摘要:在智能建筑和物业管理领域,IoT 设备的稳定运行对业务连续性至关重要。物业公司通常通过 IoT 平台管理大楼的设施设备,实时采集并记录设备报送的各类指标数据(如温度、湿度、压力等)。然而,设备离线、网络故障、平台问题等异常情况时有发生,传统的监控方式往往只能提供统计图表,关联分析比较困难,难以快速定位问题根源,影响了问题发现和处理的效率。本文以某客户智能建筑管理场景为例,介绍如何利用亚马逊云科技的无服务器(Serverless)来构建一套近实时(分钟级)的 IoT 设备异常检测系统,实现从数据采集、实时分析到告警的全流程自动化,面对大量 IoT 设备数据能够在数分钟内识别出设备的异常,为物业企业提供可靠的设备监控能力。
一、引言
在智能建筑和物业管理领域,IoT设备的稳定运行对业务连续性至关重要。物业公司通常通过IoT平台管理大楼的设施设备,实时采集并记录设备报送的各类指标数据(如温度、湿度、压力等)。然而,设备离线、网络故障、平台问题等异常情况时有发生,传统的监控方式往往只能提供统计图表,关联分析比较困难,难以快速定位问题根源,影响了问题发现和处理的效率。
本文以某客户智能建筑管理场景为例,介绍如何利用亚马逊云科技的无服务器(Serverless)来构建一套近实时(分钟级)的IoT设备异常检测系统,实现从数据采集、实时分析到告警的全流程自动化,面对大量IoT设备数据能够在数分钟内识别出设备的异常,为物业企业提供可靠的设备监控能力。
二、业务背景和挑战
客户已经有自建的IoT接入平台,完成了设备的系统化对接,IoT平台基于设备心跳的周期(大多数为5分钟)通过是否收到设备心跳信号来判定设备的在线或离线状态。设备不定期的上报设备指标数据到IoT平台。IoT平台提供MQTT协议供上层应用使用设备数据。例如如下是该客户设备IoT平台通过MQTT协议提供的设备相关数据的消息格式示例:
设备状态消息:
Topic: /device/{项目编码}/{区域}/{楼层}/{房间}/{系统}/{类别}/{productId}/{设备码}/[online|offline]
示例: /device/002/0000/000/0000/07/01/0701003-0718/0001/offline
设备指标数据:
Topic: {项目编码}/{区域}/{楼层}/{房间}/{系统}/{类别}/{productId}/{设备码}
示例: 002/0000/000/0000/06/01/0601001-MINIMONOSPACE/142U
数据Payload示例: { "deviceId": "00284L4XHV5Y8T0601001142U", "messageType": "REPORT_PROPERTY", "state": { "reported": { "temperature": 25.5, "humidity": 60, ... } }, "timestamp": 1766743982151 }
在客户的IoT设备管理场景中,其面临的挑战如下:
- 1. 人工进行异常识别:设备数量较多而且设备经常更新,设备状态和数据异常可能源于网络故障、设备故障、平台问题等多种原因,由于成本和自身IT评估其开发周期长等原因,其IoT平台尚处于设备基础管理阶段,对设备的异常依靠人工判定然后进行常处理。
- 2. 误报频繁:设备实际在线但平台显示离线的情况比较普遍,导致维保人员收到大量无效的设备离线告警,甚至有些商业体的维保人员因此而要求关闭告警邮件通知。
- 3. 批量故障定位慢:对项目级(指商业地产运营项目,例如某商业广场包括多栋大厦、底商等)网络问题导致大量设备同时离线,难以快速识别。
- 4. 告警风暴:同一个设备如果已经检测到异常,在收到新的心跳或指标数据之前,会产生重复告警,造成浪费并影响工作效率。
- 5. 成本控制:需要在实时性和成本之间找到平衡点,既要保证异常检测的及时性,又要控制使用成本。
三、解决方案架构
3.1 整体架构设计
我们采用亚马逊科技Serverless架构构建分钟级的近实时异常检测系统,充分利用相关服务的弹性、可靠性和成本效益,满足客户在数据量存在波动情况下的性能需求、能够在几分钟内识别出异常提高效率、并且易于快速开发实现。系统架构如下:
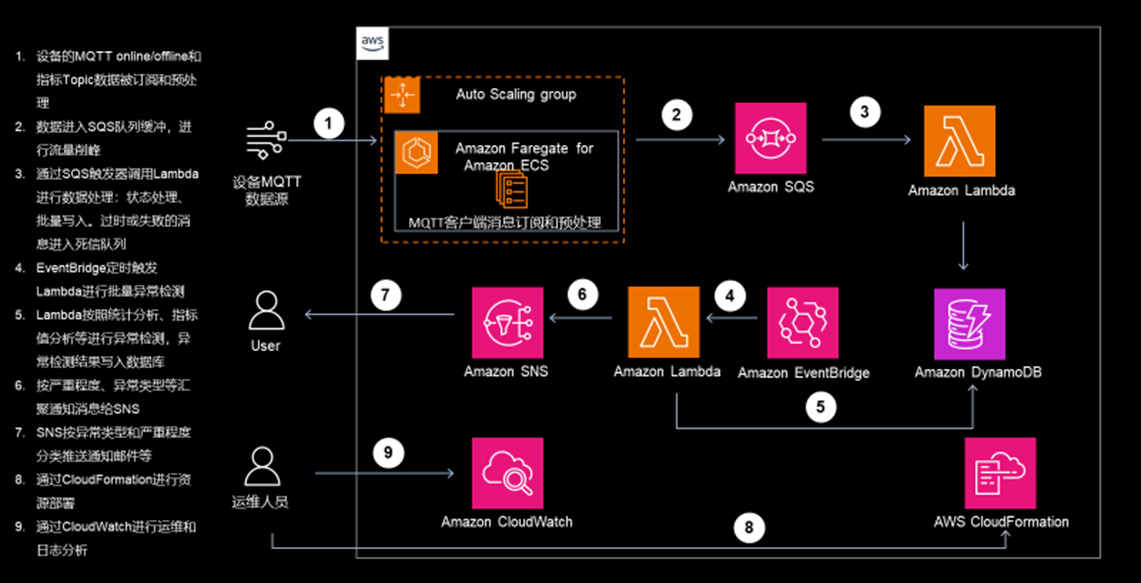
[图1] |
3.2 挑战应对的思路
针对客户面临的挑战,从业务和技术相结合、技术服务业务需求的角度,在架构设计和构建过程中应对思路如下:
- 1. 采用全自动化的流程来识别异常,通过Amazon Lambda将人工的异常检测校验沉淀到算法中,并且在设备类型变化、新发现异常出现时能够快速的修改或增加处理而不影响其他部分。
- 2. 将IoT平台的实时设备状态数据,除了存储实时数据外,通过Amazon Lambda维护设备的最新状态(在/离线)记录,以设备状态判定时间窗口(例如该客户大部分设备都为5分钟)为参照,将离线信号时点前后共两个时间窗口内的设备指标数据纳入计算,可以快速识别IoT平台的离线误判,让业务人员只需关注真实有问题的设备。最新状态的维护可以加速平台误判这类异常的判定效率并减少大多数异常场景下对Amazon DynamoDB数据库的读写数据量。
- 3. 对每个设备的异常真实性判定后存储在Amazon DynamoDB数据库中,按照设备的相互关系,对异常的设备进行分析,识别局部大量设备批量异常的情形,为后续异常的根因判断提供依据、为快速异常处理提供更高效的支撑。
