AI 驱动”范式迁移。在本文中,我们将讨论这次迁移的背景、三个本质差异,并以一个电商实时归因场景为例,对比传统数据中台路径与 AI 驱动开发生命周期(AIDLC)路径的差异。最后,我们会给出一个落地成熟度模型和五步实施建议。
二、数据工程的四次演变
要理解当前的范式迁移,需要先把过去二十年数据工程的发展轨迹看清楚。我们将其归纳为四个阶段。
第一阶段:手工作坊期(2000 年代)。 代表技术是传统数据仓库与存储过程。一个资深 DBA 往往同时承担开发、运维、分析三种职责,业务知识以口述或邮件形式流转。这个阶段的核心矛盾是”知识无法复制”——资深员工的离开几乎等同于资产的消散。
第二阶段:组件拼装期(2010 年代)。 开源大数据生态的成熟催生了独立的”数据工程师”职业。流批引擎、消息队列、调度系统、血缘与质量工具等组件拼装起来,解决了算力和吞吐的规模化问题。但”散”成了新的矛盾:每个组件都是独立阵地,打通的成本极高。
第三阶段:数据中台期(2018 年至今)。 这是大多数企业今天所处的阶段。一体化数据平台将 IDE、调度、血缘、质量、权限、成本等能力收敛到统一的控制面中,生产力较前一阶段有显著提升。然而,中台模式的一个隐形前提始终未被打破:人写代码,平台托管代码。平台再强,也必须依赖人来书写 SQL、编排 DAG、配置依赖、定义规则。这决定了团队生产力的上限等于”人数 × 人均产出”,本质上仍是线性扩张。
第四阶段:AI 驱动期(2024 年起)。 随着基础模型和 Agent 框架的成熟,AI 从”代码补全工具”升级为”贯穿需求到运维的协作者”。其代表性方法论是 BigData-AIDLC(Big Data AI-Driven Lifecycle),它将软件工程的完整生命周期压缩并重构成三个自适应阶段:Inception(需求与建模)、Construction(开发与测试)、Operations(调度与运维)。而这套方法论同样可以应用到数据分析领域,成为 BigData-AIDLC。
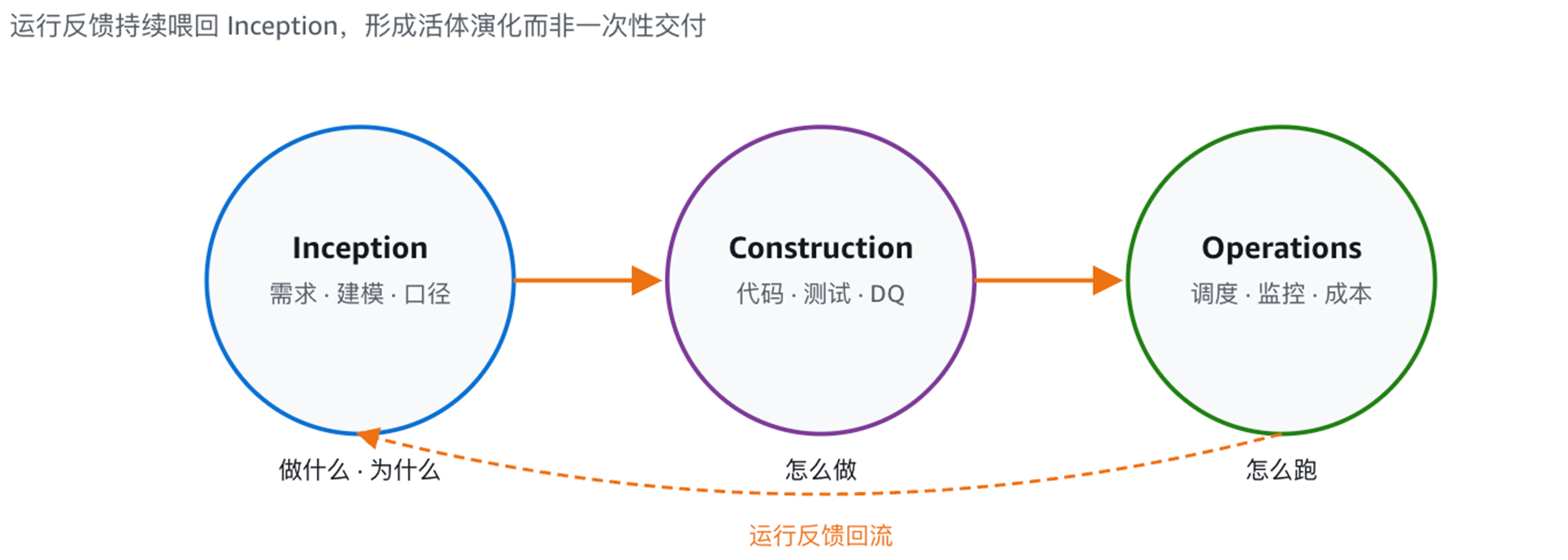
图 1:AIDLC 三阶段协作闭环。运行反馈持续回流到 Inception 阶段,使数据链路具备持续演化能力。 |
与前三个阶段相比,第四阶段最关键的变化并非”AI 代替人写代码”,而是 AI 以协作者的身份介入完整开发生命周期,从而改变了团队生产力的杠杆结构。
三、全链路建设的新图景:三层叠加
在传统的数据工程架构图中,数据链路通常被描述为”数据源 → 采集 → 存储 → 计算 → 服务 → 应用”,横切面包括调度、元数据、质量、安全、成本。这个路径准确地描述了”链路是什么”,但没有回答”链路是怎么被构建和演进的”。过去,这个问题的默认答案是”人”。
在 AI 驱动期,我们建议将架构图拓展为三层叠加结构:

图 2:三层叠加结构。平台执行层是”手脚”,AIDLC 协作层是”大脑”,知识与规范层是”灵魂”,三者缺一不可。 |
这个结构中需要特别说明的是”知识与规范层”。在传统数据工程中,团队的分层规范、命名规则、指标字典等资产散落在 Wiki、会议纪要、资深员工的认知中,本质上是供”人类阅读”的知识。在 AIDLC 范式下,这些知识被结构化为 Markdown 文件(即 Steering 文件),放入版本控制系统,成为”AI 可执行”的资产。这看似不起眼的变化,实际上是整个范式迁移的基石。
