亚马逊AWS官方博客
简化故障注入,读懂应用影响:用 AI Agent 做混沌工程
摘要:本文介绍了如何通过三个 AI Agent Skill 降低混沌工程的实践门槛。传统方式下,AWS FIS 学习曲线陡峭且缺乏应用层观测能力。通过将专业知识封装到 Agent 中,工程师只需描述测试意图,即可自动完成故障注入、日志采集和智能分析的完整闭环,让混沌工程从”专家专属”变为”人人可做”。
目录
一、专业能力的门槛问题
在技术领域,有一类能力被称为”专家专属”——大家都知道重要,但实际做的人很少。混沌工程就是典型例子。
2011 年,Netflix 开源了 Chaos Monkey,开启了混沌工程的先河。此后,这个理念逐渐被业界认可:与其等待生产环境出问题,不如主动注入故障,验证系统的韧性(Resilience)。AWS 在 2021 年推出了 Fault Injection Service (FIS),让混沌工程变得更加标准化和易于管理。
然而,十多年过去了,真正在团队中常规化实施混沌工程的组织仍然是少数。
为什么?不是不想做,而是门槛太高。
这是很多专业工具的共同困境:工具本身很强大,但要用好它,你得先成为这个工具的专家。对于混沌工程来说,你需要理解 FIS 的概念模型、熟悉几十种 action 的适用场景、掌握 Scenario Library 的配置方式、了解各种资源的兼容性要求……这条学习曲线,足以让很多团队望而却步。
但如果有另一种可能呢?
如果专业知识可以被”封装”到 AI Agent 中,用户只需描述意图,Agent 负责选择工具、配置参数、执行操作——这不是”替代专家”,而是”让非专家也能做专家的事”。
本文以混沌工程为例,展示这种范式转变的具体实践:三个Agent Skill 如何让任何工程师都能完成 EKS 故障演练,从”先学 FIS 才能做实验”到”描述意图就能做实验”。
二、旧范式的困境:为什么混沌工程难以普及
2.1 困境一:FIS 学习门槛高
AWS FIS 功能强大,但学习曲线陡峭:
- Action 众多 —— 几十种 action,每种对应不同服务和故障类型,选哪个?
- 兼容性隐蔽 —— 某些 action 只适用特定资源类型(如 failover-db-cluster 只能用于 Aurora),配置时不会提醒,启动时才报错
- Scenario Library 复杂 —— 4 种复合场景的 JSON 模板无法通过 API 生成,需要从文档手动提取
从”我想测试 AZ 故障”到写出正确的 experiment template,新手需要走完:理解概念 → 选择 action → 了解兼容性 → 编写模板。这条路不短也不易。
2.2 困境二:应用层影响的观测盲区
即使你成功完成了一次 FIS 实验,挑战还没结束。
FIS 的实验报告只提供基础设施视角:RDS failover 耗时 30 秒,ElastiCache 节点恢复正常……但应用呢?
- 连接池断开了多久?
- 重试机制生效了吗?
- 用户看到错误页面了吗?
- 应用恢复正常花了多长时间?
