亚马逊AWS官方博客
新增功能 – Step Functions 支持动态并行性
微服务可使应用程序更容易扩展,并加快其开发速度,但协调分布式应用程序的组件可能是一项艰巨的任务。 AWS Step Functions 是一种完全托管的服务,使用这种服务,您可以设计和运行包含多个步骤的工作流,让每个步骤以上一步骤的输出为输入,从而简化任务协调。例如,诺华生物医学研究所正在使用 Step Functions,让科学家能够在不依赖集群专家的前提下运行图像分析。
Step Functions 近来添加了一些非常有趣的功能,例如用于简化人工活动与第三方服务的集成的回调模式,以及将模块化、可重用的工作流组合在一起的嵌套工作流。如今,我们又在工作流中添加了对于动态并行性的支持!
动态并行性的运作方式
状态机使用 Amazon States Language 定义,Amazon States Language 是一种基于 JSON 的结构化语言。Parallel 状态可用于并行执行在状态机中定义的固定数量的分支。 现在,Step Functions 支持面向动态并行性的新 Map 状态类型。
要配置 Map 状态,您需要定义一个 Iterator,这是一个完整的子工作流。当 Step Functions 执行进入 Map 状态时,它会遍历状态输入中的 JSON 数组。对于每个项目,Map 状态都会执行一个子工作流,而且可能会并行执行。当所有子工作流执行完毕后,Map 状态将返回一个数组,其中包含 Iterator 处理的每一项的输出。
您可以通过添加 MaxConcurrency 字段来配置 Map 执行的并发子工作流数的上限。 默认值为 0,即在并行性方面没有限制,并且会尽可能地并发调用迭代。 如果 MaxConcurrency 值为 1,则效果是一次调用 Iterator 的一个元素,调用顺序依循元素在输入状态中的出现顺序,并且在上一次迭代执行完毕后才会启动迭代。
使用新 Map 状态的一种方法是在工作流中利用扇出或“分散-集中”消息传递模式:
- 扇出用于向多个目标传递消息的情况,在订单处理或批量数据处理等工作流中可能非常有用。例如,您可以从 Amazon SQS 检索消息数组,Map 会将每条消息发送到单独的 AWS Lambda 函数。
- 分散-集中可将一条消息广播到多个目标(分散),然后再聚合响应,以用于后续步骤(集中)。 这在文件处理和测试自动化中非常有用。例如,您可以并行转码 10 个 500MB 的媒体文件,然后再连接这些文件,以创建一个 5GB 的文件。
与 Parallel 和 Task 状态相似,Map 支持 Retry 和 Catch 字段,以处理服务和自定义异常。您还可以向 Iterator 内的状态应用 Retry 和 Catch,以处理异常。如果因未处理某个错误或者已转换为 Fail 状态而导致任何 Iterator 执行失败,则整个 Map 状态均会被视作失败,并且其所有迭代都会停止。如果 Map 状态本身未处理错误,则 Step Functions 会停止执行工作流,并显示错误。
使用 Map 状态
下面我们来构建一个订单处理工作流,并使用 Map 状态并行处理订单中的商品。此工作流中执行的所有任务都以 Lambda 函数的形式标识,但借助 Step Functions,您可以使用其他 AWS 服务集成,并在 EC2 实例、容器或本地基础设施上运行代码。
下面是我们的示例订单(采用 JSON 文档形式),其中订购了几本图书,以及一些在读书时品啜的咖啡。该订单包含一个 detail 部分,其中包含订单内的 items 列表。
{
"orderId": "12345678",
"orderDate": "20190820101213",
"detail": {
"customerId": "1234",
"deliveryAddress": "123, Seattle, WA",
"deliverySpeed": "1-day",
"paymentMethod": "aCreditCard",
"items": [
{
"productName": "Agile Software Development",
"category": "book",
"price": 60.0,
"quantity": 1
},
{
"productName": "Domain-Driven Design",
"category": "book",
"price": 32.0,
"quantity": 1
},
{
"productName": "The Mythical Man Month",
"category": "book",
"price": 18.0,
"quantity": 1
},
{
"productName": "The Art of Computer Programming",
"category": "book",
"price": 180.0,
"quantity": 1
},
{
"productName": "Ground Coffee, Dark Roast",
"category": "grocery",
"price": 8.0,
"quantity": 6
}
]
}
}为了处理这笔订单,我要使用一个状态机来定义如何执行不同的任务。Step Functions 控制台会为我构建的工作流创建可视化表示形式:
- 首先,我要验证并检查付款。
- 然后,我可能会并行处理订单中的商品,以检查库存情况,确定是否已经准备好交货,并启动交货流程。
- 最后,我要将订单汇总发送给客户。
- 如果付款检查失败,我会拦截工作流,以便采取向客户发送通知等措施。
