亚马逊AWS官方博客
Habby 游戏借助 AWS DevOps Agent 实现智能运维最佳实践
摘要:Habby(海彼游戏)是一家全球知名的休闲游戏发行商,代表作包括《弓箭传说》、《弹壳特攻队》、《GO!卡皮巴拉》等。公司拥有全球数亿玩家,运行在AWS上的后端基础设施按游戏多账户管理。
Habby 作为 AWS DevOps Agent 的早期采用者,通过深度集成Grafana、GitHub、飞书等工具,构建了一套适合游戏行业的智能运维方案,从而更好的应对流量波动、延迟敏感、版本更新频繁的运维要求。本文将介绍 Habby 游戏使用DevOps Agent的最佳实践,为行业客户提供有价值的落地经验。
目录
一、摘要
Habby(海彼游戏)是一家全球知名的休闲游戏发行商,代表作包括《弓箭传说》、《弹壳特攻队》、《GO!卡皮巴拉》等。公司拥有全球数亿玩家,运行在AWS上的后端基础设施按游戏多账户管理。
Habby 作为 AWS DevOps Agent 的早期采用者,通过深度集成Grafana、GitHub、飞书等工具,构建了一套适合游戏行业的智能运维方案,从而更好的应对流量波动、延迟敏感、版本更新频繁的运维要求。本文将介绍 Habby 游戏使用DevOps Agent的最佳实践,为行业客户提供有价值的落地经验。
二、游戏行业的运维挑战
2.1 流量波动剧烈
游戏业务的流量特征与传统业务有着显著差异。每次大版本更新或新功能上线,都会带来短时间内的流量激增。限时活动、节日庆典等运营活动同样会引发用户的集中登录和高频互动。如果是使用全球同服方式部署的游戏,不同地区玩家的活跃时段交替出现,会形成 24 小时的波浪式负载。这种剧烈波动对基础设施的弹性扩展能力、监控告警的敏感度、故障响应速度都提出了极高要求,使得运维团队难以应对。
2.2 多账户、多服务的复杂架构
Habby 运营的游戏非常多,AWS 账户以游戏、环境、中台服务为单位划分。游戏后端涉及 EKS、Lambda、DynamoDB、ElastiCache、API Gateway 等数十种服务。在这样的架构下,一个告警的根因可能隐藏在跨账户跨服务的调用链中,人工排查效率很低。
2.3 运维团队规模有限
游戏公司的核心竞争力在于游戏内容和玩法的创新,更倾向于将主要的人力资源投入研发和运营而非运维团队建设。Habby 的 SRE 团队仅有数人,却需要支撑全球数亿玩家、数十款游戏的运维工作。处理多款游戏的告警会消耗大量精力,形成”告警疲劳”。在人少事多的现实下,如何将重复性调查工作自动化,成为提升运维效率的关键。
2.4 版本迭代快、变更频繁
