亚马逊AWS官方博客
用 Amazon SageMaker AI 与 Qualcomm AI Hub 打通从云端训练到端侧神经处理单元(NPU)的交付闭环
摘要:本文给出一条 Amazon SageMaker 与 Qualcomm AI Hub 组合的端到端方案:云端 BYOM/BYOD 微调,AI Hub 在真实 Snapdragon 设备上完成编译、真机校验与性能分析,一个 Notebook 跑完全程。以手机人像分割为例,端到端约 20 分钟,Galaxy S24 实测 13.59 ms。
一、概述
把云端训练好的模型交付到端侧神经处理单元(Neural Processing Unit,NPU)上运行,是一项跨团队、多工具链的工程。算法团队产出的是 PyTorch 或开放神经网络交换格式(Open Neural Network Exchange,ONNX)的浮点模型,端侧团队需要的是经过量化、针对特定芯片编译并通过真机回归的二进制。中间隔着模型格式转换、量化校准、算子兼容性排查、目标硬件采购、交叉编译环境搭建、跨芯片性能与精度验证等一系列环节。这些环节缺少统一工具链,往往让一个端侧 AI 项目从训练完成到上线被拉长到 2 到 3 个月。
在这篇博客中,我们介绍如何用 Amazon SageMaker AI 与 Qualcomm AI Hub 组合出一条端到端的工作流:在 SageMaker AI 上完成 Bring Your Own Model(BYOM)和 Bring Your Own Data(BYOD)的微调,然后通过 AI Hub 在云端托管的真实 Snapdragon 设备上完成模型编译、推理校验和性能分析,最后把编译产物交付到目标手机或边缘设备。完整链路装在一个 Jupyter Notebook 里就能执行,把端侧验证从过去的数周压缩到一次 Notebook 运行。文章用一个手机端实时人像分割的例子演示这些步骤,便于读者在自己环境里复现。
二、业务挑战
越来越多的 AI 应用要求在端侧设备上完成推理,且每个领域都有各自的硬性约束。
在消费电子侧,手机相机的实时人像分割需要在 30 fps 出图节奏下、单帧 33 ms 的预算内完成推理,同时和相机管线、特效与渲染共享系统级芯片(System on Chip,SoC)资源。相册的图像超分要求在用户无感知的延迟内完成放大。增强现实(AR)应用的目标识别则通常要求识别和六自由度(six degrees of freedom,6DoF)跟踪同步进行,画面不上传云端。
在工业质检侧,产线节拍以秒级计算(冲压 4–6 秒一件、PCB 检测 30 fps),漏检会让缺陷件流入下游导致整批返工。车间网络可用性差、生产数据因合规要求往往不能出厂。模型必须部署在工位旁的工业模组上,并在宽温区间内长期稳定工作。
在汽车与车载侧,语音助手要在隧道、地下停车场等断网环境下持续可用,高级驾驶辅助系统(Advanced Driver Assistance Systems,ADAS)视觉感知要求毫秒级响应。车规芯片在宽温度范围下被约束在更低的 NPU 频率,比手机平台多了一重功耗和热管理预算。
虽然不同场景的形态不一样,但共性诉求是一致的:图像和语音不出场、推理延迟可控、断网时业务不停——把模型跑在端侧 NPU 上是这些场景共同的选择。
不过,开发者在交付端侧 AI 时通常会遇到三组困难:
第一,模型定制。开源模型是好的起点,却很少能直接满足业务对类目分布、相机色彩、光照条件等具体要求,必须用业务数据做迁移训练。
第二,针对特定芯片的优化。不同 Snapdragon 平台的 NPU 架构、Runtime(TensorFlow Lite、ONNX Runtime、Qualcomm AI Engine Direct SDK)、量化策略各不相同,把一个 PyTorch 模型变成可以在目标芯片上跑得起来的二进制,涉及大量手工劳动。
第三,真机验证的成本。性能数字必须来自目标设备本身。手机和工业模组之间、甚至同代 NPU 在不同平台上的延迟差异都可能成倍出现,缺少多设备真机数据,方案评审和 SLA 制定就只能拍脑袋。
开发者真正想要的,是一条端到端、可复制、可自动化的链路:训练在云端、优化在云端、真机验证也在云端,最后只把编译好的二进制下发到端侧。
