Original URL: https://aws.amazon.com/cn/blogs/machine-learning/building-a-customized-recommender-system-in-amazon-sagemaker/
推荐系统能够帮助您为在线平台定制客户体验。Amazon Personalize则是一项AI/ML服务,专门用于开发推荐系统解决方案。它能够自动检查数据、选择特征与算法、根据实际数据优化模型,并完成模型的部署和服务托管,进而做实时的推荐推理。但是,(由于不能访问Amazon Personalize训练好的模型文件,)如果您需要获取已训练模型中的权重,就要从零开始构建推荐系统。本文将展示如何使用TensorFlow 2.0在Amazon SageMaker中训练和部署一个基于(Neural Collaborative Filtering,NCF)(He等,2017年)模型的定制化推荐系统。
关于NCF(基于神经网络的协同过滤)
推荐系统的本质是一组工具,它通过在众多选项当中预测出用户偏爱的那部分,为用户提供个性化体验。矩阵分解(MF)可以说是解决这类问题中的普遍性方法。常规矩阵分解方法以线性方式运用显式反馈,这种显式反馈中包含用户的直接偏好,例如为电影或产品按照五分制进行评分或者是选择“喜欢”或“不喜欢”。但是,数据集中并不总是存在这种显式反馈。NCF旨在使用隐式反馈解决缺少显式反馈的难题,这种隐式反馈来自用户行为(例如点击及观看)。此外,NCF还利用多层感知器(MLP)向解决方案当中引入非线性因素。
架构概述
NCF模型包含两个固定的网络层集:embedding层与NCF层。大家可以使用这些层构建起具有两套独立网络架构(GMF和MLP两个网络架构)的神经网络矩阵分解(Neural Matrix Factorization)方案,最后将二者的输出结果串联起来作为最终输出层的输入。如下图所示,是这套架构的基本形式。(译者注:总共是三层,分别是embedding层、NCF层和输出层。embedding层是中间圆角矩形下面的部分,圆角矩形内部的是NCF层,NCF层上面的部分是输出层。NCF层有两种网络架构,分别是GMF和MLP,分别注重线性和非线性建模。NCF的两种架构,都是在通过neural network在为协同过滤建模,只不过各有侧重。和并两种网络后最终的产出在形式上也是在为CF做MF,由于方法是通过neural来做的,所以昵称NeuMF)

在本文中,我们将按照以下步骤引导大家构建并部署神经协作过滤解决方案:
- 准备用于模型训练及测试的数据。
- 在TensorFlow 2.0中编码实现协同过滤的神经网络(NCF)。
- 使用Amazon SageMaker的脚本模式执行模型训练,并把训练好的模型 使用Amazon SageMaker 托管方式来部署成一个 终端节点。
- 通过终端节点进行推荐推理。
大家可以在 GitHub repo中找到完整的示例代码。
数据准备
在本文中,我们使用MovieLens数据集。MovieLens是由明尼苏达大学研究实验室GroupLens整理的一套电影评分数据集。
首先,我们运行以下代码,将数据集下载至ml-latest-small目录当中:
%%bash
# delete the data directory if it already exists
rm -r ml-latest-small
# download movielens small dataset
curl -O http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
# unzip into data directory
unzip ml-latest-small.zip
rm ml-latest-small.zip
这里,我们只使用包含显式反馈数据的 rating.csv作为代理数据集,用于演示NCF解决方案。要让这套解决方案与您的实际数据相匹配,您需要自己确定什么样的数据代表了一个用户的喜好(然后把这些数据喂入NCF)。
为了进行训练数据与测试数据划分,我们将每位用户做出的10条最新评论作为测试集,其余部分则作为训练集:
def train_test_split(df, holdout_num):
""" perform training testing split
@param df: dataframe
@param holdhout_num: number of items to be held out per user as testing items
@return df_train: training data
@return df_test testing data
"""
# first sort the data by time
df = df.sort_values(['userId', 'timestamp'], ascending=[True, False])
# perform deep copy to avoid modification on the original dataframe
df_train = df.copy(deep=True)
df_test = df.copy(deep=True)
# get test set
df_test = df_test.groupby(['userId']).head(holdout_num).reset_index()
# get train set
df_train = df_train.merge(
df_test[['userId', 'movieId']].assign(remove=1),
how='left'
).query('remove != 1').drop('remove', 1).reset_index(drop=True)
# sanity check to make sure we're not duplicating/losing data
assert len(df) == len(df_train) + len(df_test)
return df_train, df_test
我们正在进行的是一项二分类任务,而且能够通过正向标签判断用户喜爱哪些条目,(相反的问题是如何定义不喜欢呢?)这里我们可以对用户未评分的影片进行随机抽样,并将其视为负向标签。这种方法被称为负采样。以下函数可用于实现负采样过程:
def negative_sampling(user_ids, movie_ids, items, n_neg):
"""This function creates n_neg negative labels for every positive label
@param user_ids: list of user ids
@param movie_ids: list of movie ids
@param items: unique list of movie ids
@param n_neg: number of negative labels to sample
@return df_neg: negative sample dataframe
"""
neg = []
ui_pairs = zip(user_ids, movie_ids)
records = set(ui_pairs)
# for every positive label case
for (u, i) in records:
# generate n_neg negative labels
for _ in range(n_neg):
j = np.random.choice(items)
# resample if the movie already exists for that user
While (u, j) in records:
j = np.random.choice(items)
neg.append([u, j, 0])
# convert to pandas dataframe for concatenation later
df_neg = pd.DataFrame(neg, columns=['userId', 'movieId', 'rating'])
return df_neg
您可以使用以下代码做训练/测试数据进行拆分、负采样,并将处理后的数据存储在 Amazon Simple Storage Service (Amazon S3)当中:
import os
import boto3
import sagemaker
import numpy as np
import pandas as pd
# read rating data
fpath = './ml-latest-small/ratings.csv'
df = pd.read_csv(fpath)
# perform train test split
df_train, df_test = train_test_split(df, 10)
# create 5 negative samples per positive label for training set
neg_train = negative_sampling(
user_ids=df_train.userId.values,
movie_ids=df_train.movieId.values,
items=df.movieId.unique(),
n_neg=5
)
# create final training and testing sets
df_train = df_train[['userId', 'movieId']].assign(rating=1)
df_train = pd.concat([df_train, neg_train], ignore_index=True)
df_test = df_test[['userId', 'movieId']].assign(rating=1)
# save data locally first
dest = 'ml-latest-small/s3'
!mkdir {dest}
train_path = os.path.join(dest, 'train.npy')
test_path = os.path.join(dest, 'test.npy')
np.save(train_path, df_train.values)
np.save(test_path, df_test.values)
# store data in the default S3 bucket
sagemaker_session = sagemaker.Session()
bucket_name = sm_session.default_bucket()
print("the default bucket name is", bucket_name)
# upload to the default s3 bucket
sagemaker_session.upload_data(train_path, key_prefix='data')
sagemaker_session.upload_data(test_path, key_prefix='data')
我们使用Amazon SageMaker会话的默认存储桶存储经过处理的数据。该默认存储桶的名称格式为sagemaker-{region}–{aws-account-id}。
NCF网络代码实现
在本节中,我们将分别实现通用矩阵分解(GMF)与多层感知器(MLP)。这两个部分的输入既有用户嵌入,也有条目嵌入。要定义嵌入层,我们输入以下代码:
def _get_user_embedding_layers(inputs, emb_dim):
""" create user embeddings """
user_gmf_emb = tf.keras.layers.Dense(emb_dim, activation='relu')(inputs)
user_mlp_emb = tf.keras.layers.Dense(emb_dim, activation='relu')(inputs)
return user_gmf_emb, user_mlp_emb
def _get_item_embedding_layers(inputs, emb_dim):
""" create item embeddings """
item_gmf_emb = tf.keras.layers.Dense(emb_dim, activation='relu')(inputs)
item_mlp_emb = tf.keras.layers.Dense(emb_dim, activation='relu')(inputs)
