亚马逊AWS官方博客
使用 AWS WAF 完整日志、Amazon Athena 以及 Amazon QuickSight 实现无服务器安全分析
Original URL: https://aws.amazon.com/cn/blogs/security/enabling-serverless-security-analytics-using-aws-waf-full-logs/
在传统上,要对数据日志进行分析,我们需要首先对数据进行提取、转换与加载,而后使用多种数据仓库与商务智能工具从中提取洞见结论,同时注意维护各工具运行所处的服务器设施。
在今天的文章中,我们将向您介绍如何在无需启动任何服务器的前提下,分析AWS Web Application Firewall(AWS WAF)日志并快速构建多套仪表板。借助新的AWS WAF全日志记录功能,大家现在可以通过配置Amazon Kinesis Data Firehose将AWS WAF的全部检查流量记录至Amazon Simple Storage Service (Amazon S3)存储桶当中。在本次演练中,我们将创建一条用于发送AWS WAF全日志记录的Amazon Kinesis Data Firehose交付流,并对特定Web ACL启用AWS WAF日志记录。接下来,我们将设置一项AWS Glue爬取作业以及一张Amazon Athena表。最后,我们设置一套Amazon QuuickSight仪表板,用于实现Web应用程序的安全可视化能力。当然,大家也可以使用相同的步骤构建其他可视化功能,用以从AWS WAF规则以及遍历AWS WAF层的Web流量中提取洞见。安全与运营团队可以直接监控这些仪表板,在无需其他团队配合的前提下实现日志分析。
以下架构图,重点介绍了这套解决方案中所使用的各项AWS服务: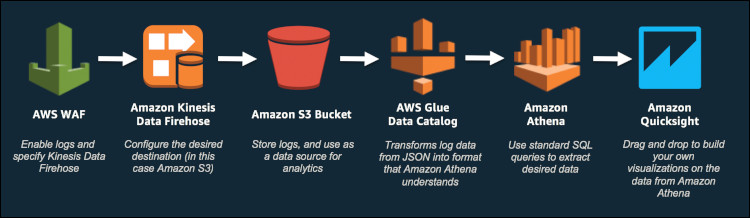
图一:架构示意图
AWS WAF是一款Web应用程序防火墙,允许用户监控访问Amazon API Gateway API、Amazon CloudFront或者应用程序负载均衡器的各类HTTP与HTTPS请求。AWS WAF还允许用户控制对内容的访问。根据您指定的条件(例如发出请求的IP地址或者查询字符串的值),API Gateway、CloudFront或者应用程序负载均衡器会使用请求的内容或HTTP 403状态码对请求做出响应(禁止)。大家还可以配置CloudFront,在请求被阻止时返回自定义错误页面。
Amazon Kinesis Data Firehose是一项全托管服务,用于向目的地(例如Amazon S3、Amazon Redshift、Amazon Elasticsearch Service以及Splunk)交付实时流式数据。使用Kinesis Data Firehose,您无需编写任何应用程序或者管理资源。您可以配置数据生产程序以将数据传递至Kinesis Data Firehose,由后者进一步完成指向特定目标的自动数据交付。您还可以配置Kinesis Data Firehose在数据实际交付之前执行数据转换操作。
AWS Glue 可用于对您的Amazon S3数据湖进行无服务器查询。AWS Glue可以对您的S3存储数据进行分类,并通过Amazon Athena与Amazon Redshift Spectrum执行进一步查询。使用爬取程序,您的元数据将与基础数据始终保持同步(后文将介绍更多关于爬取程序的详细信息)。
Amazon Athena是一项交互式查询服务,可帮助您轻松使用标准SQL直接分析在Amazon S3中的数据。Athena采用无服务器架构,因此大家只需为实际运行的查询付费,且不必管理任何基础设施。
Amazon QuickSight是一项BI分析服务,可用于构建可视化视图、执行一次性分析,并从数据当中提取商业洞见。它可以自动识别AWS数据源,也能够配合您指定的数据源一起使用。Amazon QuickSight使组织得以利用强大的内存内引擎SPICE为成千上万用户服务,提供极为强大的响应性能。
SPICE 是极快(Super-fast)、并行(Parallel)、内存内(In-memory)计算(Calculation)引擎(Engine)的缩写。SPICE支持丰富的计算功能,可帮助用户在摆脱基础设施置备或管理等繁琐工作的同时,快速通过分析得出洞见结论。SPICE还能够自动复制数据以实现高可用性,推动Amazon QuickSight面向成千上万用户进行扩展。二者相结合,即可跨越多种AWS数据源执行快速交互分析。
步骤1:设置一条新的Amazon Kinesis Data Firehose交付流
- 在AWS管理控制台中,打开 Amazon Kinesis Data Firehose服务并选择创建新流按钮。
- 在Delivery stream name字段中,为您的新流输入名称,此名称应以 aws-waf-logs- 开头,如以下截屏所示。在显示各交付流时,AWS WAF会过滤得到所有以aws-waf-logs关键字开头的流。请注意您的流名称,我们将在稍后的演练步骤中再次用到。
- 在Source部分,选择Direct PUT。这是因为本次演练将以AWS WAF日志作为数据源。