三、Amazon SageMaker AI 与 Qualcomm AI Hub 联合方案
Amazon SageMaker AI 与 Qualcomm AI Hub 各自覆盖了端到端链路的一段,组合起来正好填补中间的工程缝隙。
Amazon SageMaker AI 负责模型训练与产物管理。 它提供从分布式 GPU 训练、托管训练镜像、超参数调优到模型注册的完整能力。开发者可以按需获得 NVIDIA A10G、H100 等高性能算力,按使用量计费,不必自建训练集群。SageMaker AI 同样支持把分布式训练扩展到上千 GPU,并集成 DeepSpeed、Horovod、Fully Sharded Data Parallel(FSDP)等第三方库,能够稳定支持基础模型连续数周的训练任务。
Qualcomm AI Hub 负责端侧编译、真机验证与设备性能分析。 它接受 PyTorch 或 ONNX 模型,自动完成转换、图优化、量化和编译,输出可在 Snapdragon 设备上运行的 TensorFlow Lite、ONNX Runtime 或 Qualcomm AI Engine Direct SDK 产物。AI Hub 在 AWS 上托管了一座由真实手机、车载域控制器和工业模组组成的设备车队,开发者可以直接发起编译、推理和性能分析三类任务,不必采购物理硬件。AI Hub 同时维护一个预优化模型库,覆盖 MobileSAM、Whisper、Real-ESRGAN、YOLOv8、Llama 等常见架构,可作为开发起点或基线对照。
两者天然契合的另一个原因是 AI Hub 本身的编译服务和模型与编译产物就部署和存储在 AWS 基础设施上。从 SageMaker AI 训练输出到 AI Hub 编译输入之间,数据始终在 AWS 生态内流转,不存在跨云搬运。
下面这张图描述了开发者从本地或 SageMaker AI Notebook 出发,经过 SageMaker AI 训练并最终在 AI Hub 真机上完成验证的端到端工作流。
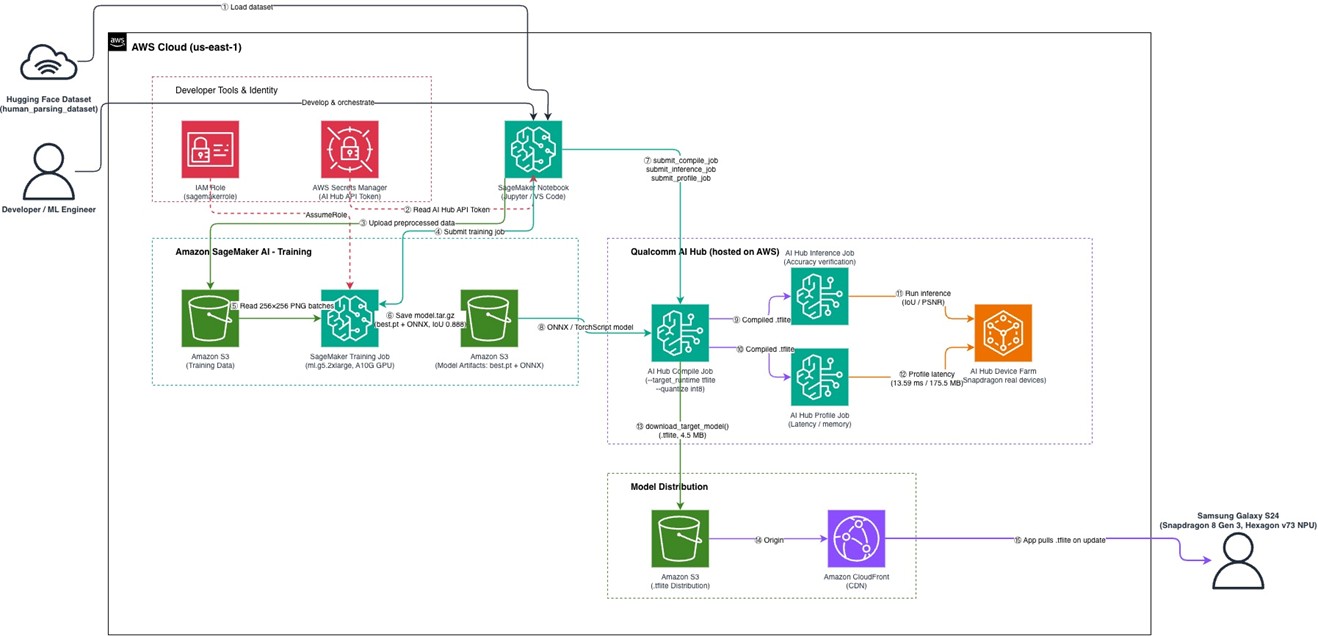
[图1:Amazon SageMaker 与 Qualcomm AI Hub 联合方案架构] |
完整链路可以装在一个 Jupyter Notebook 里执行,包括以下步骤:
- 选择基模型与数据集,把数据按目标模型期望的格式预处理。
- 用 SageMaker AI Python SDK 把数据上传到 Amazon S3。
- 调用 SageMaker AI 的训练 API,按需获取分布式训练集群完成微调。
- 训练完成后,SageMaker AI 把训练产物保存到 S3 并自动释放算力。
- 把微调好的模型拉回本地,做一次精度校验。
- 调用 AI Hub 的 submit_compile_job / submit_profile_job / submit_inference_job,在云端真实设备上完成编译、性能与精度验证,再下载编译产物供端侧应用集成。
端到端工作流之所以能装进一个 Notebook,是因为 AI Hub 已经把模型编译、跨设备性能验证、量化精度校验都做成了云端 API。算法工程师在 SageMaker AI Notebook 实例里 pip install qai-hub 之后就能直接发起任务。流程稳定之后,这些 API 调用可以放进持续集成 / 持续交付(Continuous Integration / Continuous Delivery,CI/CD)系统里自动执行,让每次模型迭代都经过相同的真机性能与精度检查。
四、实施步骤示例:手机端实时人像分割