这些问题,FIS 报告回答不了。你需要手动收集 kubectl logs,与实验时间线对齐,逐一分析。这个过程繁琐且容易遗漏关键信息。
混沌工程的真正价值不在于”注入了故障”,而在于”理解系统如何响应故障”。如果观测能力跟不上,实验的价值就大打折扣。
三、新范式的实践:AI Agent 如何封装专业能力
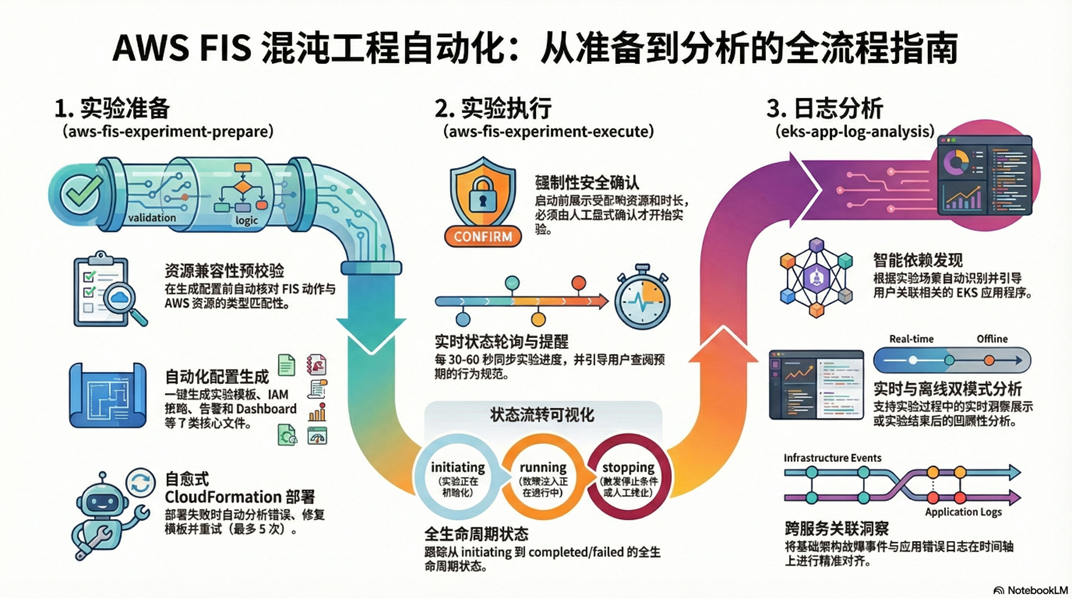
我们开发了三个 Agent Skill,形成一个端到端的混沌工程流水线:
[图1] |
这三个 Skill 的核心价值是:补齐 FIS 缺失的应用日志采集与分析能力,形成”故障注入 → 日志采集 → 智能分析”的完整闭环。用户只需用自然语言描述意图,Agent 自动完成从实验准备到结果分析的全流程。
3.1 Skill 1:aws-fis-experiment-prepare
解决问题: FIS 学习门槛高
工作方式
用户只需描述测试意图,例如:
- “准备一个 AZ 断电实验,目标是 us-east-1a”
- “我想测试 RDS 故障转移对应用的影响”
- “帮我设置一个 EKS Pod 网络延迟的实验”
Agent 会自动完成以下工作:
1. 理解意图,选择方案 —— 根据用户描述,判断应该使用哪个 FIS action 或 Scenario Library 场景。支持的场景不仅限于 Scenario Library 的 4 种复合场景(AZ 断电、AZ 应用减速、跨 AZ 流量减速、跨 Region 连接中断),还包括 EKS Pod 级别的 7 种故障注入(网络延迟、丢包、端口黑洞、CPU/Memory/IO Stress、Pod 删除)、EC2 实例故障、RDS/Aurora 故障转移、ElastiCache 中断、EBS 延迟注入等几十种 action。
2. 查询资源,验证兼容性 —— 调用 AWS CLI 发现目标资源,主动检查资源类型与 action 的兼容性。例如,用户说”测试 RDS 故障转移”,Agent 会先通过 describe-db-instances 确认这是 Aurora 集群还是独立 RDS 实例——如果是独立实例,failover-db-cluster 不适用,Agent 会自动建议改用 reboot-db-instances 并解释原因。这种兼容性验证在手动操作中极易遗漏,往往到实验启动时才报错。
3. 读取文档,获取模板 —— 对于 Scenario Library 场景,自动读取 AWS 文档提取 JSON 模板(这些模板无法通过 API 生成)
4. 处理 EKS Pod action 的复杂前置条件 —— EKS Pod 级别的故障注入有一系列独特的前置要求:集群认证模式必须是 API_AND_CONFIG_MAP 或 API、需要 K8s RBAC 资源(ServiceAccount、Role、RoleBinding)、Pod 的 readOnlyRootFilesystem 不能为 true。Agent 通过 Lambda + CloudFormation Custom Resource 自动管理这些 K8s RBAC 资源——幂等创建、跨实验共享、栈删除时不清理——用户完全不需要手动执行 kubectl apply。
5. 生成配置目录 —— 输出完整的配置目录,包括 experiment template、IAM policy、CloudFormation 模板、CloudWatch 告警和 Dashboard。这个目录将作为下一个 Skill 的输入
6. 权限预检与部署 —— 部署前先检查当前 IAM 身份是否具备 CloudFormation 权限(通过 IAM policy simulation 验证),如需 CFN Service Role 则自动检测并附加。然后执行 CloudFormation 部署,创建所需的 IAM 角色、告警和实验模板。
额外亮点:自愈式部署。 CloudFormation 部署经常因为各种原因失败(IAM 传播延迟、区域限制、属性验证错误)。Agent 会自动分析错误原因、修复模板、删除失败的栈、重新部署,最多重试 5 次。用户不需要看 CloudFormation 错误日志。
