亚马逊AWS官方博客
Mountpoint S3 与 S3 Files 在 EKS 上的实战对比
摘要:本文对比了在 EKS 上通过 Mountpoint S3 CSI 和 S3 Files + EFS CSI 两种方案访问 S3 数据的差异。Mountpoint S3 是基于 FUSE 的轻量客户端,设计目标是高吞吐而非完整 POSIX 语义;S3 Files 是 2026 年 4 月 GA 的新服务,通过 NFSv4.1+ 协议和全托管智能缓存层,首次让 S3 原生支持完整文件系统语义。
两种方案并非互斥,工作负载特征互补,在同一 EKS 集群中混合部署、按场景选型,是当前 AWS 上 S3 数据接入的最佳实践。
目录
一、背景
随着AI/ML工作负载在Kubernetes上的普及,如何高效访问存储在S3上的海量数据集成为一个关键问题。S3作为事实上的数据湖标准,承载了大量训练数据、模型文件和推理数据,但其对象存储的本质与AI框架期望的POSIX文件接口之间存在天然鸿沟。
二、S3在AI场景下的技术挑战
2.1 接口差异
S3对象存储与传统文件系统存在根本性差异:
| 特性 | S3对象存储 | 传统文件系统 |
| 访问接口 | RESTful HTTP API | POSIX接口 |
| 访问模式 | 对象全量覆盖 | 支持文件随机读写 |
| 一致性模型 | read-after-write一致性 | 强一致性 |
| 元数据 | 对象级元数据 | 文件级inode |
| 原子操作 | 对象级原子(PUT/DELETE) | 字节级原子(write/rename) |
2.2 性能瓶颈
每次HTTP GET请求都是独立的,缺乏相关性。这意味着:
- 小文件场景:频繁的HTTP请求带来高延迟,每次请求至少数十毫秒
- 随机读场景:没有类似XFS文件系统的page cache机制,无法利用本地缓存加速
- 训练场景:数据加载成为GPU利用率的瓶颈
2.3 业务痛点
AI场景下,大量的数据集都在S3上面,既有大文件(模型权重文件),也有海量小文件场景(图像数据集、文本语料),迫切需要针对S3上的对象的高性能访问方案。
三、S3挂载的主流方案
社区有 s3fs-fuse 这类老牌方案,但 Amazon Linux 2023 的官方源已经不再提供 s3fs-fuse 的 rpm 包,本文不再赘述。目前 亚马逊云科技上主流的两种方案是 Mountpoint S3 和 S3 Files,它们的设计理念和技术实现存在根本性差异。
3.1 Mountpoint S3:亚马逊云科技的工程化答案