为了让上面的方案具体起来,下面用一个手机端实时人像分割(如视频会议背景虚化)的例子来演示工作流。本文用公开的 Hugging Face 数据集 [mattmdjaga/human_parsing_dataset](https://huggingface.co/datasets/mattmdjaga/human_parsing_dataset)(多类人体解析标注,可二值化为人像 / 背景)作为训练数据;基模型选用 segmentation-models-pytorch 提供的 FPN + MobileNetV2(256×256 输入、参数量约 4.2 million);目标设备是 Samsung Galaxy S24(Snapdragon 8 Gen 3,Hexagon v73 NPU)。这只是一个便于复现的示例,同样的链路可以套用到光学字符识别(OCR)、关键词唤醒、目标检测、端侧大语言模型(LLM)等场景。本次端到端工作流在 us-east-1 区域运行,从数据准备到拿到可部署的 .tflite 文件总耗时约 20 分钟。
先决条件
- Jupyter Notebook 环境(示例在 Visual Studio Code + Python 3.11 中验证通过)。
- 一个 AWS 账户。
- 创建一个 AWS Identity and Access Management(IAM)用户,并附加 AmazonSageMakerFullAccess 策略;同时配置好 CLI 凭证。
- 安装 AWS Command Line Interface(AWS CLI),运行 aws configure 完成本地凭证设置。
- 创建一个名为 sagemakerrole 的 IAM 角色,由 SageMaker AI 担任,并附加 AmazonS3FullAccess 让 SageMaker AI 能访问你的 S3 桶。
- 通过 Service Quotas 控制台把账户内 ml.g5.2xlarge 的 SageMaker AI 训练实例配额提升到至少 1。
- 按照 Qualcomm AI Hub 的入门指引安装 qai-hub 库并配置 API Token。
第 1 步:访问模型与数据
在 Notebook 顶部安装本次工作流需要的包。
segmentation-models-pytorch 提供了一组轻量分割模型,便于以 MobileNetV2-Small 作为 encoder、LR-ASPP 作为 decoder 搭出一个手机 NPU 友好的网络。
第 2 步:预处理数据集并上传到 Amazon S3
mattmdjaga/human_parsing_dataset 在 Hugging Face 上以 image + 多类 mask 配对的形式提供。我们做三件事:把多类掩膜(头发/皮肤/衣服等)二值化为”人像/背景”两类(满足背景虚化场景),把图像和掩膜统一缩放到 256×256,按 500/50 切分训练集与验证集,最后上传到 S3。
预处理 + 上传整体耗时约 3 分钟。500 张训练样本不大,但足以在演示规模下让模型产出有意义的指标;接到生产时把样本量按需放大,目录格式不变。
第 3 步:在 SageMaker AI 上微调分割模型
训练脚本
我们准备了 train_portrait_seg.py,调用 segmentation-models-pytorch 构建 FPN + MobileNetV2 分割网络(encoder 加载 ImageNet 预训练权重),用 Dice + BCE 联合损失微调,最后导出 ONNX 文件供 AI Hub 消费。
注意 DiceLoss 与 BCEWithLogitsLoss 不能直接用 + 运算符合并成单一损失对象,需要包成 lambda 或自定义 nn.Module 再调用。SageMaker AI 的 PyTorch 2.1 容器默认没有 onnx 包,可以在脚本头部 pip install onnx 一并解决。
启动 SageMaker AI 训练作业
可以使用 SageMaker AI Python SDK 的 PyTorch estimator 提交训练,也可以用 boto3 直接调用 create_training_job API(在 Python 3.14 等较新解释器下,boto3 的兼容性目前更稳)。下面给出 SDK 的写法:
estimator 会拉起一颗 NVIDIA A10G GPU(24 GB 显存),使用 SageMaker AI 维护的预编译 PyTorch 容器(镜像 pytorch-training:2.1.0-gpu-py310-cu121)。在我们的 500 张训练样本上跑 10 个 epoch,端到端用时 260 秒(含容器启动与依赖安装),最佳验证 Intersection over Union(IoU)达到 0.888。训练运行期间可通过 AWS Management Console、AWS CLI 或 AWS SDK 跟踪状态。
