亚马逊AWS官方博客
使用 Amazon Athena、Amazon EMR 和 AWS Glue 构建 Apache Iceberg 数据湖
大多数企业将其关键数据存储在数据湖中,您可以将来自各种来源的数据存储到集中存储中。数据由专门的大数据计算引擎处理,例如用于交互式查询的 Amazon Athena、用于 Apache Spark 应用程序的 Amazon EMR、用于机器学习的 Amazon SageMaker 和用于数据可视化的 Amazon QuickSight。
Apache Iceberg 是一种用于存储在数据湖中的数据的开源表格式。它针对 Amazon Simple Storage Service(Amazon S3)云对象存储中的数据访问模式进行了优化。Iceberg 帮助数据工程师应对数据湖中的复杂挑战,例如管理不断演变的数据集,同时保持查询性能。Iceberg 允许您执行以下操作:
- 保持事务一致性,可以通过完全的读隔离和多次并发写入,自动添加、删除或修改文件
- 实施完整的模式演变,以便随着表数据的变化处理安全的表模式更新
- 通过分区演变将表组织成灵活的分区布局,从而可以在查询和数据量更改时更新分区方案,而无需依赖物理目录
- 执行行级更新和删除操作以满足新的监管要求,例如通用数据保护条例(GDPR)
- 提供受版本控制的表并支持时间旅行查询,以查询历史数据并验证更新之间的更改
- 将表回滚到以前的版本,以便在出现任何问题时将表恢复到已知的良好状态
2021 年,AWS 团队将 Apache Iceberg 与 AWS Glue 数据目录的集成贡献给了开源,这使您能够在 AWS Glue 上使用 Apache Spark 和 Iceberg 等开源计算引擎。2022年,Amazon Athena 宣布支持 Iceberg,Amazon EMR 从 6.5.0 版本开始增加了对 Iceberg 的支持。
在这篇博文中,我们将向您展示如何使用 Amazon EMR Spark 创建 Iceberg 表、加载样书评论数据、使用 Athena 进行查询、执行模式演变、行级更新和删除以及时间旅行,所有这些都通过 AWS Glue 数据目录进行协调。
解决方案概览
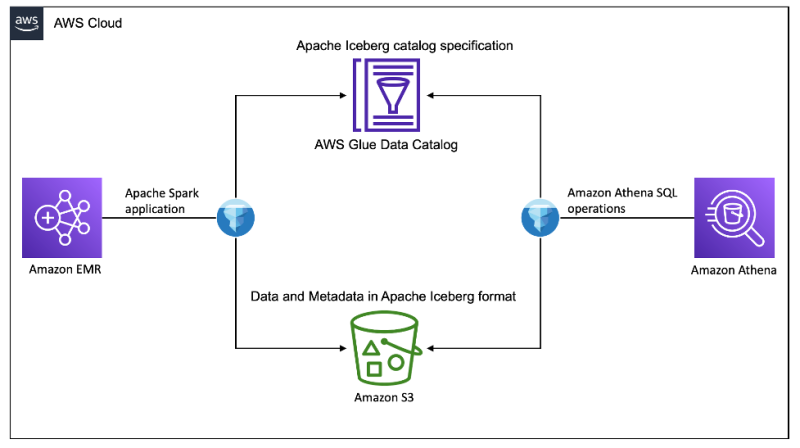
我们使用 Amazon 客户评论公共数据集作为我们的源数据。该数据集包含 Amazon S3 上采用 Apache Parquet 格式的数据文件。我们将所有与图书相关的 Amazon 评论数据加载为 Iceberg 表,以演示在原始 Parquet 文件之上使用 Iceberg 表格式的优势。下图展示了我们解决方案的架构。
要设置并测试该解决方案,我们需要完成以下高级步骤:
- 创建 S3 存储桶。
- 创建 EMR 集群。
- 创建 EMR 笔记本。
- 配置 Spark 会话。
- 将数据加载到 Iceberg 表中。
- 在 Athena 中查询数据。
- 在 Athena 中执行行级更新。
- 在 Athena 中执行模式演变。
- 在 Athena 中执行时间旅行。
- 在 Amazon EMR 和 Athena 中使用 Iceberg 数据。
先决条件
要完成本演练,您必须拥有以下账户:
- 一个 AWS 账户,其角色具有预调配所需资源的足够访问权限。
创建 S3 存储桶
要创建保存 Iceberg 数据的 S3 存储桶,请完成以下步骤:
- 在 Amazon S3 控制台的导航窗格中,选择 Buckets(存储桶)。
- 选择 Create bucket(创建存储桶)。
- 对于 Bucket name(存储桶名称),输入一个名称(对于这篇博文,我们输入
aws-lake-house-iceberg-blog-demo)。
由于 S3 存储桶名称是全局唯一的,因此请在创建存储桶时选择不同的名称。
- 对于 AWS Region(AWS 区域),选择您的首选区域(对于这篇博文,我们使用
us-east-1)。