Mountpoint S3是亚马逊云科技官方推出的开源FUSE客户端,用Rust编写,专为高吞吐场景优化。它的设计理念并不试图模拟完整的POSIX语义,而是在S3能力范围内提供最优性能。
核心特点:
- 高吞吐:单个EC2实例到S3的传输带宽可达100 Gbps
- 明确的语义边界:不支持随机写、rename等S3无法原子实现的操作(详见 https://github.com/awslabs/mountpoint-s3/blob/main/doc/SEMANTICS.md)
- 可选缓存:支持本地磁盘缓存或S3 Express One Zone作为共享缓存
- 低资源开销:Rust实现,内存占用小
3.2 S3 Files:亚马逊云科技的技术创新
2026年4月7日GA的S3 Files是S3历史上的一次重大创新——首次让对象存储原生支持完整的文件系统语义,且不牺牲性能。
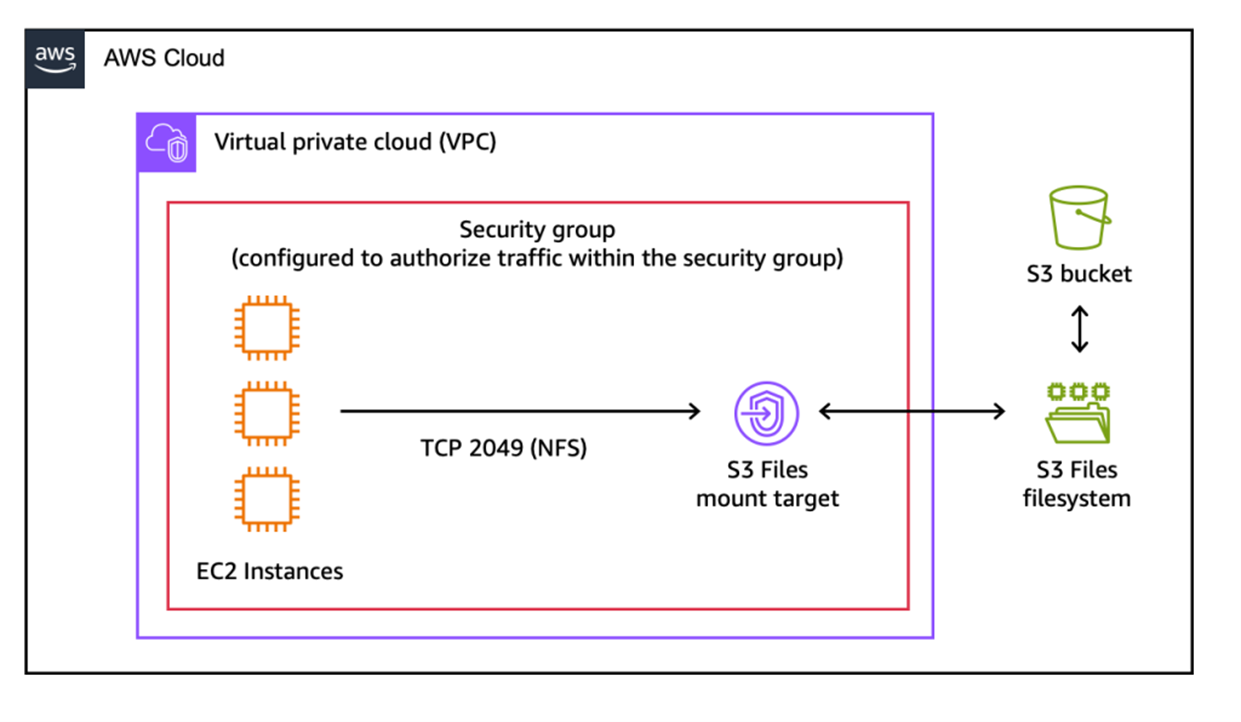
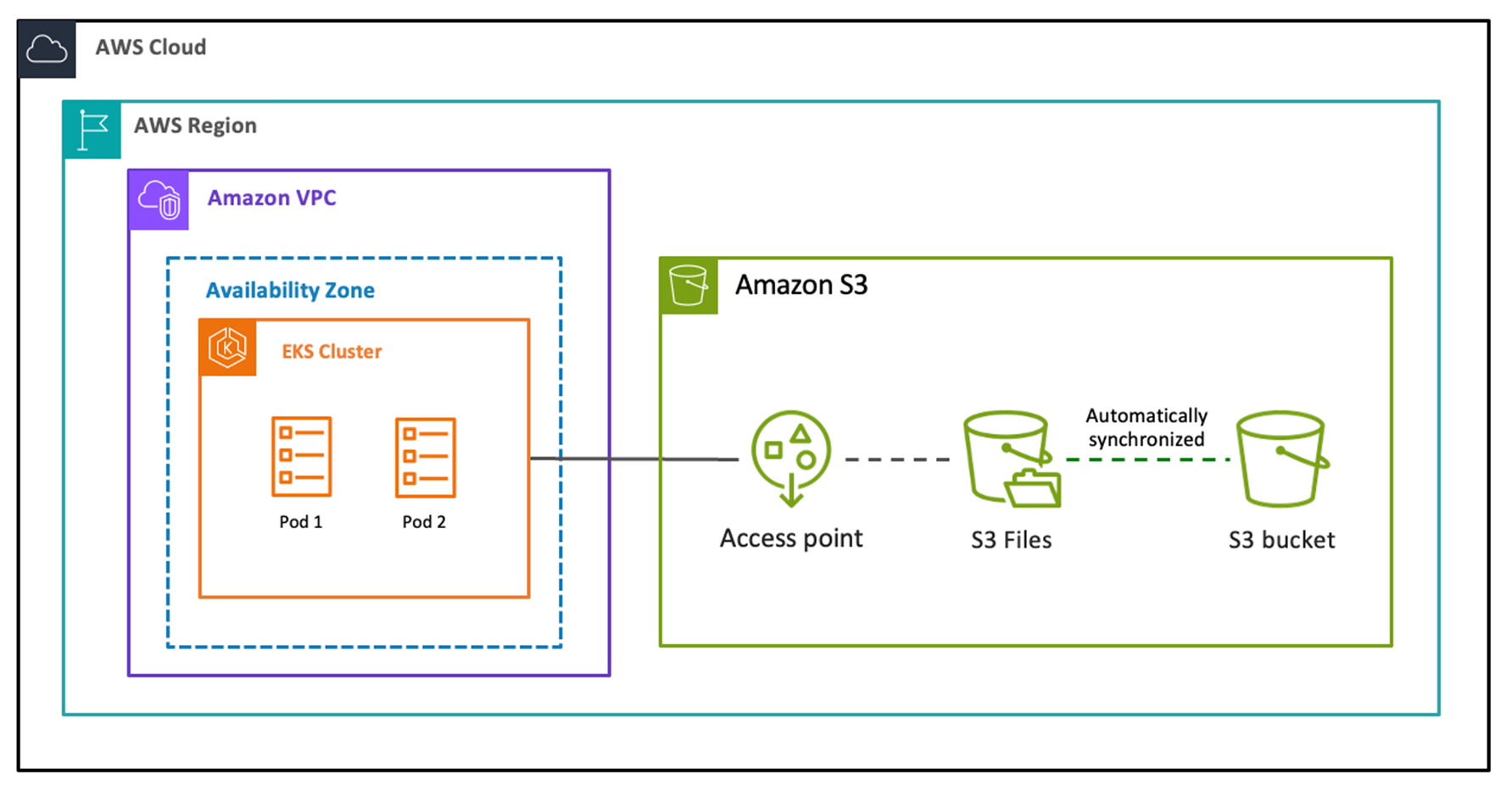
3.2.1 架构创新:NFS协议 + 智能缓存层
S3 Files的核心创新是在S3和计算资源之间引入了一个全托管高性能存储层,通过 NFSv4.1+ 协议对外提供服务:
[图1] |
关键特性:
- 提供基于 NFSv4.1+ 协议的接入,POSIX 语义
- 智能数据分层:小文件缓存 + 大文件直读
- 自动维护文件系统与 S3 之间的双向同步
- close-to-open 一致性
与前两代方案的根本区别在于:S3 Files不是FUSE方案。它并不在用户态实现文件系统,而是提供了一个真正的托管缓存文件系统,底层数据存储在S3中。缓存层完全自动管理,用户配置极其简单。
3.2.2 智能数据分层
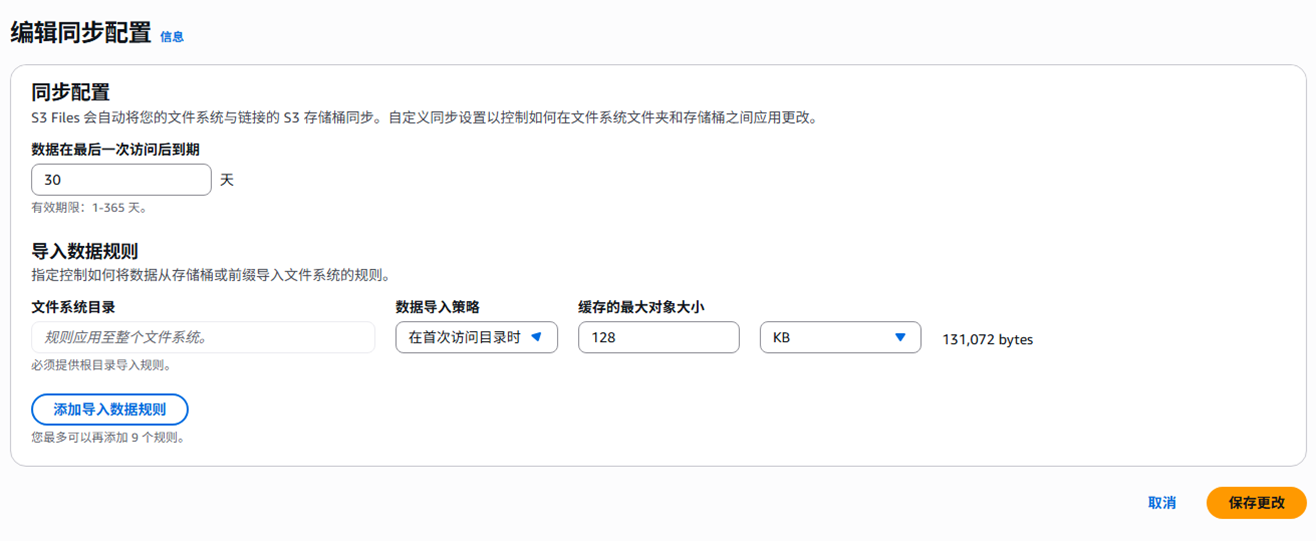
S3 Files最精妙的设计是根据文件大小和访问模式自动选择数据路径。可以选择在目录初次被访问时即缓存目录下所有大小在阈值以下的文件,也可以选择具体文件被访问时才进行缓存;针对不同的子目录还可以设置不同的规则;配合数据过期时间可保证缓存文件系统不会无限增长。
[图2] |
这个设计的巧妙之处在于:小文件的瓶颈是延迟(每次HTTP请求的开销),大文件的瓶颈是吞吐(S3本身已经很擅长)。针对两种场景分别优化,而不是用一种策略应对所有情况。亚马逊云科技针对不同情况提供了示例配置 https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-files-synchronization-customizing.html#s3-files-sync-example-configs