第 4 步与第 5 步:保存、下载并验证训练好的模型
训练作业结束后,PyTorch 权重(best.pt,约 16.7 MB)和 ONNX 文件(portrait_seg.onnx,约 16.5 MB)会一起打包成 model.tar.gz 落到 output_path 对应的 S3 路径。Notebook 把它拉到本地解压,加载权重后在验证集上跑一遍推理,把”输入图像 / 真值掩膜 / 模型预测掩膜”拼成 mosaic 做视觉化校验,并计算人像 IoU。在我们 20 张抽样验证图上得到的 FP32 IoU 是 0.932,确认模型质量进入端侧验证阶段的合格范围。
第 6 步:用 Qualcomm AI Hub 在手机上运行模型
完成 PyTorch 侧的本地验证后,下一步是把模型送到目标手机上跑。AI Hub 在这里提供四个能力:把模型编译成可以在端侧运行的格式、在 AWS 上的真实设备车队运行编译产物、校验真机精度、测量真机延迟。
目标设备是 Galaxy S24(Snapdragon 8 Gen 3,Hexagon v73 NPU),手机端推理走 TensorFlow Lite Delegate(QNN HTP),因此把 –target_runtime 指定为 tflite。运行 qai-hub list-devices 可以列出 AI Hub 当前支持的设备型号。
编译
–quantize_full_type int8 让 AI Hub 在云端自动完成 INT8 后训练量化(Post-Training Quantization,PTQ)。对人像分割这种 encoder-heavy 网络,INT8 量化把模型体积从 FP32 ONNX 的 16.5 MB 压到 4.5 MB(约为 27%)。注意 AI Hub 早期版本的量化选项叫 w8a8,后续版本统一为 int8,请以 qai-hub –help 输出为准。
真机推理校验精度
AI Hub 会自动计算峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)作为真机输出与 FP32 参考的数值保真度指标。本次结果是 -21.74 dB,但这个数字不能直接用来判断精度。原因是 FPN 分割头输出的是未经 sigmoid 的 logit,数值范围约 -8 到 +5,INT8 量化误差会被 PSNR 公式放大;而二值分割真正看的是 sigmoid 与阈值之后的掩膜。因此分割模型的精度检查不应只看 PSNR,应当用真机推理结果在验证集上重新计算 IoU、Dice 或边缘 F-score。
真机 Profile 测量延迟
Profile 在真机上重复执行 100 次推理,取最小延迟以剔除其他后台进程的干扰。在Galaxy S24 上,FPN + MobileNetV2 微调后 INT8 模型的实测推理延迟为 13.59 ms,峰值内存 175.5 MB,首次加载耗时 2.35 s、热加载 125 ms。30 fps 实时背景虚化的预算是 33 ms 帧间隔减去渲染与后处理(约 20 ms),分割模型本身落在 13 ms 量级,可以满足大多数会议场景,要进一步压缩到 8–12 ms 通常需要更小的 encoder(例如 MobileNetV3-Small)或更激进的算子裁剪。作为对照,未经 SageMaker AI 微调、直接量化的同结构模型在同款手机上的延迟是 15.31 ms,微调后的激活分布更利于 INT8 表达,这也带来了 1–2 ms 的延迟收益。
部署到设备
下载后的 .tflite 产物(4.5 MB)交给 App 集成团队。手机端用 TensorFlow Lite Interpreter + QNN HTP Delegate 加载它,由 Hexagon NPU 完成推理,CPU 留给相机管线和 UI 绘制。生产环境中模型可以托管在 Amazon S3 + Amazon CloudFront 上,由 App 启动或更新时按机型拉取对应的编译产物。
