亚马逊AWS官方博客
NoSQL Workbench for Amazon DynamoDB – 预览版现已推出
Amazon DynamoDB 的灵活性一直让我赞不绝口,它给我们的客户提供了一个完全托管的键值和文档数据库,可以轻松地从每月几个请求扩展到每秒数百万个请求。
DynamoDB 团队近期发布了许多出色的功能,从按需容量到对原生 ACID 事务的支持,不一而足。以下是对近期其他 DynamoDB 公告的回顾,例如全局表、时间点恢复和即时自适应容量。DynamoDB 现在默认加密所有静态客户数据。
但是,将思维模式从关系数据库转换到 NoSQL 并不容易。请观看去年 re:Invent 大会的两场精彩演讲,以帮助您了解 DynamoDB 的工作原理,以及如何将其用于您的使用案例:
- Amazon DynamoDB 功能揭秘:如何构建超大规模数据库,主讲人:Jaso Sorenson
- Amazon DynamoDB 深入探究:DynamoDB 高级设计模式,主讲人:Rick Houlihan
为了提供更大助力,我们今天推出了 NoSQL Workbench for Amazon DynamoDB,这是一款免费的客户端应用程序,适用于 Windows 和 macOS,可以帮助您设计和直观呈现数据模型、对数据运行查询以及为您的应用程序生成代码!
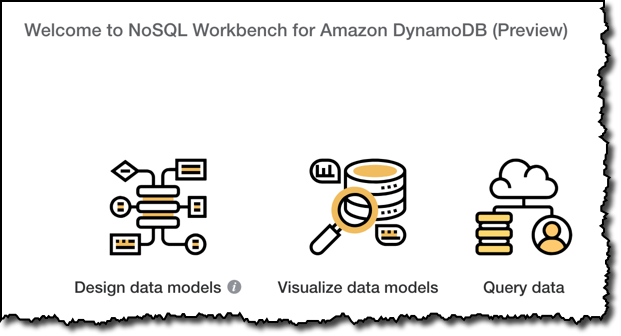
NoSQL Workbench 提供三大主要功能,如下所示:
- 数据建模器 – 构建新数据模型、添加表和索引,或者导入、修改和导出现有数据模型。
- 可视化程序 – 基于应用程序访问模式直观呈现数据模型,可以手动添加样本数据,也可以通过 SQL 查询导入。
- 运算生成器 – 定义和执行数据平面运算,或者为它们生成可以直接投入使用的样本代码。