核心游戏每周都有热更新,每月有大版本发布。频繁的代码变更和配置调整都可能引入问题,如何快速判断”是不是最近的变更导致了故障”至关重要。
三、AWS DevOps Agent 简介
AWS DevOps Agent 是一款 AI 驱动的 frontier agent,能够自动响应和主动预防事件,持续提升系统可靠性和性能。它以经验丰富的 DevOps 工程师技能经验为基础,在AI的加持下,可协助运维团队高效完成运维工作。
3.1 三大核心能力
| 能力 | 说明 |
| 自主事件响应 (Autonomous Incident Response) | 告警触发后自动开始调查,生成 RCA 和缓解计划 |
| 按需 DevOps 任务 (On-demand DevOps Tasks) | 自然语言对话式助手,查询架构、健康状况、调查洞察 |
| 主动事件预防 (Proactive Incident Prevention) | 分析历史事件模式,提供预防性建议 |
3.2 自主事件响应
自主事件响应是 DevOps Agent 最核心的能力。当配置好告警触发时,Agent 可自动开始调查,无需人工干预。它会进行事件分诊(Incident Triage),评估严重程度和影响范围(受影响的服务、用户、区域)。基于 AWS 资源拓扑图,Agent 能理解故障的”爆炸半径”,追踪故障的传播路径。在调查过程中Agent会自动收集相关日志、指标、事件和最近的代码变更,结合上下文生成详细的根因分析(RCA)和缓解计划。运维人员还可以通过调查引导指引 Agent 的分析方向。下图展示了Habby使用DevOps Agent调查ALB 5XX错误的问题。
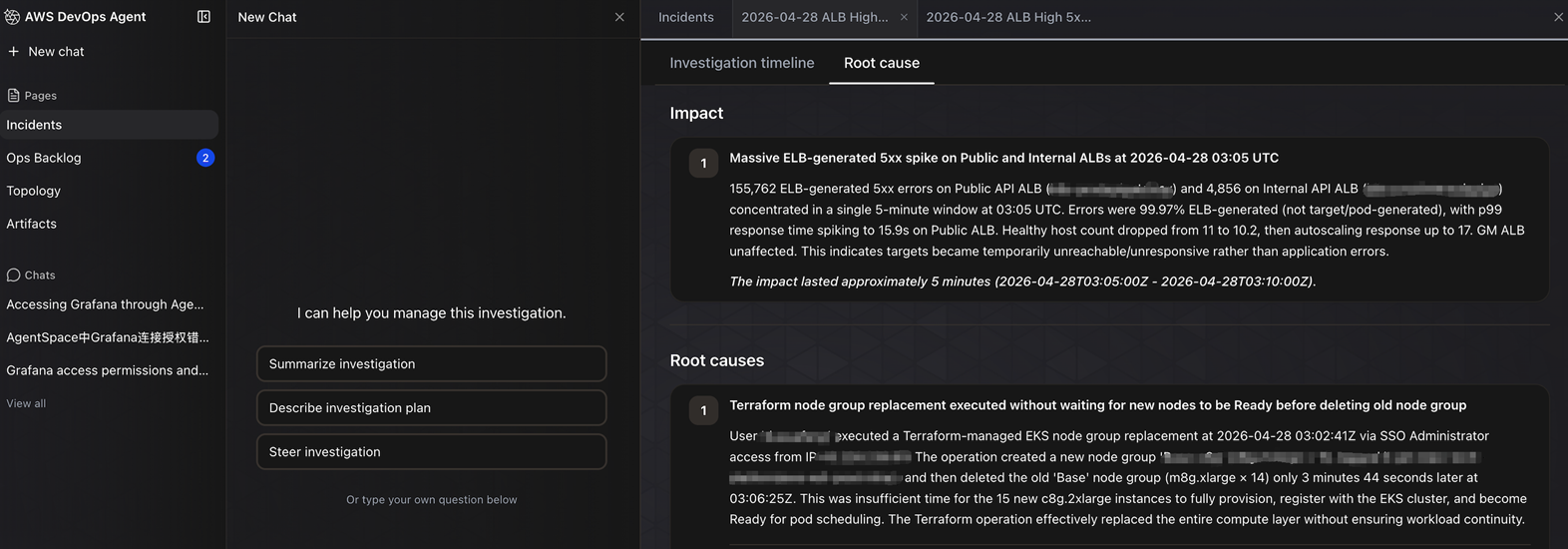
[图1 DevOps Agent对5XX错误的根因分析] |
3.3 按需 DevOps 任务
按需 DevOps 任务可通过内置于 Agent Space Web 应用的对话式 AI 助手完成。运维人员可以通过自然语言进行资源查询、系统健康分析、调查洞察、制品生成(报告、文档、周报)等任务,且不同的会话会独立分开,能保留对话历史,支持多轮追问。它还具备上下文感知能力,可以根据当前页面(如拓扑/事件)自动调整响应范围。下图展示了客户让Agent提供安全配置的优化建议。
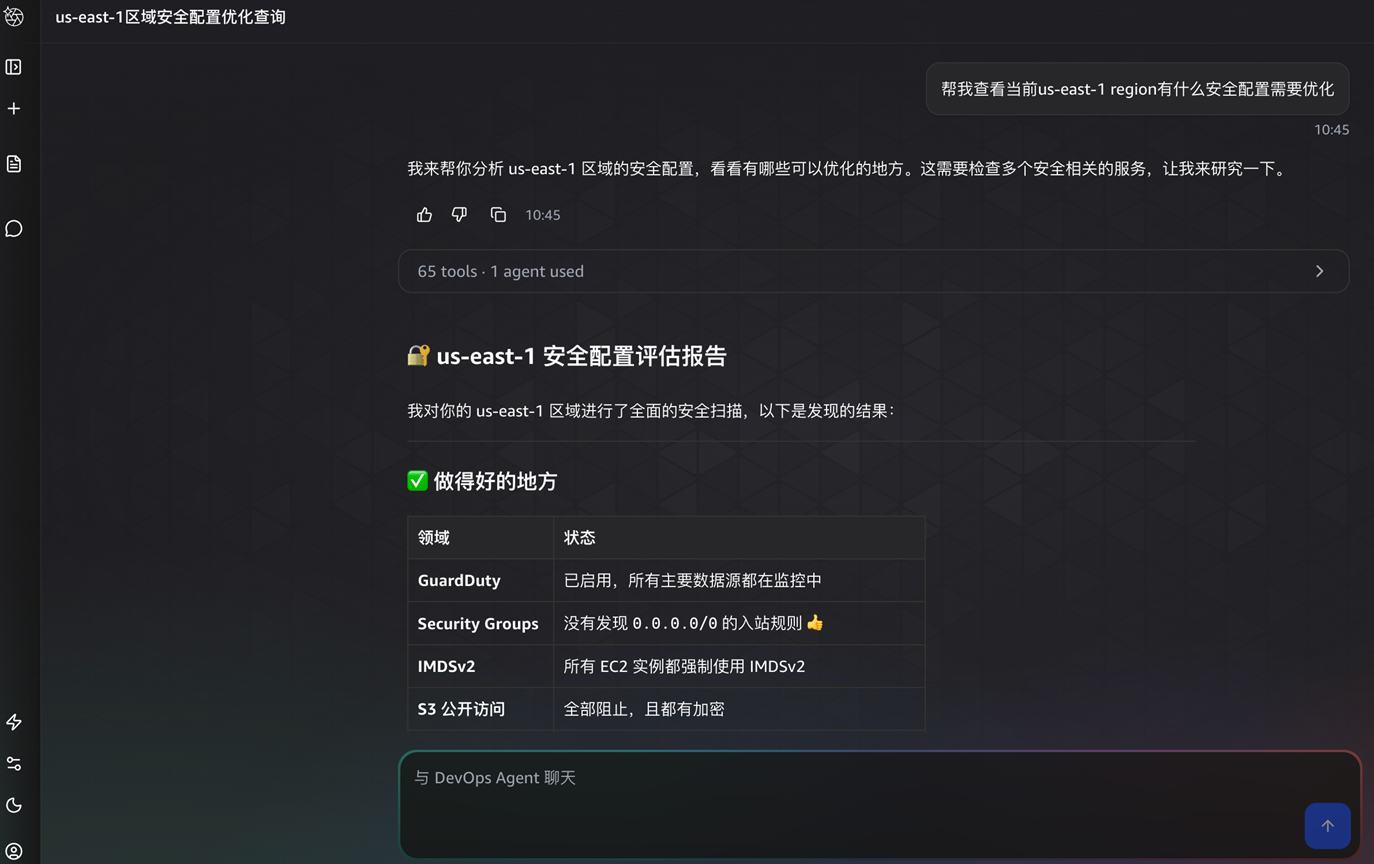
[图2 DevOps Agent提供的安全配置优化建议] |
3.4 主动事件预防