3.2.3 双向同步与一致性
S3 Files采用NFS close-to-open一致性模型:
- 写入路径:数据先写入高性能存储,后台异步同步到S3
- 读取路径:按需从S3加载到高性能存储,或直接从S3流式读取
- 一致性保证:当一个客户端close文件以后,其他客户端open时能看到最新数据
四、EKS上的部署实践
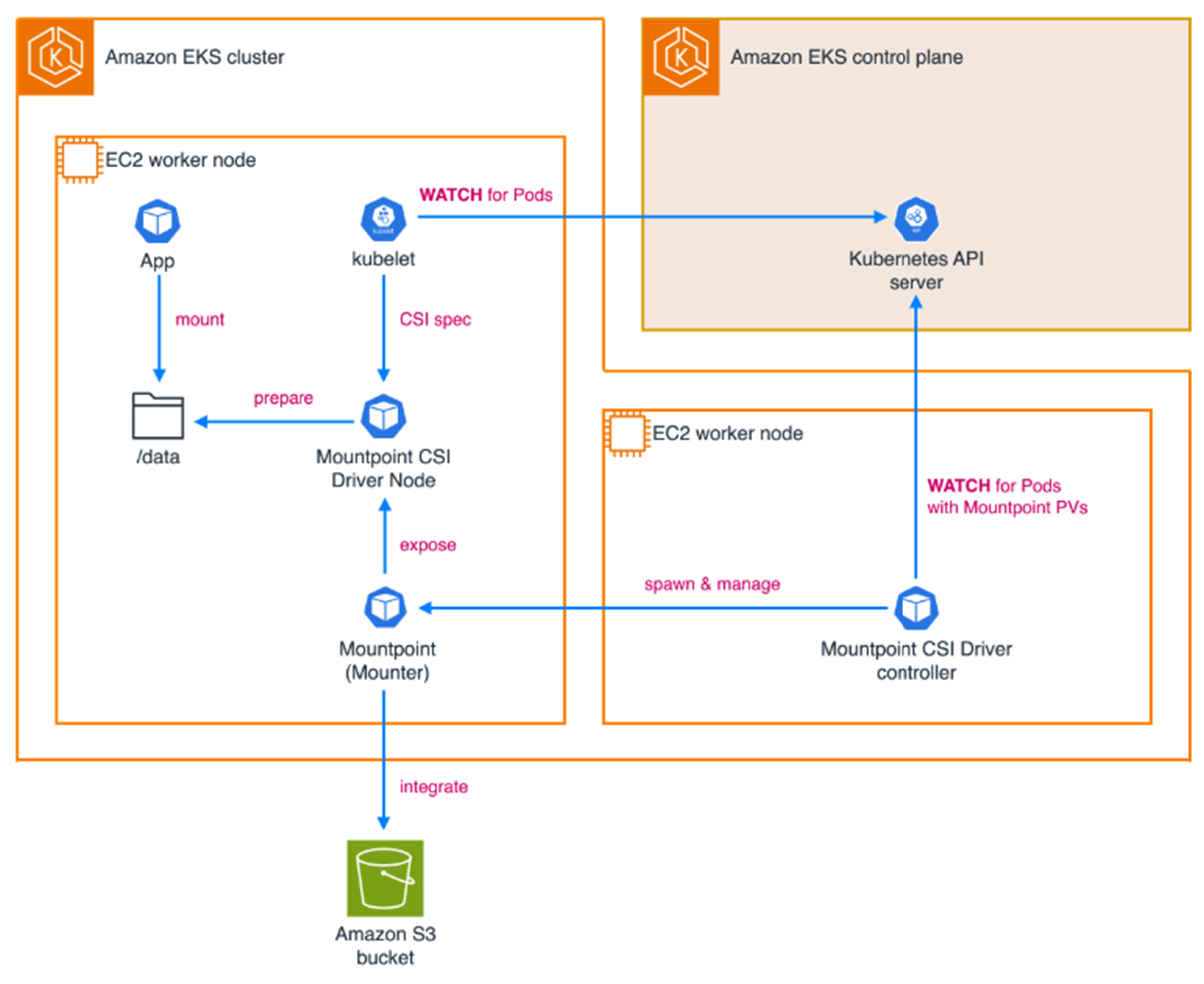
4.1 Mountpoint S3 CSI Driver
Mountpoint S3 CSI Driver这个方案,是启动专门的mounter pod,在mounter pod内部使用Mountpoint FUSE客户端将S3 bucket挂载到EKS节点上。然后Kubernetes再将其映射到业务pod。
[图3] |
- 在EKS控制台页面,安装aws-mountpoint-s3-csi-driver插件
[图4] |
- 以pv静态制备场景举例,无需创建storageclass,而是直接创建pv、pvc、pod即可
- 待pod运行起来之后,可以看到S3 bucket是以fuse方式挂载的
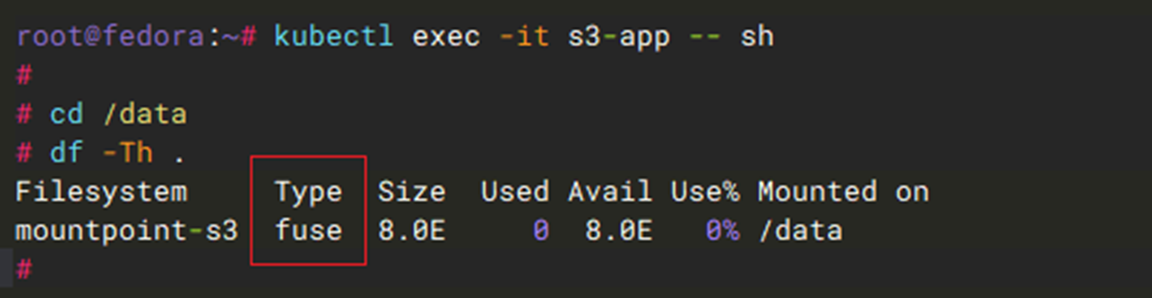
[图5] |
- 并且在mount-s3命名空间下,aws-mountpoint-s3-csi-driver还自动创建一个与pv的name关联的mounter pod。mounter pod会调度到与使用pv的业务pod相同的EKS节点,目的如前所述是为了将S3 bucket挂载到节点上
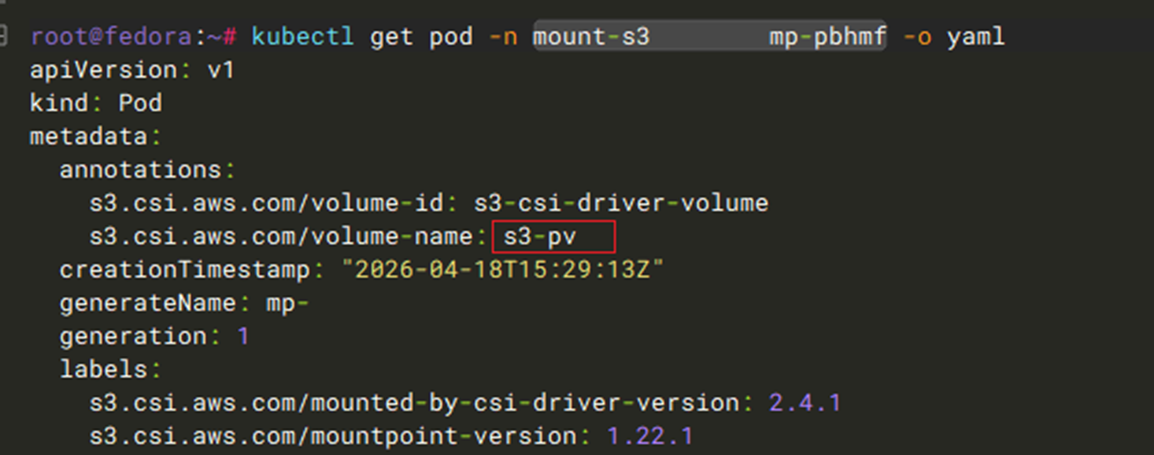
[图6] |
4.2 S3 Files + EFS CSI Driver
EKS容器挂载S3 Files文件系统的方案,是标准的NFS挂载,由内核NFS客户端处理,不需要额外的mounter Pod。
[图7] |
- 在EKS控制台页面,安装aws-efs-csi-driver插件
[图8] |
- 在S3控制台页面,选择一个S3 bucket或者bucket下的prefix,创建文件系统,将创建好的文件系统ID记录下来
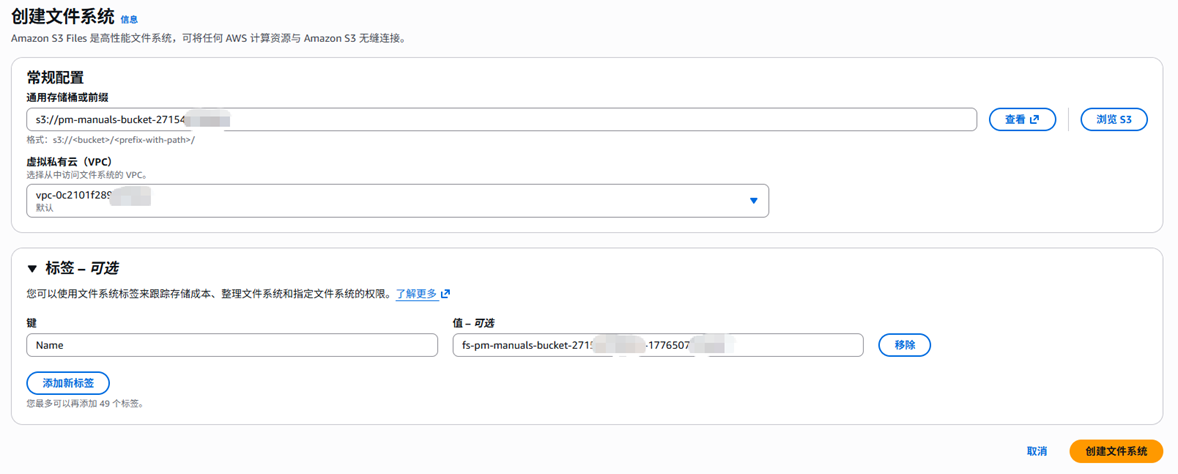
[图9] |

[图10] |
