亚马逊AWS官方博客
使用Amazon SageMaker原生TorchServe集成在生产中支持PyTorch模型
原文链接:
2020年4月,AWS与Facebook宣布推出TorchServe ,帮助PyTorch社区的研究人员与机器学习(ML)开发人员更快将其模型投入生产,且无需编写任何自定义代码。TorchServe属于开源项目,很好地解答了业界关于如何使用PyTorch从notebook过渡至生产环境的问题。全球各地的客户(包括Matroid)都亲身体验到由此带来的收益。同样,目前已经超过10000家客户采用Amazon SageMaker快速构建、训练并部署大规模机器学习模型,其中很多客户已经将SageMaker视为机器学习的标准平台。从模型支持的角度来看,Amazon SageMaker对以基础设施为中心带来的所有繁重工作进行抽象化,允许您安全可靠地向全球数百万并发用户提供低延迟预测功能。
TorchServe与Amazon SageMaker原生集成
AWS高兴地宣布,现在Amazon SageMaker已经原生支持将TorchServe作为PyTorch推理的默认模型服务器。以往,您也可以将TorchServe与Amazon SageMaker结合使用,但需要额外将其安装在notebook实例上并启动服务器以执行本地推理;或者通过构建TorchServe容器并引用其镜像以创建托管终端节点。但是,完整的notebook安装流程往往非常耗时,而且某些数据科学家及机器学习开发人员可能不愿将时间与精力浪费在构建Docker容器、将镜像存储在 Amazon Elastic Container Registry (Amazon ECR)之上、创建AWS身份与访问管理(IAM)权限、将模型上传至Amazon Simple Storage Service (Amazon S3)并部署模型终端节点等繁琐工作。但在本次功能更新之后,您已经可以使用原生Amazon SageMaker SDK直接使用TorchServe支持PyTOrch模型。
要在Amazon SageMaker中原生支持TorchServe,AWS工程技术团队向aws/sagemaker-pytorch-inference-toolkit 以及 aws/deep-learning-containers repo提交了大量pull请求。在合并之后,我们可以通过Amazon SageMaker API使用TorchServe执行PyTorch推理。这项新功能也让AWS与PyTorch社区更紧密地协同起来。随着未来关于TorchServe服务框架相关的更多功能陆续发布,我们将不断把这些经过测试、移植并纳入AWS深度学习容器镜像当中。需要强调的是,我们的实现方案向各位用户提供易于使用的Amazon SageMaker PyTorch API ,同时隐藏掉了.mar文件。
Amazon SageMaker中的TorchServe架构

大家可以通过以下步骤将TorchServe与Amazon SageMaker配合使用:
- 在Amazon SageMaker中创建模型。通过创建模型,您可以告知Amazon SageMaker在哪里寻找模型组件。具体包括用于存储模型工件的Amazon S3路径,以及Amazon SageMaker TorchServe镜像的Docker注册表路径。在后续部署步骤当中,大家可以按名称指定此模型。关于更多详细信息,请参阅创建模型。
- 为HTTPS终端节点创建一套终端节点配置。我们可以在生产变体中为一个或者多个模型指定名称,并指定供Amazon SageMaker用于托管各生产变体的机器学习计算实例。在生产环境中托管模型时,大家可以配置该端点以弹性扩展已部署的各机器学习计算实例。对于各生产变体,您还可以指定需要部署的机器学习计算实例数量。在指定两个或更多实例时,Amazon SageMaker将在多个可用区内启动这些实例,借此实现连续可用性。Amazon SageMaker将负责各实例的部署。关于更多详细信息,请参阅创建终端节点配置。
- 创建HTTPS终端节点。向Amazon SageMaker提供终端节点配置。关于更多详细信息,请参见创建终端节点。为了从模型中获取推理结果,客户端应用程序需要将请求发送至Amazon SageMaker Runtime HTTPS终端节点。关于API的更多详细信息,请参阅调用终端节点。
通过以下示例notebook可以看到,Amazon SageMaker Python SDK能够大大简化上述操作步骤。
使用经过调优的HuggingFace transformer base(RoBERTa)
在本文中,我们使用HuggingFace transformer, 由其提供可实现自然语言理解(NLU)的通用架构。具体而言,我们将为大家提供RoBERTa base transformer,此transformer已经过调优以执行情感分析。预训练的检查点会加载其他头层,而模型则输出文本内的正面、中立及负面情绪。

部署CloudFormation栈并验证notebook创建情况
这里我们部署ml.m5.xlarge Amazon SageMaker notebook实例。关于实例费率的更多详细信息,请参阅Amazon SageMaker费率说明。
- 登录至AWS管理控制台。
- 在下表中选择启动模板。
| 启动模板 | 区域 |
 |
北弗吉尼亚州 (us-east-1) |
|
爱尔兰 (eu-west-1) |
|
新加坡 (ap-southeast-1) |
您可以通过更新超链接中的Region值,在任意区域内启动这套示例堆栈。
- 在Capabilities and transforms部分,选中三个确认框。
- 选择 Create stack。