主动事件预防(改进项)是通过分析历史事件,自动生成覆盖不同领域的预防性建议,包括:可观测性增强(添加缺失的监控指标、优化告警阈值)、基础设施优化(识别自动扩展配置不合理、单点故障风险)、部署管道增强(增加测试覆盖、添加验证步骤)和架构弹性(识别服务依赖的脆弱点)等。建议还会附带代理就绪规范(Agent-ready Spec),如 CloudWatch 告警配置 JSON,并根据团队反馈持续优化。下图展示了每周运行的预防任务提供的改进项建议。
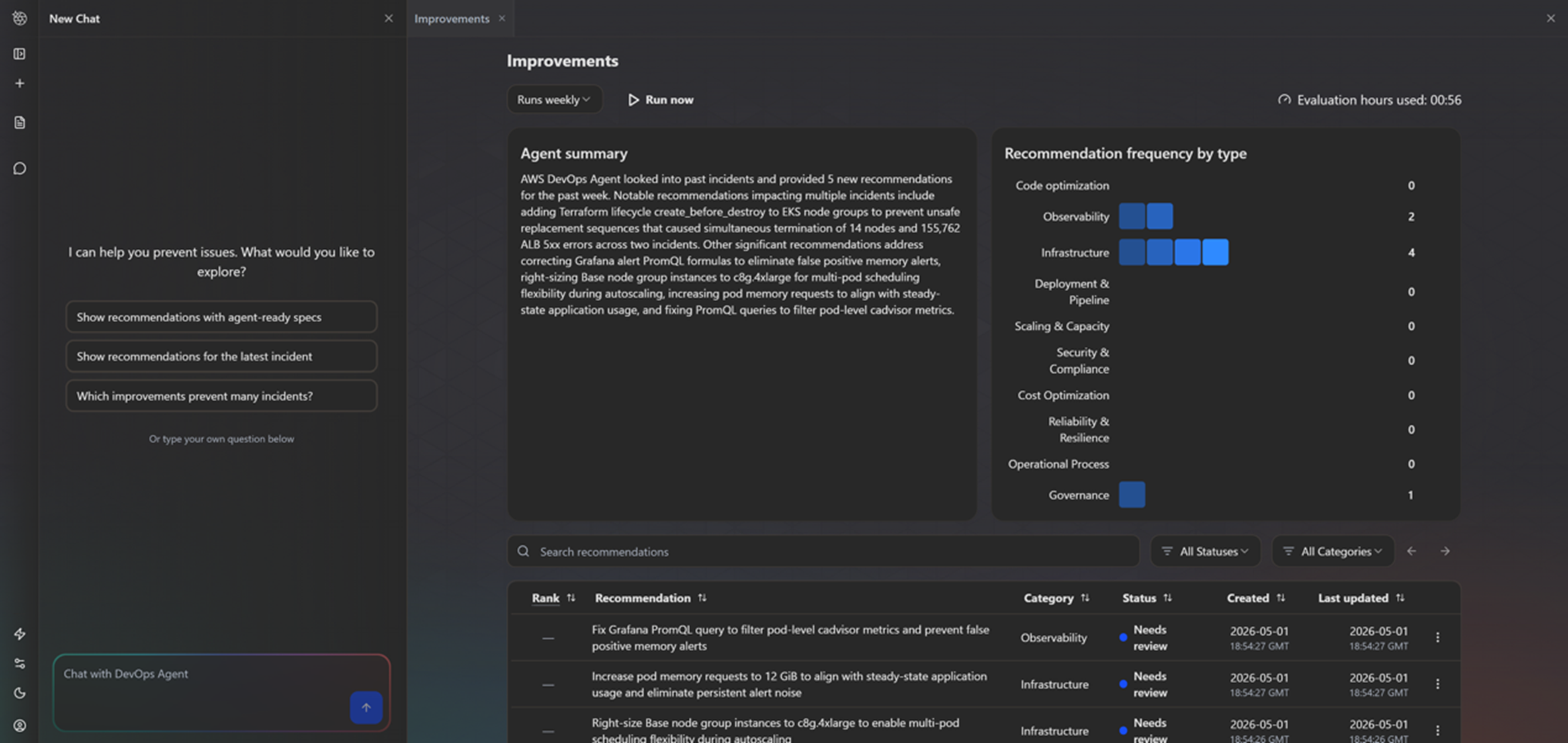
[图3 每周运行的改进项建议] |
3.5 关键功能集成
DevOps Agent 的价值不仅在于三大核心能力,还在于其丰富的第三方集成生态:
- Telemetry(遥测数据源):除 CloudWatch 原生集成外,支持接入 Grafana、Dynatrace、Datadog 等遥测数据源。Habby 游戏以 Grafana 作为主要监控工具,在和DevOps Agent 集成后,调查时就能看到基础设施指标和其他业务指标,丰富调查的上下文信息。
- Pipeline(CI/CD 集成):DevOps Agent还可以集成 GitHub/GitLab等工具,使得Agent 调查时自动关联最近的 commit 和部署记录,从而可以判断”是否是最近的代码变更导致了问题”,并在事件报告中提供完整的变更时间线。
- Communication(通讯渠道):DevOps Agent默认支持 Slack、Microsoft Teams、ServiceNow等IM工具的集成,也可以通过Webhook/Chat API,以更加灵活的方式集成如飞书这样的通讯工具。
- MCP(Model Context Protocol):作为一个AI Agent,通过接入MCP工具,DevOps Agent 就可以安全地访问企业内部或者三方系统,使得自身能力得以延伸。
- Skills(自定义技能):DevOps Agent 本身就是AWS运维经验沉淀的”知识库”和”最佳实践仓库”。它还支持上传或生成自定义Skill,使得团队将自己的故障排查经验标准化,让Agent按照团队经验进行工作。
四、Habby 的 DevOps Agent 解决方案
Habby 结合自身技术栈,构建了一套深度集成DevOps Agent的智能运维方案,核心设计理念是:自动化优先、多渠道融合、上下文增强。
4.1 整体架构
整套解决方案由两大部分组成:告警触发DevOps Agent自动调查的链路,通过Lambda实现的告警处理器根据收到的Grafana 告警,一方面以飞书群告警卡片的形式第一时间通知团队,另一方面触发DevOps Agent 自动调查并完成根因分析。第二部分是飞书 Bot 对话助手,通过调用Agent chat API实现了直接在飞书中使用Agent的能力。下图展示了方案的整体架构。