- 4. 通过将异常按类型、严重程度等进行合并后一起发送告警信息,并且通过去重判定、基于异常记录自动过期(通过设置数据库记录TTL)和online状态自动消除异常等设计,减少告警数量,防止告警风暴,让业务人员更聚焦。
- 5. 充分利用亚马逊云科技的特性实现在各种数据量下的高性能、扩展性等需求,使用告警、监控等服务减少开发工作量、加快上市时间。在成本上,选用Serverless服务满足高性能要求的同时按需支付费用。在业务实时性和综合成本的平衡设计上,主要包括:使用Amazon Fargate for Amazon ECS容器化部署 MQTT 客户端,实现长连接消息订阅,这样无需管理服务器并可以自动扩展、满足高可用性要求,而且根据使用量按需付费;使用Amazon SQS(Simple Queue Service)作为消息缓冲层,解耦数据采集和处理,利用其高可用性和弹性扩展能力,并且利用其死信队列机制应对超时和异常等情形;使用Amazon Lambda这一无服务器计算,按需执行数据处理和异常检测,按照业务量按实际使用付费和自动扩展,降低使用成本;使用Amazon DynamoDB NoSQL数据库来存储设备状态、指标数据和异常事件,利用其毫秒级响应和自动扩展能力,按需计费,通过创建支持全局二级索引(GSI)、设置TTL自动清理等提高数据存储性价比;通过Amazon SNS(Simple Notification Service)进行消息推送,其支持多渠道告警通知,包括邮件、短信、HTTP/HTTPS等多种通知方式,使用该服务无需另外构建告警通知模块;使用Amazon EventBridge作为事件调度服务,实现定时批量检测,其是Serverless事件总线,支持灵活的调度规则,在本系统中配置其默认每5分钟触发进行批量检测,在实时性和成本之间平衡。
四、解决方案构建参考
除去上述挑战应对之外,在实际实施中,还需满足扩展性,例如客户按照运营的商业项目试点后逐步推广因此需要支持项目的灵活配置。系统构建后,监控和运维也是生产环境必不可少的。因此,在业务实现层面,下面着重就数据采集、数据存储、异常检测和防重复告警机制进行展开说明。在实施和运维层面,将该客户构建中的资源部署和告警、运维等配置也做简要说明,以供参考。
4.1 数据采集
4.1.1 项目的动态主题订阅
客户逐步的接入旗下的商业地产项目,系统需支持灵活的项目配置管理,避免将过多的项目设备信息数据都接入到异常检测系统中徒增系统压力并造成存储、网络等费用的浪费,因此,通过项目配置来实现动态主题订阅:
单项目监控:
monitored_projects: ['002']
生成主题: [
‘/device/102/+/+/+/+/+/+/+/+’,
‘102/+/+/+/+/+/+/+’
]
多项目监控:
monitored_projects: ['002', '003', '004']
订阅时为每个项目生成对应的订阅主题。
4.1.2 大量MQTT数据的接收和存储
系统通过Amazon Fargate for ECS容器化部署 MQTT 客户端,实现长连接消息订阅和mqtts连接时的Token验证、重连、数据格式校验等处理。初始启动可以配置:0.25 vCPU、512MB 内存,单任务运行,自动重启机制。
系统使用MQTTS协议(MQTT over TLS)确保数据传输安全:
# MQTT配置参数
BROKER = "mqtts://exsample.com.cn"
PORT = 1883
KEEPALIVE = 60 # 心跳间隔
QOS = 1 # 确保消息至少传递一次
系统通过Amazon SQS(Simple Queue Service)作为消息缓冲层,解耦数据采集和处理。提供高可用性和弹性扩展能力,利用其死信队列机制,并且通过设置其批处理大小为10,可见性超时300秒,消息保留14天等来降低其使用成本。
系统通过Amazon Lambda无服务器计算,按需执行数据批量写入数据库(数据写入函数),按实际使用付费,自动扩展,降低运维成本。
4.2 数据存储
根据数据的特性,数据存储采用Amazon DynamoDB NoSQL数据库,存储设备状态、指标数据和异常事件等数据。充分利用其对全局二级索引(GSI)、TTL自动清理的支持,较好的适配业务场景。
4.2.1 Amazon DynamoDB表设计
系统使用5个Amazon DynamoDB表实现数据管理,充分利用DynamoDB的高性能和灵活性:
表1:设备状态表(iot-device-status)
# 主键设计
- 分区键(Partition Key):device_id
- 排序键(Sort Key):timestamp
# 全局二级索引(GSI)
- project-timestamp-index:支持项目级查询
- 分区键:project_id
- 排序键:timestamp
- message-type-timestamp-index:支持按消息类型查询
- 分区键:message_type
- 排序键:timestamp
# 存储内容
- 设备在线/离线消息
- 消息时间戳
- 项目编码
- 设备元数据
表2:设备指标表(iot-device-metrics)
# 主键设计
- 分区键:device_id
- 排序键:timestamp
# GSI
- project-timestamp-index:支持项目级指标查询
# 存储内容
- 设备上报的指标数据(温度、湿度、压力等)
- 上报时间戳
- 项目编码
表3:异常事件表(iot-anomaly-events)