核心价值: 用户不需要学习 FIS action 的细节,不需要知道 failover-db-cluster 和 reboot-db-instances 的区别,不需要手动处理 EKS RBAC 配置,只需要描述”我想测什么”。Agent 自动完成场景选择、资源发现、兼容性验证、前置条件处理、文件生成和部署验证的全流程。Skill 之间通过配置目录传递上下文,形成完整的工作流。
3.2 Skill 2:aws-fis-experiment-execute
功能: 安全执行实验 + 智能日志集成 + 监控 + 结果报告
FIS 实验会影响真实的生产资源。这个 Skill 的设计原则是:安全第一,绝不自动启动。
工作流程:
- 验证 CloudFormation 栈状态,确认部署成功
- 提取实验模板 ID 和受影响资源列表
- 实验分类与日志采集决策 —— Skill 先分析实验模板中的所有 actionId,将实验分类为 POD 类型(包含 aws:eks:pod-* action)或 NON-POD 类型(纯基础设施),并向用户展示分类结果和具体的 action 列表。对于 Pod 类型实验,自动启用应用日志采集;对于非 Pod 类型实验(如 RDS failover、EC2 stop),Skill 会主动询问用户是否需要采集应用日志,并提示”基础设施故障可能级联到应用层,导致连接超时、故障转移重试等错误”,帮助用户做出判断。这种设计让用户对实验影响范围一目了然,同时确保涉及应用的实验自动获得完整的观测能力
- (启用日志采集时)实验启动前发现应用并开始日志采集 —— 调用 eks-app-log-analysis 自动发现依赖受影响服务的 EKS 应用,启动后台 kubectl logs -f 收集日志。这一步必须在实验启动前完成,否则可能错过故障注入初期的关键日志。可选的 baseline 采集功能允许在实验前收集 2 分钟正常态日志作为对比基线
- 展示影响范围,要求用户明确确认 —— 显示实验类型(POD/NON-POD)、目标资源、影响区域、预计时长,以及正在监控的应用列表(如已启用日志采集)
- 用户确认后才启动实验
- 监控实验状态 —— 每 30-60 秒轮询实验状态,跟踪各服务的状态变化和恢复时间线。如果启用了日志采集,每个 poll 周期同时分析各应用的日志:统计错误/警告数量、展示最近的错误行、检测恢复信号(如 connected、restored)。提醒用户查看 CloudWatch Dashboard
- 生成结果报告 —— 为每个受影响的服务生成独立的 Per-Service Impact Analysis 子章节,每个子章节内嵌时间线事件表和关键发现。如果启用了日志采集,报告中还会嵌入来自 eks-app-log-analysis 的应用层分析(错误时间线、模式统计、恢复时间、跨服务关联);未启用则仅包含基础设施视角的分析。时间线直接嵌入服务分析中,读者无需在不同章节间跳转即可看到完整图景
3.3 Skill 3:eks-app-log-analysis
解决问题: 应用层观测盲区
工作方式
支持两种模式(通过输入类型自动检测):
- 实时监控 —— 输入实验配置目录,实验进行中每 30 秒展示日志洞察
- 事后分析 —— 输入 *-experiment-results.md 报告文件,基于时间范围批量分析
Agent 会:
- 读取实验上下文,了解涉及哪些 AWS 服务
- 自动发现应用依赖 —— 查询受影响服务的端点,搜索所有 Pod 环境变量和 ConfigMap,找出哪些应用连接了这些服务
- 让用户确认发现结果,并补充遗漏的应用
- 自动收集相关应用的日志:
- 实时模式:使用 kubectl logs -f –selector={labels} 后台采集(基于 label selector 而非 deployment 名称,确保捕获实验期间重建的 Pod 日志)