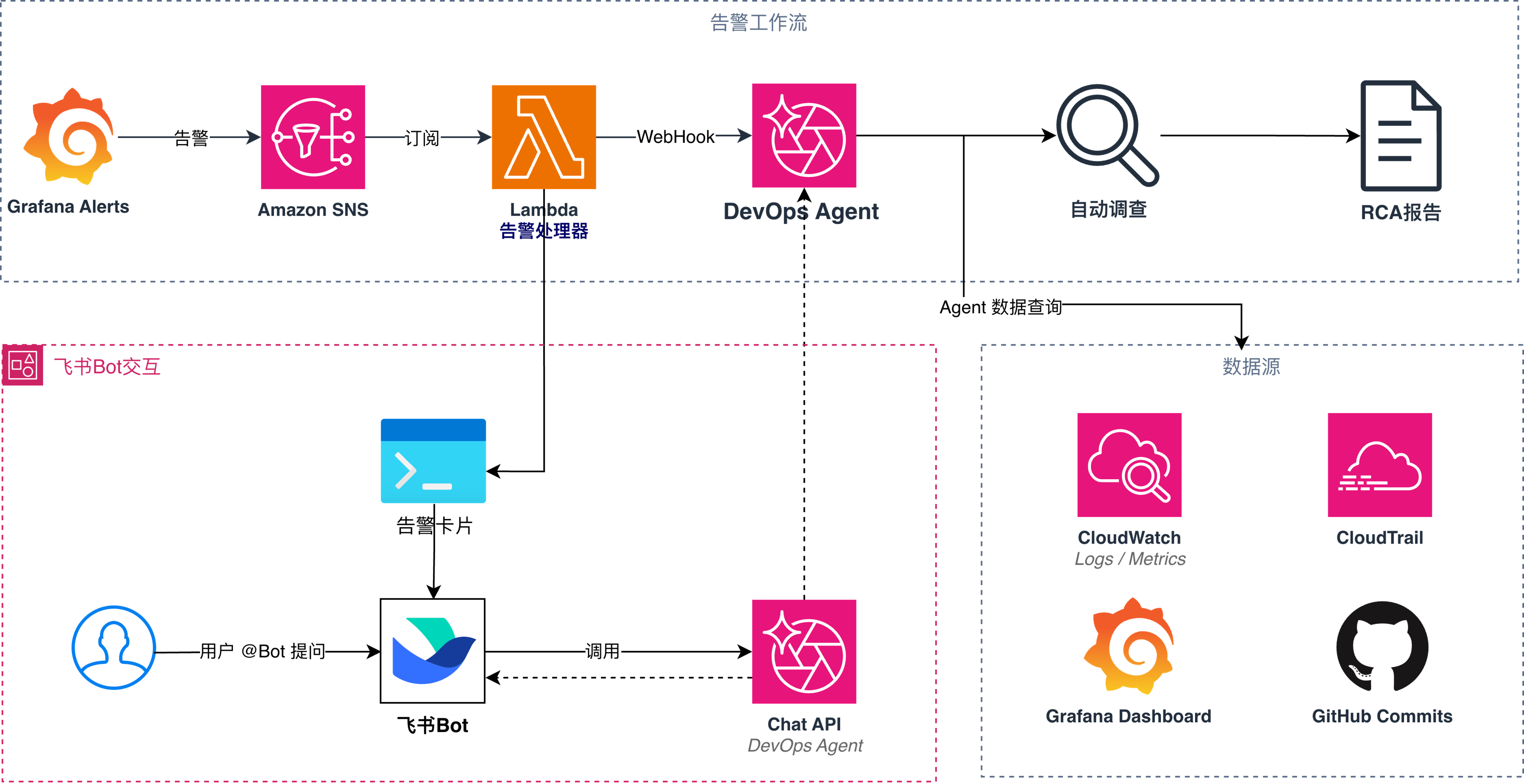
[图4 方案架构] |
下面我们来分别介绍这两部分的具体实现方法。
4.2 告警自动处理链路
整个告警处理流程由告警发送者(Grafana),SNS告警主题,Lambda告警处理器,飞书告警卡片和DevOps Agent共同完成。其中Lambda告警处理器需要我们自己编码实现,它接收到 SNS 事件后,解析来自消息中的告警。
告警路由:Grafana Alert 的通知目标设置为 Amazon SNS,Lambda 自动识别 Grafana 告警格式(JSON 或纯文本),封装为Agent Webhook 请求的要求的Payload并触发 Agent;
遥测数据源:Habby使用 Grafana 作为统一的监控平台,数据源添加了CloudWatch和三方系统的Prometheus,将AWS基础设施的指标和其他指标统一管理。Grafana 作为Telemetry Source 接入 Agent Space后,Agent 调查时就可以直接读取 Grafana Dashboard 和相关指标。
解析完成后,Lambda 执行两个动作:
- 推送飞书告警卡片:通过调用飞书API 发送交互式告警卡片,包含时间戳、服务名、区域、状态、描述以及”查看告警详情”的跳转按钮。
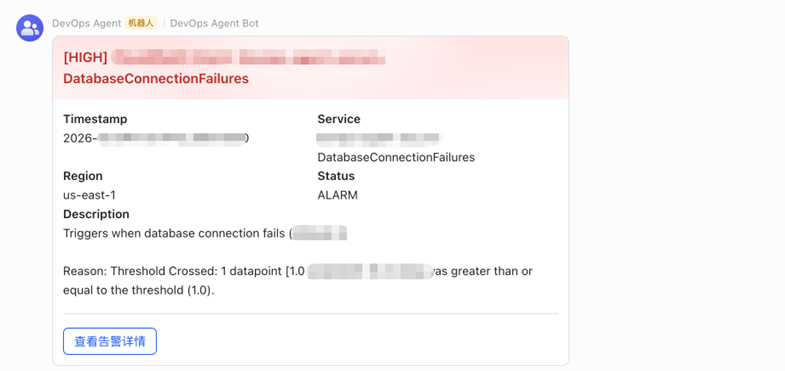
[图5 飞书告警卡片] |
- 触发 DevOps Agent:通过构造 Agent的 Webhook 请求体(包含 eventType、incidentId、priority、title、description 等字段),并按照要求使用 HMAC-SHA256 生成请求签名,调用Webhook URL触发Agent自动调查告警事件。
下面的时序图展示了告警自动处理链路的整个工作流程,包括告警事件如何自动触发DevOps Agent自动调查,Lambda基于告警事件发送飞书告警卡片等。
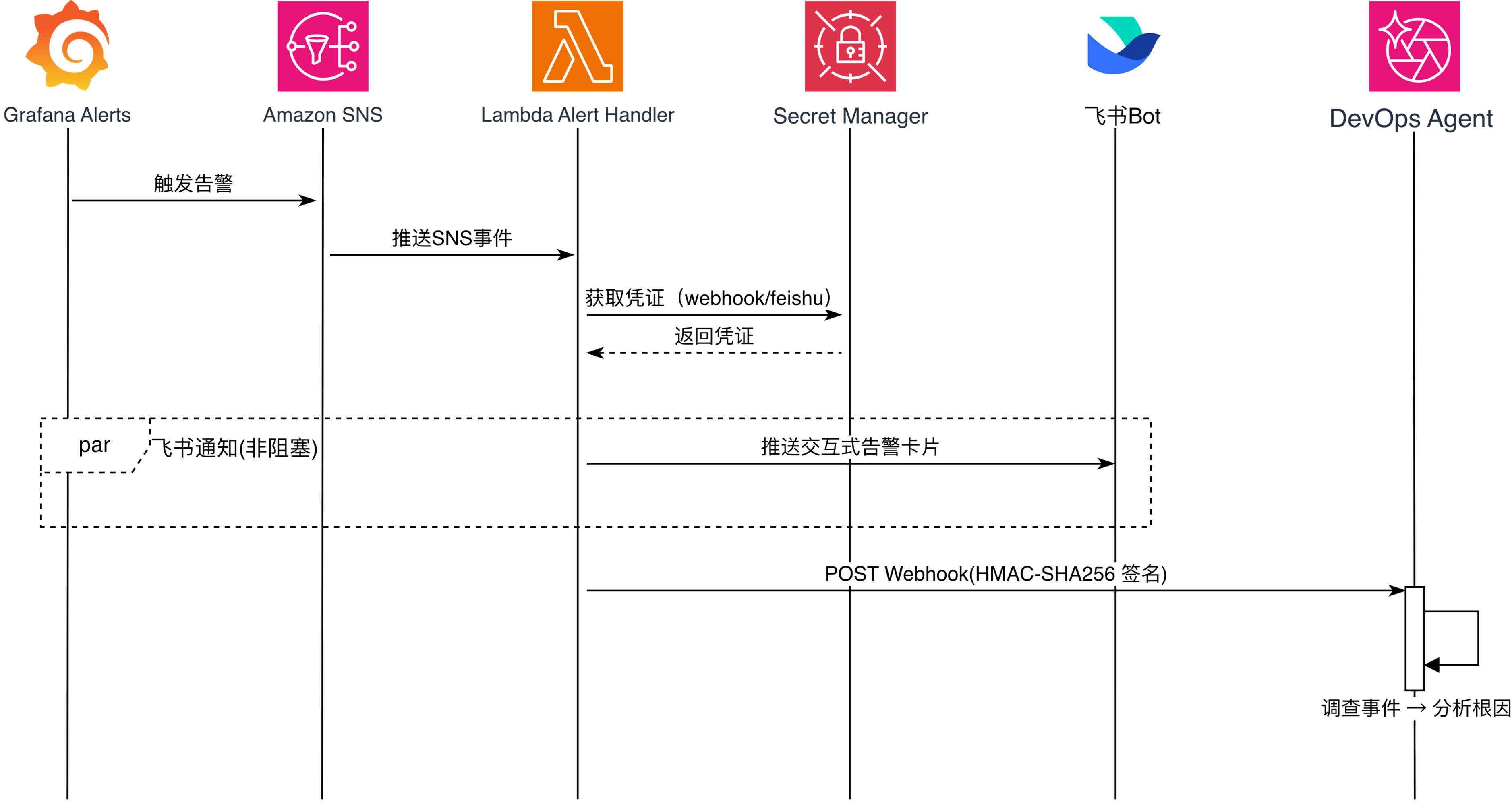
[图6 告警链路工作流] |
部分核心代码如下:
def lambda_handler(event, context):
"""Lambda 入口函数,由 SNS 触发。
处理流程:
1. 从 SNS 事件中提取消息内容
2. Grafana Alerting 解析
3. 推送飞书群通知(非阻塞,失败不影响后续流程)
4. 构造 Webhook 请求并调用 DevOps Agent 触发自动化调查
"""
