亚马逊AWS官方博客
AQUA(高级查询加速器)– 为您的 Amazon Redshift 查询提速
Amazon Redshift 已在各种规模上提供了比任何其他云数据仓库高出 3 倍的性价比。我们是通过设计自己的硬件和使用机器学习 (ML) 来实现这一目标的。
例如,我们在 2019 年底推出了面向 Amazon Redshift 的基于 SSD 的 RA3 节点 (Amazon Redshift Update – Next-Generation Compute Instances and Managed, Analytics-Optimized Storage),并在去年 4 月 (Amazon Redshift update – ra3.4xlarge Nodes) 和去年 12 月(Amazon Redshift 发布具有托管存储的 RA3.xlplus 节点)添加了额外的节点大小。除了高带宽网络外,RA3 节点还融入了复杂的数据管理模型。正如我在启动 RA3 节点时所说的那样:
每个实例上都有一个基于 SSD 的大容量、高性能存储缓存,由 S3 提供支持,用于进行扩展、实现高性能和持久性。存储系统使用多条提示,包括数据块温度、数据阻塞和工作负载模式来管理缓存,以获得高性能。数据自动放置在适当的层级中,您无需进行任何特殊操作便能从缓存或其他优化中获益。
我们的客户使用 RA3 节点来维护非常大的数据集,并且正在看到很好的结果。从数字互动娱乐到跟踪媒体购买的展示量和效果,Amazon Redshift 和 RA3 节点可以帮助我们的客户在单个数据仓库中存储多达 32 PB 的数据,并查询全球范围内的数据。
不利的一面是,事实证明,即使数据仓库继续增长,存储性能的提升仍然已经超过了 CPU 性能的提升速度。大量数据(通常由需要完全扫描的查询访问所致)再加上网络流量限制,可能导致网络和 CPU 带宽成为限制因素。
对于这种情况,我们可以做些什么…
推出 AQUA
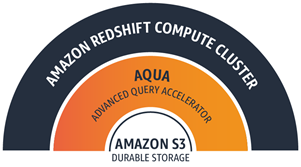 今天,我们通过添加 AQUA(高级查询加速器)使 ra3.4xl 和 ra3.16xl 节点更加强大。基于我之前提到的缓存,利用 AWS Nitro System 和基于 FPGA 的自定义加速,AQUA 将处理减少和聚合查询所需的计算推到更接近数据的位置。这样可以减少网络流量,减少 RA3 节点中 CPU 的工作量,使 AQUA 将这些查询的性能提高 10 倍,而且无需额外费用,也无需更改任何代码。AQUA 还利用与 Amazon Simple Storage Service (S3) 的快速、高带宽连接。
