亚马逊AWS官方博客
在 Amazon EMR on Amazon EKS 上使用您的 Apache Spark 应用程序自定义和打包依赖项
上次 Amazon re:Invent 大会,我们宣布正式推出 Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS),这是面向 Amazon EMR 的新部署选项,允许客户在 Amazon EKS 上自动预置和管理 Apache Spark。
借助 Amazon EMR on EKS,客户可以将 EMR 应用程序与其他类型的应用程序部署在同一个 Amazon EKS 集群上,这样他们就可以在单个解决方案上共享资源并实现标准化,以便操作和管理所有应用程序。在 Kubernetes 上运行 Apache Spark 的客户可以迁移到 EMR on EKS,利用性能优化的运行时、面向交互式作业的 Amazon EMR Studio 集成、用于运行管道的 Apache Airflow 和 Amazon Step Functions 集成,以及用于调试的 Spark UI。
当客户提交作业时,EMR 会自动将应用程序打包到具有大数据框架的容器中,并提供用于与其他 Amazon 服务集成的预建连接器。然后,EMR 在 EKS 集群上部署应用程序并管理作业运行、日志记录和监控。如果您当前运行 Apache Spark 工作负载,并将 Amazon EKS 用于其他基于 Kubernetes 的应用程序,那么您可以使用 EMR on EKS,将这些应用程序合并到同一个 Amazon EKS 集群,从而提高资源利用率并简化基础设施管理。
运行容器化、大数据分析工作负载的开发人员表示,他们只想指向一个映像,然后运行映像。目前,EMR on EKS 会在作业提交期间动态添加外部存储的应用程序依赖项。
今天,我很高兴宣布,面向 Amazon EMR on EKS 的可自定义映像支持,允许客户修改 Docker 运行时映像,该映像使用 Apache Spark 在您的 EKS 集群上运行他们的分析应用程序。
借助自可自定义映像,您可以基于性能优化的 EMR Spark 运行时,使用您自己的持续集成 (CI) 管道创建一个包含您的应用程序及其依赖项的容器。这样可以减少映像的构建时间,有助于预测本地开发或测试的容器启动。
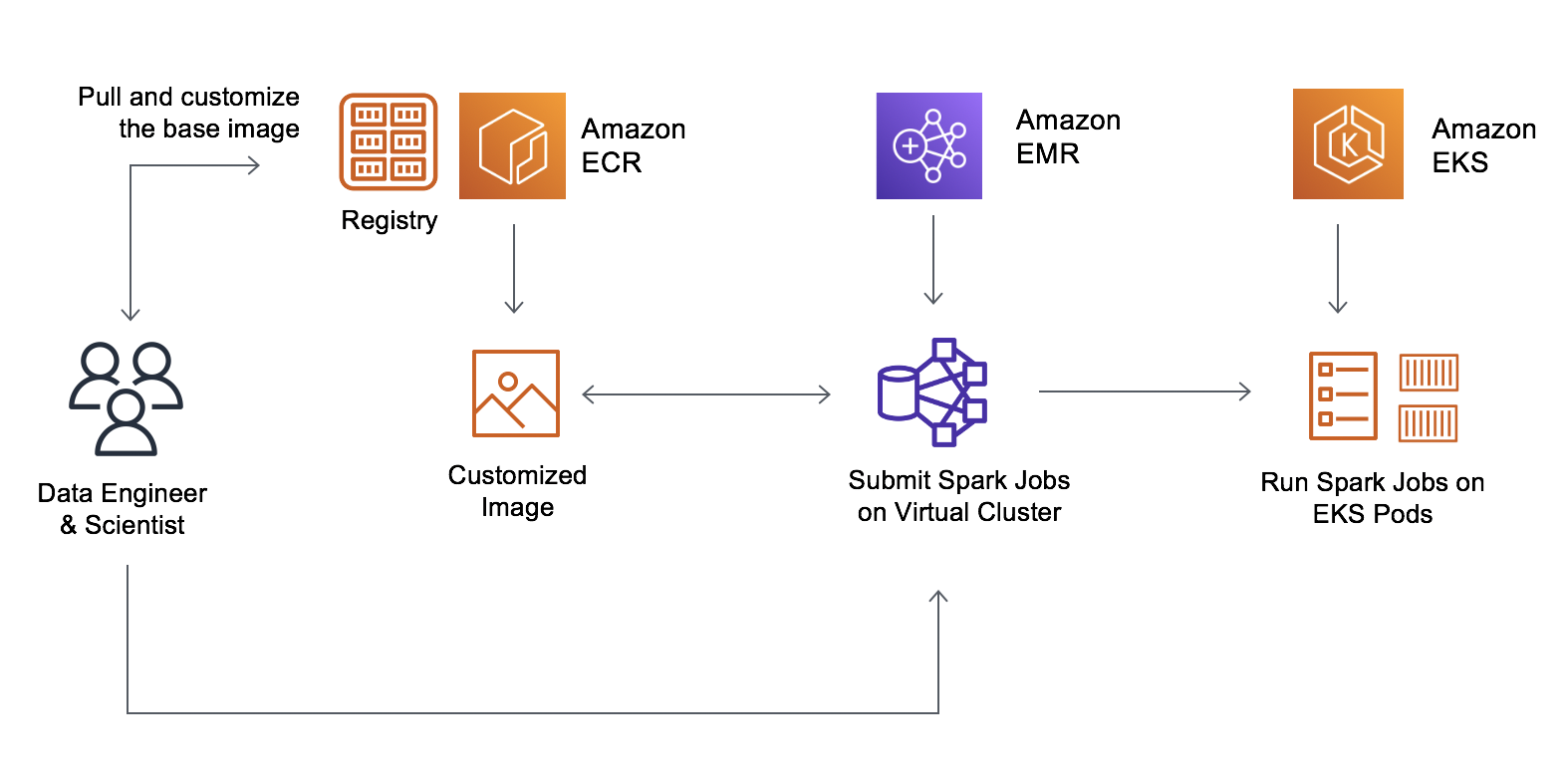
现在,数据工程师和平台团队可以创建一个基础映像、添加公司标准库,然后将其存储在 Amazon Elastic Container Registry (Amazon ECR) 中。数据科学家可以自定义映像,以包含应用程序特定的依赖项。生成的不可变化映像可以进行漏洞扫描,并可部署到测试和生产环境。开发人员现在可以轻松指向自定义映像,并在 EMR on EKS 上运行。
可自定义运行时映像 – 开始使用
要开始使用可自定义映像,请使用 Amazon Command Line Interface (AWS CLI) 执行以下步骤:
- 使用 Amazon EMR 注册您的 EKS 集群。
- 从 Amazon ECR 下载 EMR 提供的基础映像,并使用您的应用程序和库修改映像。
- 将自定义映像发布到 Docker 注册表(例如 Amazon ECR),然后在引用映像时提交作业。
您可以下载以下任一基础映像。这些映像包含 Spark 运行时,借此可以使用 EMR Jobs API 运行批处理工作负载。此处是可用的最新完整映像列表。
| 发布标签 | Spark Hadoop 版本 | 基础映像标签 |
| emr-5.32.0-latest | Spark 2.4.7 + Hadoop 2.10.1 | emr-5.32.0-20210129 |
| emr-5.33-latest | Spark 2.4.7-amzn-1 + Hadoop 2.10.1-amzn-1 | emr-5.33.0-20210323 |
| emr-6.2.0-latest | Spark 3.0.1 + Hadoop 3.2.1 | emr-6.2.0-20210129 |