- 以pv静态制备场景举例,无需创建storageclass,而是直接创建pv、pvc和pod
- 待pod运行起来之后,可以看到pod是以NFS协议挂载S3 Files文件系统。此外pv的capacity在这里只是用于pv和pvc的匹配绑定,并不是在文件系统层面的限制使用量
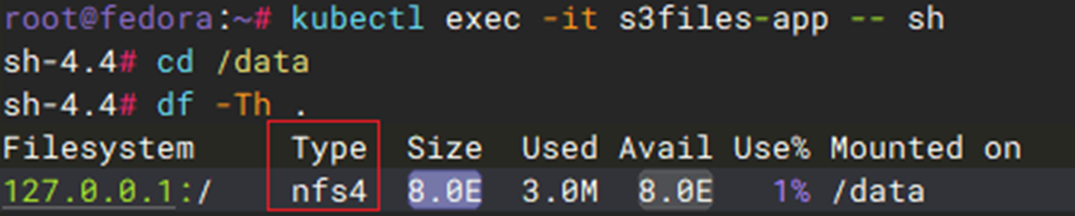
[图11] |
五、性能测试对比
为了量化两种方案在实际AI工作负载下的表现差异,我们设计了一组覆盖典型存储访问模式的性能测试。
5.1 测试环境
| 配置项 | 说明 |
| EKS版本 | 1.35.2 |
| 节点实例 | m7i.4xlarge(16 vCPU, 64 GiB, 最高12.5 Gbps网络) |
| S3 Bucket | 同Region(us-east-1),Standard存储类 |
| Mountpoint S3 CSI | Mountpoint S3 CSI v2.4.1-eksbuild.1版本 |
| S3 Files + EFS CSI | EFS CSI v3.0.0-eksbuild.1版本 |
| 测试工具 | fio 3.36 |
测试方法说明
- Mountpoint S3 不支持随机写和追加写,因此本文未对其执行随机写测试,顺序写测试也仅在新建文件上进行。
- 用例三为 Mountpoint S3 配置了 S3 Express One Zone 共享缓存(–cache-xz),以测试缓存对小文件场景的影响;其余用例均使用默认配置,不启用缓存。
- S3 Files 的”冷读”指文件首次从 S3 拉取到高性能存储层的状态,”热读”指数据已驻留缓存层后的重复访问。冷读测试在新建文件系统或缓存过期后执行,热读为冷读完成之后立即重复执行同一命令的结果。
- S3 Files的同步策略为 on-first-directory-access,小文件阈值 512 KiB。
5.2 测试用例与结果
用例一:大文件顺序读吞吐
模拟从S3加载大模型权重文件(如Mixtral-8x7B-v0.1的单个分片约5 GB)。
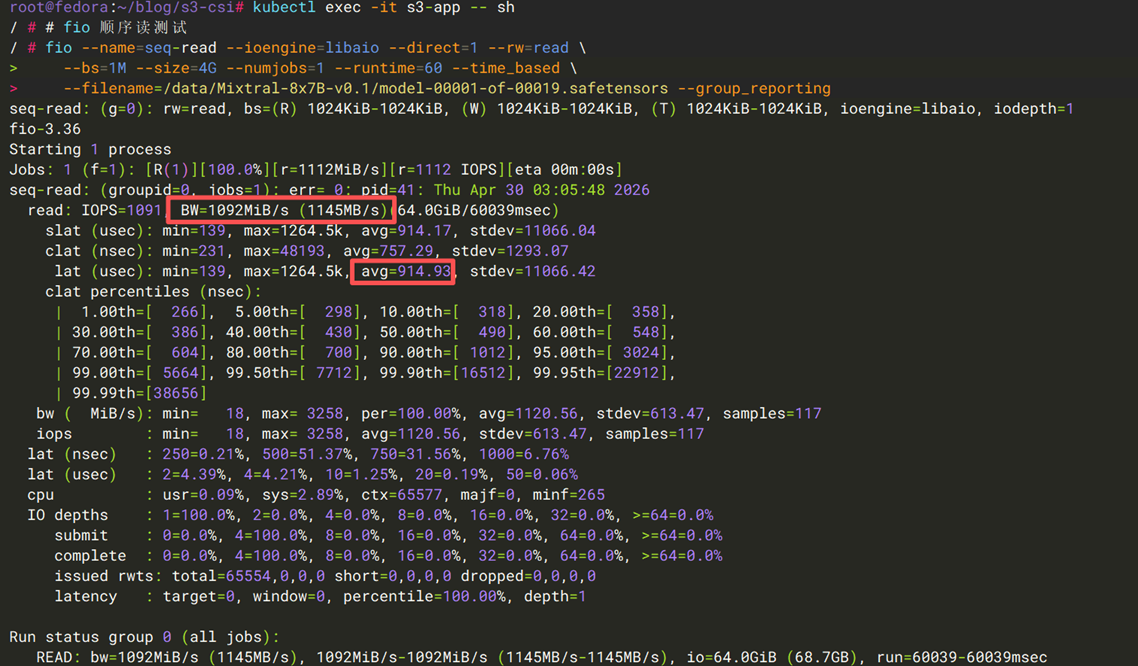
[图12] |
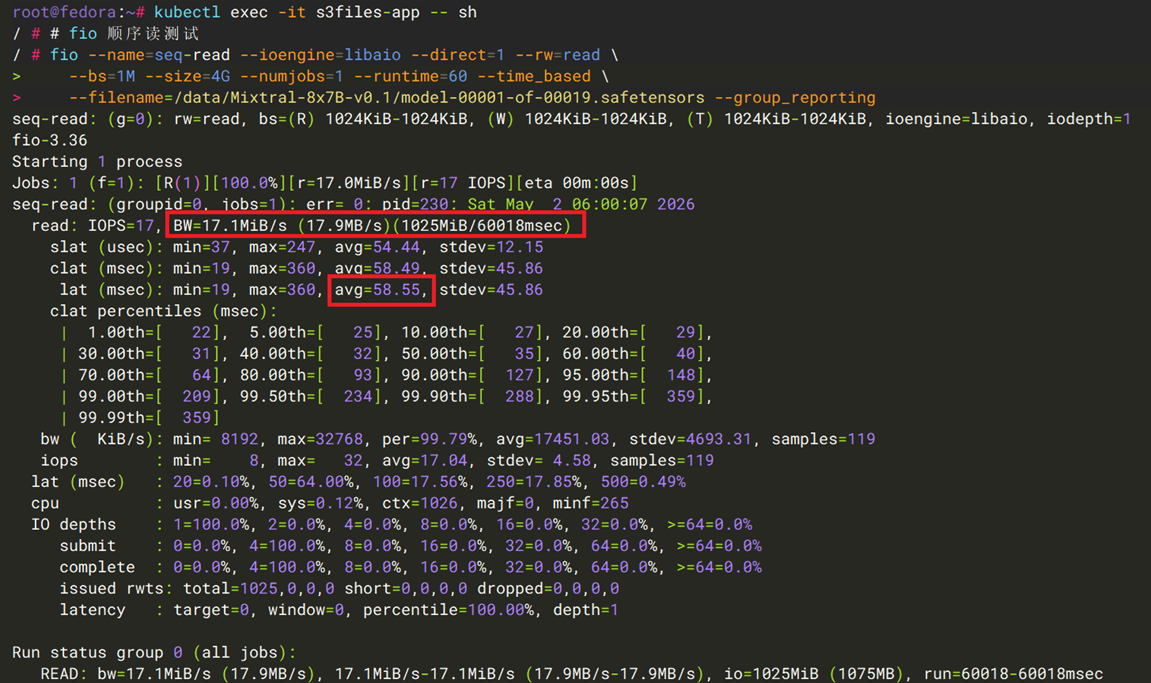
[图13] |
| 指标 | Mountpoint S3 CSI | S3 Files + EFS CSI |
| 吞吐量 | ~1.1 GB/s | ~17.9 MB/s |