- 完成剩余步骤以创建存储桶。
- 如果这是您首次使用 Athena 运行查询,请创建另一个全局唯一的 S3 存储桶来保存您的 Athena 查询输出。
创建 EMR 集群
现在我们已经准备好启动 EMR 集群来使用 Spark 运行 Iceberg 作业了。
- 在 Amazon EMR 控制台上,选择 Create cluster(创建集群)。
- 选择 Advanced options(高级选项)。
- 对于 Software Configuration(软件配置),选择您的 Amazon EMR 发行版本。
Iceberg 需要 6.5.0 及更高版本。
- 选择 JupyterEnterpriseGateway 和 Spark 作为要安装的软件。
- 对于 Edit software settings(编辑软件设置),选择 Enter configuration(输入配置)并输入
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]。 - 将其他设置保留为默认设置,然后选择 Next(下一步)。

- 您可以在此步骤中更改 Amazon EMR 集群使用的硬件。在此演示中,我们使用默认设置。
- 选择 Next(下一步)。
- 对于 Cluster name(集群名称),输入
Iceberg Spark Cluster(Iceberg Spark 集群)。 - 保持其余设置不变,然后选择 Next(下一步)。

- 您可以配置安全设置,例如添加 EC2 密钥对以访问您的本地 EMR 集群。在此演示中,我们使用默认设置。
- 选择 Create cluster(创建集群)。
您将被重定向到集群详细信息页面,在其中等待 EMR 集群从 Starting 转换为 Waiting。
创建 EMR 笔记本
当集群处于活动状态并处于 Waiting 状态时,我们已准备好在集群中运行 Spark 程序。在本演示中,我们使用 EMR 笔记本来运行 Spark 命令。
- 在 Amazon EMR 控制台的导航窗格中,选择 Notebooks(笔记本)。
- 选择 Create notebook(创建笔记本)。
- 对于 Notebook name(笔记本名称),输入一个名称(对于这篇博文,我们输入
iceberg-spark-notebook)。 - 对于 Cluster(集群),选择 Choose an existing cluster(选择现有集群),然后选择 Iceberg Spark Cluster(Iceberg Spark 集群)。
- 对于 AWS service role(AWS 服务角色),选择 Create a new role(创建新角色)以创建
EMR_Notebook_DefaultRole,或者选择其他角色来访问笔记本中的资源。 - 选择 Create notebook(创建笔记本)。

您将被重定向到笔记本详细信息页面。
- 选择笔记本旁边的 Open in JupyterLab(在 JupyterLab 中打开)。
- 选择创建新笔记本。
- 在 Notebook(笔记本)下,选择 Spark。