# ......
# 按要求构造 DevOps Agent Webhook 请求体
# 生成 HMAC-SHA256 签名,用于 Webhook 端点验证请求合法性
# 签名格式:base64(HMAC-SHA256(secret, "timestamp:payload"))
# ......
# 步骤一:推送飞书群通知(非阻塞)
try:
card = _build_feishu_card(alert)
_send_feishu_card(card)
except Exception as e:
logger.error('飞书通知发送失败: %s', e)
# 步骤二:调用 DevOps Agent Webhook 触发自动调查
try:
response = http.request('POST', webhook_url, body=payload_str, headers=headers)
print(f"Webhook response: {response.status} - {response.data.decode('utf-8')}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'DevOps Agent investigation triggered',
'alarmName': alert['service'],
'webhookStatus': response.status,
})
}
except Exception as e:
print(f"Error calling webhook: {str(e)}")
return {'statusCode': 500, 'body': json.dumps({'error': str(e)})}
凭证管理方面,Webhook URL/Secret 和飞书 App ID/Secret 统一存储在 AWS Secrets Manager 中,Lambda 进行缓存避免多次重复请求。
这部分实现中有几点需要注意:
- 告警去重:DevOps Agent默认有20分钟的回溯窗口,可以在窗口期中自动关联同类调查,但同时运维团队也需要对告警设计分组/聚合/去重的能力,避免故障一直没有处理,频繁的发送告警冲击到Agent端。CloudWatch默认是通过告警状态变化触发告警,Grafana默认的发送策略也有4小时的冷却期,一般都不会对DevOps Agent产生影响。
- 如果使用CloudWatch Alarm作为告警源,是可以直接挂载Lambda的,但引入SNS依然是更优雅的选择,可以解耦告警的生产者和消费者,实现更灵活的告警方案。
- 托管的Amazon Managed Grafana (AMG)需要通过SNS触发后续的告警流程,自建的Grafana支持Webhook调用,可以直接与DevOps Agent关联。
4.3 飞书 Bot 对话式助手
飞书 Bot 是方案中的一大亮点,可以让团队无需登录 AWS 控制台就能使用 DevOps Agent 的能力。具体的流程如下图:飞书机器人作为和用户交互的客户端,将消息发送到飞书云端,我们自己实现的飞书Bot 服务端程序和飞书云以长连接的方式接收消息,并调用DevOps Agent的chat API,从而实现和Agent的交互。

[图7 飞书机器人工作流] |
流程中两个核心组件需要我们自己创建:
- 飞书机器人应用:作为对话入口,需要在飞书开放平台(开发者后台)创建机器人类型的自建应用,事件与回调的订阅方式选择长连接,权限部分开通im:message相关的消息收发权限。
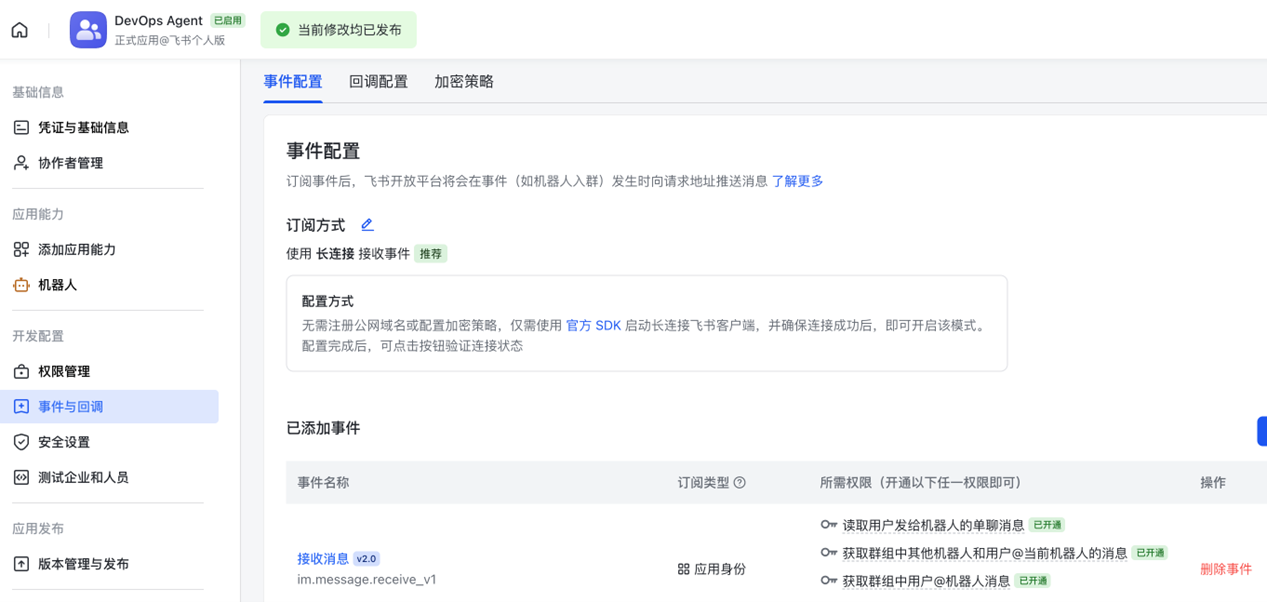
[图8 申请飞书机器人应用] |
- 飞书Bot 服务端程序:用户在飞书聊天界面和机器人对话后,消息以WebSocket长连接方式发送到这里,程序处理消息,并调用DevOps Agent的chat API实现和Agent的交互。
部分核心代码如下:
# AWS DevOps Agent 客户端
devops = boto3.client("devops-agent", region_name=AWS_REGION)
def ask_devops_agent(session_key: str, query: str) -> str:
"""向 DevOps Agent 发送消息并收集流式响应。
Agent 以 EventStream 形式返回响应,每个事件包含一个文本片段(delta)。
