亚马逊AWS官方博客
AWS Glue Data Catalog 现在支持自动压缩 Apache Iceberg 表
我们今天为 AWS Glue Data Catalog 推出一项新功能,它允许以 Apache Iceberg 格式自动压缩事务表。您可以借助该功能始终使您的事务数据湖表处于高性能状态。
刚开始设计数据湖的初衷主要是为了以较低成本存储大量原始、非结构化和半结构化数据,而且它们通常与大数据和分析使用案例相关。但随着时间的推移,由于组织意识到将数据湖用于除报告以外其他用途的潜力,数据湖的可能用例的数量不断增加,这要求加入事务功能以确保数据一致性。
另外,数据湖也在数据质量、治理与合规方面发挥关键作用,尤其当考虑到数据湖要存储越来越多的关键业务数据,常常需要对其进行更新或删除时。数据驱动型组织还需要让自己的后端分析系统和客户应用程序保持近乎实时的同步。这种情况要求您的数据湖上的事务功能支持并发读写,而不牺牲数据的完整性。最后,数据湖现在充当集成点,需要事务才能在不同来源之间安全而可靠地移动数据。
为了支持数据湖表上的事务语义,组织采用了一种开放式表格式(OTF),例如 Apache Iceberg。采用 OTF 格式自带一系列挑战:它要求将现有数据湖表格式从 Parquet 或 Avro 转换成 OTF 格式;因每个事务会在 Amazon Simple Storage Service(Amazon S3)上生成一个新文件而需要管理大量小文件;或者要大规模管理对象或元数据版本控制,而这些只是其中一部分。组织一般会构建并管理自己的数据管道来克服这些挑战,从而增加基础设施方面的无差别工作。您需要编写代码,部署 Spark 集群来运行您的代码,扩展集群,管理错误,等等。
通过与我们的客户进行交流,我们了解到最具挑战性的工作是把每次在表上写入事务时所产生的单独小文件压缩成为几个大文件。大文件的读取和扫描速度更快,让您可以更快速执行分析作业和查询。压缩会使用较大型文件优化表存储。它会将表存储从大量小文件改为少量大文件。它会降低元数据开销,缩短到 S3 的网络往返行程并提高性能。当您使用会对计算收费的引擎时,性能提升还有助于降低这项费用,因为运行查询所需的计算容量将会变小。