return item_gmf_emb, item_mlp_emb
为了实现通用矩阵分解,我们将用户与条目嵌入相乘:
def _gmf(user_emb, item_emb):
""" general matrix factorization branch """
gmf_mat = tf.keras.layers.Multiply()([user_emb, item_emb])
return gmf_mat
神经协作过滤的作者们已经表示,根据多轮不同实验的验证,拥有64维用户与条目隐性因子的四层MLP具备最好的性能表现,因此我们也将在示例中使用同样的多层感知器结果:
def _mlp(user_emb, item_emb, dropout_rate):
""" multi-layer perceptron branch """
def add_layer(dim, input_layer, dropout_rate):
hidden_layer = tf.keras.layers.Dense(dim, activation='relu')(input_layer)
if dropout_rate:
dropout_layer = tf.keras.layers.Dropout(dropout_rate)(hidden_layer)
return dropout_layer
return hidden_layer
concat_layer = tf.keras.layers.Concatenate()([user_emb, item_emb])
dropout_l1 = tf.keras.layers.Dropout(dropout_rate)(concat_layer)
dense_layer_1 = add_layer(64, dropout_l1, dropout_rate)
dense_layer_2 = add_layer(32, dense_layer_1, dropout_rate)
dense_layer_3 = add_layer(16, dense_layer_2, None)
dense_layer_4 = add_layer(8, dense_layer_3, None)
return dense_layer_4
最后,为了产生最终预测,我们将通用矩阵分解与多层感知器的输出结果合并如下:
def _neuCF(gmf, mlp, dropout_rate):
""" final output layer """
concat_layer = tf.keras.layers.Concatenate()([gmf, mlp])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concat_layer)
return output_layer
为了分步构建这套完整的解决方案,我们还创建了一项图构建函数:
def build_graph(user_dim, item_dim, dropout_rate=0.25):
""" neural collaborative filtering model
@param user_dim: one hot encoded user dimension
@param item_dim: one hot encoded item dimension
@param dropout_rate: drop out rate for dropout layers
@return model: neural collaborative filtering model graph
"""
user_input = tf.keras.Input(shape=(user_dim))
item_input = tf.keras.Input(shape=(item_dim))
# create embedding layers
user_gmf_emb, user_mlp_emb = _get_user_embedding_layers(user_input, 32)
item_gmf_emb, item_mlp_emb = _get_item_embedding_layers(item_input, 32)
# general matrix factorization
gmf = _gmf(user_gmf_emb, item_gmf_emb)
# multi layer perceptron
mlp = _mlp(user_mlp_emb, item_mlp_emb, dropout_rate)
# output
output = _neuCF(gmf, mlp, dropout_rate)
# create the model
model = tf.keras.Model(inputs=[user_input, item_input], outputs=output)
return model
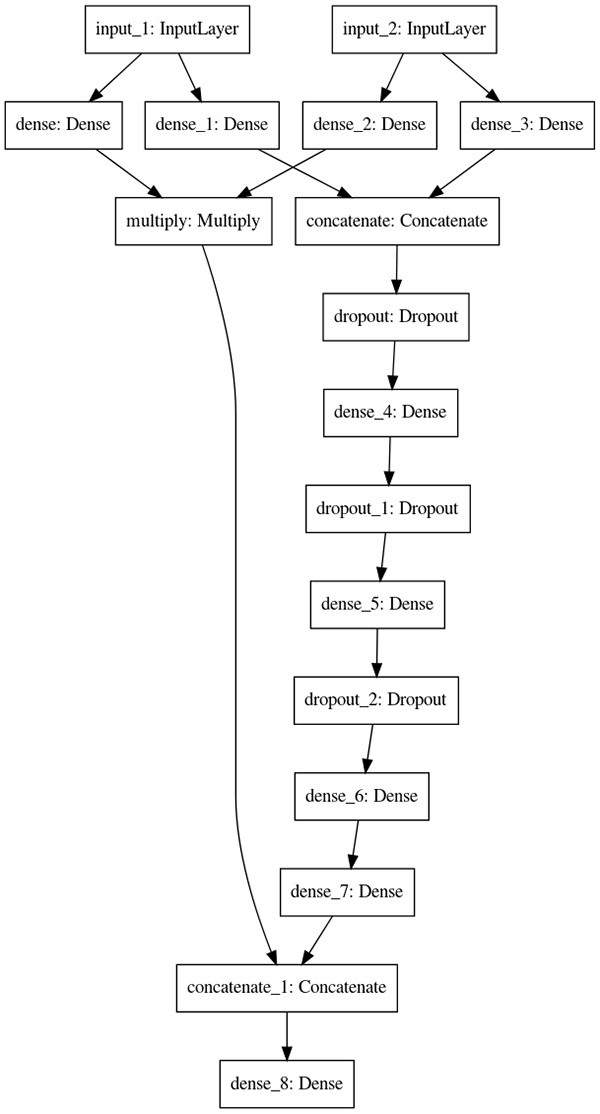
这里,我们使用Keras plot_model 实用程序以验证刚刚构建起的这套网络架构是否正确:
# build graph
ncf_model = build_graph(n_user, n_item)
# visualize and save to a local png file
tf.keras.utils.plot_model(ncf_model, to_file="neural_collaborative_filtering_model.png")
输出架构应该如下图所示。

模型训练与部署
关于如何把训练好的模型部署到Amazon SageMaker中的实例上,请参阅使用Amazon SageMaker部署经过训练的Keras或TensorFlow模型。在本文中,我们部署模型使用的是脚本模式。
我们首先需要创建一个包含模型训练代码的Python脚本。在本文中,我编写了以上模型架构的代码,并根据需要在 ncf.py中添加了额外代码供大家直接使用。此外,我还实现了一项训练数据加载函数。如果需要加载测试数据,大家不需要变更函数内容,更改其文件名以反映测试数据的所在位置即可。
def _load_training_data(base_dir):
""" load training data """
df_train = np.load(os.path.join(base_dir, 'train.npy'))