四、三个本质区别
AI 驱动与传统数据中台的差异,不在于”更强的功能”,而是在三个维度上的范式迁移:控制面、开发范式、质量保障。
控制面:从平台功能到知识资产
数据中台的控制面是”平台功能”。一个团队能做什么、不能做什么,由平台产品团队的路线图决定。团队的资产体现为”配好的节点、画好的 DAG、调好的依赖”,这些资产深度绑定于特定平台,在跨平台迁移、并购重组、技术栈演进时会成为沉重的负担。
AIDLC 的控制面是”知识资产”。团队的分层规范、命名规则、指标字典、数据契约,首次以”AI 可执行的 Markdown”形式存在,纳入 Git 版本控制。这带来三个可以量化的变化:
- 规范第一次成为”代码”——可版本控制、可 diff、可回滚、可 code review。Steering 的一次提交会直接影响 AI 的全部产出,迫使规范被严肃对待。
- 规范可跨平台复用。当团队更换底层数据平台时,Steering 可以直接携带。资产与平台解耦,意味着过去的”平台绑定成本”变成了”平台选择自由度”。
- 知识从”记忆型”转为”累积型”。新员工入职第一天,通过阅读 Steering 即可获得接近资深员工的规范直觉,这对快速扩张的团队尤为重要。
开发范式:从过程式到声明式
中台模式下的开发是过程式的:开发者在 IDE 中逐步点击、连接节点、编写 SQL、配置依赖——过程即产物,调试需要回放过程。
AIDLC 模式下的开发是声明式的:开发者书写”我期望的结果和必须满足的约束”(Spec),Agent 负责将 Spec 实现为可运行的代码与配置。Spec 即产物,实现细节对开发者不可见也不需要关心。
这一转变的历史意义,与软件工程史上从汇编到高级语言、从命令式到 SQL/函数式的跃迁同构。每一次类似的跃迁发生时,都伴随着同样的怀疑:生成的代码是否高效、出问题能否调试、人类是否还能理解。历史给出的答案是一致的——短期存在磨合成本,长期是赢家通吃,因为它将人从”怎么做”中解放出来,使其能够聚焦在更稀缺的”做什么、为什么”上。
质量保障:从后置扫描到前置契约
在数据中台范式下,数据质量(DQ)是一个独立的模块,典型流程是”开发 → 上线 → 扫描 → 发现问题 → 返工”。这个流程不是平台设计的缺陷,而是”人写代码”这一前提导致的必然结果——开发者在编写代码时关注的是”实现”,而不是全面的”约束”。
在 AIDLC 范式下,DQ 是 Spec 的组成部分。在 Inception 阶段就会明确定义诸如”主键唯一、关键字段非空、金额字段为正、归因权重之和为 1、日期分区连续无缺失”等契约。Construction 阶段 Agent 基于 Spec 自动生成对应的 DQ 规则代码,确保上线即内建校验。
这就是软件工程中广为人知的 shift-left——将质量保障从右侧(上线后)左移至左侧(设计期)。缺陷修复成本曲线(Shift-Left 的经济学)意义非常显著,主要发现:软件缺陷每年给美国经济造成 595 亿美元损失,其中相当一部分是因为缺陷发现过晚。这个结论最早可以追溯到 Barry Boehm 1981 年的《Software Engineering Economics》,后续 NIST 在 2002 年的报告 The Economic Impacts of Inadequate Infrastructure for Software Testing 中给出了更现代的实证数据。具体倍数因项目而异,但”越晚发现、修复越贵”的总体趋势是行业共识。,下图为示意性的数量级展示。:
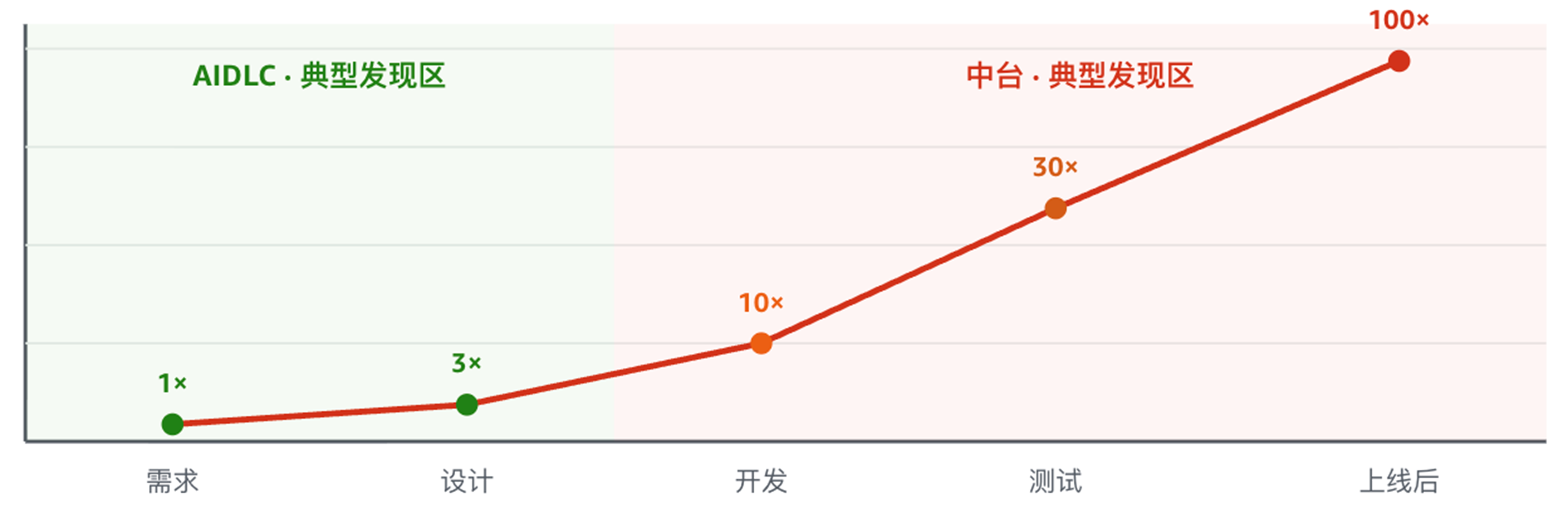
图 3:缺陷修复成本随时间推移呈指数增长。AIDLC 将口径争议等典型缺陷的发现点从”100× 区”前移至”1× 区”。 |
这里需要强调的是,我们经常看到的”开发周期缩短 60%”只是显性收益。更深层的收益在于问题发现点的前移——同一个缺陷,在 Spec Review 阶段发现的修复成本与在上线后发现相比,可以差两个数量级。
总览对比
| 维度 | 数据中台 | AI 驱动(AIDLC) |
| 核心抽象 | 组件与流程 | 意图与契约 |
| 开发入口 | 可视化 IDE + SQL | 自然语言 + Spec |
| 知识沉淀 | 平台功能与文档(人读) | Steering 与 Prompt(AI 可执行) |
| 生产力瓶颈 | 代码编写速度 | Spec 审核速度 |
| 变更成本 | 修改多处节点 | 修改 Spec 即重新生成 |
| 治理方式 | 事后扫描与审批 | 事前嵌入约束 |
| 平台依赖 | 强耦合 | 可跨平台 |
| 团队规模化方式 | 线性扩张 | 杠杆放大 |
五、案例:实时 GMV 渠道归因
为使上述差异更加具体,我们以一个在电商行业中常见的实时归因需求为例进行对比。
需求背景: 某电商平台运营团队希望在大促期间实时观察 GMV 在各个渠道(自然搜索、付费投放、私域、直播、联盟)的贡献归因,要求分钟级更新,并支持按类目和地域下钻。数据输入包括订单流(CDC)、点击流(Kafka)、广告数据(外部 API)、商品维表、归因规则。交付物包括实时大屏(延迟低于 1 分钟)、明细归因表、异常告警和离线复盘看板。交付时间窗口为距大促开始的 3 周。
路径 A:基于数据中台的传统做法
在中台模式下,典型项目路径如下。
| 时点 | 阶段 | 关键动作 |
| W1 | 需求评审 | PRD 评审,架构师与开发多轮会议对齐指标口径 |
| W1 | 建模设计 | 人工设计 ODS/DWD/DWS/ADS 分层,资产目录登记 |
| W2 | 管道开发 | 在 IDE 中编写实时流作业与批任务 |
| W2 | DQ 规则 | 在质量模块中逐字段配置校验规则 |
| W2–3 | 调度编排 | 设计 DAG、配置依赖、设置告警 |
| W3 | 联调上线 | 业务方验收。常见发现口径与预期不符,触发返工 |
该路径下最昂贵的成本通常出现在第三周的联调验收阶段:此时代码已经写完,业务方才意识到实际计算的 GMV 口径与预期不一致。这并非平台的缺陷,而是”人写代码 + 人工对齐需求”这一范式的必然结果。
路径 B:基于 AIDLC 的新做法
在 AIDLC 模式下,同一需求的典型路径如下。
| 阶段 | 耗时 | AI 产出 | 人的动作 |
| Inception | 2 天 | 指标口径 Spec、分层方案、技术选型、验收标准与 DQ 契约 | 业务方与架构师 Review 并签字 |
| Construction | 5 天 | 流批作业、单元测试、DQ 规则、性能调优建议 | Code Review 与小样验证 |
| Operations | 2 天 | DAG 编排、SLA 告警、大促弹性策略 | 监督与护栏配置 |