您的CloudFormation堆栈大约需要5分钟才能完成Amazon SageMaker notebook实例及其IAM角色的创建过程。
- 在堆栈创建完成之后,请检查Resources选项卡中的输出结果。
- 在Amazon SageMaker控制台的Notebook之下, 选择 Notebook instances。
- 找到您刚刚创建的notebook,而后选择 Open Jupyter。


访问Lab环境
在notebook实例之内,导航至serving_natively_with_amazon_sagemaker目录并打开deploy.ipynb。
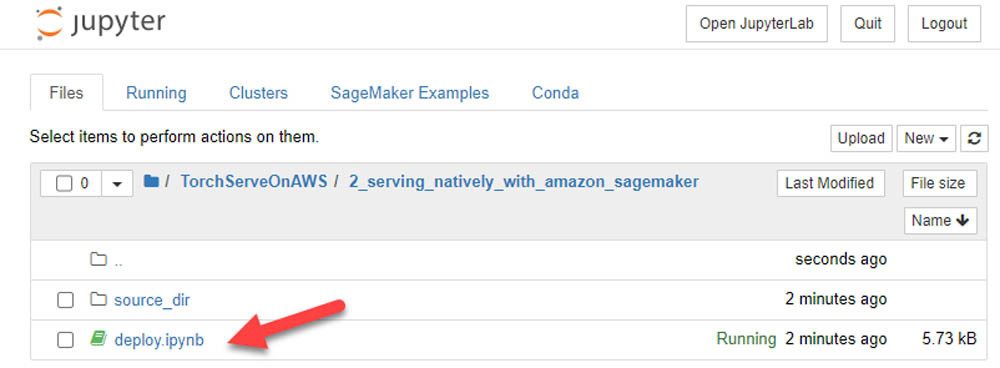
现在,我们可以运行Jupyter notebook中的步骤:
- 设置您的托管环境。
- 创建您的终端节点。
- 使用TorchServe后端Amazon SageMaker终端节点执行预测。
在托管环境设置完成之后,使用原生TorchServe estimator轻松创建Amazon SageMaker终端节点:
model = PyTorchModel(model_data=model_artifact,
name=name_from_base('roberta-model'),
role=role,
entry_point='torchserve-predictor.py',
source_dir='source_dir',
framework_version='1.6.0',
predictor_cls=SentimentAnalysis)
endpoint_name = name_from_base('roberta-model')
predictor = model.deploy(initial_instance_count=1, instance_type='ml.m5.xlarge', endpoint_name=endpoint_name)
资源清理
在完成本轮演练之后,您的Amazon SageMaker终端节点应该已经被正确删除。如果未能删除,请完成以下操作步骤:
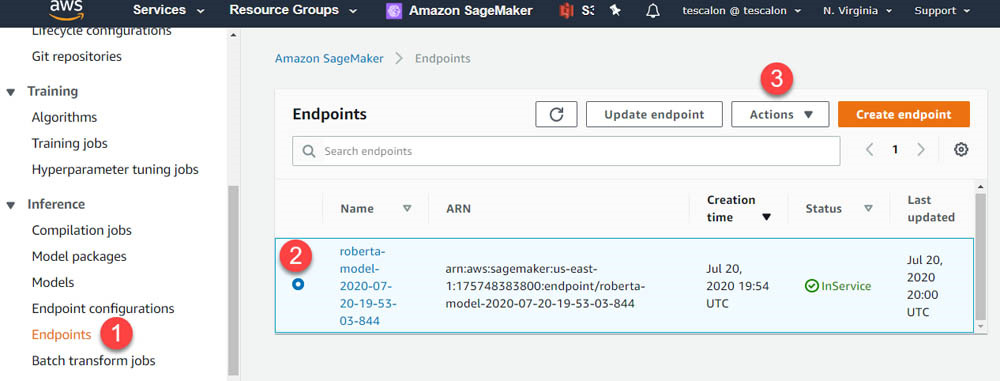
- 在Amazon SageMaker控制台的 Inference之下, 选择 Endpoints。
- 选定要删除的终端节点(应以 roberta-model开头)。
- 在 Actions下拉菜单中, 选择 Delete。
在AWS CloudFormation控制台上,选择torchserve-on-aws堆栈并选择Delete以删除剩余环境。

现在,我们会看到另外两个基于源CloudFormation模板构建的堆栈名称。这些是嵌套栈,并且会与主栈被一同删除。清理流程大约需要3分钟左右,包括停止环境运行、删除notebook实例以及与之关联的IAM角色。
总结
随着客户对于TorchServe需求的不断增长以及PyTorch社区的快速发展,AWS致力于为客户提供一种通用且高效的PyTorch模型托管方式。无论您使用的是Amazon SageMaker、 Amazon Elastic Compute Cloud (Amazon EC2)还是 Amazon Elastic Kubernetes Service (Amazon EKS), 我们都将不断优化后端基础设施并为开源社区提供支持。这里也建议大家根据需求在项目repo(TorchServe、AWS Deep Learning容器、PyTorch推理工具包等)中提交pull请求及/或创建问题。