为了解这一新工具如何简化 DynamoDB 使用方法,我们来构建一个应用程序检索客户及其订单的相关信息。
使用 NoSQL Workbench
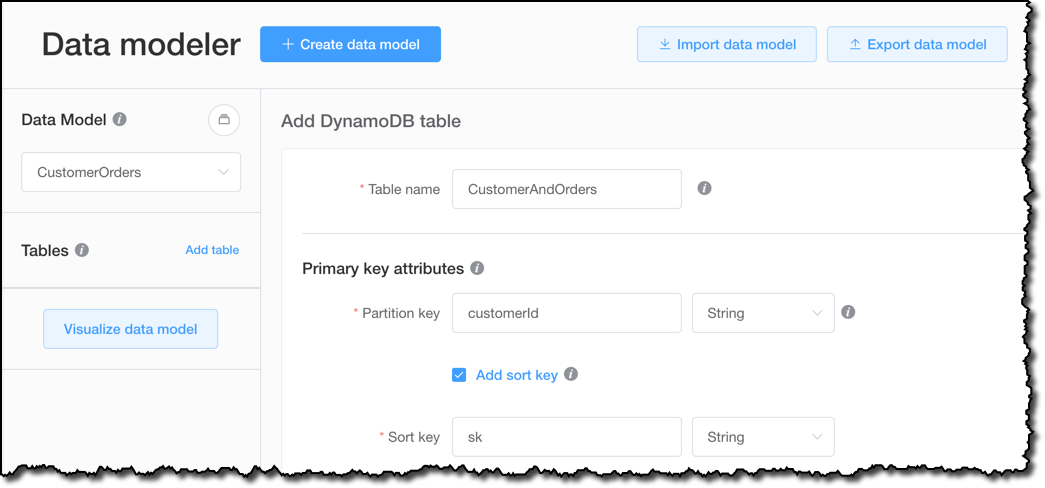
在数据建模器中,我首先创建一个 CustomerOrders 数据模型,随后添加一个 CustomerAndOrders 表,用来保存我的客户数据及其订单信息。您可以使用此工具创建一个简单的数据模型,其中客户和订单位于两个不同的表中,每个表都有自己的主键。这没有什么不妥。在这里,我想展示这款工具如何帮助您使用更高级的设计模式。通过将客户和订单数据放在一个表中,我可以构建查询,通过与 DynamoDB 的一次交互返回我需要的所有数据,从而提升应用程序的性能。
我使用 customerId 作为分区键。选择这样的结构可以跨多个分区实现数据均匀分布。我这个数据模型中的排序键将成为一个重载属性,从某种意义上来说,它可以根据具体项保存不同的数据:
- 一个固定字符串(例如
customer),用于保存包含客户数据的项。 - 订单日期(例如
20190823),使用 ISO 8601 字符串编写,用于保存包含订单的项。
通过使用这两个可能的值重载排序键,我可以通过运行一次查询来返回客户数据和最新订单。 因此,我使用一个通用的排序键名称。在本例中,我使用的是 sk。
DynamoDB 还具有灵活的架构,除了分区键和可选的排序键之外,其他所有属性都可以随表中的每个项发生变化。但是使用这款工具,我可以选择在数据模型中描述将用于表的所有可能属性。通过这种方式,我可以稍后检查我的应用程序所需的所有访问模式是否适用于此数据模型。
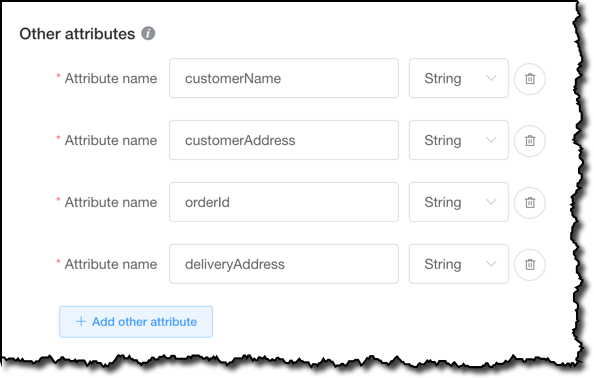
