亚马逊AWS官方博客
S3 Tables 实战:两种方案,把 MySQL 数据实时”搬”进 S3 Tables
摘要:这篇博客介绍了将 MySQL 变更数据实时同步到 Amazon S3 Tables(一种专为 Apache Iceberg 优化的全托管存储方案)的两种方法:一是基于 MSK Connect + Iceberg Kafka Connect 的全托管方案,二是基于 Flink CDC + Flink SQL 的流处理方案。文章重点展示了 S3 Tables 如何通过内置的自动表维护功能(小文件合并、快照清理等)解决传统 Iceberg 数据湖的运维难题,让用户专注于数据写入而无需操心底层维护。
目录
1. 背景介绍
随着分析业务对数据时效性要求越来越高,企业希望业务数据在产生后能立即进入数据湖供后续分析使用。Apache Iceberg 凭借其出色的数据管理能力、ACID 事务支持、Schema Evolution 和 Time Travel 等特性,已成为构建现代数据湖的首选技术方案,越来越多的企业正在将 Iceberg 作为其数据湖的核心表格式。笔者在之前的博文《使用 Amazon MSK Connect 与 Iceberg Kafka Connect 轻松构建数据实时入湖》 中介绍了使用 MSK Connect 将数据实时同步到 Iceberg 中。但是,对于 Iceberg 并不是很熟悉的用户在运维 Iceberg 数据湖也遇到了不少挑战。
1.1 Iceberg 的运维挑战
然而,在实际生产环境中,Iceberg 表的运维管理给用户带来了不小的挑战。特别是在实时数据入湖场景下,高频写入会产生大量小文件,如果不及时处理,将严重影响查询性能。用户通常需要自行实现以下维护操作:
- 小文件合并(Compaction):需要定期运行 Spark 作业执行 rewrite_data_files 操作,将小文件合并成大文件
- 快照过期清理(Expire Snapshots):需要清理历史快照,释放存储空间
- 孤立文件删除(Remove Orphan Files):需要定期清理不再被任何快照引用的数据文件
- 元数据文件清理(Rewrite Manifests):需要优化和压缩 manifest 文件
这些维护任务不仅增加了运维复杂度,还需要额外的计算资源和调度系统支持。
1.2 S3 Tables 的解决方案
2024 年底,AWS 推出了 Amazon S3 Tables —— 一种专为 Apache Iceberg 表格式优化的全新存储方案。S3 Tables 最大的亮点就是内置了托管的自动表维护功能,可以自动执行小文件合并、快照清理和孤立文件删除等操作,彻底解放用户在表维护方面的运维负担。
S3 Tables 提供了标准的 Iceberg REST Catalog 接口,这意味着任何支持 REST Catalog 的计算引擎都可以直接将数据写入 S3 Tables。本文将介绍两种将 MySQL 变更数据实时同步到 S3 Tables 的方案:
- 方案一:Amazon MSK Connect + Iceberg Kafka Connect —— 基于 Kafka 生态的全托管方案,适合已有 MSK 集群的场景
- 方案二:Flink CDC + Iceberg Dynamic Sink —— 基于 Flink 和 Iceberg 1.10+ Dynamic Sink 的流处理方案,支持多表动态路由和自动 Schema Evolution
两种方法的核心都是利用 S3 Tables 提供的 REST Catalog 接口写入 Iceberg 表。
2. Amazon S3 Tables 简介
Amazon S3 Tables 是专为 Apache Iceberg 表优化的全新存储类型,它将 S3 的高扩展性、持久性与 Iceberg 的表格管理能力完美结合。
2.1 核心优势
卓越的查询性能:S3 Tables 针对 Apache Iceberg 表格式进行了底层存储优化,查询性能相比传统 S3 存储可提升高达 3 倍。
