亚马逊AWS官方博客
EKS 使用Spot 实例最佳实践
服务介绍
AWS EKS
Amazon Elastic Kubernetes Service (Amazon EKS) 是AWS 提供的托管的 Kubernetes 集群,它运行上游 Kubernetes,其 Kubernetes 一致性经过认证,以提供可预测的体验。您可以轻松地将任何标准 Kubernetes 应用程序迁移到 EKS,而无需重构您的代码。
AWS Spot 实例
Amazon EC2 Spot 实例让您可以利用 AWS 云中未使用的 EC2 容量。与按需实例的价格相比,使用 Spot 实例最高可以享受 90% 的折扣。您可以将 Spot 实例用于各种无状态、容错或者灵活的应用程序。同时它与Auto scaling 服务紧密集成,因此你可以选择如何启动和维护Spot 实例上运行的应用程序。
场景介绍
越来越多的客户利用AWS EKS 的扩展性和托管易用性,结合SPOT 实例来运行超大规模工作负载同时节省成本,我们在关注使用SPOT 实例作为EKS节点运行工作负载节省大量成本的同时,也注意到SPOT 服务因为使用的AWS 空闲资源,有一定的概率中断的特性,对工作负载的可靠性造成一定的影响,本文章将通过SPOT 的特性以及AWS 提供的一些工具和服务,来帮助用户使用更合适的方式应对该中断事件,从而缓解SPOT 中断事件对工作负载的影响。
常见方案介绍
当我们使用Spot 实例来构建我们的EKS 计算节点时,就需要考虑到中断事件带来的影响。首先,不同Spot实例的中断概率不一样,我们可以通过Spot Advisor(https://aws.amazon.com/cn/ec2/spot/instance-advisor/)选择中断概率较低的实例从而降低中断概率频次。
另外,我们有很多方法更优雅的处理中断事件。最近几年针对用户的反馈,AWS帮助用户通过新的功能更好的进行实践:
- EC2 Instance rebalance recommendation for Spot Instances(RBR): 当 Spot 实例处于中断风险较高时发送的信号,通常该信号更早于SPOT实例的中断信号发出。
- Mixed instances policy: 一个 Auto Scaling 组配置,通过在多个可用区中运行的多个实例类型之间进行部署来增强可用性
- Capacity Rebalancing for Amazon EC2 Auto Scaling: 用于主动管理 Auto Scaling 组中的 Amazon EC2 Spot 实例生命周期
- Capacity-optimized allocation strategy: designed to help find the most optimal spare capacity
- Amazon EC2 Instance Selector: 一个 CLI 工具和 go 库,它根据 vCPU 和内存等资源标准推荐实例类型
合理选择Spot资源,降低中断概率
AWS 使用nodegroup 来将Kubernetes底层的计算节点资源进行抽象定义,具体通过Autoscaling group(ASG) 组来对计算节点就行管理,所以我们就可以通过 ASG的许多特性功能对Spot进行规划管理。
选择不同的Spot资源池,降低资源回收对整体负载的影响
Spot 的中断因不同资源池资源的使用情况而决定,资源池与可用区资源,实例类型等有关。

如上图所示,当我们选择更多的实例类型和不同可用区的时候,Spot的资源池中断概率就会因为不同的资源池选择,降低整体受影响的范围,从而提升我们应用负载的可靠性。
通过ASG的Mixed instances policy 我们可以将多种资源类型提供给同一个Nodegroup使用,来满足EKS的工作负载需求。需要注意的是,通常我们会和EKS的Cluster Autoscaler(CA)组件一起使用来完成集群的动态扩缩容容,因为CA的扩展策略算法的限制,同一个Nodegroup内的所有实例类型的CPU 核数和内存必须一致。