按 contentBlockIndex 分组收集,取最后一个 block 作为最终回复。
参数:
session_key: 飞书会话标识
query: 用户发送的问题文本
返回:
Agent 的完整回复文本,或错误提示信息
"""
execution_id = get_or_create_execution(session_key)
try:
resp = devops.send_message(
agentSpaceId=AGENT_SPACE_ID,
executionId=execution_id,
content=query,
)
blocks: dict[int, list[str]] = {}
for event in resp.get("events", []):
if "contentBlockDelta" in event:
block = event["contentBlockDelta"]
idx = block.get("contentBlockIndex", 0)
delta = block.get("delta", {})
text_delta = delta.get("textDelta", {})
if "text" in text_delta:
blocks.setdefault(idx, []).append(text_delta["text"])
elif "responseFailed" in event:
err = event["responseFailed"]
logger.error("Agent response failed: %s", err.get("errorMessage"))
return f"DevOps Agent 返回错误:{err.get('errorMessage', 'unknown')}"
if not blocks:
return "(DevOps Agent 未返回内容)"
last_idx = max(blocks.keys())
return "".join(blocks[last_idx])
except Exception:
logger.exception("DevOps Agent call failed")
with _lock:
_sessions.pop(session_key, None)
return "调用 DevOps Agent 失败,已重置会话,请重试。"
技术实现要点
- WebSocket 长连接:使用飞书
lark-oapiSDK 建立 WebSocket 连接,订阅im.message.receive_v1事件,无需暴露公网端口 - 会话管理:每个飞书会话(chat_id)对应一个 DevOps Agent 的 executionId,多轮对话共享同一 execution 保持上下文连贯
- 异步处理:Agent 调用耗时较长,Bot 使用后台线程处理,不阻塞 WebSocket 事件循环。收到消息后立即添加 emoji 表情给用户即时反馈
- Markdown → 飞书卡片转换:Agent 返回的 Markdown 文本自动转换为飞书交互式卡片,支持粗体、链接、代码块等格式
下面的截图是通过飞书机器人询问账号中Amazon S3的使用情况:
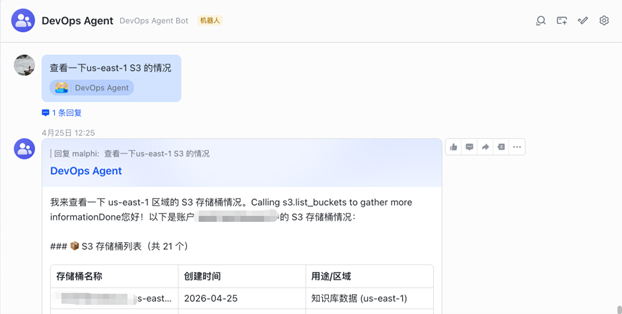
[图9 通过机器人对话使用DevOps Agent] |
下面的时序图详细说明了用户通过@机器人,完成对话交互的全过程:
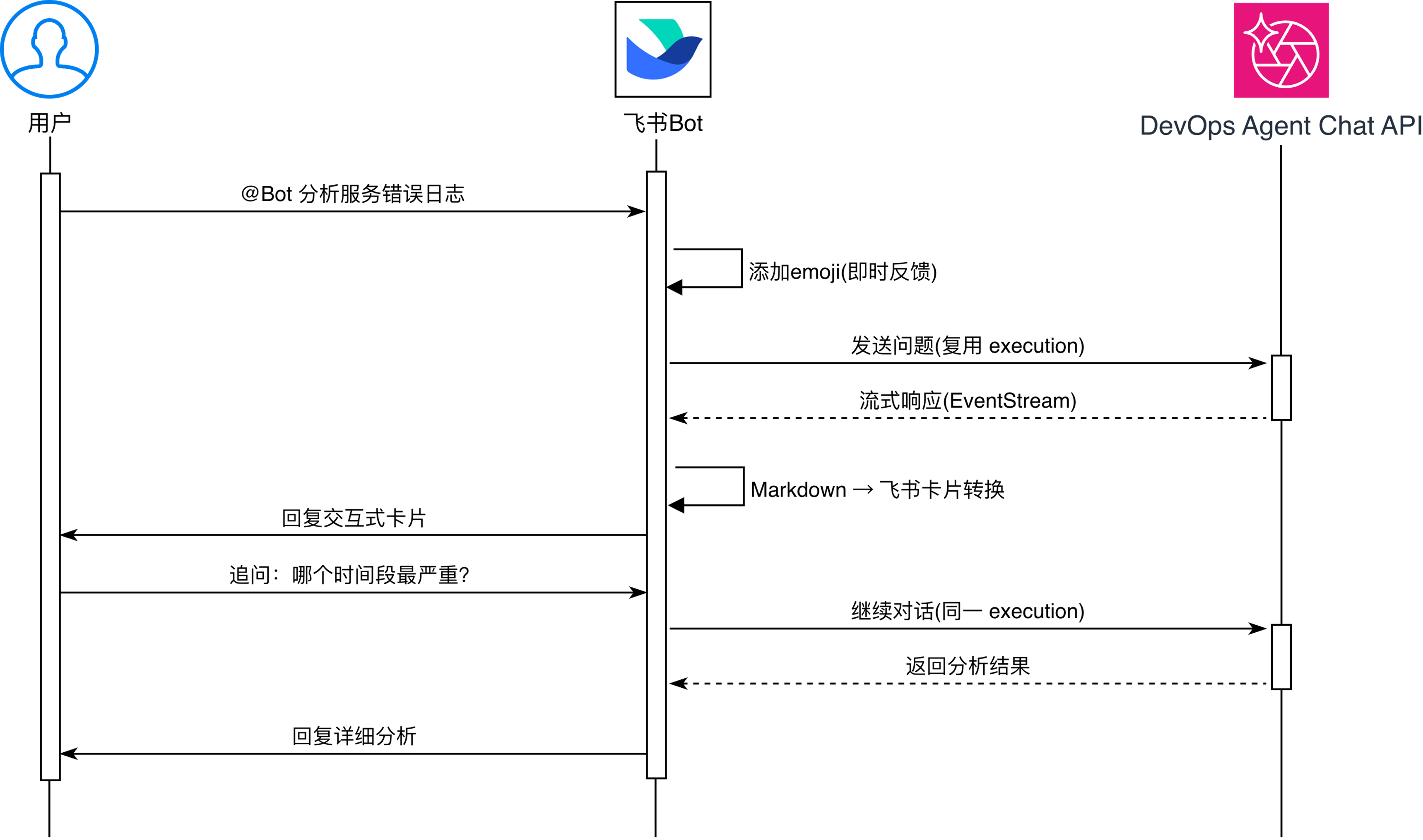
[图10 对话交互流程] |
在部署方面,我们提供了两种方案:基于EKS的容器方案和EC2方案。对于已经有EKS集群的用户来说,前者更加适合,只需要在集群中创建一个Pod即可,无任何额外成本,缺点是如果Pod重启会丢失容器内存储的上下文信息。但对于对话方式的交互来说,对连续性要求不高,且Bot可以获取到已经发送在聊天界面的历史信息,因此影响不大。EC2方案的配置更加简单一点,且Bot服务端对资源的要求非常低,将其部署在已有的EC2实例也可以做到无成本。
| 维度 | EKS 方案 | EC2 方案 |
| AWS认证 | IRSA(ServiceAccount 绑定 IAM Role) | Instance Profile |
| 飞书凭证 | K8s Secret → 环境变量注入 | Secrets Manager |
| 进程管理 | K8s Deployment(自动重启) | systemd(Restart=always) |