高并发写入能力:S3 Tables 支持每秒最多 10 万次事务写入,适合流式数据处理场景。
托管式自动表维护:S3 Tables 将 Compaction、Snapshot 清理等维护工作完全托管,用户只需专注于数据写入。
无缝集成 AWS 分析生态:支持 Amazon EMR、Amazon Athena、Amazon Redshift、AWS Glue 等服务直接查询。
2.2 自动表维护功能
自动 Compaction(小文件合并):自动检测并合并小文件,默认目标文件大小为 512MB,约每 3 分钟执行一次。
自动 Snapshot 管理:自动清理过期的快照,保留必要的历史版本用于时间旅行查询。
孤立文件清理:自动识别并删除不再被任何快照引用的数据文件。
⚠️ 注意:
使用 S3 Tables 后,不能再使用 Iceberg 原生的表维护方法(如 rewrite_data_files),需要完全依赖托管的维护功能。
2.3 S3 Tables REST Catalog —— 连接数据写入的核心
S3 Tables 采用 REST Catalog 作为元数据管理接口,这是 Apache Iceberg 社区推荐的标准化 Catalog 实现方式,也是本文两种数据同步方法的核心连接点。
标准化的开放接口:基于 Iceberg REST Catalog Spec 实现,提供标准化的 HTTP API,任何支持 REST Catalog 的客户端(Kafka Connect、Flink、Spark 等)都可以直接连接。
细粒度的访问控制:通过 AWS SigV4 签名认证,与 IAM 权限体系深度集成。
简化的客户端配置:客户端只需配置 catalog URI 和认证信息,无需关心底层存储路径。
更好的多租户支持:不同的 Table Bucket 和 Namespace 可以实现逻辑隔离。
S3 Tables REST Catalog 的端点格式为:https://s3tables.<region>.amazonaws.com/iceberg
连接时需要提供以下关键信息:
- REST Catalog URI:区域特定的 S3 Tables REST 端点
- Warehouse ARN:S3 Table Bucket 的 ARN,格式为
arn:aws:s3tables:region:accountID:bucket/bucketname - SigV4 签名认证:signing-name 为
s3tablessigv4-enabled=true
3. 环境准备
3.1 创建 S3 Table Bucket
aws s3tables create-table-bucket \
--name iceberg-data-${ACCOUNT_ID} \
--region us-east-1
3.2 准备 MySQL 数据源
确保 MySQL 启用了 binlog:
-- 检查 binlog 状态
SHOW VARIABLES LIKE 'log_bin';
-- 检查 binlog 格式
SHOW VARIABLES LIKE 'binlog_format';
-- 创建 CDC 用户
CREATE USER 'flink_cdc'@'%' IDENTIFIED BY 'password';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flink_cdc'@'%';
FLUSH PRIVILEGES;
3.3 创建 S3tables Namespace
4. 方案一:Amazon MSK Connect + Iceberg Kafka Connect
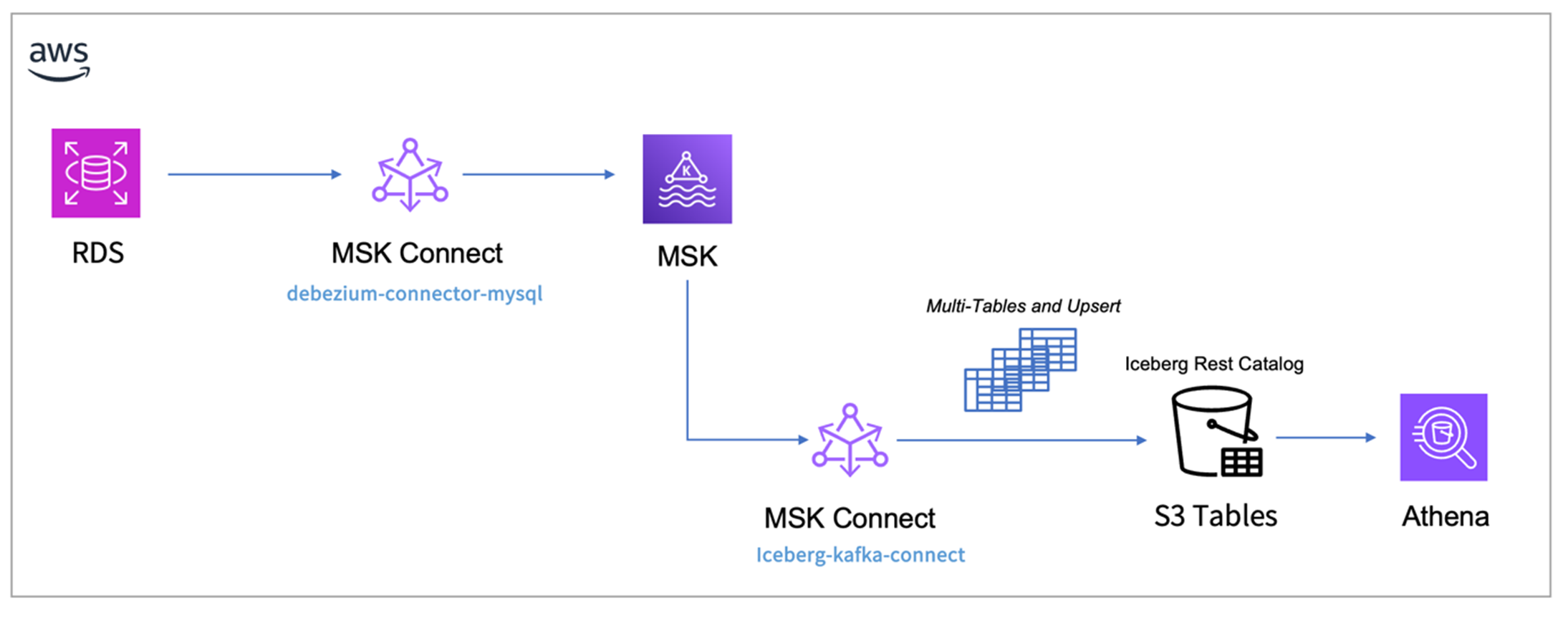
4.1 方案架构
本方案使用以下组件构建端到端的实时数据入湖流程:
- Debezium MySQL Connector:捕获 MySQL 的 binlog 变更日志,写入 Amazon MSK
- Amazon MSK:托管的 Kafka 集群,作为数据缓冲层