| 单次 I/O 延迟(1 MB 块) | ~0.9 ms | ~58.5 ms |
结论:S3 Files 走的是大文件直读路径(4 GB 文件远超 512 KiB 的小文件缓存阈值),并未经过缓存层。而Mountpoint S3的对象预取技术,会在读取请求之前将对象内容下载到内存中,以优化顺序读取吞吐量,这使得Mountpoint S3 CSI在顺序读场景下的优势明显 https://github.com/awslabs/mountpoint-s3/blob/main/doc/CONFIGURATION.md#maximum-prefetch-window-size。从测试结果能看到,对接Mountpoint S3 CSI的测试pod,读带宽已接近其所在的EC2实例的网络带宽上限。
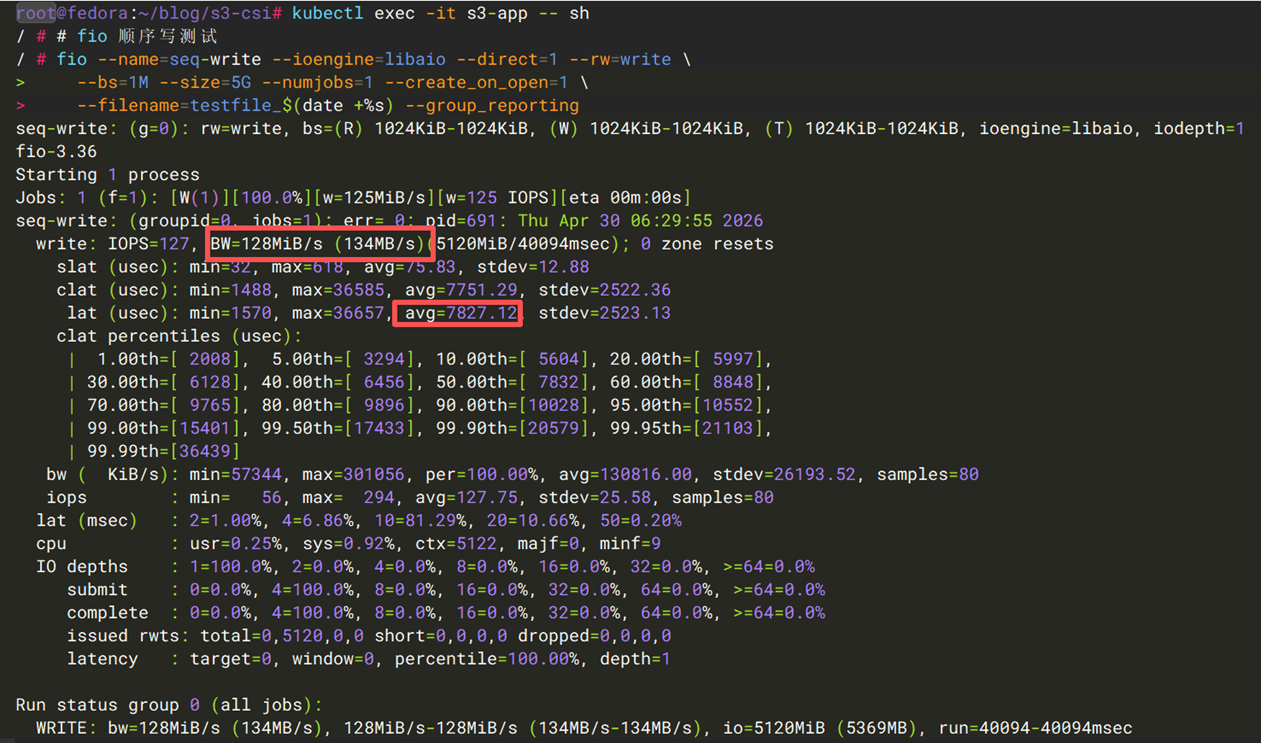
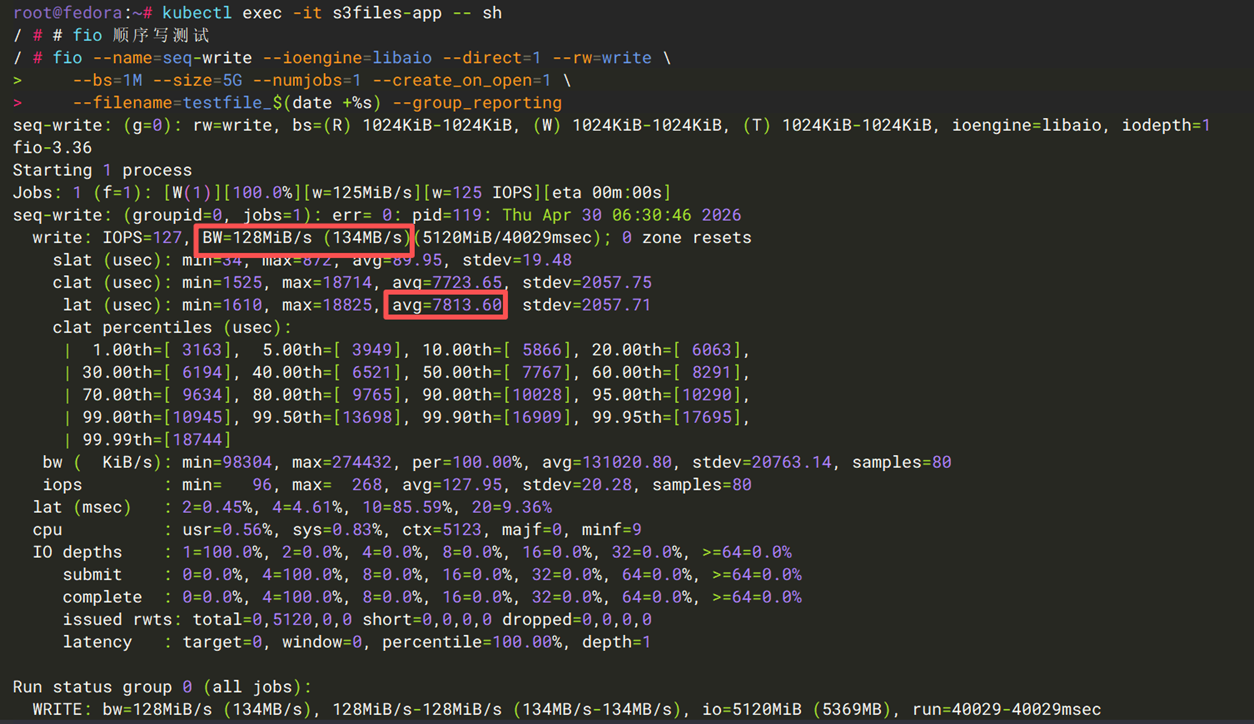
用例二:顺序写吞吐
LLM训练中需要周期性保存和恢复checkpoint(单个checkpoint含模型权重、优化器状态和训练元数据)。使用下面的命令,模拟训练checkpoint保存或推理结果写出。
[图14] |
[图15] |
| 指标 | Mountpoint S3 CSI | S3 Files + EFS CSI |
| 吞吐量 | ~134MB/s | ~134MB/s |
| 平均延迟 | ~7.82 ms/op | ~7.81 ms/op |
结论:单文件顺序写场景两者表现相当(均约 134 MB/s)。Mountpoint S3 通过 multipart upload 实现高吞吐写入,S3 Files 先写入高性能存储层再异步同步到 S3。需要注意的是,Mountpoint S3 仅支持新建文件的顺序写(不支持追加写和随机写),而 S3 Files 支持任意写入模式。
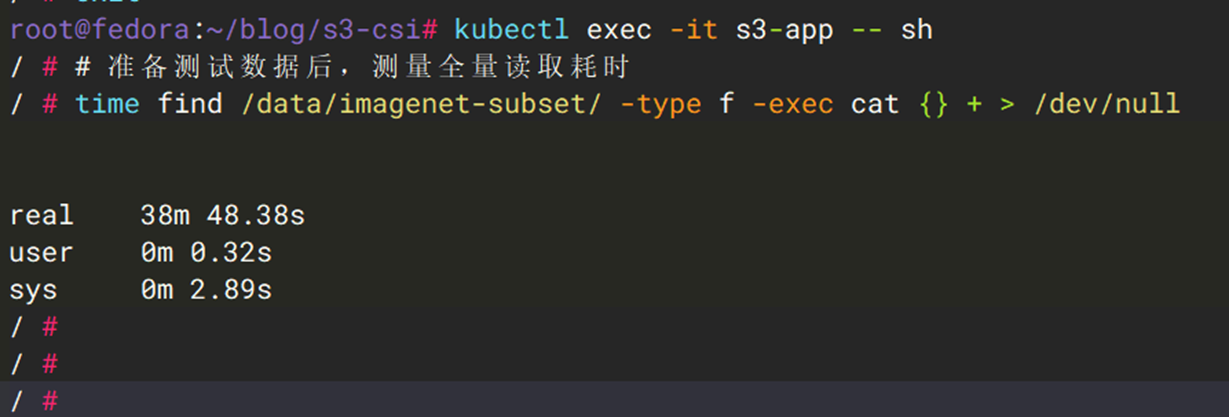
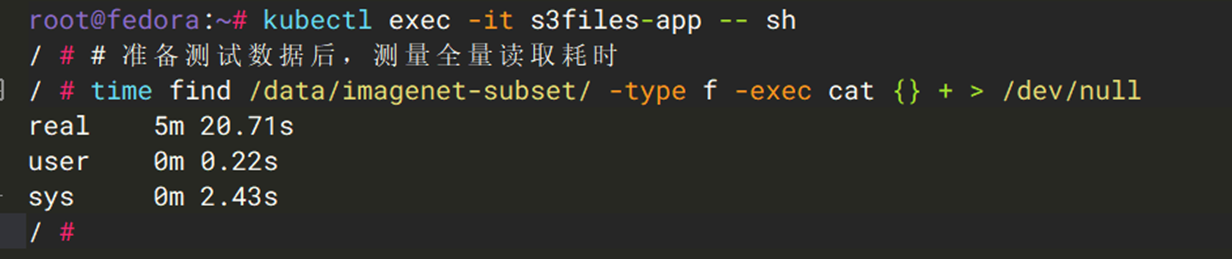
用例三:海量小文件读取(目录遍历 + 读取)
采用如下命令,模拟ImageNet图像数据集加载:24,000 余个 20 KiB 的文件分布在40个子目录中。在这个用例里,配置对接Mountpoint S3 CSI的测试pod,使用S3 Express One Zone作为共享缓存。
[图16] |

[图17] |
[图18] |

[图19] |