图二:选择交付流的名称与数据源
- 接下来,如果大家需要先转换数据,再将结果传输至目的地,则应选择启用AWS Lambda。(关于数据转换的更多详细信息,请参阅 Amazon Kinesis Data Firehose说明文档。) 在本次演练中,我们不需要执行任何转换,因此请在 Record transformation部分选择 Disabled。

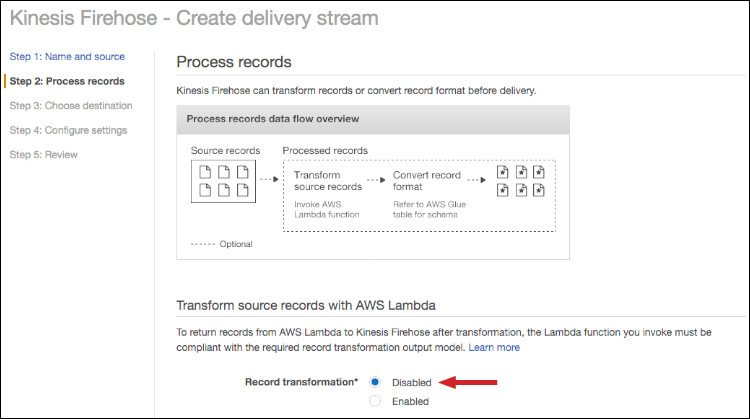
图三:在Record transformation部分选择“Disabled”
-
- 大家可以选择将JSON对象转换为Apache Parquet或者Apache ORC格式以提高查询性能。在本示例中,我们以JSON格式读取AWS WAF日志,因此在 Record format conversion部分选择Disabled。

- 大家可以选择将JSON对象转换为Apache Parquet或者Apache ORC格式以提高查询性能。在本示例中,我们以JSON格式读取AWS WAF日志,因此在 Record format conversion部分选择Disabled。

图四:选择“Disabled”,不对JSON对象进行转换
- 在Select destination页面的Destination部分,选择Amazon S3。


图五:选择传输目的地
-
- 在S3传输目的地方面,您可以输入现有S3存储桶名称,也可以创建新的S3存储桶。请记录此S3存储桶名称,我们将在演练的后续步骤中用到。
- 在Source record S3 backup部分,选择Disabled,因为本演练将把S3存储桶设定为传递目的地。

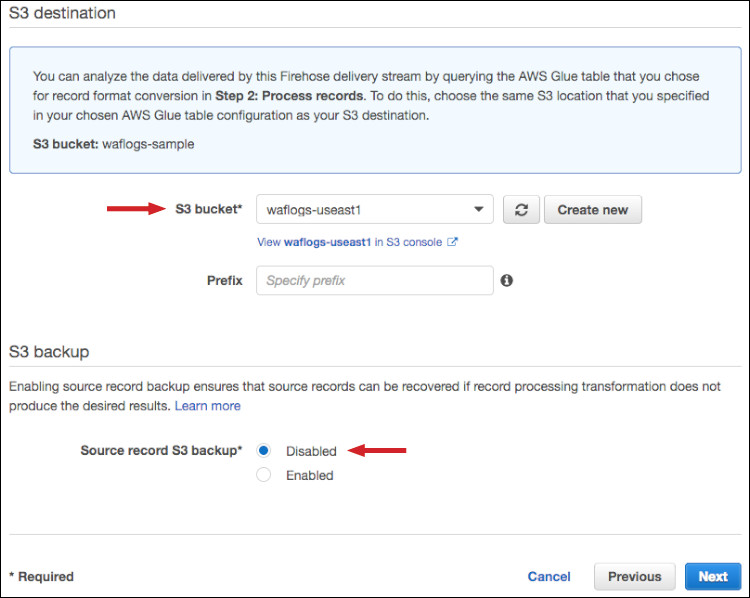
图六:输入S3存储桶名称,而后在源记录S3备份处选择“Disabled”
- 在下一步中,直接保留Buffer size, Buffer interval, S3 compression 以及 S3 encryption的默认设定。但在这里,我们建议大家将 Error logging 设置为 Enabled以进行故障排查。
- 在IAM role部分,选择Create new or choose。这将打开一个新窗口,提示您创建firehose_delivery _role,如以下截屏所示。在此窗口中选择 Allow即表示接受角色创建,这将授权Kinesis Data Firehose服务访问S3存储桶的权限。