- Iceberg Kafka Connect:消费 Kafka 数据,写入 Iceberg 表
- Amazon S3 Tables:存储 Iceberg 表数据,提供自动维护
[图1] |
4.1.1 Iceberg Kafka Connector 特性
- Exactly-once 语义:保证数据不丢失、不重复
- 多表同步:支持将多个 Topic 写入多张表
- Upsert 模式:支持 Update/Delete 操作,实现数据变更同步
- Schema Evolution:自动同步源端的字段变更
- 自动建表:无需预先创建目标表
4.1.2 为什么选择 MSK Connect
Amazon MSK Connect 作为全托管的 Kafka Connect 服务,具有以下优势:
零基础设施管理:无需预置或管理任何服务器,只需上传 Connector 插件包、配置连接参数,服务即可自动运行。
弹性伸缩能力:支持 Auto Scaling,可以根据 CPU 使用率自动调整 Worker 数量。
内置的高可用性:自动处理 Worker 故障检测和恢复,结合 offset 管理实现断点续传。
与 MSK 无缝集成:支持 IAM 认证、VPC 网络隔离等企业级安全特性。
显著的运维成本节省:相比自建 Kafka Connect 集群,可以节省约 70% 的运维工作量。
4.2 创建 MSK Connect Custom Plugin
需要创建两个 Custom Plugin:
- Debezium MySQL Connector:负责将 MySQL binlog 同步到 MSK
- Iceberg Kafka Connect:负责将 MSK 数据同步到 S3 Tables
将下载的 Plugin JAR 包上传到 S3,然后在 MSK 控制台创建 Custom Plugin。
创建步骤可以参考早前的博客《使用 Amazon MSK Connect 与 Iceberg Kafka Connect 轻松构建数据实时入湖》 中第3章节,这里我们就不做赘述。
另外,S3Tables 也已经支持 Iceberg V3,如需支持 Iceberg Table Spec V3,需要重新打包 Iceberg Kafka Connect,将 Iceberg 版本升级到 1.7.0 或更高版本。我们已经有一个编译好的版本,可直接下载。但是由于 Amazon Athena 截止当前(2026-03)还不支持 Iceberg V3,需要查询 S3Tables 中 Iceberg v3 版本的表,可以使用 Amazon EMR。
4.3 配置 Debezium MySQL Connector
在 MSK Connect 控制台创建 Connector,点击左侧菜单中的 Connectors,点击 Create Connector,选择 4.2 章节已经创建好的 Debezium MySQL Plugin,在创建页面选择 MSK 集群,处于安全考虑,选择 IAM 认证。Kafka Connector 版本选择 3.7.x。
使用以下配置:
4.4 配置 S3Tables Sink Connector
这是方法一的核心部分 —— 配置 Iceberg Kafka Connect 将数据写入 S3 Tables。与传统的 Glue Catalog 不同,连接 S3 Tables 需要使用 REST Catalog 方式,并配置 SigV4 签名认证。以下是完整的 Connector 配置:
4.4.1 关键配置说明
REST Catalog 配置(S3 Tables 特有):
| 参数 | 值说明 |
| iceberg.catalog.type | 使用 REST Catalog 类型: rest |
| iceberg.catalog.uri | S3 Tables REST 端点 URL: https://s3tables.us-east-1.amazonaws.com/iceberg |
