亚马逊AWS官方博客
Data-centric AI之特征工程(第三讲)
在Data-centric AI之特征工程第二讲中,我们介绍了特征预处理的三个子步骤即样本类别不均衡处理,连续特征离散化和数值型category特征编码。今天我们接着介绍特征预处理以及特征工程的其他步骤。
特征预处理之特征缩放
当样本的不同特征的取值幅度范围具有不同量级时,数量级的差异将导致量级较大的特征占据主导地位,而特征缩放就是用来统一数据集中的特征的值的幅度变化范围的方法,主要针对的是连续特征。我们来看一下特征缩放的作用(假设两个特征的幅度变化有数量级的差别),如下图:
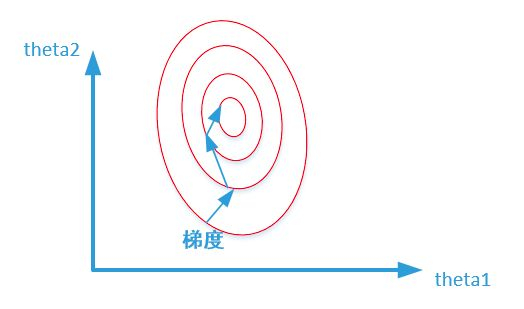 |
 |
左上图是针对两个特征并且未作特征缩放的某个模型的目标函数关于2个模型参数的等高线,右上图是做完特征缩放的。可以看出右上图最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解;也就是说做完特征缩放,梯度下降不容易震荡,能更快收敛。特征缩放的缺点是,容易让特征失真,可能丢失对训练模型一些重要的信息。
就像上面提到的特征缩放有缺点,因此先不要进行特征缩放(简单就是美,这个基本上可以认为是特征工程的通用准则,因为任何特征处理步骤都可能带入一些噪音),发现模型效果不好再尝试。如果样本的所有特征的幅度范围都具有同样的量级,先不做特征缩放。根据之后是否需要做特征降维分情况讨论,如果选择用PCA(主成分分析)做特征降维,在当前步骤只需要做中心化(即特征值减去均值作为新的特征值,因此新特征的均值为0),不做其他特征缩放,如果选择LDA(线性判别分析)做特征降维,在当前步骤即不需要做中心化也不做其他特征缩放。之后如果选择对于数据尺寸/幅度不敏感的基于tree的模型,先忽略该步骤,最后在对原特征或者特征降维后得到的新特征做特征缩放。注意,深度学习模型对特征值的尺度是比较敏感的(因为它用的是梯度下降方法来学习参数的),因此在使用深度学习模型建模的时候,特征缩放是经常需要做的。
特征缩放常用的方法:
| 方法 | 介绍 | 公式 |
| Z-score标准化 | 把特征变为均值为0,方差为1的新特征 |  |
| 对数log变换 | 相当于压缩特征值的变化范围变小(实际项目中用的很多的一种方法);相反的情况是,有些情况下某个连续特征的幅度变化很小,我们可以使用指数变换把这个幅度变化稍微放大。 |
log(x + delta) x要保证大于等于0;delta是用来做平滑的,防止x为0的时候log0变成负无穷,delta一般设置为一个很小的数,比如10的-7次方。 |
| 区间缩放(也叫归一化) | 利用两个最值(即最大值最小值)进行缩放到[0,1]区间 |  |
| 分位数规范化 | 如果训练数据中含有异常数据并且需要做规范化,可以考虑对异常数据更健壮的比如SKLearn中的RobustScaler来进行处理 |  |
实践中,经常会遇到选择标准化方法还是归一化方法的问题。如果特征稳定,不存在极端的最大值最小值,用归一化。如果特征存在异常值或者较多噪音,用标准化(它间接通过中心化来降低异常值和噪音的影响)或基于分位数的规范化,最好的方式还是线上AB test看对应的效果。
特征生成
特征生成的目的是为了把人的先验知识通过特征的方式注入模型中。特征生成可以贯穿在整个ML项目的生命周期中:最开始时候,需要从各种日志(比如用户点击日志)和数据库表(比如用户属性表和物品属性表)中抽取并加工出原始特征。接着可能需要对原始特征做数据探索或分析然后生成一些新的特征替换或追加到原始特征。在数据探索/分析之后得到的特征可能仍然很少,这个时候可以考虑增加一些新的特征。如果在模型训练后发现欠拟合,这个时候可以考虑增加一些新的特征(虽然本文中特征生成放在了特征预处理之后,但二者其实没有什么顺序依次关系)。