# 主键设计
- 分区键:event_id(格式:{device_id}_{timestamp})
- 排序键:created_at
# GSI
- device-created-index:支持按设备查询历史异常
- 分区键:device_id
- 排序键:created_at
# 存储内容
- 异常类型(DEVICE_TRULY_OFFLINE、FALSE_OFFLINE_ALERT等)
- 严重程度(CRITICAL、HIGH、MEDIUM、LOW)
- 异常描述
- 检测时间
- 相关设备信息
# TTL配置
- 自动清理30天前的异常记录
表4:设备异常状态表(iot-device-anomaly-status)
# 主键设计
- 分区键:device_id
# GSI
- project-index:支持项目级异常状态查询
# 用途
- 防止重复告警
- 记录设备当前异常状态
- 跟踪异常首次检测时间和最后更新时间
# TTL配置
- 自动清理7天前的异常状态记录
表5:项目配置表(iot-project-config)
# 主键设计
- 分区键:config_key
# 存储内容
- 监控项目列表(monitored_projects)
- 心跳时间窗口(HEARTBEAT_WINDOW_MINUTES)
- 批量检测倍数因子(BATCH_DETECTION_MULTIPLIER)
- 其他系统配置参数
# 特点
- 支持动态配置更新
- 配置变更无需重启服务
- 带缓存机制(5分钟TTL)
4.2.2 数据写入优化
系统采用批量写入策略提高性能:
# Lambda函数:批量数据写入
class DataWriteHandler:
def __init__(self):
self.dynamodb = boto3.resource('dynamodb')
self.status_table = self.dynamodb.Table('iot-device-status')
self.metrics_table = self.dynamodb.Table('iot-device-metrics')
def lambda_handler(self, event, context):
"""批量处理SQS消息"""
status_items = []
metrics_items = []
# 解析SQS批量消息(每批最多10条)
for record in event['Records']:
message = json.loads(record['body'])
if self.is_status_message(message):
status_items.append(self.format_status_item(message))
else:
metrics_items.append(self.format_metrics_item(message))
# 批量写入DynamoDB(使用batch_writer)
if status_items:
self.batch_write_status(status_items)
if metrics_items:
self.batch_write_metrics(metrics_items)
def batch_write_status(self, items):
"""批量写入设备状态(每批最多25条)"""
with self.status_table.batch_writer() as batch:
for item in items:
batch.put_item(Item=item)
4.3 异常检测
4.3.1 异常识别逻辑
系统按照异常检测的难易程度,本次先实现了4种核心异常检测场景,每种场景都有明确的检测逻辑和业务含义便于快速实现和检验:
场景1:设备真离线(DEVICE_TRULY_OFFLINE)
如果某设备被平台判定为离线,而且在其前后的时间间隔中也没有任何指标数据,则可以判定设备是真实离线的。
# 检测逻辑
- 收到离线消息
- 离线前5分钟有指标数据
- 离线后5分钟无指标数据
# 严重程度
- HIGH:离线消息次数 ≥ 3次
- MEDIUM:离线消息次数 < 3次
# 业务含义
设备确实断开连接,需要现场检查设备状态或网络连接
# 示例
设备在10:00收到离线消息
检查9:55-10:00有指标数据 ✓
检查10:00-10:05无指标数据 ✓
判定:设备真离线
场景2:离线消息误判(FALSE_OFFLINE_ALERT)
以大多数设备按照5分钟时间间隔报送心跳信号为例,超过该时间没有心跳信号,那么如果收到该设备的指标数据,则可以初步判定为是平台对离线消息有误判,应识别该场景并指导平台修正。
# 检测逻辑
- 收到离线消息
- 离线消息时间窗口内(前后5分钟)仍有指标数据上报
# 严重程度
- LOW
# 业务含义
平台误判,设备实际在线,可能是心跳包丢失或平台判断逻辑问题
# 示例
设备在10:00收到离线消息
检查9:55-10:05期间有指标数据 ✓
判定:离线消息误判
场景3:潜在设备平台问题(POTENTIAL_PLATFORM_ISSUE)
如果某设备最后状态为在线也在期间内没有任何指标数据,则可以判定平台可能存在潜在问题。
# 检测逻辑
- 设备最后状态为在线
- 但在检测时间窗口内(5分钟)无任何指标数据上报
# 严重程度
- MEDIUM
# 业务含义
可能存在平台数据采集问题或消息队列阻塞
# 示例
设备最后状态:ONLINE(10:00)
当前时间:10:10