- 在IAM role部分,选择Create new or choose。这将打开一个新窗口,提示您创建firehose_delivery _role,如以下截屏所示。在此窗口中选择 Allow即表示接受角色创建,这将授权Kinesis Data Firehose服务访问S3存储桶的权限。

图七:选择“Allow”以创建 “firehose_delivery_role” IAM角色
- 在配置的最后一步,检查之前我们选定的所有选项,而后选择 Create delivery stream。接下来,交付流状态将在Status下显示为“Creating”。几分钟之后,状态将变更为“Active”,如以下截屏所示。


Figure 8: Review the options you selected
步骤2:为特定Web ACL启用AWS WAF日志记录
- 在 AWS Management Console部分打开 AWS WAF服务,而后选择Web ACLs。打开您的Web ACL资源,该资源可被部署在CloudFront发行版或者应用程序负载均衡器当中。
- 选择要启用日志记录功能的Web ACL。(在以下截屏中,我们选择了美国东部区域的Web ACL。)
- 在 Logging选项卡上,选择 Enable Logging。


图九:选择“Enable Logging”
- 下一页中将显示所有以aws-waf-logs开头的交付流。在这里,请选择我们在演练开头处为AWS WAF日志创建的Amazon Kinesis Data Firehose交付流。 (In the screenshot below, our example stream name is 如以下截屏所示,我们的示例流名称为aws-waf-logs-us-east-1。)
- 大家还可以删除希望在日志中排除的某些特定字段。在本演练中,我们不需要选择任何排除字段。
- 选择Create。


图十:选择您的交付流,而后选择“Create”
几分钟之后,我们即可检查Kinesis Data Firehose交付流中定义的S3存储桶。日志文件将按年、月、日及小时的目录结构创建。
步骤3:设置AWS Glue爬取器以及Amazon Athena表
数据目录中爬取器的作用,在于遍历数据存储(例如Amazoon S3)并提取文件中的元数据字段。爬取器的输出将包含一个或者多个在数据目录中定义的元数据表。在爬取器运行过程中,列表中第一个成功识别您数据存储的分类器将负责为表创建schema。AWS Glue提供内置的分类器,能够将通用文件导出为JSON、CSV以及Apache Avro等多种格式。
- 在AWS Management Console当中打开AWS Glue 服务,而后选择Crawler以设置一项爬取作业。
- 选择Add crawler以启动爬取作业安装导航。在 Crawler name部分,输入一个相关名称,而后选择Next。

图十一:输入“Crawler name”,而后选择“Next”
- 在Choose a data store部分选择S3 ,并添加用于存储您AWS WAF日志的S3存储桶路径。我们已经在步骤1.3当中记录过这条路径。而后选择Next。


图十二:选择数据存储
- 您还可以选择添加其他数据存储,在本示例中直接选择No。
- 接下来,选择Create an IAM role并输入一个名称。该角色将为AWS Glue服务授予对S3存储桶的访问权限,用以访问日志文件。


图十三:选择“Create an IAM role”并输入名称
- 接下来,将频率设置为Run on demand。您也可以安排爬取器定期运行,以保证文件结构中的任何变更都及时被反映在数据目录当中。


图十四:将“Frequency”设置为“Run on demand”
- 在输出部分,请选择Athena表创建所在的数据库,并添加一条前缀以轻松识别您的表名称。选择Next。


图十五:选择数据库,而后输入前缀
- 查看您为爬取器作业选择的所有选项,而后选择 Finish按钮以完成向导。
- 现在您已经设置了爬取器作业参数,请在控制台的左侧面板上选择Crawlers以选定您的作业,而后选择 Run crawler。该作业会创建一个Amazon Athena表。持续时间取决于日志文件的实际大小。


图十六:选择“Run crawler”以创建Amazon Athena表
- 要查看由AWS Glue爬取器作业创建的Amazon Athena表,请在 AWS Management Console中打开Amazon Athena 服务。您可以根据表名称前缀进行过滤。
- 要查看数据,请选择Preview table。这将显示表数据,其中某些字段会以JSON对象结构显示数据。

- 要查看数据,请选择Preview table。这将显示表数据,其中某些字段会以JSON对象结构显示数据。
图十七:选择“Preview table”以查看数据
步骤4:使用Amazon QuickSight创建可视化结果
- 在AWS Management Console当中,打开Amazon QuickSight。
- 在Amazon QuickSight容器的左上角,选择New Analysis。选择New Data set,而后在数据源部分选择 Athena。为该数据源输入适当名称,而后选择 Create data source。