我们可以通过Amazon EC2 Instance Selector 工具直接来查找符合结果的实例类型
例如在弗吉尼亚区域查找4GiB 内存,2vCPU,x86架构的所有实例类型:
ec2-instance-selector –memory 4 –vcpus 2 –cpu-architecture x86_64 -r us-east-1
instance selector 提供Go 的library 已经集成到EKSCTL aws官方的部署工具中,可以在定义nodegroup模版时直接指定相应的参数,会自动帮助我们筛选实例类型:
# instance-selector-cluster.yaml
—
通过ASG 支持的配置,减少中断概率
我们建议使用allocation strategies ,我们建议选择默认的capacity-optimized 策略,该策略会在不同的Spot 资源池中挑选资源最充沛的资源池给到用户使用,从而降低中断概率,如下图

同时我们建议ASG 在配置的时候选择多个可用区,进一步来利用更多的SPOT 资源池降低资源回收的影响。
需要注意的当ASG 选择多个可用区的时候,可能因为一些极少的事件触发可用区再平衡操作,例如一个可用区AZ-1a资源大量回收或发生故障,当资源重新释放的时候,ASG会尝试将其他可用区的一些计算需求平衡到该可用区AZ-1a,导致大规模集群可能发生一部分工作节点的切换,影响了负载的连续性,类似的ASG 通知事件:

针对该问题,我们的建议是:
- 如果我们的工作负载已经为了SPOT 中断事件进行了可用性的考虑和设计,我们建议保留跨AZ多可用区的ASG配置,该事件相对出现频率较低,我们可以当成Spot的一般回收事件进行处理,如果我们观察频繁发生相应的事件,并且影响到业务负载的可用性,可以设置多个ASG 并且每个ASG 只负责单可用区的扩展,该方案需要借助CA 组件的–balance-similar-node-groups 功能在扩展时尽量的平衡多个可用区之间的资源,CA配置:
- ASG 设置中可以配置On-demand 和 Spot的比例,这样可以在Spot 资源出现大量回收的时候有On-demoand 托底资源,这虽然是个好办法,但是我们更建议扩充Spot 实例类型选择来提供ASG更充沛的资源选择,而不是使用On-demand进行托底,因为在CA 进行缩容策略的时候,无法感知ASG的on-demand和Spot比例,造成缩容时候关闭了托底的on-demond实例,后续ASG需要平衡比例,进行新的切换,可能也会带来业务的短暂不稳定。
当Spot 资源回收事件发生,如何优雅的进行节点退出和切换
当Spot 指定的node回收事件发生时,我们会提前2分钟收到相应的事件,AWS 提供了相应的Termination handler 工具在收到事件后对该Node上的Pods 进行驱逐,然后通过Kubernates 自身的调度策略重新的将Pods 调度到其他节点
该方案目前在一些场景可能并不能很好的满足客户对负载可用性的需求,主要问题如下
提前2分钟的事件通知,并不足够时间对Pod进行驱逐重新分配,因为重新分配的Pod可能要等待底层新的Node ready 后才能够进行重新部署,在此期间无法使用,影响了工作负载的可靠性。
亚马逊云科技增加了新的通知事件EC2 Instance rebalance recommendation for Spot Instances (RBR),通过该事件我们可以得到以下好处:
- 更早的了解资源池情况,该事件通过亚马逊云科技后台的监控和算法结合,更早的预测到资源池的使用情况,可以更早的以事件通知的方式告知客户,客户就可以更早的对事件进行处理
- 自动的迁移方式:同时ASG 增加了Capacity Rebalancing for Amazon EC2 Auto Scaling 功能,可以在获得该事件后,自动进行Pods的迁移(通过Kubernates API 及 AWS ASG API),不需要再使用Termination handler 工具来对Pods进行迁移。