| 适用场景 | 已有 EKS 集群 | 快速上线、无 K8s 基础设施 |
4.4 集成 GitHub
变更是导致故障产生的最主要原因,在IT/互联网运维及软件开发领域属于共识性的铁律。据研究和生产经验显示,生产环境中约 **70% **左右的故障是由变更引起的。对于发布频繁,迭代周期短的游戏行业来说,快速判断”是否是最近的代码变更导致了问题”至关重要。
在 Agent Space 的 Settings → Pipeline Sources 中添加 GitHub 仓库后,Agent 在调查事件时会自动查询”告警发生前 1-2 小时内的代码变更”,包括 commit、pull request 和 merge 记录。如果发现可疑的 commit,会在 RCA 报告中高亮显示,并在事件报告中标注事件发生前后的代码变更和部署操作,提供完整的时间线视图。DevOps Agent还支持跨仓库关联,例如Habby的完整游戏应用是由游戏业务服务和中台服务共同实现的,我们就可以把游戏业务代码仓库和中台代码仓库都关联到Space空间,完善调查的上下文。
4.5 多账户统一管理
DevOps Agent支持将多个Accoun挂载在同一个Agent Space下,这样做的好处有以下两点:
- 单一入口,统一管理:我们可以统一监控和调查所有账号的问题,无需逐个登录。发生故障时无需切换账号,DevOps Agent会根据告警中的Account信息在对应账号进行调查。
- 跨账号关联调查:如果应用是跨账号部署的,或者不同账号之间的服务有交互,那么关联调查就非常有用。DevOps Agent 能理解这种跨账户依赖,在调查时一并分析。
多账号绑定是通过 IAM Role 的跨账户信任关系(AssumeRole)实现的。Agent 在调查时可自动切换账户查询资源和指标。单一 Agent Space 即可跨账户查看拓扑、响应事件、生成建议。权限控制方面,遵循最小权限原则,通过 IAM 策略精细化控制 Agent 在每个账户中的可访问资源范围。默认情况下,Agent只需要只读权限就可以完成工作。
五、Habby采用DevOps Agent的收益
5.1 MTTR 大幅缩短
传统人工模式下,运维工程师收到告警后需要登录AWS Console、Grafana等多个控制台,逐一检查日志、指标、事件,平均排查时间 1.5-2 小时。凌晨告警如果无人值班,可能延迟到早上才处理,MTTR 长达 4-6 小时。
采用 DevOps Agent 后,告警触发后 Agent 在几分钟内就能完成数据的收集和调查工作,生成根因分析报告并推送到飞书群,运维人员在移动端即可查看。人工介入时间缩短为 15-30 分钟(主要用于验证分析结果和执行缓解操作),平均 MTTR 从 2 小时降低到 20 分钟,缩短了 80%。即时在凌晨无人值守的情况下,第二天运维人员可直接基于 RCA 报告修复故障,省去了故障排查的时间。
5.2 告警疲劳显著降低
DevOps Agent 会自动分类和关联告警,将同一根因的多次告警聚合为一个 Incident(如 EC2 的 CPU 告警、内存告警、健康检查失败可能识别为同一事件),对低优先级告警自动降级。运维工程师需要处理的告警数量大大降低。
5.3 运维效率提升
- 理解并优化架构:运维/开发人员可以通过飞书 Bot 直接了解架构问题和服务依赖拓扑关系,查看历史 RCA 报告学习排查思路,从而熟悉部署架构并做好优化工作。
- 报告生成:DevOps Agent提供了构件功能,可以对运维相关信息生成分析报告。比如我们可以通过对话方式输入”生成本周事件汇总报告”。生成的构件通常会包含表格/图表等信息,极大的缩短了我们自己编写报告的工作量。下图展示了生成的运维健康摘要:
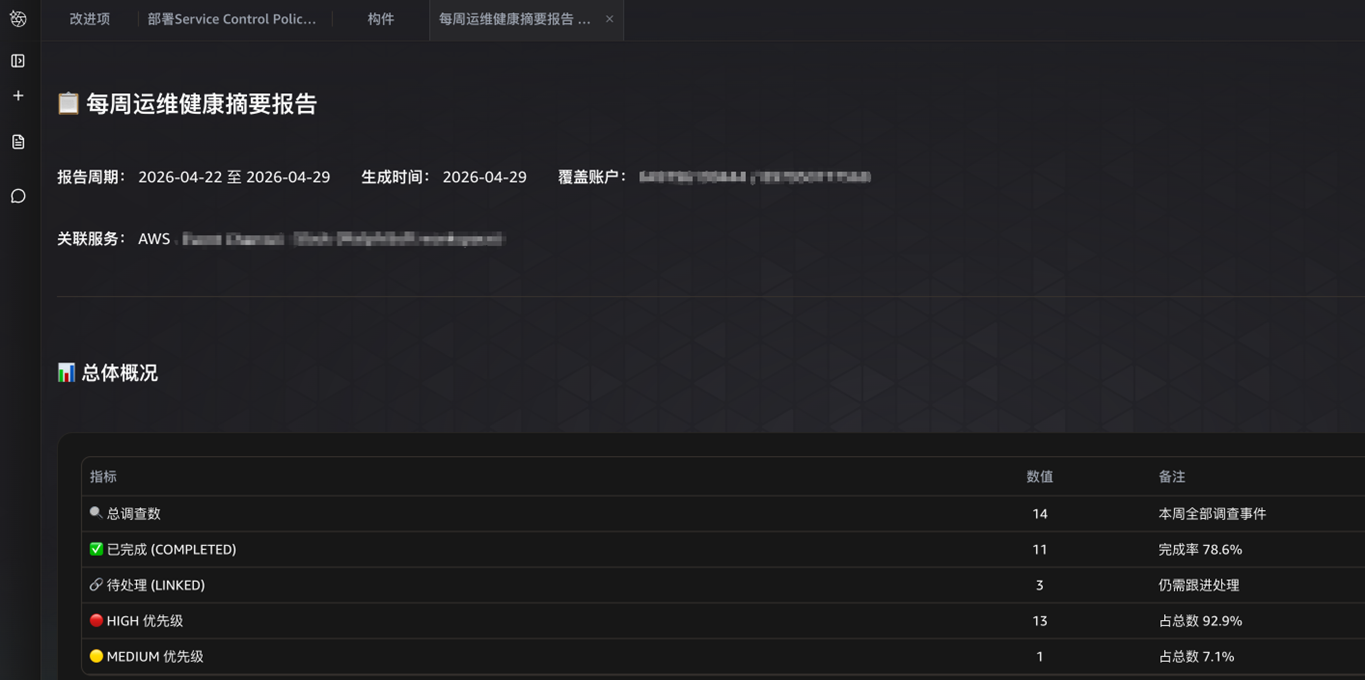
[图11 DevOps Agent生成的运维健康报告] |
- 减少控制台切换:所有信息聚合在 Agent Space中,可以通过Web页面或者我们接入的飞书Bot机器人统一交互,无需在多个平台或账号之间频繁切换。
5.4 系统可靠性持续提升
DevOps Agent 每周会生成防护建议,帮助团队消除系统中的隐患。运维团队会定期对防护报告进行Review,按影响范围和实施难度评估优先级,并将高优先级建议转化为工作计划。防护功能可以让运维工作从”救火式”转变为”防火式”,提高系统的可靠性。
5.5 运维知识沉淀