图十八:输入“Data source name”,而后选择“Create data source”
- 接下来,选择Use custom SQL以提取JSON对象中的所有字段,具体SQL查询如下:
```
with d as (select
waf.timestamp,
waf.formatversion,
waf.webaclid,
waf.terminatingruleid,
waf.terminatingruletype,
waf.action,
waf.httpsourcename,
waf.httpsourceid,
waf.HTTPREQUEST.clientip as clientip,
waf.HTTPREQUEST.country as country,
waf.HTTPREQUEST.httpMethod as httpMethod,
map_agg(f.name,f.value) as kv
from sampledb.jsonwaflogs_useast1 waf,
UNNEST(waf.httprequest.headers) as t(f)
group by 1,2,3,4,5,6,7,8,9,10,11)
select d.timestamp,
d.formatversion,
d.webaclid,
d.terminatingruleid,
d.terminatingruletype,
d.action,
d.httpsourcename,
d.httpsourceid,
d.clientip,
d.country,
d.httpMethod,
d.kv['Host'] as host,
d.kv['User-Agent'] as UA,
d.kv['Accept'] as Acc,
d.kv['Accept-Language'] as AccL,
d.kv['Accept-Encoding'] as AccE,
d.kv['Upgrade-Insecure-Requests'] as UIR,
d.kv['Cookie'] as Cookie,
d.kv['X-IMForwards'] as XIMF,
d.kv['Referer'] as Referer
from d;
```
- 要提取单一字段,请复制之前的SQL查询并将其粘贴在New custom SQL框当中,而后选择Edit/Preview data。


图十九:在“New custom SQL query”当中粘贴SQL查询
-
- 在 Edit/Preview data视图中的Data source部分,选择SPICE,而后选择 Finish。

- 在 Edit/Preview data视图中的Data source部分,选择SPICE,而后选择 Finish。

图二十:选择 “Spice”,而后选择“Finish”
- 回到Amazon QuickSight控制台,在Fields部分下选择下拉菜单,并将数据类型变更为Date。


图二十一:在Amazon QuickSight控制台中,将数据类型更改为 “Date”
- 在看到Date 列出现之后,在页面顶部为可视化结果输入合适的名称,而后选择Save。


图二十二:为可视化结果输入名称,而后选择“Save”
- 现在,您可以使用拖放功能创建具有多种视觉类型的各类可视化仪表板。您可以播放多种字段组合,例如Action, Client IP, Country, Httpmethod以及 User Agents。您也可以在Date 上添加过滤器以查看仪表板上的特定时间轴。以下为部分示例截屏:


图二十三a:可视化仪表板示例

图二十三b:可视化仪表板示例
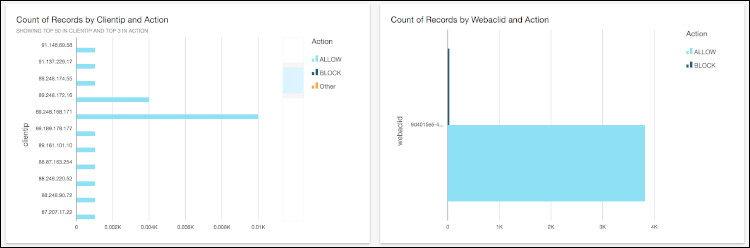
图二十三c:可视化仪表板示例
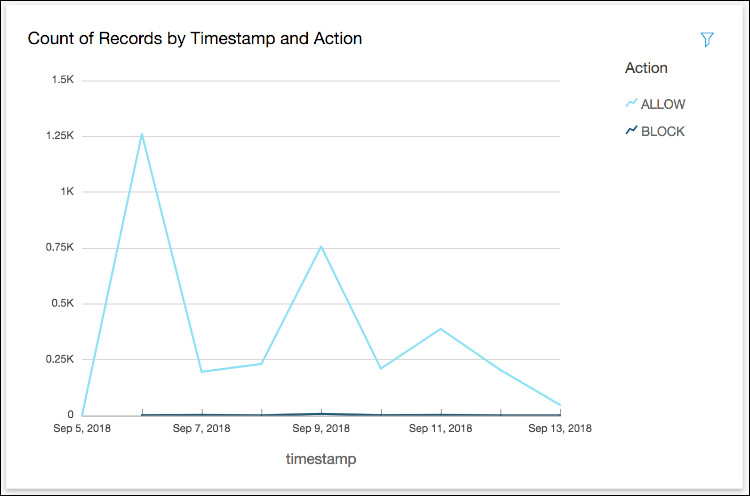
图二十三d:可视化仪表板示例
总结
您可以在Amazon S3存储桶上启用AWS WAF日志,并通过配置Amazon Kinesis Data Firehose对日志进行分析与流式传输。您可以通过数据流自动化,结合特定要求使用AWS Lambda进行多种数据转换操作,借此进一步增强这套解决方案。配合Amazon Athena与Amazon QuickSight,用户还可以轻松分析日志内容并为领导团队构建良好的可视化结果与仪表板。整套体系完全以无服务器架构运行,AWS将为您分担各类繁重的运营工作。