- 更优雅的进行迁移:之前使用使用Termination handler 在迁移时,Termination handler 获得通知事件后,会第一时间进行Pods驱逐,此时底层的Nodes 资源并没有准备完毕,当Nodes资源自动完毕并注册到集群后,Pods才能够顺利迁移到相应的Nodes实例上面,这个过程相对较长,主要受到节点启动时长,CA扩展策略,Pod 部署时长影响,通过Capacity Rebalancing for Amazon EC2 Auto Scaling 功能功能,会先启动新节点,当新节点ready后才会驱逐回收节点的Pods,这样在节点启动过程中,Pods并没有因为提前驱逐而影响访问,同时Pods的schedule 过程中,无需CA扩展策略的影响,直接通过Scheduler 部署,节省了不必要的时间开销。
Termination Handler vs Capacity Rebalancing for Auto Scaling 时间开销

由上图可见,通过对ASG 对RBR事件的处理,能更好的缓解Spot 实例回收带来的服务可靠性问题
使用ASG Capacity Rebalancing 方式:
- Web界面配置:ASG 中instances distribution 勾选Capacity rebalance
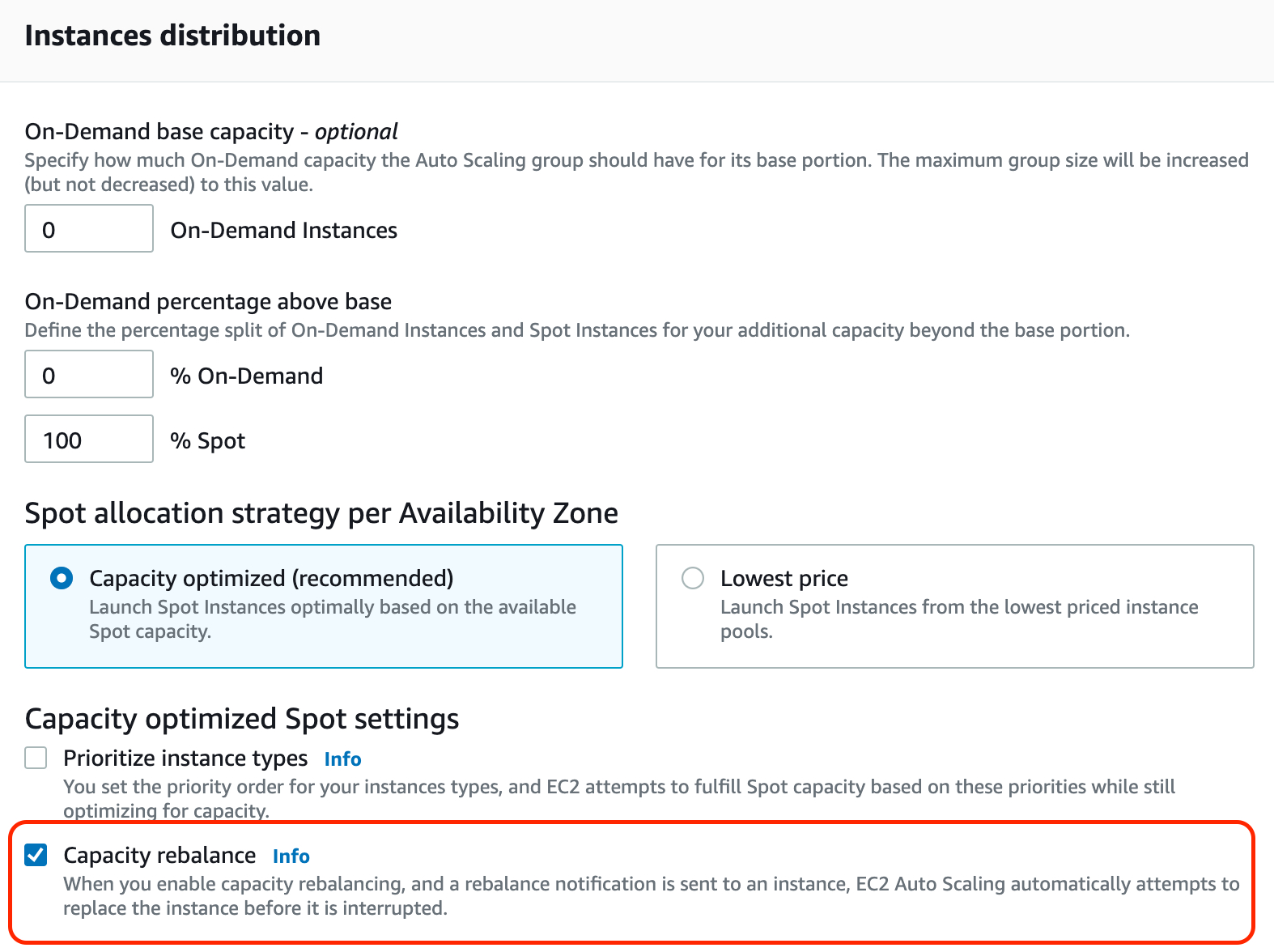
- 使用EKSCTL 模板生成NodeGroup :
*注意 目前如果使用Capacity Rebalance 调度资源建议时需要使用托管节点组,托管节点组会在节点终结前自动的调用Kubernates API对 Pod 进行调度,非托管节点组目前只能根据RBR信号创建新的节点关闭资源紧张的资源池节点,但是不能够自动调度Pod
如果我们需要在收到RBR信号后处理一些自有逻辑处理或者非托管节点组甚至自建集群是否可以使用Capacity Rebalance的功能进行优雅调度呢,其实我们可以基于Termination handler方案进行扩展,那么我们看一下Termination Handler 方案(https://github.com/aws/aws-node-termination-handler),此项目其实也在不停的迭代演进,目前已经支持支持获取RBR事件,同时之前的Terminatn handler 是基于Demonset在每个实例部署对Instance Meta service 信息进行捕获,此方案简称IMDS(Instance metadata Service),现在该方案可以使用Queue Processor的方式来捕获事件,通过Lambda或者自有逻辑模块进行事件的消费,不需要部署Demonset,同时可以在Lambda中处理更多的事件逻辑,两者总结如下:
| Feature | IMDS Processor | Queue Processor |
| K8s DaemonSet | ✅ | ❌ |
| K8s Deployment | ❌ | ✅ |
| Spot Instance Interruptions (ITN) | ✅ | ✅ |
| Scheduled Events | ✅ | ✅ |
| EC2 Instance Rebalance Recommendation | ✅ | ✅ |
| ASG Lifecycle Hooks | ❌ | ✅ |
| EC2 Status Changes | ❌ | ✅ |
目前自建集群或自建节点组可以使用该两种方式配合ASG的Capacity Rebalance 和 RBR信号进行处理
方案一. 使用IMDS processor 配合 ASG节点Capacity Rebalance 功能
目前IMDS prossor 已经可以接受RBR事件,默认只有cordon操作,禁止新的Pod调度到该节点,如果开始了ASG Capacity Rebalance功能后,可以设置Drain Pod的参数,这样会在接收到RBR信号后会第一时间驱逐Pod