| emr-6.3-latest | Spark 3.1.1-amzn-0 + Hadoop 3.2.1-amzn-3 | emr-6.3.0:latest |
这些基础映像位于每个 Amazon 区域中的 Amazon ECR 存储库,带映像 URI,该 URI 整合了 ECR 注册账户、Amazon 区域代码,以及美国东部(弗吉尼亚北部)区域的基础映像标签。
755674844232.dkr.ecr.us-east-1.amazonaws.com/spark/emr-5.32.0-20210129
现在,登录 Amazon ECR 存储库,将映像提取到本地工作区。如果您想从其他 Amazon 区域提取映像以减少网络延迟,请选择其他 ECR 存储库,该存储库与美国西部(俄勒冈)区域的映像提取位置非常接近。
$ aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 895885662937.dkr.ecr.us-west-2.amazonaws.com
$ docker pull 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129使用 EMR 提供的基础映像在本地工作区创建 Dockerfile,并添加命令以自定义映像。如果应用程序需要自定义 Java SDK、Python 或 R 库,您可以直接将它们添加到映像,就像使用其他容器化应用程序一样。
以下 Docker 命令示例面向安装 Python 实用库(例如使用 Spark 和 Pandas 的自然语言处理 [NLP])的使用案例。
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129
USER root
### 在此处添加自定义 ####
RUN pip3 install pyspark pandas spark-nlp // Install Python NLP Libraries
USER hadoop:hadoop正如我所说,在其他使用案例中,您可以安装不同版本的 Java(例如 Java 11):
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129
USER root
### 在此处添加自定义 ####
RUN yum install -y java-11-amazon-corretto // Install Java 11 and set home
ENV JAVA_HOME /usr/lib/jvm/java-11-amazon-corretto.x86_64
USER hadoop:hadoop如果您将 Java 版本更改为 11,那么您还需要更改 Spark 的 Java 虚拟机 (JVM) 选项。提交作业时,在 applicationConfiguration 中提供以下选项。您需要这些选项,因为 Java 11 不支持某些 Java 8 JVM 参数。
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.driver.defaultJavaOptions" : "
-XX:OnOutOfMemoryError='kill -9 %p' -XX:MaxHeapFreeRatio=70",
"spark.executor.defaultJavaOptions" : "
-verbose:gc -Xlog:gc*::time -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:OnOutOfMemoryError='kill -9 %p' -XX:MaxHeapFreeRatio=70
-XX:+IgnoreUnrecognizedVMOptions"
}
}
]要将自定义映像与 EMR on EKS 结合使用,请发布您的自定义映像,并使用可用 Spark 参数在 Amazon EMR on EKS 中提交 Spark 工作负载。