该路径下最有价值的变化发生在 Inception 阶段的第二天:由于 Spec 以自然语言书写,业务方能够直接参与评审与签字,口径争议从第三周前置到第二天。这正是 shift-left 在数据工程中的典型体现。
两条路径的关键指标对比
| 指标 | 数据中台 | AIDLC |
| 交付周期 | 约 3 周 | 约 9 天 |
| 口径争议发生时点 | 第 3 周(成本约 100×) | 第 2 天(成本约 1×) |
| 业务方介入时机 | 上线前验收 | Spec 评审阶段 |
| 返工率 | 较高,常见 1–2 轮 | 较低 |
| 瓶颈位置 | 开发人手 | Review 速度 |
| 文档与代码一致性 | 长期不一致 | Spec 即真相 |
需要特别指出的是,周期缩短不是这种范式迁移最重要的收益。更重要的收益是瓶颈的位置上移、业务方参与前置、以及文档与代码的强一致——这些变化会在团队长期运营中产生持续的复利效应。
六、团队角色的演变
“AI 会替代数据工程师吗?” 这是我们在客户访谈中被问到最多的问题。根据我们对多个试点团队的观察,更准确的描述是角色上移:工作重心从”执行”迁移到”定义”,即从写代码转向”定义问题、设计约束、验收结果”。
| 角色 | 过去的职责 | AI 驱动后的职责 |
| 数据架构师 | 绘制分层、制定规范(供人阅读) | 沉淀 Steering 与 Prompt(供 AI 执行) |
| 数仓与 ETL 开发 | 编写 SQL 与数据处理代码 | 撰写 Spec 与验收标准,审核 AI 产出 |
| 数据分析师 | 提需求后排期等待 | 用自然语言快速验证 PoC |
| 数据质量与治理 | 事后补充规则 | 在 Inception 阶段定义契约 |
| 数据平台与 SRE | 维护调度与集群 | 维护 Agent 工具箱与护栏 |
其中,数据架构师的杠杆效应最为显著。过去架构师的规范通常依赖执行层的自觉性,而在 AIDLC 范式下,Steering 文件的一次提交即可改变整个团队的 AI 产出质量——架构师第一次具备了”直接控制产线”的能力。数据开发工程师受到的冲击最为直接,但我们观察到的并不是替代,而是两极分化:能清晰表达设计意图的开发者获得了更大的杠杆,而单纯依赖”写得快”的开发者则被暴露。数据分析师是最大的直接受益者,业务响应速度可以压缩一个数量级。数据质量团队从”救火”转变为”立法”,从成本中心转变为赋能中心。平台 SRE 的职责从运维 pipeline 扩展到运维 AI 系统,这是一个全新的技能栈。
七、落地路径:成熟度模型与五步实施建议
根据我们与多家企业客户合作的经验,大多数团队目前处于”AI 在个人层面被零星使用”的阶段。我们建议参考以下成熟度模型进行自检。
- L0 · 散点使用:少数工程师在个人工作中使用 AI 辅助编码。
- L1 · 工具化:AI 编码助手嵌入 IDE,团队日常使用,但没有统一规范。
- L2 · 规范化:Steering 文件就位,在窄场景试点中跑通完整流程。(第一个实质性门槛)
- L3 · 生命周期化:AIDLC 成为主流开发模式,团队 KPI 已重定义。
- L4 · 自演化:运行反馈自动回流到 Steering,Agent 具备一定程度的自主优化能力。
从 L0/L1 到 L2 的跃迁是最具挑战性也最有价值的一步。我们建议以下五步实施路径。