端到端可视化验证
为直观展示完整链路的实际效果,我们取一张验证集中的真实人像图片,分别在本地 FP32 和 Galaxy S24 真机 NPU 上执行推理,将结果并排对比。验证目的是隔离”训练到设备推理”链路的正确性,因此本节使用无量化编译(FP32 TFLite):
执行结果如下(AI Hub Job ID:Compile jgnrz39q5,Inference jp8wez3op):
| 推理环境 | 与 Ground Truth 的 IoU | 说明 |
| 本地 PyTorch FP32 | 0.9326 | CPU 推理,数值参考基线 |
| Galaxy S24 NPU(TFLite) | 0.9347 | Hexagon v73 真机推理 |
| 两者像素级一致性 | 0.9961 | 仅 64 个像素(0.1%)不同 |
99.6% 的像素级一致性证明:SageMaker AI 训练输出经过 AI Hub 编译后,在端侧 NPU 上的推理结果与开发环境基本等价。

[图2:本地 FP32 vs Galaxy S24 NPU 推理] |
上排(从左到右)依次是验证集原图(256×256 人像照片)、人工标注的人像/背景二值掩膜、本地 PyTorch FP32 推理结果(IoU 0.933)。下排依次是 Galaxy S24 Hexagon NPU 真机推理结果(IoU 0.935,与 FP32 几乎一致)、把 NPU 分割结果叠加到原图上模拟的背景虚化效果、FP32 与 NPU 的差异热力图(仅在人像边缘有 64 个像素差异)。
整理为验证维度对照:
| 验证维度 | 结果 | 判定 |
| 分割精度 | IoU > 0.93 | PASS(背景虚化可用阈值 > 0.85) |
| 云端–端侧一致性 | 99.6% 像素一致 | PASS(无功能性差异) |
| 推理延迟 | 13.59 ms(INT8) | PASS(满足 30 fps 需求) |
| 边缘质量 | 人像轮廓清晰完整 | PASS(可直接用于背景虚化) |
这张可视化图直观证明了端到端链路的有效性:SageMaker AI 训练的模型在 Galaxy S24 的 Hexagon NPU 上跑出了与开发环境一致的结果;人像边缘清晰,分割质量足以支撑实时背景虚化;整个验证过程不需要采购物理设备。
下表汇总了本次端到端流程中可以核对的工件:
| 阶段 | 工件 | 关键数值 |
| SageMaker AI 训练 | best.pt / portrait_seg.onnx | IoU 0.888,训练耗时 260 s |
| 本地复核 | 验证集推理 | FP32 IoU 0.932(20 张抽样) |
| AI Hub Compile | portrait_seg_s24.tflite | 大小 4.5 MB |
| AI Hub Inference | 真机输出张量 | logit-PSNR -21.74 dB(应改用掩膜 IoU 评估) |
| AI Hub Profile | 性能报告 | 推理延迟 13.59 ms,峰值内存 175.5 MB |
| 端到端时间 | 数据准备到生成 .tflite | 约 20 分钟 |
| AWS 侧成本 | ml.g5.2xlarge + S3 | 约 USD $0.12 / 次 |
五、工程实践要点
手机平台之间的性能差异必须用真机数据评估。 即便采用同代 Hexagon NPU,Galaxy S24 与 Galaxy S25、车载 SA8775P 之间的延迟也会因为热管理和功耗预算不同而相差数倍。AI Hub 的多设备 Profile 让你只更换 device 参数就能拿到多款机型的真机数据,不必为每款目标硬件单独搭测试架。