如上图所示开启IMDS Processer 配合ASG节点Capacity Rebalance功能后,用户得到主要在以下两方面得到更好的优化:
- 之前驱逐节点的Pods然后kubernates进行调度和节点调度是串行事件,开启后两部分变成并行执行,可缩短Pod ready时间(取决于CA的调度参数和Pod驱逐时间,节省10秒到2分钟)
- 比SPOT中断事件拥有更长的时间处理中断事件,可以结合Pod Disruption Budget更优雅的逐步迁移负载
安装IMDS Processer 方案
方案二. 使用 Queue processor 配合ASG Capacity Rebalance 功能
IMDS 方案可能的问题是,在新的节点还没有完全Ready的时候,可能已经被IMDS processor将Pods 驱逐出旧的节点,导致出现业务的不稳定,是否在新节点启动完成后在进行Pods驱逐呢?
其实可以通过ASG Lifecycle hooks事件在旧节点关闭前,对Pods进行处理
Queue processor 相较于IMDS 方案,可以使用ASG Lifecycle hooks 来触发相应的事件。
- ASG Lifecycle hooks 是通过ASG 来管理实例节点的事件信息,并通过相应自定义动作对事件进行处理
该方案开启使用Capacity Rebalance 来进行对RBR信号的节点调度,添加一个Termination hooks 事件,当旧的节点开始关闭时,会向相应的消息队列发送相关信息,然后使用相应的模块进行资源的驱逐,当驱逐完成后,回应Hooks ,关闭节点

安装Queue processor 方案:
使用Queue Processor部署还需要部署以下组件
- ASG Termination Lifecycle Hook
- Amazon Simple Queue Service
- Amazon EventBridge Rule
- IAM role for Queue Processing Pods
部署具体步骤:
- 配置Termination Lifecycle hook:
- 创建消息队列SQS ,来监控相应的EC2和ASG的消息
- 创建相应的事件过滤规则来收集ASG 终止事件,Spot 中断,实例状态修改等事件
- 创建相应的权限
Queue Processor安装:
*注意安装的yaml文件中,需要修改创建的SQS URL
该方式是部署了相应的Pods 作为事件处理的handler 来进行事件处理,如果想部署成lambda可使用AWS node handler进行部署( https://github.com/aws-samples/amazon-k8s-node-drainer)
安装建议使用SAM 工具进行安装
其他Kubernates 功能集成使用优化手段:
- PDBs poddisruptionbudget 功能:有些服务必须保障最小的副本运行数量才能正常工作,比如3节点选举的场景,或者kubesystem的condns服务等,现在通过RBR事件可以更早的获知通知,保证Pods在保证最低副本的使用情况下,逐步迁移,命令参考:
kubectl create poddisruptionbudget <pdb name> --namespace=kube-system --selector app=<app name> --max-unavailable 1
对相应的应用,每次迁移时只驱逐1个Pod 副本,当Pod 副本迁移成功后,再逐个迁移
总结
本篇文章,帮助大家回顾了EKS集成SPOT使用方式,通过亚马逊云科技不停推出的新的工具和功能的增强,来实现Spot 使用的最佳实践,在大规模工作负载使用Spot的情况下,既有效的节约成本,又相对提升工作负载的可靠性。
参考
https://github.com/aws/aws-node-termination-handler