我们应该优先使用直接观测或收集/抽取到的特征,而不是生成特征。如果模型性能不好,再考虑特征生成。对于聚类任务,尽量少的生成特征,因为聚类没有明确目标,而生成的特征又是目的性的,所以二者有冲突。对于分类和回归任务,相对来说可以多创造一些特征,分类和回归任务的目标明确,因此可以把人工对任务的理解和知识建模为特征,有助于更好的达成目标任务。
特征生成的常用方法:
| 方法 | 介绍 | 使用时机 |
| 时间窗口内的统计特征 |
历史统计量特征:比如用户一周的点击次数,物品最近1天的点击率,用户一个月的累积消费。 统计聚合量特征:比如一周内某商品按照天计算的点击率的min,max,average。 分组统计量特征:分组统计中位数,比如所属公司职员的工资中位数;分组统计算术平均数,比如顾客平均每次的购买金额;某段时间内的分组统计众数,比如某类客户一周内购买商品类型的众数。 |
原始特征抽取时 |
| 通过特征之间的语义来进行加减乘除生成新的特征 |
特征相减:比如根据房屋的建造时间和购买时间的差来得到房屋购买时的年限;比如游戏用户logout与login的时间差是单次用户停留时长。 特征相加:比如把同一个类目的商品的销量相加得到该类目的总销量。 特征相乘:比如可以通过售价和成交率相乘来得到新的特征单次收益。 特征相除:比如可以通过点击次数和网页曝光次数相除来得到点击率(可以把点击率和点击次数一起作为特征,这样能更好的反应item的受欢迎程度) 注意:通过特征的语义创造出新的特征后,要注意把可能冗余的特征去掉,留下最有用的特征。 |
原始特征抽取时 |
| 用人类可理解的方式对已有特征进行组合或修改来得到新特征 |
比如把基于daytime时间戳的时间特征变成早晨,上午,下午,晚上这样的category特征并替换原时间特征(替换原特征);或者变成一天中24个小时的分桶离散特征(替换原特征)。 比如把经纬度2个特征转化为国家,省,市三个特征并追加(追加新特征)或者替换掉经纬度特征(替换原特征)。 比如把用户最近一次登录时间戳换算为距离当前时间点的以天为单位的时间间隔(追加新特征) |
数据探索/分析时 |
| 合并category特征的稀疏类别 | 若category特征的一些类别只有很少数量的样本,可以考虑把这些类别统一归并成一大类“Other”。有个例外是比如约会类app应用,有的“城市”比如“合肥”的样本少,如果把这些小样本的城市都合并为一个other的话,会违背了同城约会可能性更高这样的事实,这个时候可能就不要合并了。 | 数据探索/分析时 |
| 根据对业务的理解,把先验知识作为新的特征加入数据集 |
比如一些衣服会根据季节不同销量不同,那需要把季节特征加入进来。 比如用户消费水平可能对用户流失预测任务有帮助,把用户消费水平特征加入进来。 |
数据探索/分析时 |
| 通过机器学习算法或统计分析方法来构造新特征 |
比如聚类算法和主题模型来提取隐特征; 比如通过GDBT算法在每棵树的输出的叶子节点的索引来构造新特征; 比如利用统计分析方法或者机器学习方法对用户和物品分别建立画像特征。 |
特征数量不足或者模型欠拟合时 |
| 交叉特征 | SKLearn中提供PolynomialFeatures 来建立包括交叉特征的多项式特征; 有些Deep Learning模型可以用来自动生成交叉特征比如Deep & Cross network | 特征数量不足或者模型欠拟合时 |
| 使用能自动生成特征的工具比如tsfresh,featuretools 等 | 自动生成特征的工具的问题是会导致“特征爆炸”(实际项目中几乎没有见到人用这个自动生成特征的工具) | 特征数量不足或者模型欠拟合时 |