检查10:05-10:10无指标数据 ✓
未收到离线消息 ✓
判定:潜在平台问题
场景4:项目区域网络问题(PROJECT_NETWORK_ISSUE)
如果某项目下时间窗口内出现大量设备离线并且同时这些设备也没有任何指标数据,则可以判定该项目平台与设备之间存在网络问题。
# 检测逻辑
- 项目下大量设备(≥5个)同时离线
- 离线设备比例 ≥ 30%
- 离线且无数据设备比例 ≥ 25%
- 时间窗口内这些设备都无指标数据
# 严重程度
- CRITICAL
# 业务含义
项目级网络故障,需要紧急处理,可能影响整个项目的设备通信
# 示例
项目002共有20个设备
时间窗口内8个设备离线(40%)
其中7个设备无指标数据(35%)
判定:项目网络问题
4.3.2 批量检测机制
为了平衡实时性和成本,系统采用时间分段批量检测策略:
配置参数:
# 可配置参数
HEARTBEAT_WINDOW_MINUTES = 5 # 设备状态判定时间窗口(设备心跳时间窗口)
BATCH_DETECTION_MULTIPLIER = 1 # 批量检测倍数因子(n≥1)
BATCH_DETECTION_INTERVAL = HEARTBEAT_WINDOW_MINUTES × BATCH_DETECTION_MULTIPLIER
# 默认配置:5分钟间隔
# 推荐配置:
# - n=1(5分钟):实时性要求高的场景
# - n=2(10分钟):平衡方案
# - n=3(15分钟):成本敏感场景
使用批量检测的成本对比分析:
假设每小时1000个离线事件,则
1)事件驱动方案(实时检测)
Lambda调用次数 = 1000次/小时 × 24小时 × 2(检测+延迟验证)
= 48,000次/天
2)批量检测方案(5分钟间隔)
Lambda调用次数 = 12次/小时 × 24小时
= 288次/天
可以发现在Lamdba调用上成本降低:99.4%
因此,批量检测流程可以设计如下:
class BatchAnomalyDetectorLambda:
def lambda_handler(self, event, context):
"""批量异常检测主函数"""
# 1. 获取当前检测时间窗口
current_time = int(datetime.now().timestamp() * 1000)
window_start = current_time - (BATCH_INTERVAL_MINUTES * 60 * 1000)
# 2. 获取监控项目列表(支持动态配置)
monitored_projects = self.project_config_manager.get_monitored_projects()
# 3. 获取时间窗口内的所有离线事件
offline_events = self.get_offline_events_in_window(
window_start, current_time, monitored_projects
)
# 4. 获取时间窗口内的所有新数据(用于检查设备恢复)
all_new_data = self.get_all_new_data_in_window(
window_start, current_time, monitored_projects
)
# 5. 批量检查设备恢复状态
self.anomaly_status_manager.batch_check_recovery(all_new_data)
# 6. 批量检测新异常
anomalies = self.batch_detect_anomalies(offline_events)
# 7. 过滤重复告警
filtered_anomalies = self.filter_duplicate_alerts(anomalies)
# 8. 批量保存异常结果和更新状态
if filtered_anomalies:
self.batch_save_anomalies_with_status(filtered_anomalies)
# 9. 批量发送告警(仅发送HIGH和CRITICAL级别)
critical_anomalies = [
a for a in filtered_anomalies
if a['severity'] in ['HIGH', 'CRITICAL']
]
if critical_anomalies:
self.batch_send_alerts(critical_anomalies)
return {
'statusCode': 200,
'processed_events': len(offline_events),
'detected_anomalies': len(anomalies),
'filtered_anomalies': len(filtered_anomalies)
}
4.4 告警机制
系统基于设备异常状态表,通过防重复告警、自动恢复、告警合并等实现告警管理,避免告警风暴:
4.4.1 防重复告警逻辑
class DeviceAnomalyStatusManager:
def should_send_alert(self, device_id, new_anomaly):
"""判断是否应该发送告警"""
# 1. 检查设备当前异常状态
current_status = self.check_device_anomaly_status(device_id)
# 2. 没有异常状态记录,可以发送告警
if not current_status:
return True
# 3. 设备已恢复,可以发送新的告警
if current_status.get('anomaly_type') == 'RECOVERED':
return True
# 4. 相同类型异常,跳过重复告警
if current_status.get('anomaly_type') == new_anomaly['anomaly_type']:
logger.info(f"设备 {device_id} 异常 {new_anomaly['anomaly_type']} 已存在,跳过重复告警")
return False
# 5. 不同类型异常,发送告警
return True
def update_device_anomaly_status(self, device_id, anomaly_info):
"""更新设备异常状态"""
# 设置TTL(7天后自动清理)
ttl = int((datetime.now() + timedelta(days=7)).timestamp())
self.status_table.put_item(
Item={
'device_id': device_id,
'project_id': self.extract_project_id(device_id),
'anomaly_type': anomaly_info['anomaly_type'],
'severity': anomaly_info['severity'],
'first_detected_at': anomaly_info['timestamp'],
'last_updated_at': int(datetime.now().timestamp() * 1000),
'alert_sent': True,
'description': anomaly_info['description'],
'ttl': ttl
}
)
4.4.2 自动恢复检测
当设备收到新的online消息或指标数据时,系统自动清除异常状态:
def check_device_recovery(self, device_id, new_data_type, timestamp):
"""检查设备是否从异常中恢复"""
current_status = self.check_device_anomaly_status(device_id)
if not current_status or current_status.get('anomaly_type') == 'RECOVERED':
return # 没有异常或已恢复
# 根据新数据类型判断是否恢复
recovery_conditions = {
'DEVICE_TRULY_OFFLINE': ['ONLINE', 'REPORT_PROPERTY'],
'FALSE_OFFLINE_ALERT': ['ONLINE'],
'POTENTIAL_PLATFORM_ISSUE': ['REPORT_PROPERTY'],
'PROJECT_NETWORK_ISSUE': ['ONLINE', 'REPORT_PROPERTY']
}
anomaly_type = current_status.get('anomaly_type')
if anomaly_type in recovery_conditions:
if new_data_type in recovery_conditions[anomaly_type]:
# 设备已恢复,清除异常状态
self.clear_device_anomaly_status(
device_id,
f"收到{new_data_type}消息"
)
# 可选:发送恢复通知
self.send_recovery_notification(device_id, current_status, new_data_type)
4.4.3 告警合并策略
对于批量异常,系统采用告警合并策略,避免告警风暴:
def batch_send_alerts(self, critical_anomalies):
"""批量发送告警(合并相似告警)"""
# 创建告警汇总
alert_summary = {
'alert_time': datetime.now().isoformat(),
'total_anomalies': len(critical_anomalies),
'anomaly_types': {},
'affected_devices': [],
'critical_issues': []
}
for anomaly in critical_anomalies:
# 统计异常类型
anomaly_type = anomaly['anomaly_type']
if anomaly_type not in alert_summary['anomaly_types']:
alert_summary['anomaly_types'][anomaly_type] = 0
alert_summary['anomaly_types'][anomaly_type] += 1
# 收集受影响设备
if 'device_id' in anomaly:
alert_summary['affected_devices'].append(anomaly['device_id'])
# 收集关键问题
if anomaly['severity'] == 'CRITICAL':