今天,我们通过添加 AQUA(高级查询加速器)使 ra3.4xl 和 ra3.16xl 节点更加强大。基于我之前提到的缓存,利用 AWS Nitro System 和基于 FPGA 的自定义加速,AQUA 将处理减少和聚合查询所需的计算推到更接近数据的位置。这样可以减少网络流量,减少 RA3 节点中 CPU 的工作量,使 AQUA 将这些查询的性能提高 10 倍,而且无需额外费用,也无需更改任何代码。AQUA 还利用与 Amazon Simple Storage Service (S3) 的快速、高带宽连接。
您可以观看此视频,详细了解 AQUA 如何使用 AQUA 节点中定制设计的硬件来加速查询。优势表现在几个不同方面。每个节点都与其他节点并行执行减少和聚合操作。除了由于并行操作而将速度提高 n 倍之外,必须在计算节点上发送和处理的数据量通常要小得多(通常只是原始数量的 5%)。下图显示了所有元素如何共同提高查询速度:
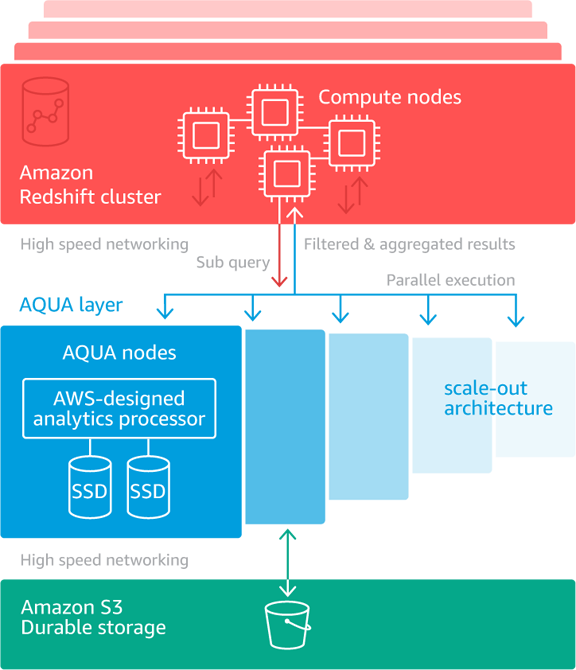
如果您已在使用 ra3.4xl 或 ra3.16xl 节点托管数据仓库,可以在几分钟内开始使用 AQUA。您只需为集群启用 AQUA,重启集群,然后即可从减少和聚合查询的性能大幅提升中获益。如果您已准备好在未来使用 RA3 和 AQUA,可以从现有集群快照创建一个新的基于 RA3 的集群,也可以使用经典调整大小进行就地升级。
使用 AQUA
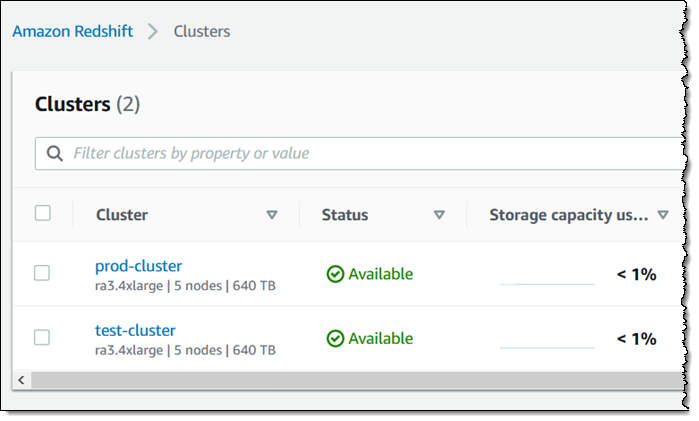
我没有数据仓库! 我以前使用 Redshift 团队提供的快照创建了一对集群。第一个集群 (prod-cluster) 没有启用 AQUA,第二个集群 (test-cluster) 启用了 AQUA:
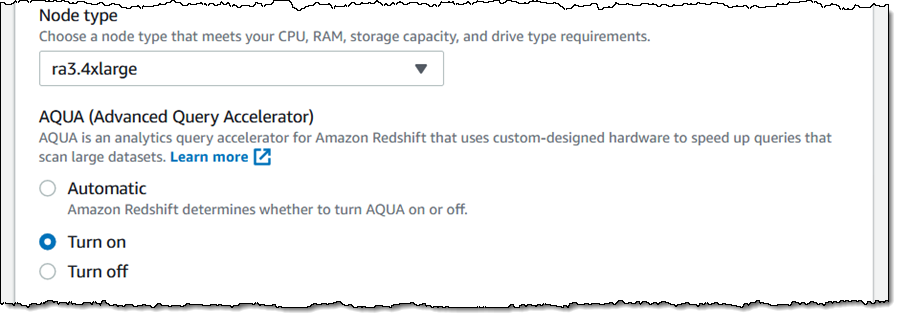
要创建启用了 AQUA 的集群,我只需在 Cluster configuration (集群配置) 页面上选择 Turn on (打开) 即可:
我的查询将使用 lineitem 表,该表有超过 180 亿行:
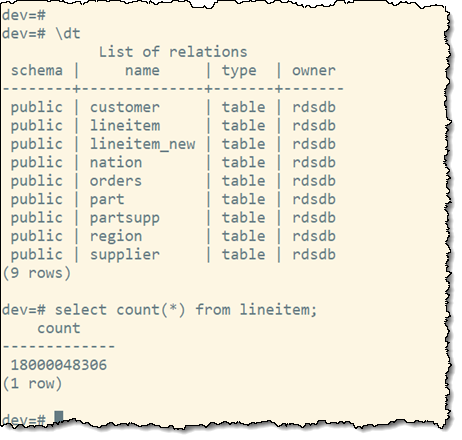
我在每个集群上创建一个会话并禁用 Redshift 结果缓存:
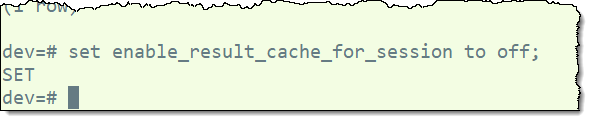
然后我在两个集群上运行相同的查询:
如果您看一下上面的图表(也可以观看视频),就能够明白为什么 AQUA 可以非常有效地处理这种类型的查询了。AQUA 不是按顺序扫描计算节点上的所有 180 亿行内容,而是将 similar to 表达式的集合分发到多个并行运行的 AQUA 节点。
在已启用 AQUA 的集群上进行查询不到一分钟即可完成:
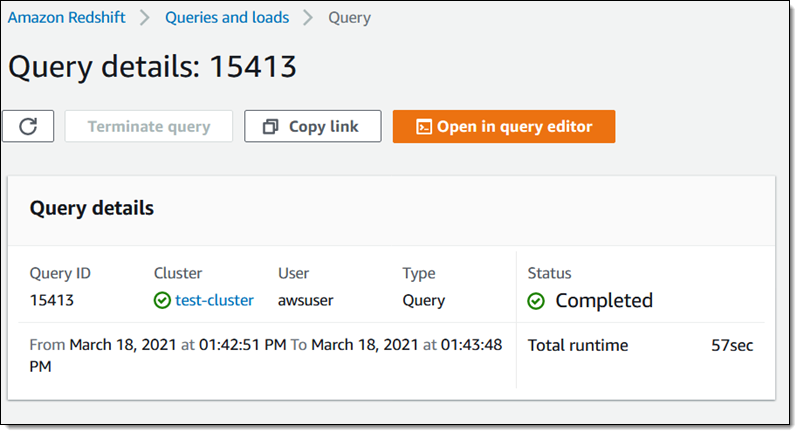
在没有启用 AQUA 的集群上进行查询需要不到 4 分钟时间才能完成:
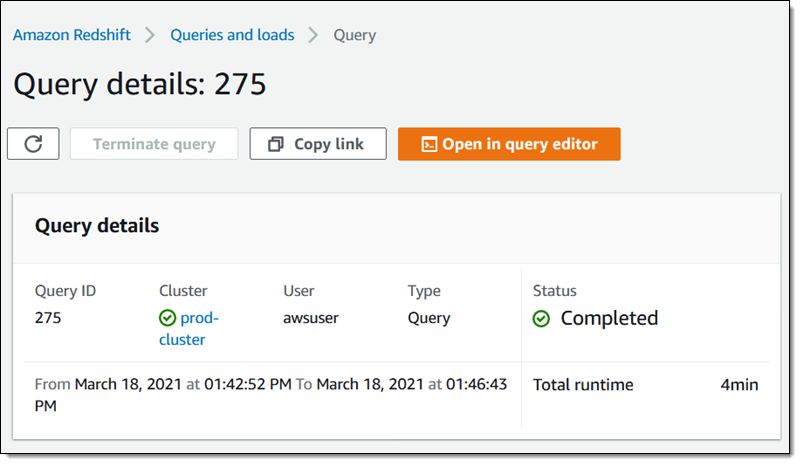
与使用数据库、复杂数据和执行同样复杂的查询时一样,您的里程碑也将有所不同。例如,您可以想象对从多个表中选择的以复杂方式连接到一起的行进行查询,每次选择都可以通过 AQUA 获益,从而整体速度会有更大提升。您从我用于这篇文章的简单查询中可以看到,AQUA 可以大大缩短查询时间,甚至可能实现一些新类型的实时查询,这些查询在过去根本无法实现。
注意事项
以下是关于 AQUA 的几个有趣事实:
集群版本 – 您的集群必须运行 Redshift 版本 1.0.24421 或更高版本才能使用 AQUA。要了解有关如何启用和禁用 AQUA 的更多信息,请参阅管理 AQUA 集群。
相关查询 – AQUA 旨在为使用 LIKE 和 SIMILAR_TO 谓词执行大型扫描、聚合和筛选的查询提供高达 10 倍的性能。我们希望未来增加对更多查询的支持。
安全性 – AQUA 缓存的所有数据都使用您的密钥进行加密。执行筛选或聚合操作后,AQUA 会压缩结果、加密结果,然后将结果返回到 Redshift。
区域 – AQUA 现已在美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、美国东部(俄亥俄)、欧洲(爱尔兰)和亚太地区(东京)区域推出,并将于 2021 年上半年在欧洲(法兰克福)、亚太地区(悉尼)和亚太地区(新加坡)推出。
定价 – 正如我之前提到的那样,使用 AQUA 无需支付额外费用。
立即试用 AQUA
如果您使用 ra3.4xl 或 ra3.16xl 节点为 Redshift 集群提供服务,可以启用 AQUA、重启集群,并在几分钟内运行一些测试查询。让 AQUA 带您一起飞翔吧,请把您的想法告诉我!
– Jeff;