但构建用于压缩和优化 Iceberg 表的自定义管道既费时,而且成本昂贵。您必须管理规划、预置基础设施,并且安排与监控压缩作业。正因为如此,我们在今天推出自动压缩功能。
下面我们来看看它的工作原理
为了向您展示如何启用与监控 Iceberg 表的自动压缩,我会从 AWS 管理控制台的 AWS Lake Formation 页或 AWS Glue 页开始操作。我现在有一个包含表的 Iceberg 格式数据库。我会用几天时间在这个表上执行事务,该表开始在底层 S3 桶上产生小文件片段。

我会选择想在哪个表上启用压缩,然后选择启用压缩。
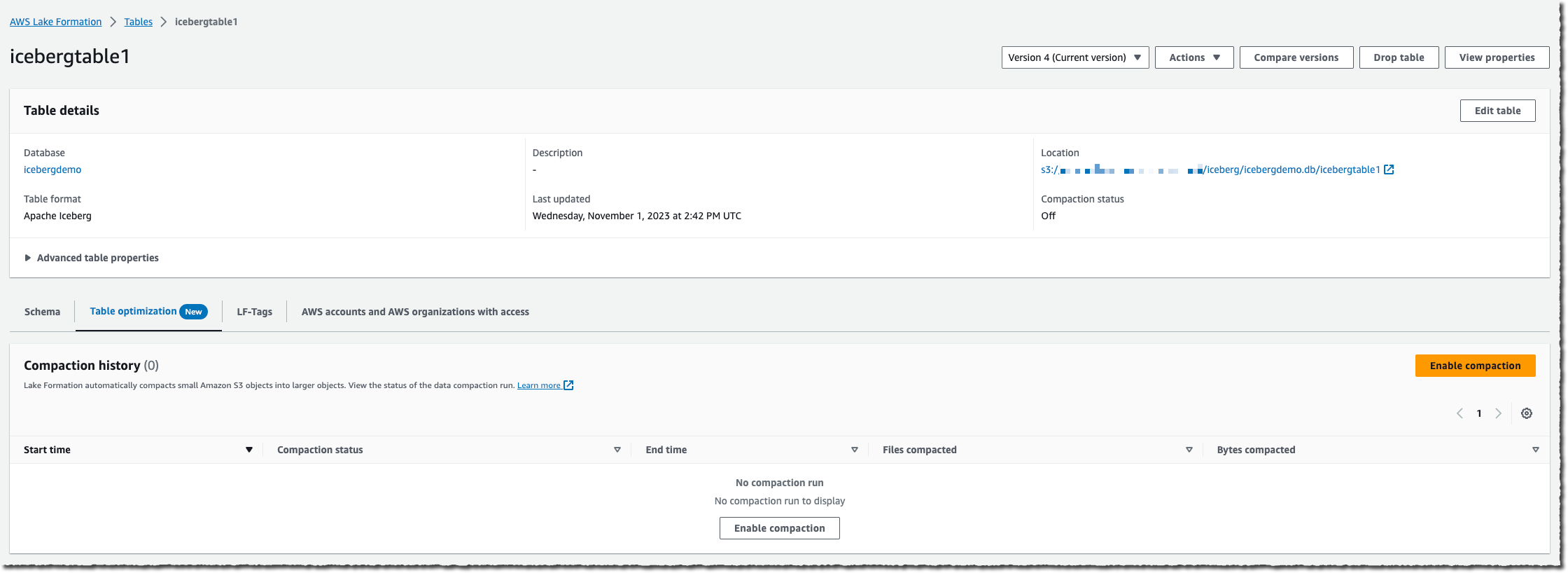
在向 Lake Formation 服务传递权限时需要用到一个 IAM 角色,才能访问我的 AWS Glue 表、S3 桶以及 CloudWatch 日志流。我会创建一个新的 IAM 角色,或选择一个现有角色。您的现有角色必须对表有 lakeformation:GetDataAccess 和 glue:UpdateTable 权限。该角色还需要 logs:CreateLogGroup、logs:CreateLogStream、logs:PutLogEvents,才能执行 “arn:aws:logs:*:your_account_id:log-group:/aws-lakeformation-acceleration/compaction/logs:*“。角色的受信任权限服务名称必须被设为 glue.amazonaws.com。
然后,选择开启压缩。好了! 压缩会自动执行;您不需要做任何管理工作。
服务会开始测量表的变化率。由于 Iceberg 表可能有多个分区,服务会计算每个分区的此项变化率,并且在此项变化率超过某个阈值时安排托管作业,以便对分区进行压缩。