配置 Spark 会话
在您的笔记本中,运行以下代码:
这将设置以下 Spark 会话配置:
- spark.sql.catalog.demo – 注册一个名为
demo的 Spark 目录,该目录使用 Iceberg Spark 目录插件 - spark.sql.catalog.demo.catalog-impl –
demoSpark 目录使用 AWS Glue 作为物理目录来存储 Iceberg 数据库和表信息 - spark.sql.catalog.demo.warehouse –
demoSpark 目录将所有 Iceberg 元数据和数据文件存储在根路径s3://<your-iceberg-blog-demo-bucket>下 - spark.sql.extensions – 增加对 Iceberg Spark SQL 扩展的支持,它允许您运行 Iceberg Spark 程序和一些仅限 IceBerg 的 SQL 命令(您将在后面的步骤中使用此命令)
将数据加载到 Iceberg 表
在我们的 Spark 会话中,运行以下命令来加载数据:
需要使用 Iceberg 格式 v2 来支持行级更新和删除。有关更多详细信息,请参阅格式版本控制。
命令可能需要长达 15 分钟才能完成。完成后,您应该能够在 AWS Glue 控制台的 reviews 数据库下看到该表,其中 table_type 属性显示为 ICEBERG。

表模式是从 Parquet 源数据文件中推断出来的。在使用 Spark SQL、Athena SQL 或 Iceberg Java 和 Python SDK 加载数据之前,您还可以使用特定模式创建表。
在 Athena 中查询
导航到 Athena 控制台,然后选择 Query editor(查询编辑器)。 如果这是您首次使用 Athena 查询编辑器,则需要配置为使用之前创建的 S3 存储桶来存储查询结果。
book_reviews 表可供查询。运行以下查询:
以下屏幕截图显示了正在显示的表中的前五条记录。

在 Athena 中执行行级更新
在接下来的几个步骤中,我们重点关注表中评论 ID 为 RZDVOUQG1GBG7 的记录。目前,当我们运行以下查询时,没有总票数:

我们使用以下查询将 total_votes 值更新为 2:

更新命令成功运行后,运行以下查询,并记下显示总共两票的更新结果:
Athena 对 Iceberg 表的所有写入操作强制执行 ACID 事务保证。这是通过 Iceberg 格式的乐观锁规范完成的。当同时尝试更新同一记录时,会发生提交冲突。在这种情况下,Athena 会显示事务冲突错误,如以下屏幕截图所示。

删除查询的工作方式类似;有关更多详细信息,请参阅 DELETE。
在 Athena 中进行模式演变
假设该评论突然疯传,并获得 100 亿张投票:
根据 AWS Glue 表信息,total_votes 是一个整数列。如果您尝试更新 100 亿的值,该值大于允许的最大整数值,则会收到报告类型不匹配的错误。

Iceberg 支持大多数模式演变功能作为仅限元数据的操作,不需要重写表。这包括添加、删除、重命名、对列重新排序和提升列类型。要解决此问题,您可以通过运行以下 DDL 将整数列 total_votes 更改为 BIGINT 类型:
现在,您可以成功更新该值:
查询记录现在可以得到 BIGINT 中的预期结果:
在 Athena 中执行时间旅行
在 Iceberg 中,事务历史记录被保留,每次事务提交都会创建一个新版本。您可以执行时间旅行来查看表的历史版本。在 Athena 中,您可以使用以下语法前往提交第一个版本之后的某个时间:

在 Amazon EMR 和 Athena 中使用 Iceberg 数据
数据湖最重要的特点之一是不同的系统可以通过 Iceberg 开源协议无缝协同工作。在 Athena 中完成所有操作后,我们回到 Amazon EMR,确认 Amazon EMR Spark 可以使用更新的数据。
首先,运行相同的 Spark SQL,看看示例中使用的评论结果是否相同:
Spark 显示该评论的总票数为 100 亿张。