| 指标 | Mountpoint S3 CSI + S3 Express One Zone(冷读) | Mountpoint S3 CSI + S3 Express One Zone(热读) | S3 Files(冷读) + EFS CSI | S3 Files(热读) + EFS CSI |
| 总耗时 | ~2320 s | ~169 s | ~320 s | ~100 s |
| 平均单文件耗时 | ~94 ms | ~7 ms | ~13 ms | ~4 ms |
结论:S3 Files 冷读时通过目录级批量预取大幅减少请求次数,热读时数据已在高性能存储层,延迟降至个位数毫秒。而Mountpoint S3 即使配置共享缓存层,延迟相对S3 Files依然存在差距。 对于小文件密集型的 AI 训练数据加载,S3 Files 的优势显著。
用例四:随机读(模拟特征检索 / Embedding查找)
RAG(检索增强生成)场景中,推理服务从预计算的Embedding文件中按索引随机读取向量。文件为内存映射格式,每次查询需要从不同偏移位置读取若干个向量。采用如下命令,模拟推理阶段从大型Embedding文件中随机读取向量片段。
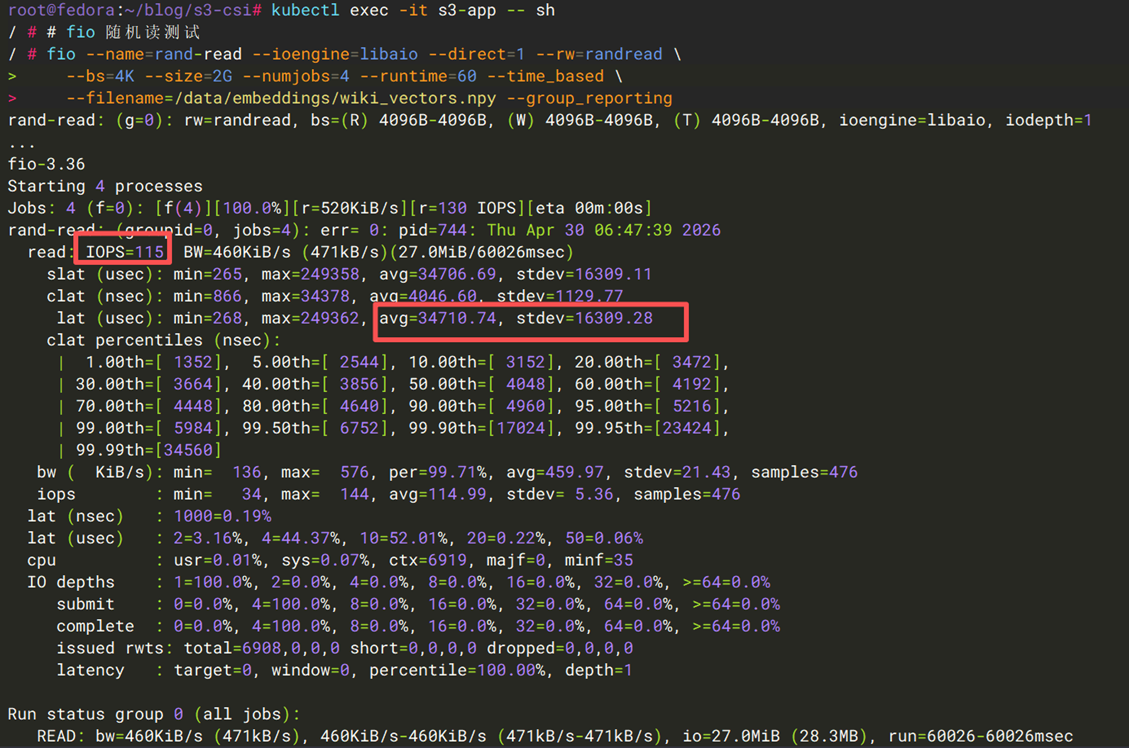
[图20] |
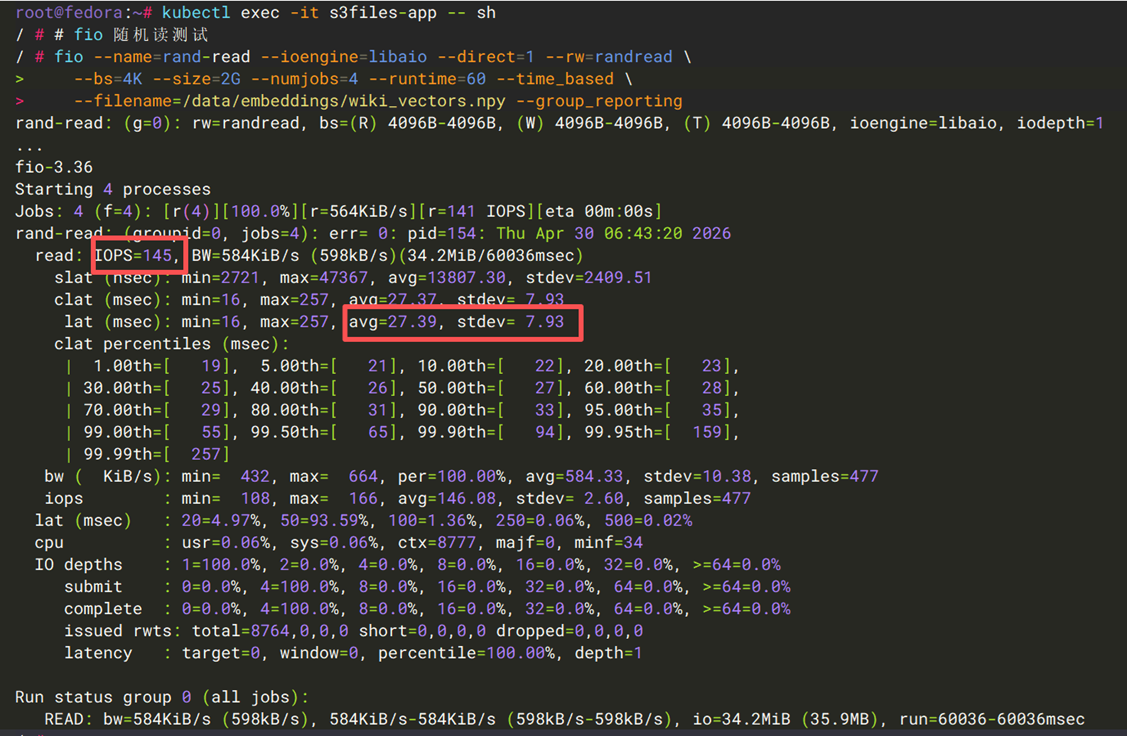
[图21] |
| 指标 | Mountpoint S3 CSI | S3 Files(热读) + EFS CSI |
| IOPS | ~115 | ~145 |
| 平均延迟 | ~34.7 ms | ~27.39 ms |
| 延迟标准差 | ~16.3 ms | ~7.93 ms |
结论:随机读情况下,S3 Files 在 IOPS、平均延迟、延迟标准差等方面均有一定优势。对于需要随机访问的Embedding查找、特征检索等场景,S3 Files是更合适的选择。
5.3 测试结果汇总
| 测试场景 | Mountpoint S3 CSI | S3 Files + EFS CSI | 优势方 |
| 大文件顺序读(5 GB) | ~1.1 GB/s 吞吐 | ~17.9 MB/s 吞吐 | Mountpoint S3 CSI |
| 小文件批量读(24K × 20 KiB) | 单文件均值 ~7 ms(共享缓存热读) | 单文件均值 ~4 ms(热读) | S3 Files + EFS CSI |
| 顺序写(5 GB,单线程) | ~134 MB/s 吞吐 | ~134 MB/s 吞吐 | 基本持平 |