alert_summary['critical_issues'].append(anomaly['description'])
# 发送汇总告警
self.sns.publish(
TopicArn=self.SNS_TOPIC_ARN,
Message=json.dumps(alert_summary, ensure_ascii=False),
Subject=f"IoT设备批量异常告警 - 检测到{len(critical_anomalies)}个严重异常"
)
4.5 系统资源的部署和配置
在系统开发完成后,要进行部署和配置后才能运行。本架构基于Serverless,通过Amazon CloudFormation进行部署后,只需进行SNS订阅即可完成整个部署。
4.5.1 Amazon CloudFormation部署参考
系统使用Amazon CloudFormation实现基础设施即代码(IaC)的部署,如下是客户案例中使用到的亚马逊云科技服务的资源部署配置,可供参考。
AWSTemplateFormatVersion: '2010-09-09'
Description: 'IoT异常检测系统 - 资源部署'
Resources:
# 1. DynamoDB表(5个)
DeviceStatusTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: iot-anomaly-detection-device-status
BillingMode: PAY_PER_REQUEST # 按需计费
AttributeDefinitions:
- AttributeName: device_id
AttributeType: S
- AttributeName: timestamp
AttributeType: N
- AttributeName: project_id
AttributeType: S
- AttributeName: message_type
AttributeType: S
KeySchema:
- AttributeName: device_id
KeyType: HASH
- AttributeName: timestamp
KeyType: RANGE
GlobalSecondaryIndexes:
- IndexName: project-timestamp-index
KeySchema:
- AttributeName: project_id
KeyType: HASH
- AttributeName: timestamp
KeyType: RANGE
Projection:
ProjectionType: ALL
- IndexName: message-type-timestamp-index
KeySchema:
- AttributeName: message_type
KeyType: HASH
- AttributeName: timestamp
KeyType: RANGE
Projection:
ProjectionType: ALL
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
TimeToLiveSpecification:
AttributeName: ttl
Enabled: true
# 2. Lambda函数 - 数据写入
DataWriterFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: iot-anomaly-detection-data-writer
Runtime: python3.9
Handler: index.lambda_handler
MemorySize: 256
Timeout: 60
Role: !GetAtt LambdaExecutionRole.Arn
Environment:
Variables:
DEVICE_STATUS_TABLE: !Ref DeviceStatusTable
DEVICE_METRICS_TABLE: !Ref DeviceMetricsTable
# 3. Lambda函数 - 批量检测
BatchDetectorFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: iot-anomaly-detection-batch-detector
Runtime: python3.9
Handler: index.lambda_handler
MemorySize: 512
Timeout: 300
Role: !GetAtt LambdaExecutionRole.Arn
Environment:
Variables:
HEARTBEAT_WINDOW_MINUTES: 5
BATCH_DETECTION_MULTIPLIER: 1
SNS_TOPIC_ARN: !Ref AnomalyAlertsTopic
# 4. SQS队列(2个主队列 + 2个死信队列)
DeviceStatusQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: iot-anomaly-detection-device-status-queue
VisibilityTimeout: 300
MessageRetentionPeriod: 1209600 # 14天
RedrivePolicy:
deadLetterTargetArn: !GetAtt DeviceStatusDLQ.Arn
maxReceiveCount: 3
DeviceStatusDLQ:
Type: AWS::SQS::Queue
Properties:
QueueName: iot-anomaly-detection-device-status-dlq
MessageRetentionPeriod: 1209600
# 5. SNS主题
AnomalyAlertsTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: iot-anomaly-detection-anomaly-alerts
DisplayName: IoT设备异常告警
# 6. EventBridge调度规则
BatchDetectionSchedule:
Type: AWS::Events::Rule
Properties:
Name: iot-anomaly-detection-batch-detection-schedule
Description: 批量异常检测定时任务
ScheduleExpression: rate(5 minutes)
State: ENABLED
Targets:
- Arn: !GetAtt BatchDetectorFunction.Arn
Id: BatchDetectorTarget
# 7. IAM角色
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws-cn:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: DynamoDBAccess
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Query
- dynamodb:Scan
- dynamodb:BatchWriteItem
Resource: '*'
- PolicyName: SNSPublish
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- sns:Publish
Resource: !Ref AnomalyAlertsTopic
Outputs:
DeviceStatusTableName:
Description: 设备状态表名称
Value: !Ref DeviceStatusTable
DeviceStatusQueueUrl:
Description: 设备状态队列URL
Value: !Ref DeviceStatusQueue
AnomalyAlertsTopicArn:
Description: 异常告警主题ARN
Value: !Ref AnomalyAlertsTopic
BatchDetectorFunctionArn:
Description: 批量检测函数ARN
Value: !GetAtt BatchDetectorFunction.Arn
4.5.2 配置SNS告警订阅
部署完成后,需要配置告警邮箱订阅,如下是参考步骤。
1. 订阅SNS主题,如下是使用aws cli命令进行配置的参考:
aws sns subscribe \
--topic-arn arn:aws-cn:sns:cn-northwest-1:123456789012:iot-anomaly-detection-anomaly-alerts \
--protocol email \
--notification-endpoint admin@example.com \
--profile cn \
--region cn-northwest-1
其中123456789012应替换为您的账户ID。
2. 确认订阅:检查邮箱中的确认邮件,点击确认链接激活订阅。如下示例:
[图2] |
4.6系统的监控与运维
4.6.1 系统监控
系统集成Amazon CloudWatch实现对Amazon Lambda、Amazon ECS、告警等的监控。其中业务服务的监控指标和CloudWatch告警配置如下可供参考。
# Lambda函数监控
- 执行时间(Duration)
- 错误率(Errors)
- 调用次数(Invocations)
- 并发执行数(ConcurrentExecutions)
- 限流次数(Throttles)
# DynamoDB监控
- 读写容量使用率(ConsumedReadCapacityUnits/ConsumedWriteCapacityUnits)
- 限流请求数(UserErrors)
- 系统错误数(SystemErrors)
- 表大小(TableSize)
# SQS监控
- 队列深度(ApproximateNumberOfMessagesVisible)
- 消息年龄(ApproximateAgeOfOldestMessage)
- 死信队列消息数(ApproximateNumberOfMessagesVisible in DLQ)
# 业务指标
- 异常检测准确率
- 告警发送成功率
- 设备在线率
- 项目级异常频率
# 告警规则示例
# 告警规则示例
CLOUDWATCH_ALARMS = {
'lambda_error_rate': {
'metric': 'Errors',
'threshold': 5, # 错误率 > 5%
'evaluation_periods': 2,