user_train, item_train, y_train = np.split(np.transpose(df_train).flatten(), 3)
return user_train, item_train, y_train
将训练脚本下载并存储在与模型训练notebook相同的目录之后,我们即可使用以下代码对TensorFlow estimator 进行初始化:
ncf_estimator = TensorFlow(
entry_point='ncf.py',
role=role,
train_instance_count=1,
train_instance_type='ml.c5.2xlarge',
framework_version='2.1.0',
py_version='py3',
distributions={'parameter_server': {'enabled': True}},
hyperparameters={'epochs': 3, 'batch_size': 256, 'n_user': n_user, 'n_item': n_item}
)
在estimator的fit方法中传入训练数据,我们即可启动训练作业:
# specify the location of the training data
training_data_uri = os.path.join(f's3://{bucket_name}', 'data')
# kick off the training job
ncf_estimator.fit(training_data_uri)
当您在屏幕上看到的内容类似于以下截屏时,即表明模型训练已经开始。
在模型训练过程完成后,我们可以将模型部署为终端节点,详见以下代码:
predictor = ncf_estimator.deploy(initial_instance_count=1,
instance_type='ml.c5.xlarge',
endpoint_type='tensorflow-serving')
使用模型进行推理
如果想使用测试数据集在终端节点做推理,那么可以使用跟TensorFlow Serving相同的方式来调用模型:
# Define a function to read testing data
def _load_testing_data(base_dir):
""" load testing data """
df_test = np.load(os.path.join(base_dir, 'test.npy'))
user_test, item_test, y_test = np.split(np.transpose(df_test).flatten(), 3)
return user_test, item_test, y_test
# read testing data from local
user_test, item_test, test_labels = _load_testing_data('./ml-latest-small/s3/')
# one-hot encode the testing data for model input
with tf.Session() as tf_sess:
test_user_data = tf_sess.run(tf.one_hot(user_test, depth=n_user)).tolist()
test_item_data = tf_sess.run(tf.one_hot(item_test, depth=n_item)).tolist()
# make batch prediction
batch_size = 100
y_pred = []
for idx in range(0, len(test_user_data), batch_size):
# reformat test samples into tensorflow serving acceptable format
input_vals = {
"instances": [
{'input_1': u, 'input_2': i}
for (u, i) in zip(test_user_data[idx:idx+batch_size], test_item_data[idx:idx+batch_size])
]}
# invoke model endpoint to make inference
pred = predictor.predict(input_vals)
# store predictions
y_pred.extend([i[0] for i in pred['predictions']])
对于我们指定进行推理的每个用户-条目对,模型输出结果将是一组概率,范围从0到1。为了做出最终二分类的判定,例如喜欢或不喜欢,我们需要选择一个阈值。这里方便演示,选取0.5作为阈值。如果预测得到的概率等于或大于0.5,则代表模型预测认为用户会喜欢该条目,反之则是不喜欢。
# combine user id, movie id, and prediction in one dataframe
pred_df = pd.DataFrame([
user_test,
item_test,
(np.array(y_pred) >= 0.5).astype(int)],
).T
# assign column names to the dataframe
pred_df.columns = ['userId', 'movieId', 'prediction']
最后,我们可以整理出一份关于用户是否喜欢某部电影的模型预测列表,如以下截屏所示。
总结
推荐系统的设计是一项艰巨的任务,有时需要对模型进行全面定制。在本文中,我们共同了解了如何在Amazon SageMaker当中从零开始实现、部署并调用NCF模型。以此为基础,大家可以运用自己的数据集打造出更适合自身场景的解决方案。
关于使用Amazon SageMaker内置算法,以及使用 Amazon Personalize构建推荐系统解决方案的具体操作说明,请参阅:
要进一步对NCF进行自定义,大家可以使用深度矩阵分解Deep Matrix Factorization (Xue等,2017年)模型。关于更多详细信息,请参阅在AWS上构建推荐引擎。
本篇作者