DevOps Agent支持上传或者新建Skill,可以将资深工程师的排查经验编写为自定义 Skills。而根因分析报告也是高质量的事后复盘文档,包含时间线、根因、相关数据和缓解措施等内容,这些经验Skill和复盘报告可以沉淀下来,成为团队的运维知识库。
六、落地最佳实践
6.1 分阶段落地
任何项目或系统的构建都不是一蹴而就的,需要循序渐进,逐渐完善,DevOps Agent的落地方案也是如此。Habby的经验是:
- 第一阶段,先进行快速验证,从单个游戏项目的生产账户创建第一个 Agent Space,优先接入 CloudWatch(原生告警),最小化配置即可看到自动事件响应的效果,使用Chat对话进行日常巡检和架构查询;
- 第二阶段,持续集成,接入Grafana将游戏指标纳入Agent的可观测视野,接入Github打通代码变更 → 部署 → 事件的关联链路,添加 Secondary Account,实现多游戏项目的跨账户聚合监控;
- 第三阶段:知识沉淀与持续优化,编写自定义 Skills,将团队积累的调查经验标准化;定期 Review 防护建议,按优先级逐项落实。
6.2 Agent Space 设计建议
- 按游戏项目划分:每个核心游戏创建独立 Agent Space,数据隔离、调查不互相干扰
- 环境隔离:生产和非生产使用不同 Agent Space
- 权限精细化:按角色分配权限(运维完整权限、开发只读),利用权限限制资源范围
6.3 告警与事件响应调优
- 告警质量先行:建议先梳理现有告警,清理过期/无效告警,确保告警阈值合理。为关键服务配置 Composite Alarm 减少噪声告警(例如”CPU > 80% 且持续 5 分钟”比”CPU > 80%”更合理)。在告警描述字段中提供更多上下文,例如
payment-service in us-east-1: CPU usage > 80%。 - 善用调查引导:当 Agent 自动调查的方向不够精准时,运维人员可以通过 Chat 提供引导,例如”聚焦 UTC 14:00 – 15:00 之间支付服务的日志并更新你的 RCA”。引导过的调查会帮助 Agent 在类似场景中做出更好的判断,将运维人员的领域知识教给Agent,实现持续学习。
- 防护建议的落地机制:建议每两周召开一次 Review 会议,生成建议摘要报告,按影响范围和实施难度评估优先级,将高优先级的建议转化为工作计划,从而持续改进系统可靠性。
七、总结与展望
通过深度集成 AWS DevOps Agent,Habby 成功将运维模式从”人工救火”升级为”AI 驱动的智能运维”,实现了 MTTR 缩短 80%、告警疲劳降低 75%、系统可用性显著提升等核心收益。
在实践过程中,Habby 团队也与 AWS 产品团队保持了紧密的沟通与反馈。基于一线使用经验,双方对 DevOps Agent 未来的能力演进方向有着共同的期待:
- 从”建议”到”行动”:当前 Agent 已能高效完成问题调查与根因定位,未来期待进一步向自动化修复演进——对于置信度高的常规运维操作,Agent 能够在人工确认后自动执行,实现”调查 → 建议 → 执行”的完整闭环;
- 更灵活的调查策略:不同业务场景对告警回溯的时间窗口需求各异,未来若能提供可配置的调查回溯范围,将帮助团队更精准地匹配自身的运维节奏;
- 更流畅的交互体验:在深度排障场景中,工程师与 Agent 的对话往往持续较长时间,期待会话管理策略能更好地适配这类长时交互场景,减少不必要的中断;
- 更简洁的集成体验:随着 DevOps Agent 对接的数据源和告警通道日益丰富,期待未来能提供更开箱即用的集成方式,降低初始配置的门槛,让团队能更快速地获得价值。
我们相信,随着 AI 技术的持续演进和客户反馈的不断融入,DevOps Agent 将帮助更多团队实现真正的智能运维。
➡️ 下一步行动:
相关产品:
- Amazon DevOps Agent — 解决和预防事故的代理
- AWS Lambda — 无需服务器即可运行代码
- Amazon SNS — 发布/订阅和推送通知
- Amazon CloudWatch — 可观测性工具
- Amazon EC2 — 安全且可调整大小的计算容量
相关文章:
- AWS DevOps Agent 与 GitHub 集成实践:如何实现从代码变更到故障调查的端到端闭环
- 将 AWS DevOps Agent 智能运维能力延伸到中国区
- 基于 AWS DevOps Agent 构建 AI 驱动的运维分析系统
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