| iceberg.catalog.warehouse | S3 Table Bucket ARN: arn:aws:s3tables:region:accountid:bucket/tablebucket-name |
| iceberg.catalog.rest.sigv4-enabled | 启用 AWS SigV4 签名认证: true |
| iceberg.catalog.rest.signing-name | 签名服务名: s3tables |
CDC 配置:
| 参数 | 值说明 |
| iceberg.tables.cdc-field | CDC 操作类型字段,Debezium 格式为 _cdc.op |
| iceberg.table.<db>.<table>.id-columns | 主键字段,用于 Update/Delete 操作定位记录 |
| iceberg.tables.route-field | 多表路由字段,Debezium 格式为 _cdc.source |
| iceberg.tables.dynamic-enabled | 启用动态表名(从消息中提取表名)true |
5. 方案二:Flink CDC + Iceberg Dynamic Sink
5.1 Flink CDC 写入 S3 Tables
由于 S3 Tables 提供了标准的 Iceberg REST Catalog 接口,任何支持 REST Catalog 的计算引擎都可以直接写入。Flink CDC 通过 Debezium 捕获 MySQL binlog 变更事件,再利用 Iceberg REST Catalog 将数据写入 S3 Tables,无需引入 Kafka 中间层,架构更加简洁。
然而,在传统的 Flink + Iceberg 方案中,用户面临几个痛点:
- 需要为每张表预定义 Flink SQL DDL:Source 表和 Sink 表都需要手动定义字段结构,表数量多时维护成本很高
- 不支持运行时 Schema 变更:源表执行
ALTER TABLE ADD COLUMN - 一个 Job 只能同步一张表:如果要同步多张 MySQL 表,需要启动多个 Flink Job
5.2 Iceberg Dynamic Sink:解决传统方案的痛点
从 Iceberg 1.10.0 版本开始,社区引入了全新的 Flink Dynamic Iceberg Sink(简称 Dynamic Sink),专门为上述场景设计。根据 Iceberg 官方文档,Dynamic Sink 提供了以下能力:
- Writing to any number of tables:一个 Sink 可以动态路由记录到多个 Iceberg 表,无需预先定义每张表的 DDL
- Dynamic table creation and updates:表可以根据用户定义的路由逻辑自动创建和更新
- Dynamic schema and partition evolution:表的 Schema 和分区规范可以在流式执行过程中动态更新
所有这些配置都通过 DynamicRecord
用户只需实现一个 DynamicRecordGenerator 接口,负责将输入记录转换为 DynamicRecord(包含目标表、Schema、数据),其余的表创建、Schema Evolution、数据路由全部由 Dynamic Sink 内部自动处理。
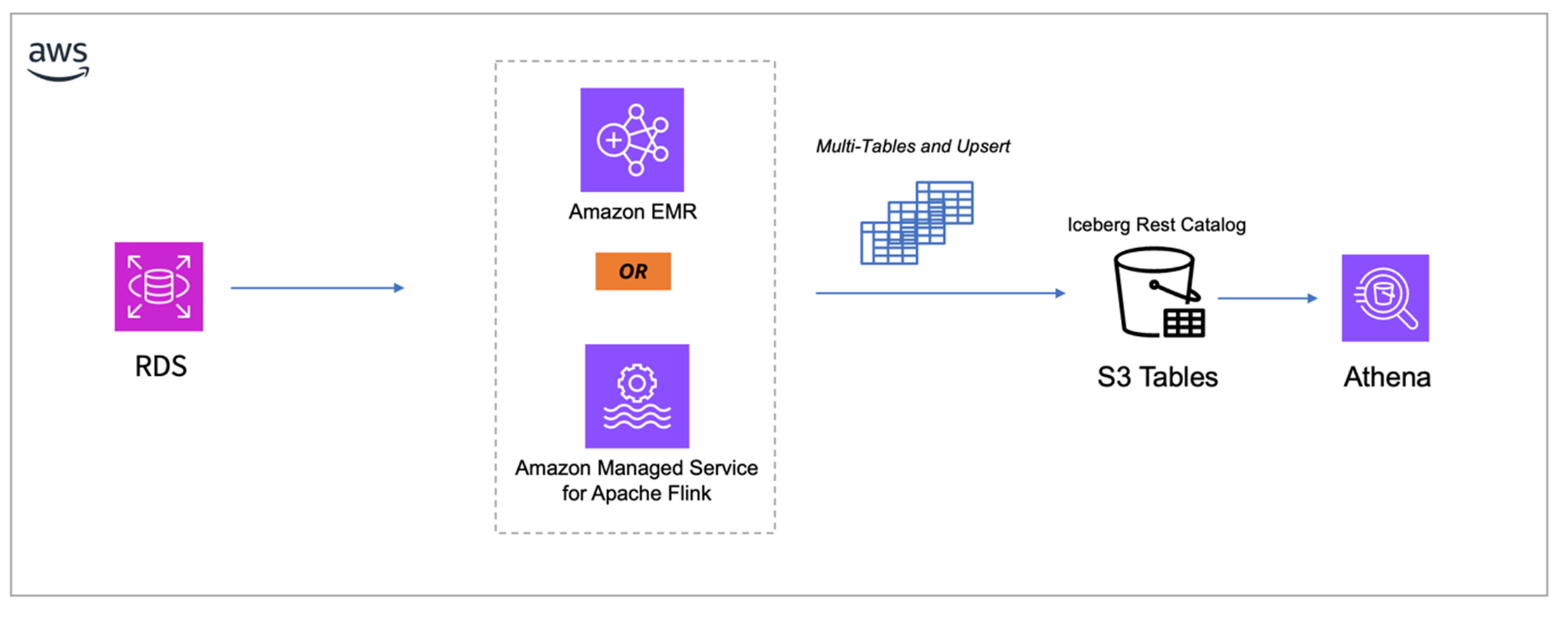
5.3 结合 S3 Tables REST Catalog 实现方案
基于 Iceberg Dynamic Sink 的能力,我们结合 S3 Tables 的 REST Catalog 实现了一套完整的 MySQL CDC 到 S3 Tables 的实时同步方案。我们将 Flink 作业托管在 Amazon EMR 或者 Amazon Managed Service for Apache Flink 中。
[图2] |
完整的项目代码和使用说明请参考:flink-cdc-mysql-iceberg-dynamic
5.3.1 核心设计如下:
数据流:MySQL CDC Source → DataStream(Flink) → CDCDynamicRecordGenerator(Flink) → DynamicIcebergSink(Flink) → S3 Tables
CDCDynamicRecordGenerator 是自定义实现的 DynamicRecordGenerator 接口,负责:
- 解析 Debezium CDC JSON,提取数据和 Schema 信息
- 从
source.table - 从 Debezium schema 元数据构建 Iceberg Schema
- 处理 INSERT/UPDATE/DELETE 操作(通过 Equality Delete 实现 Upsert)
S3 Tables 连接:程序自动配置 REST Catalog 和 SigV4 签名认证,只需指定 Table Bucket ARN 和 Region。Namespace 和表由 Dynamic Sink 根据 CDC 事件自动创建。在 Flink 代码中按如下设置 catalog 参数:
关键特性:
- 多表同步:通过
--mysql.tablesorders|customers.*),一个 Flink Job 完成全库同步 - 自动 Schema Evolution:MySQL 执行
ALTER TABLE ADD COLUMN - 自动建表:目标 Iceberg 表不存在时自动创建,无需手动建表
- 完整 CDC 支持:支持 INSERT、UPDATE、DELETE,通过 Iceberg format-version=2 的 Equality Delete 机制实现
5.4 部署配置
我们已经将该项目打包为可直接运行的 JAR 文件,读者可以从 这里 下载预编译的 flink-cdc-mysql-iceberg-dynamic-1.1.0.jar
运行环境要求:
- Apache Flink 1.20.0
- Java 11+
- MySQL 5.7+(需启用 binlog)
5.4.1 写入 S3 Tables
flink run \
-c com.amazonaws.java.flink.MySQLCDCToIcebergDynamic \
flink-cdc-mysql-iceberg-dynamic-1.1.0.jar \
--sink.target s3tables \
--mysql.hostname <mysql-host> \
--mysql.port 3306 \
--mysql.username <username> \
--mysql.password <password> \
--mysql.database <database-name> \
--mysql.tables "orders|customers" \
--s3tables.warehouse arn:aws:s3tables:<region>:<account-id>:bucket/<table-bucket-name> \
--aws.region <region> \
--iceberg.namespace <namespace> \
--sink.upsert true
5.4.2 参数说明
MySQL CDC Source 参数:
| 参数 | 值说明 |
| mysql.hostname | MySQL 地址(默认 localhost) |
| mysql.hostname | MySQL 端口(默认 3306) |
| mysql.username / mysql.password | 数据库认证信息 |
| mysql.database | 数据库名 |
| mysql.tables | 表名,支持正则匹配多表(如 orders|customers 同步两张表,.* 同步全库) |
| mysql.server.timezone | 时区(默认 UTC) |
| 参数 | 值说明 |
| s3tables.warehouse | S3 Tables Table Bucket ARN(必填),格式为 arn:aws:s3tables:<region>:<account-id>:bucket/<bucket-name> |