- 事后分析模式:采用分级日志源策略——优先检测集群是否启用了 Container Insights(检查 amazon-cloudwatch-observability addon 或 CloudWatch agent DaemonSet),如果有则通过 CloudWatch Logs Insights 查询 /aws/containerinsights/{cluster}/application 日志组,获取包括已终止 Pod 在内的完整日志;如果没有 Container Insights,则 fallback 到 kubectl logs –since-time,但会提示用户这种方式无法获取已终止 Pod 的日志
- 生成应用层分析报告:
- 错误时间线(与 FIS 事件对齐)
- 错误模式统计
- 恢复时间分析
- 跨服务关联表 —— 将时间线、各服务影响和应用响应统一到一张表中,清晰展示故障传播路径:例如 RDS failover 发生时 ElastiCache 状态如何、应用日志出现了什么错误
- 改进建议
核心价值: 补全了 FIS 报告缺失的”应用视角”,让混沌工程的分析从基础设施延伸到业务影响。
四、示例:实际报告展示
以下是通过 Agent Skill 完成的故障演练报告示例。
示例 1:Redis + MySQL 故障时的应用表现
这是一次同时测试 ElastiCache Redis AZ 电源中断和 RDS MySQL failover 的实验。以下是 aws-fis-experiment-execute 自动生成报告的核心内容:
示例 2:Pod 到数据库的网络延迟注入
在实际场景中,托管数据库可能包含多个 database 供不同应用使用,直接重启数据库影响范围太大。更精准的做法是:对特定应用的 Pod 注入网络延迟,模拟该应用到数据库的网络故障,而不影响其他应用。以下是 eks-app-log-analysis 自动生成应用日志分析报告的核心内容:
示例 3:AZ 电源中断场景
这是最全面的混沌实验场景:模拟整个可用区 (us-west-2a) 的电源中断,同时影响 EC2 节点、ElastiCache、RDS 故障转移、网络连接和 ASG 扩容。这个场景包含 6 个并行 action,可以验证系统在真实 AZ 故障时的恢复能力。
关键发现:AZ 网络黑洞 vs 单独数据库重启的行为差异
在之前的数据库高可用切换实验中,应用日志总能捕获到 connection refused 或 broken pipe 等错误。但在 AZ 电力中断场景下,我们发现了一个单独做数据库切换实验无法暴露的问题:应用日志竟然显示”零错误”,但服务实际上已经完全不可用。
| 单独 RDS 重启(之前的实验) | AZ 电力中断(本次实验) | |
| 网络状态 | 正常 | us-west-2a 全部流量被黑洞 |
| TCP 连接断开方式 | RDS 主动发送 RST/FIN → 快速断开 | 数据包被静默丢弃 → TCP 重传超时 |
| 应用感知 | 立即收到 connection reset → 报错并重连 | 无任何回复 → 无限阻塞等待 |
| 应用日志表现 | connection refused / broken pipe 错误 | 零日志 — 请求卡住不返回 |
| 恢复时间 | 几秒(DNS 切换后自动重连) | ~14 分钟(等待 TCP 超时) |
原因在于:当 FIS 的 disrupt-connectivity action 将整个 AZ 的网络流量黑洞化后,TCP 数据包被静默丢弃(没有 RST/FIN 回复)。Go MySQL driver 的读写操作无限阻塞在 db.Query() 上,HTTP 请求无法完成,GIN 框架也就没有任何日志输出。这种”静默挂起”比明确的错误更难发现——监控系统看到的是”没有日志”而非”错误日志”。
最终,应用需要等待 Linux 内核的 tcp_retries2 超时(约 13-15 分钟)才能恢复,远超 RDS 故障转移本身的 2-3 分钟。根因是应用的 MySQL DSN 缺少 readTimeout/writeTimeout 配置——这在单服务故障时不是问题(因为有 RST 信号快速断开),但在网络黑洞场景下会导致灾难性的长时间不可用。
这正是 AZ 级别混沌实验的核心价值:暴露那些单组件故障演练无法发现的系统性问题。
五、范式转变的效果
对比:谁能做混沌工程?