当表的变化累积到较高水平时,您将可以在控制台中优化选项卡的下方查看压缩历史。
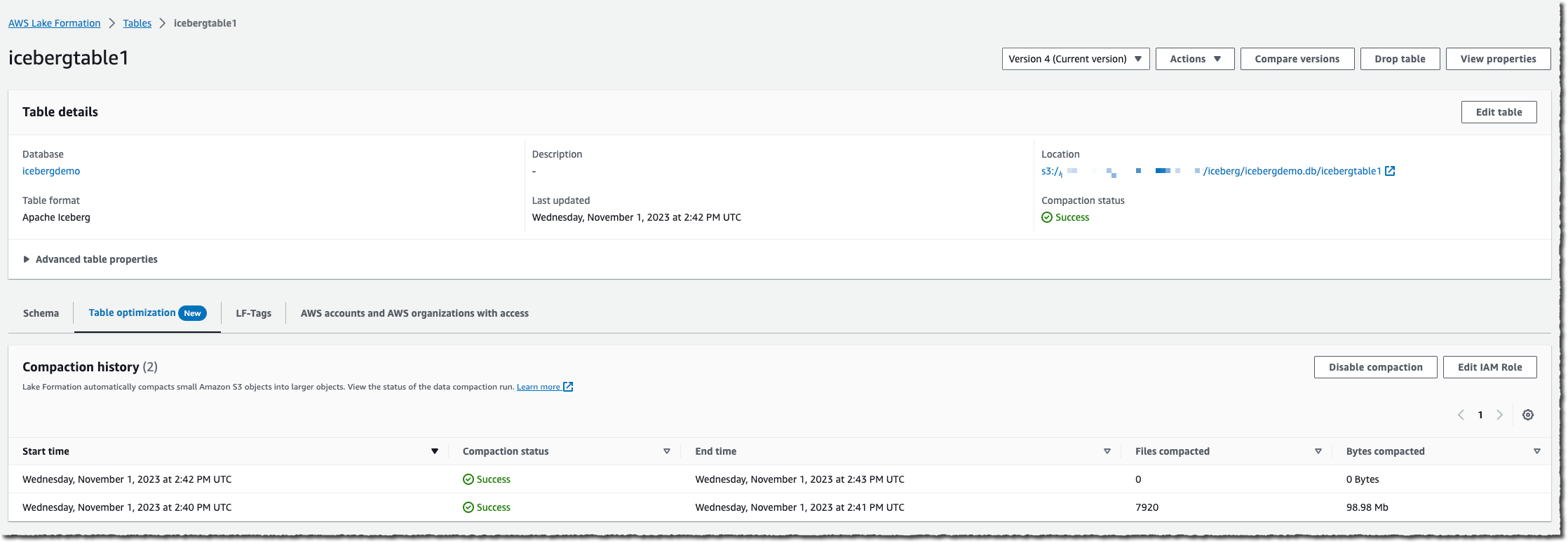
您还可以通过观察 S3 桶上的文件数量(使用 NumberOfObjects 指标)或两项新 Lake Formation 指标中的一项(numberOfBytesCompacted 或 numberOfFilesCompacted),来监控整个过程。
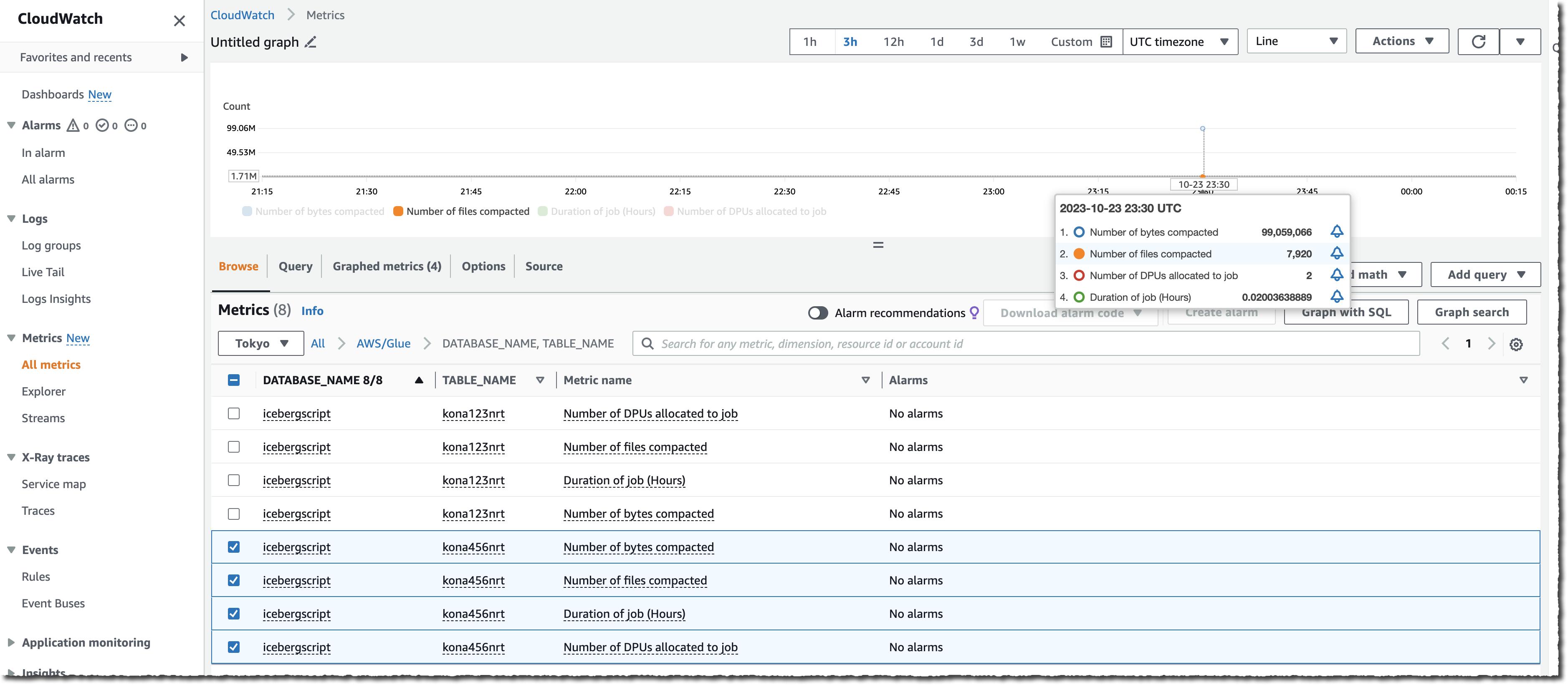
除 AWS 管理控制台以外,您还可以使用六项新的 API 来公开该新功能:CreateTableOptimizer、BatchGetTableOptimizer、UpdateTableOptimizer、DeleteTableOptimizer、GetTableOptimizer 和 ListTableOptimizerRuns。AWS SDK 和 AWS 命令行界面(AWS CLI)均提供这些 API。和平时一样,别忘了将 SDK 或 CLI 更新到最新版本,以访问这些新的 API。
注意事项
随着今天这项新功能的推出,我还想与您补充分享几点:
- 压缩不会合并删除文件。含有已删除数据的表会被压缩,但如果数据文件有与之相关的删除文件,它们将被跳过。
- 配置为从 VPC 独占访问 VPC 端点的 S3 桶不受支持。
- 使用 Apache Parquet 存储数据的 Apache Iceberg 表可被压缩。
- 压缩适用于使用默认服务器端加密(SSE-S3)的桶,以及通过 KMS 托管密钥进行服务器端加密(SSE-KMS)的桶
可用性
从今天开始,在所有提供 AWS Glue Data Catalog 的 AWS 区域均可使用这项新功能。
定价指标为数据处理单元(DPU),它是处理能力的相对度量,由 4 个具有计算能力的 vCPU 和 16 GB 内存组成。每个 DPU/小时按秒计费,从一分钟起步。
现在就停用您的现有压缩数据管道,改用这项完全托管的新功能吧。