对于此表,我添加以下属性:
customerName和customerAddress,用于包含客户数据的表中的项。orderId和deliveryAddress,用于包含订单数据的表中的项。
我没有添加 orderDate 属性,因为对于此数据模型来说,该值将存储在 sk 排序键中。 在真实的生产使用案例中,您可能要使用更多属性来描述客户和订单,在这里我只是以最简单的方式说明这款工具,向您展示可以实现的操作,以免细节过多造成干扰。
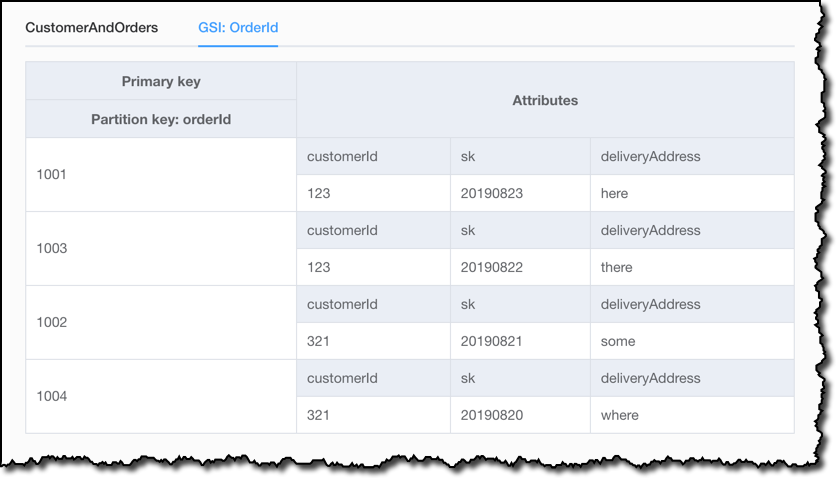
我的应用程序的另一种访问模式是能够通过 ID 获取特定订单。为此,我向表中添加了一个全局二级索引,以 orderId 作为分区键,没有排序键。

我将一个表定义添加到该数据模型,然后转到可视化程序。在可视化程序中,我通过添加一些样本数据来更新表。我手动添加数据,但也可以从 MySQL 数据库的表中导入几行数据,例如,用来简化从关系数据库到 NoSQL 的迁移。
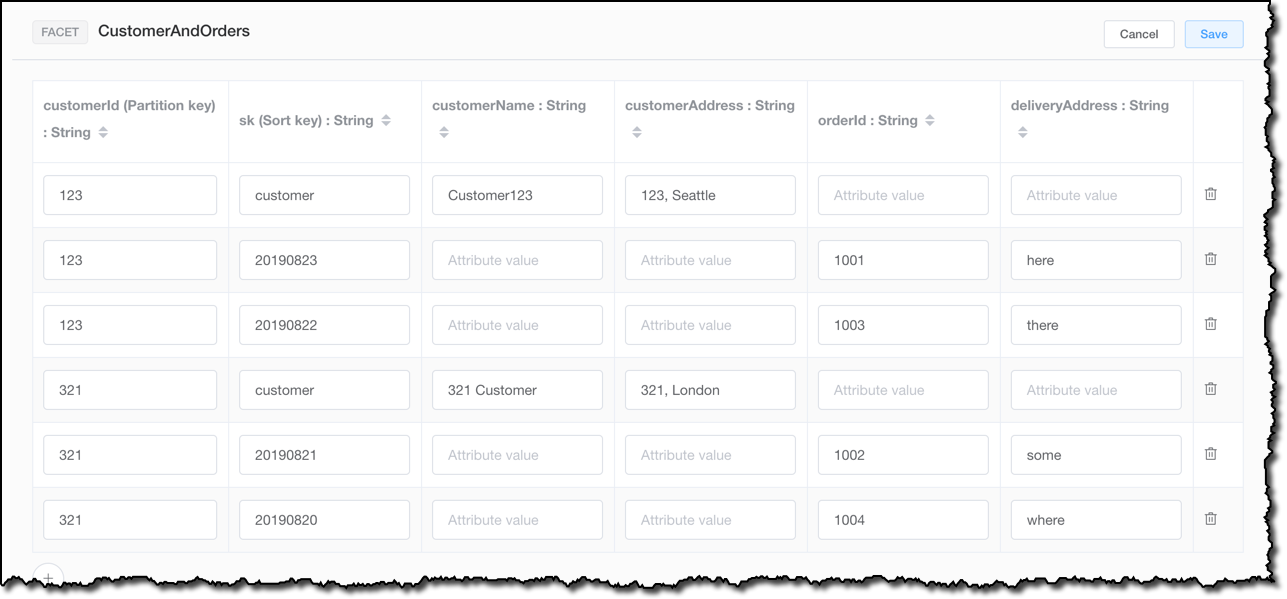
现在,我使用样本数据直观呈现我的数据模型,以便更好地理解此表的使用效果。例如,如果我选择 customerId,并查询订单日期晚于特定日期的所有订单,那么最后也会获得客户数据,因为存储在 sk 排序键中的字符串 customer 始终晚于用 ISO 8601 语法编写的任何日期。
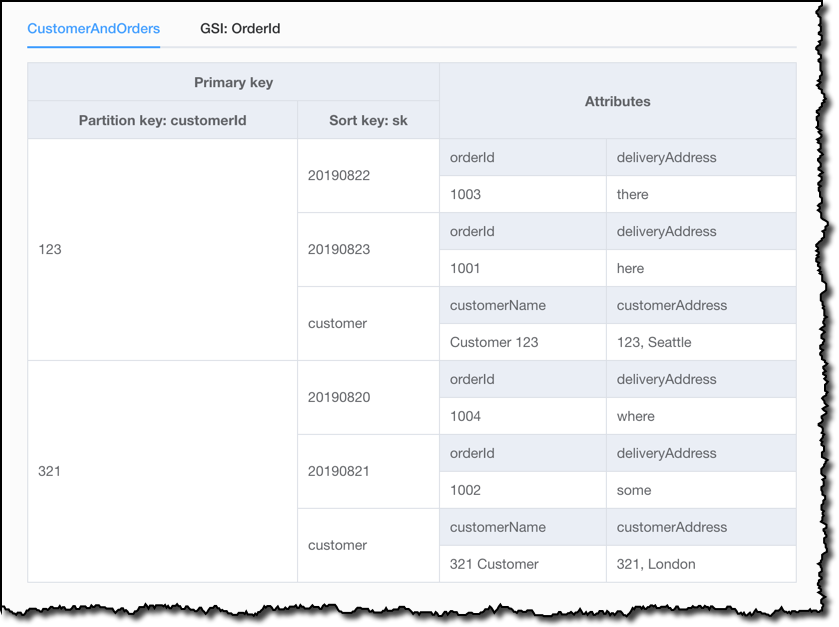
在可视化程序中,我还可以看到全局二级索引在 orderId 上的工作方式。有趣的是,此索引并未包含没有 orderId 的项,因此我只获得了样本数据中所包含的 6 个项中的 4 个。之所以发生这种情况,是因为仅在项中存在索引排序键值时,DynamoDB 才会写入相应的索引条目。如果排序键未出现在每个表项中,则将该索引称为稀疏索引。 稀疏索引对于针对表的子部分的查询很有用。