特征选择
特征选择即从给定的特征集合中选出可能的重要特征子集的过程。首先在现实任务中可能会遇到维度灾难问题,这往往是由于对高基数的category特征作了One-hot向量造成的,也可能是进行了特征交叉后导致的维度灾难,这个时候要考虑这样的两个特征交叉是否合理以及考虑利用深度学习模型来做特征交叉。如果能从中选择出重要的特征,使得后续学习过程仅仅需要在一部分特征上进行,那么维度灾难问题会大大减轻。从这个意义上讲,特征选择与特征降维有相似的动机。事实上它们是传统机器学习处理高维数据的两大主流技术。就目前来讲,在实际的ML项目中,除了在数据探索阶段会考虑特征的方差选择法,两两特征之间的相关性,特征与目标变量之间的相关性来进行可能的特征选择外,特征选择的其他方法和特征降维几乎很少用到,可能是因为实际项目中更多时候是原始特征相对比较少,高基数的category特征我们有更好的办法来处理(比如用LightGBM或者深度学习模型)。我们这里为了特征工程方法论的完整性,还是需要把特征选择和特征降维简单介绍一下,但是我们要知道在实际项目中他们不是重点。其次,去除不相关特征往往会降低学习任务的难度。
特征选择可能会降低模型的预测能力(因为被剔除的特征中可能包含了有效的信息,抛弃了这部分信息可能会一定程度上降低预测准确率),这是计算复杂度和预测能力之间的折衷。
使用特征选择的流程:

特征选择方法(除了方差选择法,这里提到的其他方法都是对于有label的数据进行的):
| 方法 | 介绍 |
| Filter method(过滤法) |
按照发散性或者相关性对各个特征进行评分,设定阈值来选择特征。 计算特征本身的统计信息,比如利用方差选择法(它只适合连续特征); 计算单个特征与目标变量之间的相关性,比如使用Pearson相关系数法,卡方检验法或者互信息法。 |
| Wrapper method(包裹法) |
利用机器学习模型来进行多轮训练,选出最优特征子集。 比如使用递归式特征消除算法RFE, 它使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干不重要的特征,再基于新的特征集进行下一轮训练; 比如LVM(Las Vegas Wrapper)算法,它使用随机策略来进行子集搜索,并以最终学习器的误差作为特征子集的评价标准。 |
| Embedded method(嵌入法) |
先使用某个机器学习模型进行训练,根据训练完得到的特征的重要性或权重来选择特征。 比如基于L1正则的特征选择(因为L1正则倾向于把权重变为0); 比如基于tree算法的特征选择。 |
Filter方法与Wrapper方法的区别在于Filter方法不考虑后续的学习器,而Wrapper方法直接把最终将要使用的学习器的性能作为特征子集的评价准则,其目的就是为给定学习器选择最有利于其性能且量身定做的特征子集。Wrapper方法优点是由于直接针对特定学习器进行优化,从最终学习器性能来看比filter方法更好,缺点是需要多次训练学习器,因此计算开销通常比filter方法大得多。
在Wrapper方法中,用来做特征选择的机器学习模型和之后专门用来训练的机器学习模型是同一种,而在embedded方法中,用来做特征选择的机器学习模型和之后专门用来做训练的机器学习模型可以是不同的。
特征降维
到了这个步骤,如果特征维度过大,会导致计算量大,训练时间长,模型的容量太大,模型容易过拟合。这个时候要首先考虑特征维度这么高是否合理,是否是因为one-hot向量导致的,是否可以做embedding,之后在考虑降低特征维度。特征降维是有假设的,即人们观测或者收集到的数据样本虽然是高维的,但是与学习任务密切相关的也许仅仅是某个低维分布,即高维空间中的一个低维“嵌入”。当前主流的特征降维的方法都是针对连续性特征的。
