Artificial Intelligence
Extending Amazon SageMaker factorization machines algorithm to predict top x recommendations
Amazon SageMaker gives you the flexibility that you need to address sophisticated business problems with your machine learning workloads. Built-in algorithms help you get started quickly. In this blog post we’ll outline how you can extend the built-in factorization machines algorithm to predict top x recommendations.
This approach is ideal when you want to generate a set number of recommendations for users in a batch fashion. For example, you can use this approach to generate the top 20 products that a user is likely to buy from a large set of users and product purchase information. You can then store the recommendations in a database for further use, such as dashboard display or personalized email marketing. You can also automate the steps outlined in this blog for periodic retraining and prediction using AWS Batch or AWS Step Functions.
A factorization machine is a general-purpose supervised learning algorithm that you can use for both classification and regression tasks. This algorithm was designed as an engine for recommendation systems. It extends the collaborative filtering approach by learning a quadratic function over the features while restricting second order coefficients to a low rank structure. This restriction is well-suited for large and sparse data because it avoids overfitting and is highly scalable, so that a typical recommendation problem with millions of input features will have millions of parameters rather than trillions
The model equation for factorization machines is defined as:
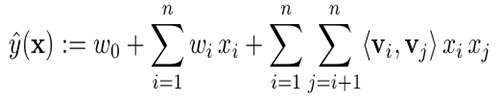
Model parameters to be estimated are:
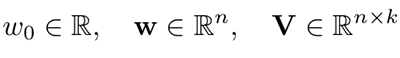
where, n is the input size and k is the size of the latent space. These estimated model parameters are used to extend the model.
Model extension
The Amazon SageMaker factorization machines algorithm allows you to predict a score for a pair, such as user, item, based on how well the pair matches. When you apply a recommendation model, you often want to provide a user as input and receive a list of the top x items that best match the user’s preferences. When the number of items is moderate, you can do this by querying the model for user, item for all possible items. However, this approach doesn’t scale well when the number of items is large. In this scenario, you can use the Amazon SageMaker k-nearest neighbors (k-NN) algorithm to speed up top x prediction tasks.
The following diagram provides a high-level overview of the steps covered in this blog post, which include building a factorization machines model, repackaging model data, fitting a k-NN model, and producing top x predictions.

You can also download a companion Jupyter notebook to follow along. Each of the following sections corresponds to a section in the notebook so that you can run the code for each step as you read.
Step 1: Building a factorization machines model
See Part 1 of the companion Jupyter notebook for steps to build a factorization machines model. To learn more about building factorization machines models, see the Factorization Machines documentation.
Step 2: Repackaging model data
The Amazon SageMaker factorization machines algorithm leverages Apache MXNet deep learning framework. In this section, we’ll cover how to repackage the model data using MXNet.
Extract the factorization machines model
First, you’ll download the factorization model, and then you’ll decompress it for constructing an MXNet object. The main purpose of the MXNet object is to extract the model data.
Extract model data
The input to a factorization machines model is a list of vectors xu + xi representing user u and item i coupled with a label, such as a user rating for a movie. The resulting input matrix will include sparse one-hot encoded values for users, items, and any additional features you may want to add.
The factorization machines model output consists of three N-dimensional arrays (ndarrays):
- V – a (N x k) matrix, where:
- k is the dimension of the latent space
- N is the total count of users and items
- w – an N-dimensional vector
- b – a single number: the bias term
Complete the steps below to extract the model output from the MXNet object.
Prepare data to build a k-NN model
Now you can repackage the model data extracted from the factorization machines model to build a k-NN model. This process will create two datasets:
- Item latent matrix – for building the k-NN model
- User latent matrix – for inference
Step 3: Fitting a k-NN model
Now you can upload the k-NN model input data to Amazon S3, create a k-NN model, and save it so that it can be used in Amazon SageMaker. The model will also come in handy for calling batch transforms, as described in the following steps.
The k-NN model uses the default index_type (faiss.Flat). This model is precise, but it can be slow for large datasets. In such cases, you may want to use a different index_type parameter for an approximate but faster answer. For more information about index types, see either the k-NN documentation or this Amazon Sagemaker Examples notebook.
Step 4: Predicting Top x recommendations for all users
The Amazon SageMaker batch transform feature lets you generate batch predictions at scale. For this example, you’ll start by uploading user inference input to Amazon S3, and then you’ll trigger a batch transform.
The resulting output file will contain predictions for all users. Each line item in the output file is a JSON line containing item IDs and distances for a specific user.
Here’s a sample output for a user. You can store the recommended movie IDs to your database for further use.
Multiple features and categories scenario
The framework in this blog applies to a scenario with user and item IDs. However, your data may include additional information, such as user and item features. For example, you might know the user’s age, zip code, or gender. For the item, you might have a category, a movie genre, or important keywords from a text description. In these multiple-feature and category scenarios, you can use the following to extract user and item vectors:
- encode xi with both the users and user features:
ai =concat(VT · xi , wT · xi) - encode xu with items and item features:
au =concat(VT · xu, 1)
Then use ai to build the k-NN model and au for inference.
Conclusion
Amazon SageMaker gives developers and data scientists the flexibility to build, train, and deploy machine learning models quickly. Using the framework outlined above, you can build a recommendation system for predicting the top x recommendations for users in a batch fashion and cache the output in a database. In some cases you may need to apply further filtering on predictions or filter out some of the predictions based on user responses over the time. This framework is flexible enough to modify for such use cases.
About the Authors
 Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
 Rama Thamman is a Sr. Solution Architect with the Strategic Accounts team. He works with customers to build scalable cloud and machine learning solutions on AWS.
Rama Thamman is a Sr. Solution Architect with the Strategic Accounts team. He works with customers to build scalable cloud and machine learning solutions on AWS.