您可以使用自定义 Spark 映像提交批处理工作负载。要使用 StartJobRun API 或 CLI 提交批处理工作负载,请使用 spark.kubernetes.container.image 参数。
$ aws emr-containers start-job-run \
--virtual-cluster-id <enter-virtual-cluster-id> \
--name sample-job-name \
--execution-role-arn <enter-execution-role-arn> \
--release-label <base-release-label> \ # Base EMR Release Label for the custom image
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "local:///usr/lib/spark/examples/jars/spark-examples.jar",
"entryPointArguments": ["1000"],
"sparkSubmitParameters": [ "--class org.apache.spark.examples.SparkPi --conf spark.kubernetes.container.image=123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_custom"
]
}
}'使用 kubectl 命令确认作业正在运行您的自定义映像。
$ kubectl get pod -n <namespace> | grep "driver" | awk '{print $1}'
示例输出:k8dfb78cb-a2cc-4101-8837-f28befbadc92-1618856977200-driver获取 Driver pod 中主容器的映像(使用 jq)。
$ kubectl get pod/<driver-pod-name> -n <namespace> -o json | jq '.spec.containers
| .[] | select(.name=="spark-kubernetes-driver") | .image '
示例输出:123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_custom要在 Amazon EMR 控制台中查看作业,请在 EMR on EKS 下面选择 Virtual clusters (虚拟集群)。在虚拟集群列表中,选择需要查看日志的虚拟集群。在 Job runs (作业运行) 表上,选择 View logs (查看日志) 以查看作业运行的详细信息。

自动化 CI 流程和工作流
您现在可以自定义 EMR 提供的基础映像,以包含用于简化应用程序开发和管理的应用程序。借助自定义映像,您可以使用现有 CI 流程添加依赖项,从而创建包含 Spark 应用程序及其所有依赖项的单一不可变映像。
您可以应用现有开发流程,例如基于 Amazon EMR 映像的漏洞扫描。您还可以使用 EMR 验证工具验证正确的文件结构和运行时版本,该工具可以本地运行或集成到 CI 工作流。
面向 Amazon EMR on EKS 的 API 与编排服务(例如 Amazon Step Functions 和 Amazon Managed Workflows for Apache Airflow [MWAA])集成,允许您在自动化工作流中包括 EMR 自定义映像。
现已推出
您现在可以在推出 EKS 上 Amazon EMR 的所有 Amazon 区域设置可自定义映像。自定义映像不收取额外费用。要了解更多信息,请参阅 Amazon EMR on EKS 开发指南,以及观看演示视频,了解如何构建自己的映像,以便在 Amazon EMR on EKS 上运行 Spark 作业。
您可以将反馈发送到 Amazon EMR 的 Amazon 论坛,或者通过常用 Amazon 支持联系人发送反馈。
– Channy