| 维度 | 旧范式(手工) | 新范式(Agent Skill) |
| 前置知识 | 需要熟悉 FIS action、scenario、资源兼容性 | 只需描述测试意图 |
| 学习曲线 | 数小时到数天 | 几乎为零 |
| 执行时间 | 半天到一天(新手) | 10-15 分钟 |
| 谁能做 | FIS 专家或愿意投入学习的工程师 | 任何了解业务的工程师 |
这里的关键变化不是”快了多少倍”,而是**”原本不会做的人现在能做了”**。
当混沌工程的门槛从”需要专家”降低到”会描述意图”,它就有可能从”年度演练任务”变成”团队常规实践”。这才是 Resilience 工程的真正目标。
六、更大的图景:专业能力的普惠化
混沌工程只是一个例子。
技术领域有大量”专家专属”的能力:安全审计、性能调优、合规检查、架构评估、成本优化……这些能力的共同特点是:工具强大,但学习门槛高。结果是,很多”应该做”的事情,因为”不会做”而被搁置。
AI Agent 提供了一种新的可能:把专业知识封装成可对话的能力。
这是一种范式转变:
| 旧范式 | 新范式 |
| 人先学工具 → 再用工具做事 | 人描述意图 → Agent 选择工具、配置、执行 |
| 专业知识是使用门槛 | 专业知识被封装到 Agent 中 |
| 能力受限于个人学习投入 | 能力受限于 Agent Skill 的覆盖范围 |
这不是”降低标准”——专业知识没有消失,而是换了一种存在形式。也不是”替代专家”——对于复杂场景和边界情况,仍然需要专家判断。但对于大量标准化的、重复性的专业任务,Agent Skill 可以让更多人参与进来。
对工程师来说,这意味着:
- 可以专注于决策和分析(这是混沌工程的真正价值),而不是工具配置
- 可以更频繁地进行 Resilience 测试,而不是因为门槛高而放弃
- 可以把时间花在理解系统行为上,而不是学习又一个专业工具
Agent Skill 是一种新的知识封装和分发方式。我们期待看到更多专业领域的能力被”普惠化”——不是取代专家,而是让专家的知识能够惠及更多人。
你的领域有哪些专业能力,可以被封装成 Skill?
本文涉及的三个 Agent Skill 已开源:https://github.com/aws-samples/sample-fis-skills/
七、结语
➡️ 下一步行动:
相关产品:
- Amazon RDS — 完全托管的关系数据库服务
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon CloudFormation — 基础设施即代码服务
- Amazon ElastiCache — 无服务器缓存
- Amazon IAM — 身份管理和访问权限
相关文章:
- 从代码到分子系列:一场由 AI 驱动的 EGFR 抑制剂发现之旅 — 深度融合 AWS Bedrock与 Claude Code/Claude Agent Skills,生命健康行业的科学活动探微
- (上篇)基于 AWS Bedrock AgentCore 构建企业级航空客服智能体 —— 基于AIDLC方法从需求分析到生产部署的完整实践
- AWS Security Agent 渗透测试实操
- (下篇)Solutions Memory:让 AI Agent 从成功案例中持续学习 —— 双 Memory 架构实践
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