| aws.region | AWS Region(默认 us-east-1) |
| iceberg.namespace | Namespace(默认 default),Namespace 和表由 Dynamic Sink 自动创建 |
| 参数 | 值说明 |
| sink.target | s3tables, iceberg |
| sink.upsert | 默认 false,CDC 场景建议设为 true |
| sink.parallelism | 写入并行度(默认 2) |
⚠️ 注意:
S3 Tables 需要提前创建 Table Bucket。运行环境(EMR / Amazon Managed Service for Apache Flink)需要有访问 S3 Tables 的 IAM 权限。
6. 验证数据同步
无论使用方法一还是方法二,数据写入 S3 Tables 后,都可以通过以下方式验证。
6.1 查询同步数据
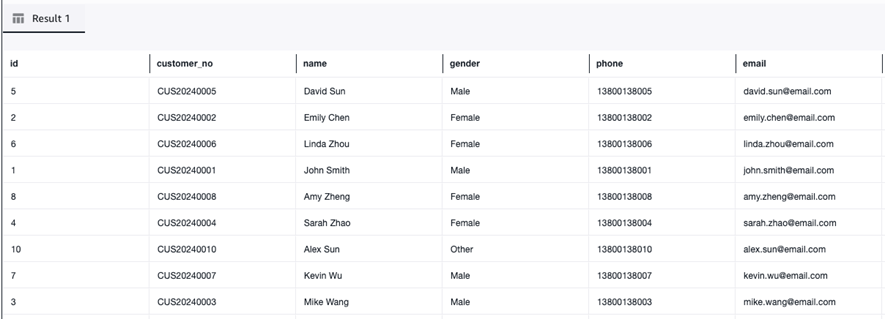
Connector 或 Flink 作业启动后,可通过 Athena 查询同步到 S3 Tables 的数据。
-- 通过 Athena 查询 S3 Tables 数据
SELECT * FROM "salsedb"."customer" LIMIT 10;
[图3] |
6.2 验证 Update 同步
两种方法都支持 CDC 的 Update 和 Delete 操作同步。方法一通过 Iceberg Kafka Connect 的 Upsert 模式实现,方法二通过 Dynamic Sink 的 Equality Delete 机制实现。
-- MySQL 中更新一条记录
update salesdb.customer set customer_level = 4 where id = 1;
-- 在 Athena 中验证更新已同步
SELECT id, customer_level FROM salesdb.customer WHERE id = 1;
-- 使用时间旅行查询历史版本,确认字段被更新
SELECT a.ID, a.customer_level, b.ID, b.customer_level FROM
(SELECT * FROM "salesdb"."customer" FOR TIMESTAMP AS OF TIMESTAMP '2026-03-11 2:55:00 UTC' WHERE id = 1) a JOIN
(SELECT * FROM "salesdb"."customer" FOR TIMESTAMP AS OF TIMESTAMP '2026-03-11 3:00:00 UTC' WHERE id = 1) b
ON a.ID = b.ID
如下图,第一列是修改之前的值,第2列是初始化写入的值,第4列是更新之后的值。

[图4] |
6.3 验证 Schema Evolution
两种方案都可以验证自动 Schema Evolution 能力:
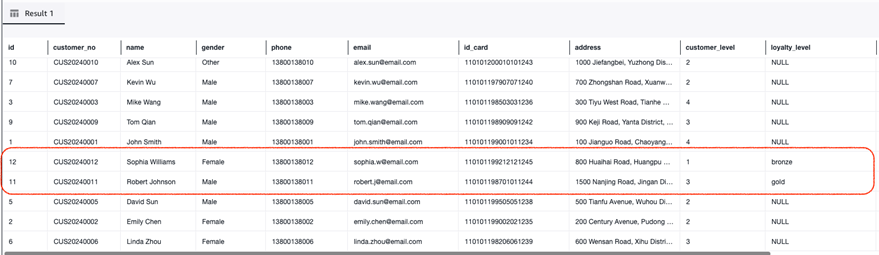
-- 在 MySQL 中添加新列
ALTER TABLE salesdb.customer ADD COLUMN loyalty_level VARCHAR(20) DEFAULT 'bronze';
-- 插入一条包含新列的数据
INSERT INTO salesdb.customer (..., loyalty_level) VALUES (..., 'gold');
-- 在 Athena 中查询,新列已自动出现,旧数据为 NULL
SELECT id, loyalty_level FROM salesdb.customer LIMIT 100;