| 随机读 4K(多线程) | ~115 IOPS,延迟波动偏大 | ~145 IOPS(热读),延迟稳定 | S3 Files + EFS CSI |
5.4 性能测试总结
从实际测试结果可以看出两个方案的性能特征差异明显:
- 大文件顺序读:Mountpoint S3 CSI在单个大文件顺序读场景下优势明显
- 顺序写:单文件顺序写场景两者表现一致(均约 134 MB/s);但 Mountpoint S3 仅支持新建文件的顺序写,S3 Files 支持任意写入模式
- 小文件密集读取:S3 Files 优势明显,智能缓存层显著降低小文件无法摊薄的 HTTP 往返开销
- 随机读:S3 Files 在 IOPS、平均延迟、延迟标准差上均有一定优势,更适合 Embedding 检索等场景
六、选型建议
6.1 功能对比
| 特性 | Mountpoint S3 CSI | S3 Files + EFS CSI |
| 接入协议 | FUSE | NFSv4.1+ |
| K8s 集成 | CSI Driver(含 mounter pod) | CSI Driver(复用内核 NFS 客户端) |
| POSIX兼容性 | 明确限制 | 完全兼容 |
| 缓存机制 | 可选(本地缓存/Express One Zone共享缓存) | 全托管智能缓存 |
| 随机写 | 不支持 | 支持 |
| rename | 不支持(结合S3 Express One Zone作为缓存可以支持 rename) | 支持 |
| 制备模式 | 目前只支持静态制备 | 静态和动态制备均支持 |
| 运维复杂度 | 中 | 低(全托管) |
| 成本 | 仅S3费用 | S3 + 高性能存储 |
6.2 场景化推荐
根据工作负载特征对应的推荐方案:
| 工作负载特征 | 推荐方案 | 主要理由 |
| 大文件顺序读为主(模型加载、数据湖分析) | Mountpoint S3 CSI | 顺序读吞吐优势明显 |
| 日志写入、模型导出等顺序写 | Mountpoint S3 CSI | 顺序写吞吐与 S3 Files 持平,且成本更低 |
| AI 训练数据加载(小文件密集) | S3 Files + EFS CSI | 智能缓存层显著降低小文件访问延迟 |
| Embedding 检索、特征查找等随机读 | S3 Files + EFS CSI | 随机读 IOPS 与延迟稳定性更优 |
| 需要随机写、rename 等完整 POSIX 语义 | S3 Files + EFS CSI | 原生支持完整 POSIX |