通过 Spark Iceberg 的历史系统表查看 Athena 中操作的事务历史记录:
这显示了与您在 Athena 中运行的两次更新相对应的三个事务。

Iceberg 提供了各种各样的 Spark 程序来优化表。例如,您可以运行 expire_snapshots 程序来删除旧快照并释放 Amazon S3 中的存储空间:
请注意,运行此程序后,将无法再对过期的快照执行时间旅行。
再次检查历史系统表,注意它只显示最近的快照。
在 Athena 中运行以下查询会导致错误“No table snapshot found before timestamp…(在时间戳之前找不到表快照…)”,因为较旧的快照已被删除,并且您无法再通过时间旅行访问较旧的快照:
清理
为避免产生持续成本,请完成以下步骤来清理您的资源:
- 在笔记本中运行以下代码以删除 AWS Glue 表和数据库:
- 在 Amazon EMR 控制台的导航窗格中,选择 Notebooks(笔记本)。
- 选择笔记本
iceberg-spark-notebook,然后选择 Delete(删除)。 - 在导航窗格中选择 Clusters(集群)。
- 选择集群
Iceberg Spark Cluster(Iceberg Spark 集群)并选择 Terminate(终止)。 - 删除 S3 存储桶以及您在本文的先决条件中创建的任何其他资源。
结论
在这篇博文中,我们向您展示了使用 Amazon S3、AWS Glue、Amazon EMR 和 Athena 在 AWS 上构建 Iceberg 数据湖的示例。Iceberg 表可以跨两个常用的计算引擎无缝运行,您可以利用这两个引擎来设计自定义的数据生产和消费使用案例。
借助 AWS Glue、Amazon EMR 和 Athena,您已经可以通过 AWS 集成使用许多功能,例如用于机器学习的 SageMaker Athena 集成,或用于控制面板和报告的 QuickSight Athena 集成。AWS Glue 还提供了 Iceberg 连接器,您可以使用它来创作和运行 Iceberg 数据管道。
此外,Iceberg 还支持各种其他开源计算引擎,您可以从中进行选择。例如,您可以将 Amazon EMR 上的 Apache Flink 用于流式传输和更改数据捕获(CDC)使用案例。Iceberg 提供强大的事务保证和高效的行级更新、删除、时间旅行和模式演变体验,为用户释放大数据的力量奠定了坚实的基础并提供无限可能。
关于作者
 Kishore Dhamodaran 是 AWS 的高级解决方案架构师。Kishore 利用他多年的行业和云经验,帮助战略客户制定云企业战略和迁移之旅。
Kishore Dhamodaran 是 AWS 的高级解决方案架构师。Kishore 利用他多年的行业和云经验,帮助战略客户制定云企业战略和迁移之旅。
 Jack Ye 是 Athena 数据湖和存储团队的软件工程师。他是 Apache Iceberg 委员会成员和 PMC 成员.
Jack Ye 是 Athena 数据湖和存储团队的软件工程师。他是 Apache Iceberg 委员会成员和 PMC 成员.
 Mohit Mehta 是 AWS 的首席架构师,具有 AI/ML 和数据分析方面的专业知识。他拥有 12 项 AWS 认证,热衷于帮助客户实施云企业战略以实现数字化转型。在业余时间,他为参加马拉松坚持训练,并计划徒步穿越世界各地的主要山峰。
Mohit Mehta 是 AWS 的首席架构师,具有 AI/ML 和数据分析方面的专业知识。他拥有 12 项 AWS 认证,热衷于帮助客户实施云企业战略以实现数字化转型。在业余时间,他为参加马拉松坚持训练,并计划徒步穿越世界各地的主要山峰。
 Giovanni Matteo Fumarola 是 Athena 数据湖和存储团队的工程经理。他是 Apache Hadoop 委员会成员和 PMC 成员。自 2013 年以来,他一直专注于大数据分析领域。
Giovanni Matteo Fumarola 是 Athena 数据湖和存储团队的工程经理。他是 Apache Hadoop 委员会成员和 PMC 成员。自 2013 年以来,他一直专注于大数据分析领域。
 Jared Keating 是 AWS Professional Services 的高级云顾问。Jared 凭借 20 多年的 IT 经验,为客户提供云基础设施、合规性和自动化要求方面的帮助。
Jared Keating 是 AWS Professional Services 的高级云顾问。Jared 凭借 20 多年的 IT 经验,为客户提供云基础设施、合规性和自动化要求方面的帮助。