无需重启,Iceberg Sink Connector 与 Flink Dynamic Sink 都可以自动检测到 schema 变化并更新 Iceberg 表结构。如下,从 Athena 查询的结果可以看到新的字段已经添加,并且新导入的记录也包含了这个新字段的值。
[图5] |
7. S3 Tables 自动维护管理
数据写入 S3 Tables 后,会自动触发表维护功能。以下命令可用于管理和监控维护任务。
7.1 查看表维护状态
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="<table bucket arn>" \
--namespace="<s3tables namespace>" \
--name="<tablename>"
7.2 配置 Compaction 参数
# 配置 Compaction 目标文件大小为 512MB
aws s3tables put-table-maintenance-configuration \
--table-bucket-arn <table bucket arn> \
--type icebergCompaction \
--namespace <s3tables namespace> \
--name <tablename> \
--value='{"status": "enabled","settings": {"icebergCompaction": {"targetFileSizeMB": 512}}}'
# 查看维护配置
aws s3tables get-table-maintenance-configuration \
--table-bucket-arn <table bucket arn> \
--namespace <s3tables namespace> \
--name <tablename>
8. 两种方案对比与选型建议
两种方法都依赖 S3 Tables REST Catalog 实现数据写入,但在架构设计和适用场景上有明显差异:
8.1 架构差异
方案一(Amazon MSK Connect) 是一个”解耦”架构:MySQL → Debezium → MSK(Kafka) → Iceberg Kafka Connect → S3 Tables。数据经过 Kafka 缓冲,生产者和消费者完全解耦,支持多消费者并行消费。
方法二(Flink CDC + Dynamic Sink) 是一个”直连”架构:MySQL → Flink CDC → Dynamic Sink → S3 Tables。数据直接从 MySQL 流入 S3 Tables,无需中间件,链路更短、延迟更低。
8.2 核心能力对比
| 方案一 Amazon MSK Connect + Iceberg Kafka Connect | 方案二 Flink CDC + Iceberg Dynamic Sink | |
| 多表同步 | 通过 Debezium transform + dynamic routing 实现,需要在 Connector 配置中启用 iceberg.tables.dynamic-enabled=true |
DynamicRecordGenerator 从 CDC 事件中提取 source.table 实现,支持正则匹配和运行时动态发现新表 |
| Schema Evolution | 依赖 Iceberg Kafka Connect 的 iceberg.tables.evolve-schema-enabled=true 配置 |
使用 Iceberg Dynamic Sink 原生的 Schema Evolution 能力,源表 ALTER TABLE ADD COLUMN 后无需重启即可自动同步新列 |
| CDC 操作支持 | 通过 Iceberg Kafka Connect 的 Upsert 模式实现 | 通过 Iceberg format-version=2 的 Equality Delete 机制实现 |
| Kafka 依赖 | 需要 MSK 集群作为中间层(带来缓冲、解耦优势,但增加成本和复杂度) | 无需 Kafka,架构更轻量 |