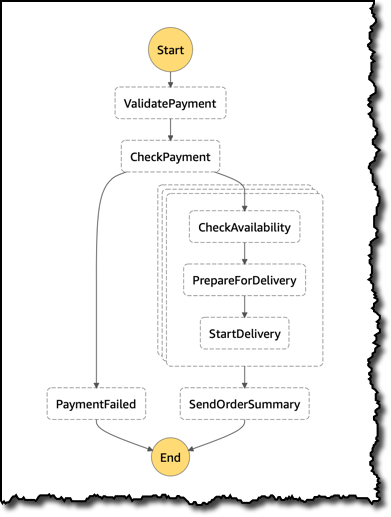
这是以 JSON 文档形式表示的相同状态机定义。ProcessAllItems 状态使用 Map 并行处理订单中的商品。在本例中,我使用 MaxConcurrency 将并发数量限制为 3。在 Iterator 内,我可以设置任意复杂度的子工作流。在本例中,我有 3 个步骤,分别用于处理商品的 CheckAvailability、PrepareForDelivery 和 StartDelivery。每个步骤都可 Retry 和 Catch 错误,以使子工作流的执行更可靠,例如在与外部服务集成的情况下。
{
"StartAt": "ValidatePayment",
"States": {
"ValidatePayment": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:validatePayment",
"Next": "CheckPayment"
},
"CheckPayment": {
"Type": "Choice",
"Choices": [
{
"Not": {
"Variable": "$.payment",
"StringEquals": "Ok"
},
"Next": "PaymentFailed"
}
],
"Default": "ProcessAllItems"
},
"PaymentFailed": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:paymentFailed",
"End": true
},
"ProcessAllItems": {
"Type": "Map",
"InputPath": "$.detail",
"ItemsPath": "$.items",
"MaxConcurrency": 3,
"Iterator": {
"StartAt": "CheckAvailability",
"States": {
"CheckAvailability": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:checkAvailability",
"Retry": [
{
"ErrorEquals": [
"TimeOut"
],
"IntervalSeconds": 1,
"BackoffRate": 2,
"MaxAttempts": 3
}
],
"Next": "PrepareForDelivery"
},
"PrepareForDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:prepareForDelivery",
"Next": "StartDelivery"
},
"StartDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:startDelivery",
"End": true
}
}
},
"ResultPath": "$.detail.processedItems",
"Next": "SendOrderSummary"
},
"SendOrderSummary": {
"Type": "Task",
"InputPath": "$.detail.processedItems",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:sendOrderSummary",
"ResultPath": "$.detail.summary",
"End": true
}
}
}此工作流使用的 Lambda 函数并不了解订单 JSON 文档的整体结构。它们只需知道自身要处理的输入状态部分即可。这是在多个工作流中轻松重用这些函数的最佳实践。状态机定义使用 JsonPath 语法通过 InputPath、ItemsPath、ResultPath 和 OutputPath 字段操控用于函数输入和输出的路径:
InputPath用于过滤处于输入状态的数据,例如仅将订单的detail传递给Iterator。ItemsPath是Map状态特有的,用于标示在输入中的何处可以找到要处理的数组字段,例如处理订单detail中的items。ResultPath让您可以将一项任务的输出添加到输入状态,而不是完全覆盖输入状态,例如将summary添加到订单的detail。- 我这次没有使用
OutputPath,但它对于过滤掉不必要的信息,仅将您关注的 JSON 部分传递给下一个状态可能是一种很有用。例如,仅将订单的detail作为输出发送。
您可以选择使用 Parameters 字段来自定义每次迭代使用的原始输入。例如,deliveryAddress 包含在订单的 detail 中,但不包含在每个 item 中。为了保证 Iterator 具有商品的 index,并可访问 deliveryAddress,我可以将下面这段代码添加到 Map 状态中:
"Parameters": {
"index.$": "$$.Map.Item.Index",
"item.$": "$$.Map.Item.Value",
"deliveryAddress.$": "$.deliveryAddress"
}现已推出
从今天开始,所有可以使用 Step Functions 的区域均可开始使用这项新功能。动态并行性或许是 Step Functions 用户呼声最高的一项功能。它可让用户无障碍地实施新使用案例,并有助于优化现有使用案例。欢迎与我们分享您打算用这项功能来做些什么!