关于降维的效果,没有很好的直接评价指标,通常是比较降维前后学习器的性能,如果模型性能有所提高(尤其是模型的线上效果),则认为降维可能起了作用。也可以将维数降至二维或者三维,然后通过可视化技术来判断降维效果。关于如何选择降维到多少的问题,把这个维数当作超参数来选择,根据不同的维数使用PCA降维后看学习器的性能(尤其是线上效果),性能最好的那个对应的PCA的维数可能就是应该降到的维数,或者按照保留原始信息的百分比来设置。
常见的降维方法的划分如下图:

一般情况下选择非生成式方法进行降维,在需要生成新样本的情况下,生成式方法是更好或唯一的选择。PCA是讨论的比较多的降维算法,我们下面简单介绍PCA和LDA两个算法。
PCA的原理:把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合,尽量使新的m个特征互不相关,目标是最大化投影后的方差(即样本在这个投影方向最发散)。从另外一个角度来说,目标是让重构误差最小,即从变换后的低维空间再投影回原始空间后与原始样本距离最小。PCA有两个假设,一是假设不同的特征可能包含了冗余的信息,通过线性组合原始特征,从而去掉一些冗余的或者不重要的特征,保留重要的特征;二是假设重构误差符合高斯分布(PCA并不假设数据本身符合高斯分布,为了计算方便,概率PCA是假设数据本身以及隐变量本身都是高斯分布)。PCA对训练集拟合完会生成投影矩阵,并保存训练集的每个特征的平均值,当对新的数据(包括验证集,测试集以及将来才能获得的数据)进行降维时,利用保存的每个特征的平均值来进行中心化,然后与投影矩阵运算生成降维后的结果。
LDA的原理:将带有label的数据点,通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分一簇一簇的情况,相同类别的点将会在投影后的空间中更接近。目标是使得类别内的点距离越近越好(集中),类别间的点越远越好。LDA做降维时并没有假设样本数据符合高斯分布。
PCA和LDA的相似点是两者均可以对数据进行降维,均使用了矩阵特征分解的思想,两者都只是适合线性的场景,两者都不适合对非高斯分布样本进行降维(尽管这两个算法在降维时并不假设数据本身符合高斯分布)。

PCA和LDA的不同点:
| 不同点 | PCA | LDA |
| 出发思想不同 | PCA是从特征的协方差角度出发,选择样本点投影具有最大方差的方向; | LDA是更多考虑分类标签信息,选择把类别分的最开的方向。 |
| 学习模式不同 | PCA属于无监督学习。 | LDA是一种监督式学习,本身除了可以降维外,还可以进行分类(LDA主要还是用于降维)。 |
| 降维后可用维度数量不同 | PCA最多有N维度可用(N表示降维前特征维度) | LDA降维后最多可生成C-1维子空间(C表示该分类任务的分类数量) |
总结
算法工程师在机器学习项目开发过程中,除了关注模型本身,应该花更多的时间在特征工程和样本工程上,发现线上效果不好的时候,第一时间去检查样本和特征,也就是先调样本和特征,然后在调模型,在换更复杂的模型之前,一定要先考虑特征工程是否做到位了。
Data-centric AI之特征工程到此全部介绍完毕,我们用了三讲的篇幅介绍特征工程相关的概念,特征的处理步骤以及相关的实践知识。到这里,相信聪明的你已经更加感受到特征工程的重要性了。和特征工程相对的就是样本工程,我们接下来将介绍Data-centric AI之样本工程。感谢大家的耐心阅读。