混合部署策略:两种方案的 CSI 可以安装在同一个 EKS 集群,根据不同业务场景选择合适的 PV 对接,发挥两者各自的优势。
七、总结
从 s3fs-fuse 到 Mountpoint S3,再到 S3 Files,S3 的上层访问方案正从”对象存储的兼容补丁”演进为”原生支持文件语义的托管服务”。
对 EKS 用户而言,Mountpoint S3 与 S3 Files 并非互斥选择——两者覆盖的工作负载特征互补,按需混合部署、各取所长,才是当前 亚马逊云科技上 S3 数据接入的最佳实践。
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon EFS — 弹性文件存储
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon EC2 — 安全且可调整大小的计算容量
相关文章:
- 推出 S3 Files:使 S3 存储桶能够以文件系统形式直接访问
- 用 Kiro CLI 自动搭建 FluentBit 日志采集方案:两种 EKS 埋点数据落地 S3 Parquet 的实战对比
- 给 Openclaw瘦身-利用Nova MME 和 S3 Vector实现Skill按需召回
- 向量存储成本降低 85%:用 Amazon S3 Vectors 构建企业级多平台统一知识库
- S3 Tables 实战:两种方案,把 MySQL 数据实时”搬”进 S3 Tables
八、参考资料
- https://github.com/awslabs/mountpoint-s3
- https://github.com/awslabs/mountpoint-s3/blob/main/doc/SEMANTICS.md
- https://github.com/awslabs/mountpoint-s3-csi-driver
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-files.html
- https://aws.amazon.com/blogs/aws/launching-s3-files-making-s3-buckets-accessible-as-file-systems/
- https://docs.aws.amazon.com/eks/latest/userguide/csi-drivers.html
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