| 托管程度 | Amazon MSK Connect 为全托管服务,零基础设施管理,支持 Auto Scaling | 可部署到 Amazon Managed Service for Apache Flink 或 Amazon EMR 实现托管运行 |
8.3 选型建议
选择方案一(Amazon MSK Connect) 当:
- 已有 MSK/Kafka 集群,希望复用现有基础设施
- 需要多个下游消费者从同一份 CDC 数据流中读取
- 追求全托管、零代码的运维体验
- 数据来源多样(不仅是 MySQL,还有 PostgreSQL、MongoDB 等),需要统一汇聚到 Kafka 后入湖
选择方法二(Flink CDC + Dynamic Sink) 当:
- 希望架构尽量简洁,不引入额外中间件
- 已有 Flink 生态,或计划使用 Amazon Managed Service for Apache Flink
- 需要在数据入湖前做复杂的流式计算或数据转换,或者下游有实时数仓的业务场景。
9. 总结
本文介绍了两种将 MySQL 变更数据实时同步到 Amazon S3 Tables 的方法。两种方法的核心都是利用 S3 Tables 提供的 REST Catalog 接口,通过标准的 Iceberg REST 协议和 AWS SigV4 签名认证实现数据写入。
方案一(MSK Connect) 适合已有 Kafka 生态、需要多数据源汇聚的场景,通过全托管的 MSK Connect 服务实现零运维。
方案二(Flink CDC + Dynamic Sink) 基于 Iceberg 1.10+ 引入的 Dynamic Sink 新能力,一个 Flink Job 即可实现多表同步、自动 Schema Evolution 和自动建表,架构简洁且功能强大。
相比传统的 Glue Catalog + S3 方案,S3 Tables 提供了以下核心优势:
- 零运维的表维护:自动 Compaction、Snapshot 管理、孤立文件清理,无需配置额外的 Spark 作业
- 更好的查询性能:针对 Iceberg 优化的存储层,查询性能提升可达 3 倍
- 高并发写入支持:每秒最多 10 万次事务,满足实时入湖场景需求
- 标准化的 REST Catalog 接口:任何支持 Iceberg REST Catalog 的引擎都可以无缝对接
- 无缝集成 AWS 分析服务:支持 Athena、EMR、Redshift 等服务直接查询
无论选择 MSK Connect 还是 Flink CDC,企业都可以快速构建低延迟、高可靠的实时数据湖,让业务数据在产生后秒级入湖,为下游分析业务提供最新鲜的数据支持。
参考资源:
- Iceberg Flink Dynamic Sink 文档
- flink-cdc-mysql-iceberg-dynamic 项目
- Flink CDC Connectors
- Amazon S3 Tables 文档
- S3 Tables REST Catalog 集成
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon Connect — AI 客户体验解决方案
- Amazon MSK — 完全托管式 Apache Kafka 服务
- Amazon IAM — 身份管理和访问权限
- Amazon Athena — 使用 SQL 在 S3 中查询数据
相关文章:
- 告别堡垒机:使用 AWS EICE (EC2 Instance Connect Endpoint) 与 Chaterm 实现私有子网的安全智能运维
- 给 Openclaw瘦身-利用Nova MME 和 S3 Vector实现Skill按需召回
- AWS 一周综述:Amazon S3 推出 20 周年、Amazon Route 53 Global Resolver 正式推出等(2026 年 3 月 16 日)
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