现在,我将数据模型提交到 DynamoDB。此步骤为所选数据模型创建服务器端资源(如表和全局二级索引),并加载样本数据。为此,我需要 AWS 账户的 AWS 凭证。我在使用此工具的环境中安装并配置了 AWS 命令行界面 (CLI),因此我可以直接选择一个已命名的配置文件。
我转到运算生成器,从中可以查看选定 AWS 区域中的所有表。我选择新创建的 CustomerAndOrders 表来浏览数据并为我在应用程序中所需的运算生成代码。

在本例中,我想运行一项查询,针对特定客户,选择订单日期晚于我提供的日期的所有订单。如前所述,重载的排序键也会将客户数据作为最后一项返回。运算生成器可以帮助您使用 DynamoDB 运算的完整语法,例如添加条件和子表达式。在本例中,我将条件添加到仅返回 deliveryAddress 包含 Seattle 的订单。

我可以选择在 DynamoDB 表上执行运算,但这次我想在我的应用程序中使用该查询。为了生成代码,我可以选择 Python、JavaScript (Node.js) 或 Java。
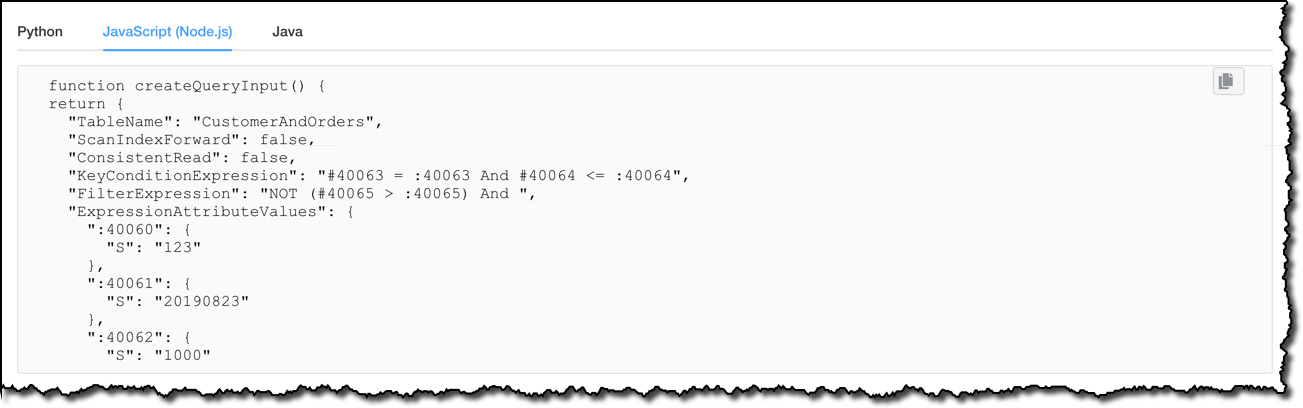
您可以使用运算生成器,使用 DynamoDB 提供的所有高级功能(包括 ACID 事务),为您计划用于应用程序的所有访问模式生成代码。
现已推出
您可以在此处了解如何为 Windows 和 macOS 设置 NoSQL Workbench for Amazon DynamoDB(预览版)。
我们诚挚欢迎您在 DynamoDB 论坛中积极提出意见建议。与我们分享您用这款新工具构建的项目,告诉我们怎样才能为您提供更多帮助!