第一步:先沉淀 Steering。 这是杠杆最高、风险最低的起点。建议按”分层规范 → 命名规则 → 核心指标字典 → 质量契约模板”的顺序推进,每份文档控制在 2000 字以内,先覆盖最高频使用的 10 张表。不追求完美,优先可用。
第二步:选择一个窄场景试点。 避免一次性全量铺开。建议选择边界清晰、业务方熟悉的场景(例如”新增一张 ADS 表”的完整流程),完整跑通一次,然后再考虑复制。
第三步:重构 Code Review 流程。 评审对象从”代码”扩展为”Spec + 代码 diff”。如果评审流程不变,AI 产出的代码将无法顺利进入主干。
第四步:重新定义 KPI。 从”上线的表数量”转向”需求到上线的 lead time”与”返工率”。如果 KPI 不变,团队成员在现实激励下难以真正采用新范式。
第五步:建立 AI 护栏。 包括权限边界、成本阈值、敏感数据保护、幻觉检测、审计日志,五条红线必须具备。
八、常见反模式
根据我们的试点观察,团队在采用 AIDLC 时常见三种反模式,了解它们往往比做对更重要。
九、总述
数据工程正在经历一次从”平台驱动”到”AI 驱动”的范式迁移。这一迁移的核心并非”AI 替代数据工程师”,而是在数据中台之上叠加了”AIDLC 协作层”与”知识与规范层”,使团队的生产力杠杆结构发生了根本变化。
我们的判断是:未来 3 年,采用 AI 原生范式的数据团队与停留在平台驱动范式的数据团队,在人效上的差距可能拉大到 5–10 倍。这一差距并不来自大模型能力的强弱——基础模型的能力会在行业内快速拉平——而来自谁更早把自己的方法论变成 AI 可执行的知识。
这件事可以今天就开始,不需要等待下一代模型、下一个平台版本,或一个大而全的解决方案。一个务实的起点是:在你的代码仓库中新建 steering/ 目录,请团队中最资深的数据架构师将”我们团队的分层规范”写成第一份 Markdown 文件。这就是迈向 AI 驱动数据工程的第一步。
套用客户负责人的一句话:我们在森林里遇到一头熊,大家要赶紧跑,不管你跑得快还是慢,但你不能是最后一个。这是最好的创新时代,缓解焦虑的最佳姿势,就是赶紧上车。
参考文档:
- AI-Driven Development Lifecycle (AI-DLC) Method Definition
- AIDLC workflow
- BigData-AIDLC — 大数据 AI 驱动开发生命周期框架
- NIST 报告 “The Economic Impacts of Inadequate Infrastructure for Software Testing” (2002)
➡️ 下一步行动:
相关文章:
- (上篇)基于 AWS Bedrock AgentCore 构建企业级航空客服智能体 —— 基于AIDLC方法从需求分析到生产部署的完整实践
- 从 SDLC 到 AIDLC:CI&T 对 AI 驱动软件开发模式的探索及Kiro最佳实践
- 基于 AWS DevOps Agent 构建 AI 驱动的运维分析系统
- AI 驱动的跨云网络搭建:用 Claude Code 和 Kiro CLI 实现 AWS-腾讯云 IPSec VPN 双隧道互联
- 简化故障注入,读懂应用影响:用 AI Agent 做混沌工程
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