INT8 量化对边缘细节的影响要单独验证。 INT8 量化对边缘细节的影响要单独验证。 AI Hub 自动算的 PSNR 是数值保真度指标,对图像超分、去噪、HDR 等输出范围有界([0,1] 或 [0,255])的任务,PSNR > 30 dB 是常用的快速门槛;但对本文这类直接输出 logit 的分割模型,logit 的大动态范围会把量化误差在 PSNR 公式里放大,得到的负值(如本文 -21.74 dB)并不反映真实分割质量。因此分割任务应当跳过 PSNR 门槛,直接用真机推理结果在验证集上计算 sigmoid 后的掩膜 IoU、Dice 或边缘 F-score(本文 NPU 真机 IoU 0.9347,与 FP32 基线 0.9326 基本一致)。如果量化让边缘明显抖动,可在 Compile 阶段保留少量算子走 FP16,或改用量化感知训练(Quantization-Aware Training,QAT)重新走一次链路。
从公开数据集到产品图像的迁移。 公开数据集让链路可复现,但每家厂商的相机色彩、镜头畸变、低光降噪都不一样。一旦接入产品图像,建议保留公开数据训练得到的 backbone 权重作为热启动,再在产品数据上做二次微调。
六、清理资源
为减少持续产生的费用,演示完成后请按以下顺序清理资源。
1. 如果训练后部署了任何 SageMaker AI Endpoint,先删除:
2. 清空不再需要的 S3 数据:
3. 如果通过 AWS Secrets Manager 管理 AI Hub API Token,删除对应密钥。
4. AI Hub 上的 Job 记录默认保留,可在 Dashboard 上手动删除。
七、总结
Amazon SageMaker AI 与 Qualcomm AI Hub 联合形成了一条从云端训练、端侧编译、真机验证到设备部署的端到端链路。SageMaker AI 提供按需扩展的分布式训练能力,AI Hub 把跨芯片编译、量化与真机性能 / 精度验证封装成云端 API。两者打通后,端侧 AI 项目的核心工程步骤可以在一个 Jupyter Notebook 内完成,并平滑地嵌入团队既有的 CI/CD 系统。
文章用一个手机端实时人像分割的小例子展示了完整步骤:基于 Hugging Face 公开数据集,在 SageMaker AI 上 4.3 分钟完成微调(IoU 0.888),再通过 AI Hub 在真实 Galaxy S24 上拿到 13.59 ms 的真机延迟和 4.5 MB 的部署产物,端到端工作流 20 分钟跑完。同样的架构模式可以应用到 OCR、关键词唤醒、AR 目标检测、低光照增强、端侧 LLM 等场景:替换数据集与基模型后,多数情况下云端到端侧的主体路径仍然适用,只需根据具体模型结构调整量化策略、目标设备与延迟预算。
➡️ 下一步行动:
相关产品:
- Amazon SageMaker — 适用于所有数据、分析和 AI 的中心
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon IAM — 身份管理和访问权限
- Amazon CloudFront — 全球内容分发网络
- Amazon Secrets Manager — 密钥管理
相关文章:
- 从IDC到云上GPU:基于 Amazon EKS 的大模型推理混合云弹性部署实践
- 短剧视频字幕位置自动识别:OpenCV + Amazon Nova 2 Lite 混合方案
- Code系列的多架构容器镜像构建流水线
- SageMaker Hyperpod Cluster部署whisper模型
八、下一步
如果希望复现本文流程,可以按下面的顺序操作:
- 准备 AWS 账户与 IAM 角色,开通 ml.g5.2xlarge 训练实例配额。
- 在 [aihub.qualcomm.com](https://aihub.qualcomm.com) 注册 AI Hub 账户,安装 qai-hub 并配置 API Token。
- 拉取一份公开数据集(例如 mattmdjaga/human_parsing_dataset),按本文第 2 步预处理并上传到 Amazon S3。
- 用本文第 3 步的训练脚本启动 SageMaker AI 训练作业,得到 PyTorch 与 ONNX 产物。
- 用本文第 6 步的 AI Hub API 在 Galaxy S24 等目标设备上完成编译、推理校验与性能分析。
- 把 .tflite 产物集成到你的移动 App 或边缘网关里。
九、参考文档
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