'action': 'SNS通知运维团队'
},
'dynamodb_throttle': {
'metric': 'UserErrors',
'threshold': 10, # 限流次数 > 10
'evaluation_periods': 1,
'action': '自动扩容或告警'
},
'sqs_dlq_messages': {
'metric': 'ApproximateNumberOfMessagesVisible',
'threshold': 10, # 死信队列消息 > 10
'evaluation_periods': 1,
'action': '紧急告警'
},
'batch_anomaly_count': {
'metric': 'AnomalyCount',
'threshold': 100, # 单次检测异常 > 100
'evaluation_periods': 1,
'action': '项目级告警'
}
}
4.6.2 日志管理
配置结构化日志,有利于日志查询和分析。下面提供本设计使用的结构化日志和查询使用示例。
import structlog
# 配置结构化日志
logger = structlog.get_logger()
# 日志示例
logger.info(
"batch_detection_completed",
batch_interval_minutes=5,
monitored_projects=['102'],
processed_events=150,
detected_anomalies=12,
filtered_anomalies=8,
execution_time_ms=45000
)
# 输出格式(JSON)
{
"event": "batch_detection_completed",
"batch_interval_minutes": 5,
"monitored_projects": ["002"],
"processed_events": 150,
"detected_anomalies": 12,
"filtered_anomalies": 8,
"execution_time_ms": 45000,
"timestamp": "2026-02-11T10:30:00.000Z",
"level": "info"
}
- 1. 日志查询:如下是通过aws cli进行查询,以及在CloudWatch Insights查询日志的语句参考:
# 查看Lambda函数日志
aws logs tail /aws/lambda/iot-anomaly-detection-batch-detector \
--follow \
--profile cn \
--region cn-northwest-1
# 查询特定时间范围的错误日志
aws logs filter-log-events \
--log-group-name /aws/lambda/iot-anomaly-detection-batch-detector \
--start-time $(date -d '1 hour ago' +%s)000 \
--filter-pattern "ERROR" \
--profile cn \
--region cn-northwest-1
# 使用CloudWatch Insights查询
# 查询最近1小时检测到的异常数量
fields @timestamp, detected_anomalies
| filter event = "batch_detection_completed"
| stats sum(detected_anomalies) as total_anomalies by bin(5m)
五、解决方案的运行效果
如下图所示,是某项目在一段时间内运行后记录的异常检测结果的导出记录。在构建实施后,实现了全自动化的设备异常检测和告警,识别出了IoT平台的离线误报和批量离线异常等异常场景。系统按照设计识别到规划的各类异常,在<=11分钟内(设备状态判定时间窗口为5分钟)识别出所有异常,然后批量告警通知业务人员。
系统在增加项目配置数量或者数据量波动时都能自动扩缩容以满足波动和扩展的需求。在新异常场景出现时,既可以通过在现有Amazon Lambda增加处理逻辑,也可以通过增加新的Amazon Lambda由Amazon Bridge进行触发来扩展,具备异常监测更多业务场景的扩展性。设备指标数据、异常数据等在达到设置的TTL时间后自动删除,数据存储按照业务的数据量动态而且自洽的进行管理、无需人工进行数据清理、同时避免无用数据存储导致的成本浪费。

[图3] |
六、总结
本文介绍了如何利用无服务器构建分钟级的近实时IoT设备异常检测系统,并且设计无需绑定具体的IoT平台。通过Serverless架构、批量处理机制、告警机制设计等手段,将问题发现时间从事后的小时级缩短到分钟级、大幅缩短异常识别时间,而且让业务人员能够更有效的关注在真实异常的处理上,兼顾业务实时性和成本使其可落地。希望本文的实践经验能为您的IoT设备异常检测提供参考和启发。
不过,本方案也存在着一些不足之处,例如缺乏基于历史数据的检测阈值优化,未实现设备异常的根因分析,未实现通过异常趋势进行预测以便从事中提前到事前预警,这些将在未来持续优化,并迭代到后面的版本中。
➡️ 下一步行动:
相关产品:
相关文章:
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |