亚马逊AWS官方博客
Valkey 为什么这么快?盘点 Valkey 中提升性能的黑科技
摘要:Valkey 是 Amazon ElastiCache 的核心引擎,作为一款高性能的开源内存数据库,Valkey自诞生以来,在性能方面实现了惊人的突破:单节点吞吐量可达 119 万 RPS,集群规模可扩展到 2000 节点,从而实现 10 亿规模的RPS。随着今年5月份Valkey 9.0的发布,它的性能再一次得到提升,你可以在Amazon ElastiCache体验它的速度。Valkey是怎么做到这么快的呢?本文将带领读者,一起深入剖析成就了这个性能怪兽背后的那些“黑科技”。
目录
一、概述
Valkey 是 Amazon ElastiCache 的核心引擎。用户无需自行编译部署,即可通过 ElastiCache 开箱即用地享受Valkey的特性。作为一款高性能的开源内存数据库,Valkey自诞生以来,在性能方面实现了惊人的突破:单节点吞吐量可达 119 万 RPS,集群规模可扩展到 2000 节点,从而实现 10 亿规模的RPS。随着今年5月份Valkey 9.0的发布,它的性能再一次得到提升,Pipeline 场景下的吞吐量提升了40%,你可以在Amazon ElastiCache体验它的速度。Valkey是怎么做到这么快的呢?本文将带领读者,一起深入剖析成就了这个性能怪兽背后的那些“黑科技”。
二、Valkey 的五层架构
Valkey 作为 Redis 的fork版本,在完整支持 Redis OSS 7.2 全部API的基础上 ,同时也引入了 Valkey 特有的功能,如向量搜索引擎(Valkey-Search),多数据库集群模式(Numbered Databases),Hash字段级过期(Hash Field Expiration)等。随着9.0版本的发布,Valkey已经从一个传统的NoSQL缓存数据库成长为适应更多复杂应用场景的全能选手。
在介绍具体的性能优化技术之前,让我们先从全局视角来了解一下Valkey的系统架构:
- GLIDE 客户端:GLIDE 是 General Language Independent Driver for the Enterprise 的缩写,由 AWS 联合 Google 和 Valkey 社区共同开发。在客户端中,Rust Core作为底层核心,处理客户端与服务端通信的所有底层任务,上层则提供了多语言支持。此外,GLIDE还内置了连接管理、重试、故障转移、集群拓扑感知、AZ 亲和路由等生产级特性;
- 网络连接层:通过 TCP/IP、Unix Socket,以及RDMA 方式接收客户端连接,使用 epoll/kqueue 多路复用和多线程 I/O处理读写操作,这也是让它有优异性能的关键技术之一,我们会在后面的章节详细介绍;
- 命令处理层:命令是以单线程的方式,由主线程顺序执行,并支持流水线批处理和键空间变更的 Pub/Sub 事件通知;
- 数据结构与存储层:除兼容Redis原有数据结构外,采用缓存行优化的哈希表;在集群模式下使用每槽(per-slot)字典组织数据并利用 Fenwick 树进行高效槽操作,这也是Valkey在内存层面的性能优化大招;
- 持久化与复制层:通过 fork() 实现零影响的 RDB 后台快照,支持 AOF 追加日志和双通道复制;
- 集群协调层:使用16,384个哈希槽分布数据,通过 Gossip 协议传播集群状态,支持自动故障转移。
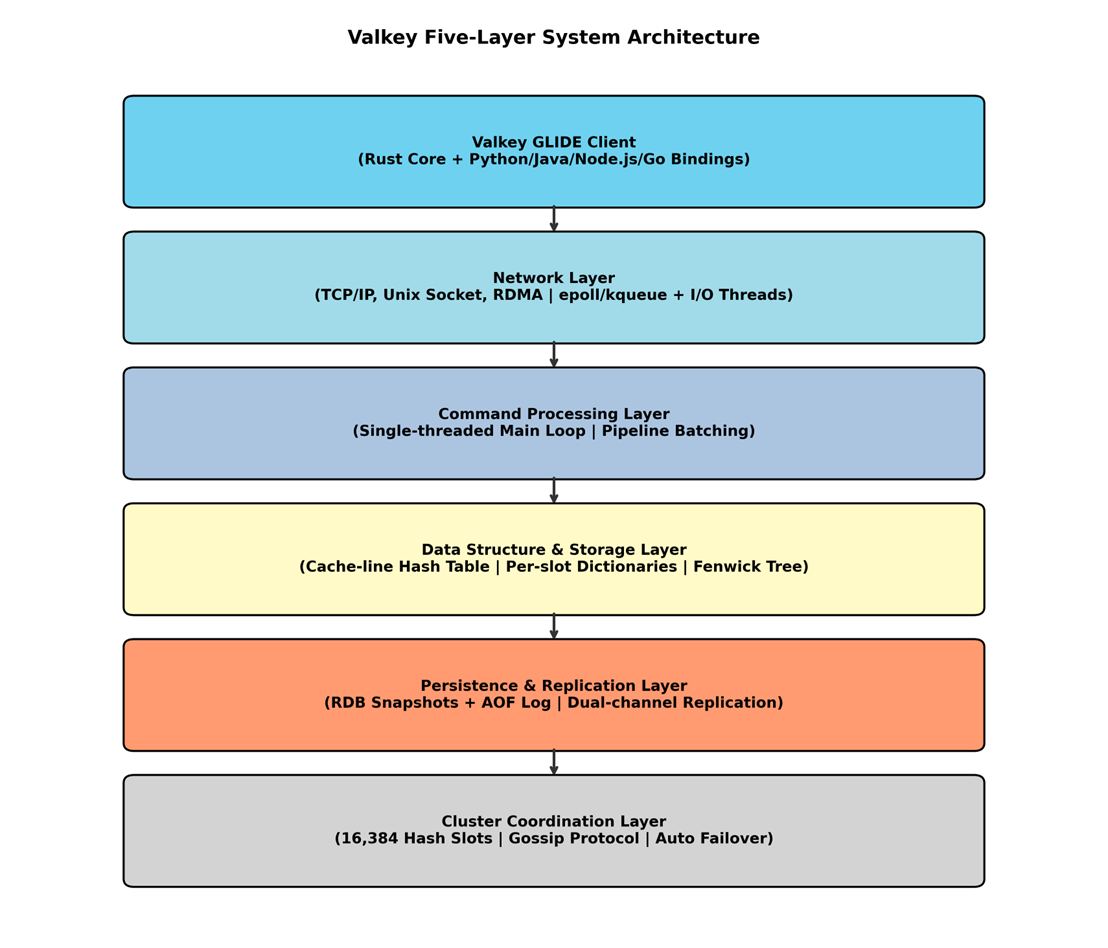
[图1:Valkey的五层系统架构] |
Valkey 的核心设计哲学是单线程执行命令 + 多线程处理 I/O。这样可以让主线程保证原子性和 API 的简洁性,而I/O 线程则负责榨取硬件的性能。这种分层解耦的设计原则可以让每一层都能独立优化。下面就让我们一起探索Valkey在不同层面所做的性能提升。
三、网络与 I/O 层优化
3.1 多线程 I/O 架构
在电商大促、新产品秒杀、游戏开服等场景下,瞬间涌入的数百万请求会让传统的单线程 I/O 成为瓶颈。Valkey 8.0 版本之前的多线程 I/O是同步模式,主线程和 I/O 线程交替工作,无法并发。在高并发情况下,epoll_wait 系统调用和数据读写会占用主线程超过 20% 的时间。在8.0版本中,AWS 团队贡献了全新的异步并发架构——主线程和 I/O 线程可以真正并发运行,加上了 epoll 卸载、动态线程伸缩、命令批处理等能力。多线程 I/O 并不是“多线程的执行命令”,而是将纯 I/O 操作(如读取请求、解析协议、发送响应、轮询事件)卸载到独立的 Worker 线程池,而主线程专心做最核心的事:执行命令。这也是很多数据库产品和Web服务器使用的技术。在托管服务Amazon ElastiCache 中,多线程 I/O 默认启用,用户无需手动配置线程数,服务会根据节点规格自动调优。
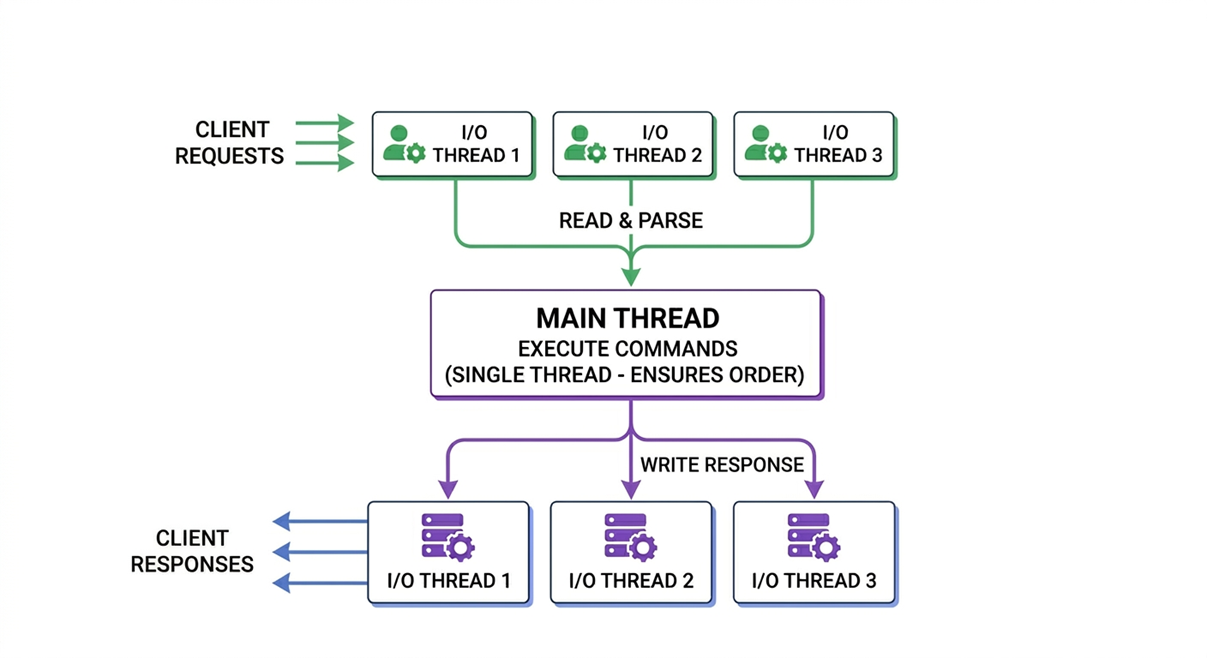
[图2:Valkey中的多线程I/O] |
多线程I/O主要有下面几点设计细节:
- 线程亲和性:同一客户端尽量由同一 I/O 线程处理,提升 CPU 缓存命中率
- 动态伸缩:根据实时负载自动增减 I/O 线程数量
- 零竞争:I/O 线程与主线程之间通过事件通知协调,无需加锁
在多线程I/O的加持下,Valkey的吞吐量有了大幅提升。从下图的对比测试可以看出,系统在使用8个 I/O 线程时吞吐量从 360K 提升至 1.19M RPS,达到了惊人的230%;平均延迟也从 1.792ms 降至 0.542ms,降幅达69.8% (测试环境:AWS EC2 c7g.4xlarge,3M keys,512B value,650 clients)。此外,因为socket 轮询系统调用(epoll_wait)被卸载到 I/O 线程,减少了主线程20%的消耗时间。
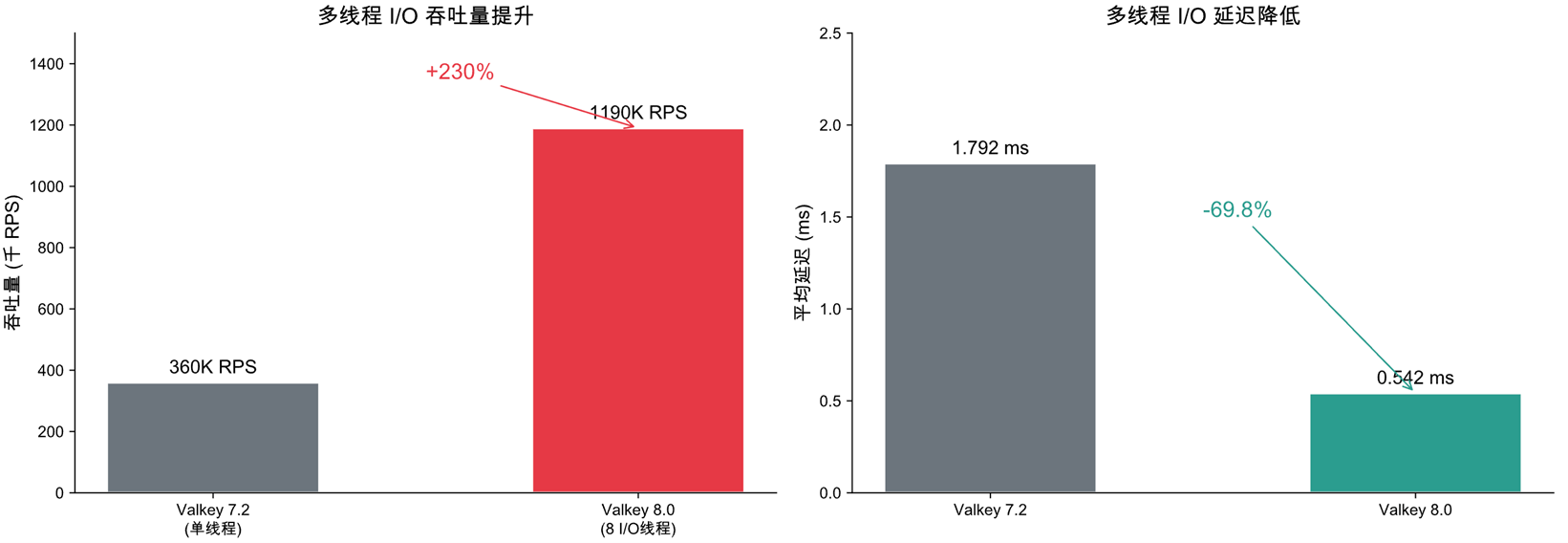
[图3:多线程I/O性能对比测试] |
3.2 RDMA 远程直接内存访问
有一些对网络延迟极度敏感的应用场景。例如实时竞价广告(RTB),用户在打开网页或者APP时,会触发一个广告请求,由面向媒体主的卖方代理平台(SSP)实时发送一个竞价请求(bid request),广告交易平台再将请求广播给买方平台,最后将竞价胜出的广告素材在媒体上展示出来,整个过程需要在毫秒级完成。因为有网络的介入,必然会增加整个链路的访问延迟。RDMA(Remote Direct Memory Access)传输技术允许一台机器直接读写另一台机器的内存,从而绕过对方的 CPU 和操作系统内核来提升访问速度。RDMA与传统网络通信有如下的区别:
- 零拷贝(Zero-copy):数据不经过内核缓冲区,直接在应用内存和网卡之间传输
- 内核旁路(Kernel bypass):不走操作系统网络协议栈
- CPU 卸载:远端 CPU 完全不参与数据搬运
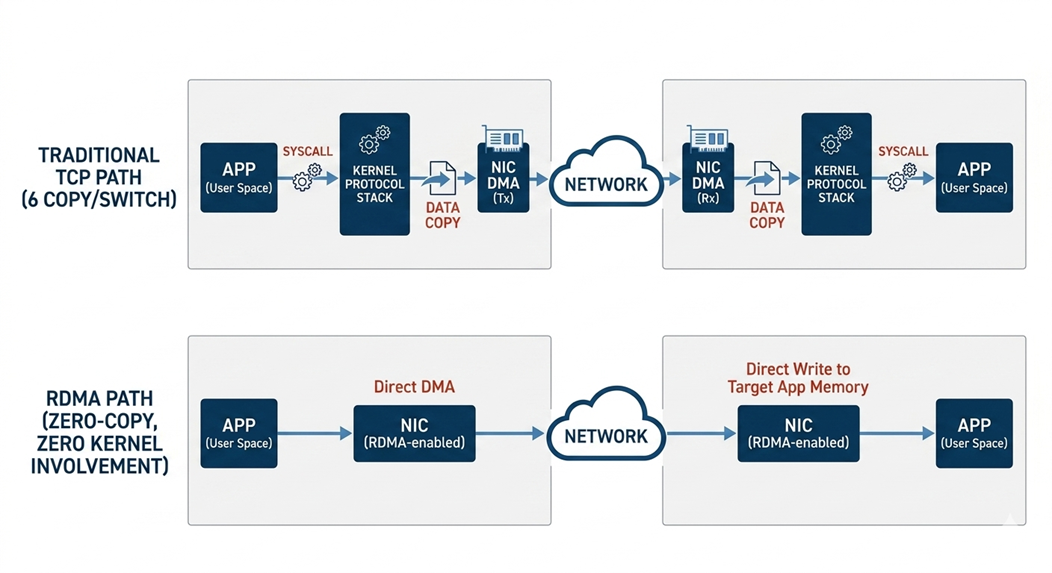
[图4:RDMA传输模式] |
Valkey 通过 valkey-rdma.so 模块支持 RDMA 传输。在其加持下,相比TCP路径实现了约 2 倍的 QPS 提升和更低的延迟。(注:RDMA 是 Valkey 开源社区的实验性网络优化技术, Amazon ElastiCache 托管服务中并未启用,目前主要通过 Enhanced I/O 和多线程架构来实现网络层加速)
3.3 Multipath TCP
在许多业务场景下,比如游戏应用,其流量有突然爆增、跨 AZ、不能中断等特点。例如一个 MMO 游戏会将不同区域的玩家状态缓存在 ElastiCache 的多 AZ 中。当玩家跨地图传送或大规模团战时,需要跨 AZ 读取玩家属性(血量、装备、位置坐标等)。这种情况下,单路径容易拥塞,链路抖动也会导致卡顿。 使用MPTCP技术可以多路径聚合带宽,卡顿时自动切换路径,保证连接不中断。Multipath TCP (MPTCP)是标准 TCP 的扩展,允许一个 TCP 连接同时使用多条网络路径传输数据。它会在传输层将一个 TCP 连接分散到多条子流(subflow),自动做负载均衡和故障切换。与传统TCP相比具有如下的优势:
| 特性 | 说明 |
| 降低延迟 | 数据可走最快的路径,避免单条路径拥塞 |
| 提升带宽 | 多条路径聚合带宽 |
| 容错/高可用 | 一条路径断开时,连接不中断,自动切到其他路径 |
| 透明兼容 | 对上层应用透明,仍是一个 TCP socket |
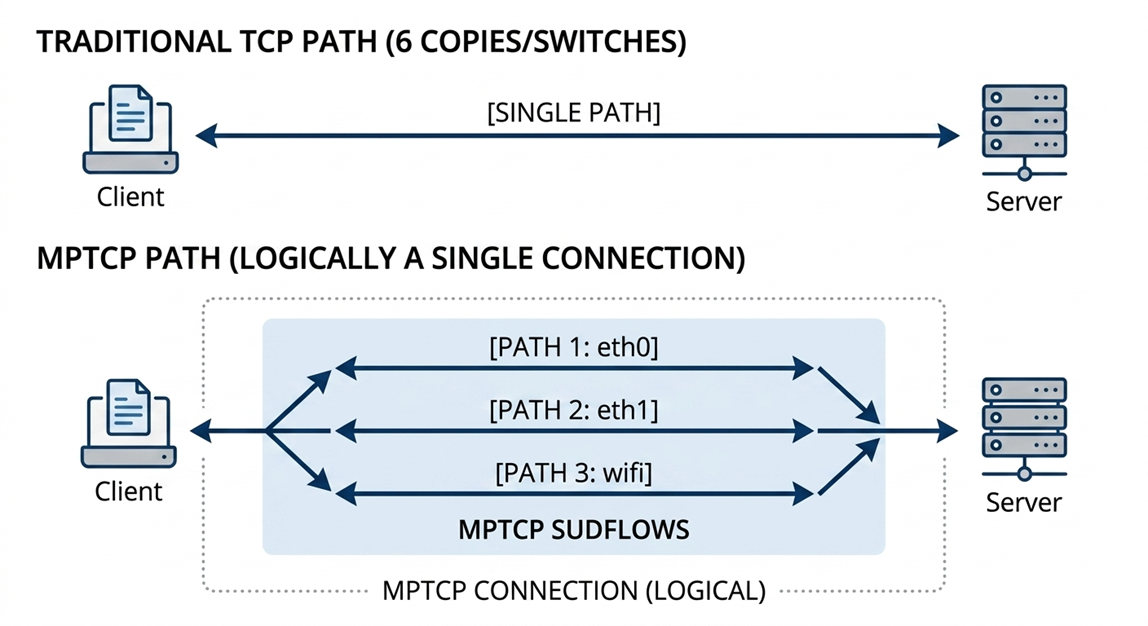
[图5:MPTCP与TCP路径对比] |
Amazon ElastiCache 9.0 for Valkey 已经有了 MPTCP 网络支持,具体应用在客户端/服务端连接以及集群内节点间通信:
- 客户端到Valkey 节点:客户端连接可走多条网络路径(例如主机有多块网卡或多条网络链路),减少单路径故障导致的连接中断
- 集群节点间通信:节点间的复制和集群通信可利用多路径,降低跨机架/AZ 的通信延迟
根据 Valkey 9.0 发布的公告,MPTCP 可降低约 25% 的延迟。
3.4 零拷贝响应(Zero Copy Response)
零拷贝是指在数据传输过程中避免不必要的内存复制(memcpy),让数据直接从源位置发送到目标位置,减少 CPU 开销和内存带宽占用。在 Valkey 9.0 之前,当客户端请求一个大对象(比如 10MB 的字符串)时,主线程必须等待这 10MB 的 memcpy 完成后才能处理下一个命令。即使只有少量大对象请求,也会阻塞主线程,导致其他小对象请求的延迟飙升。使用零拷贝后有如下几点提升:
- 主线程不再 拷贝大对象,只写入一个 16 字节的指针引用
- I/O 线程通过
writev()配合iovec,直接从原始内存位置把数据发送到 socket - 主线程几乎零开销,立即可以处理下一个命令
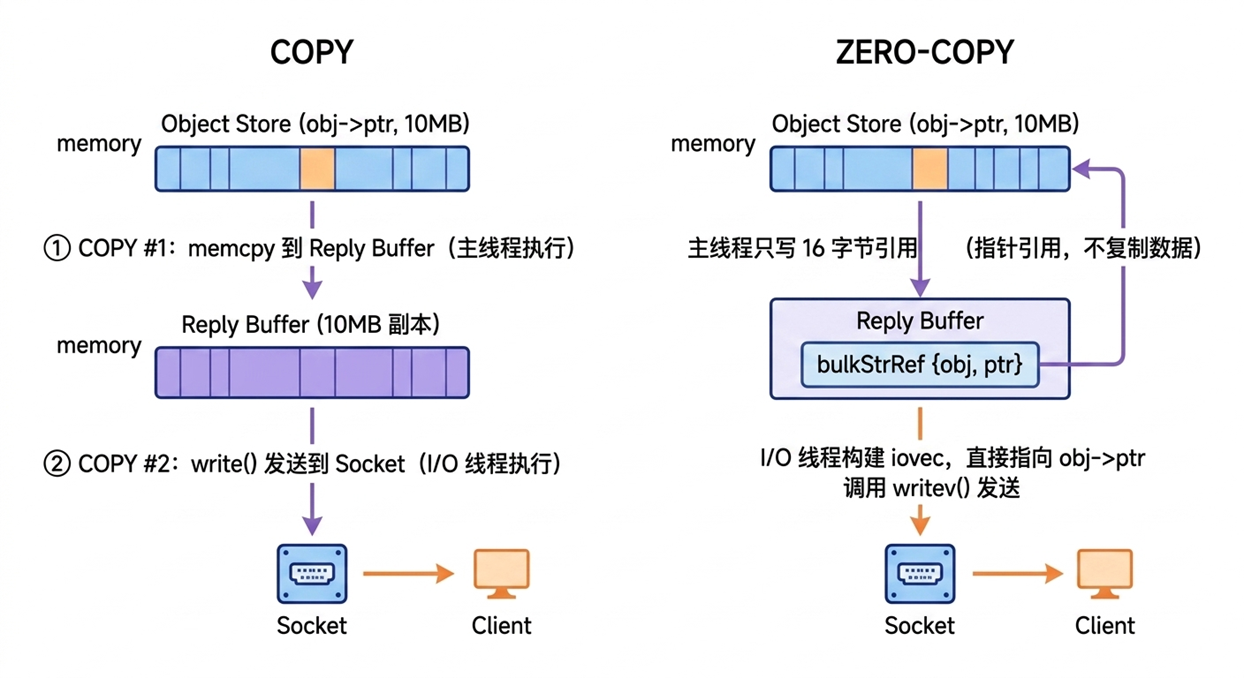
[图6:普通拷贝和零拷贝的对比] |
Valkey 9.0 默认开启零拷贝,并提供了3个参数可以进行动态调整。在与Valkey 8.1的实际对比测试效果来看,1KB 请求 + 10MB 大对象的混合负载下,8.1版本的p99 延迟为26.2ms,而9.0版本只有8ms,几乎不受影响。
四、CPU 与命令执行优化
4.1 内存访问摊销(Memory Access Amortization)
当处理大量的 key 时,每次 lookupKey都需要跟随指针链查找。这些指针地址是串行依赖的,必须先拿到前一个地址的内容,才能知道下一个地址在哪。如果 key 集合很大,大量的指针跳转会发生 cache miss,触发昂贵的外部内存访问。Profiling 显示,主线程 40% 以上的时间都花在了 lookupKey 上,CPU 100% 利用率,但实际上大部分时间在是等内存。
内存访问摊销的核心思想可以归纳为:交错执行 + 预取。即不要一个一个的串行查找,而是将多个 key 的查找操作交错执行,让 CPU 能同时发起多个内存访问请求。假设有 16 个链表,串行遍历所有链表需要 20多秒,但如果交错遍历(每轮对每个链表前进一步),只需不到 2 秒,可获得10倍提速!
那为什么叫“摊销”呢?我们假设单次内存访问的延迟(100ns)没有变,但通过同时发起 N 个内存请求,总等待时间从 N × 100ns 变成了接近 1 × 100ns,延迟被 N 个操作均摊了,类似算法复杂度中的“摊销分析”。 其实这种做法和编程语言中的并行执行是一个道理,比如Golang语言中的sync.WaitGroup。
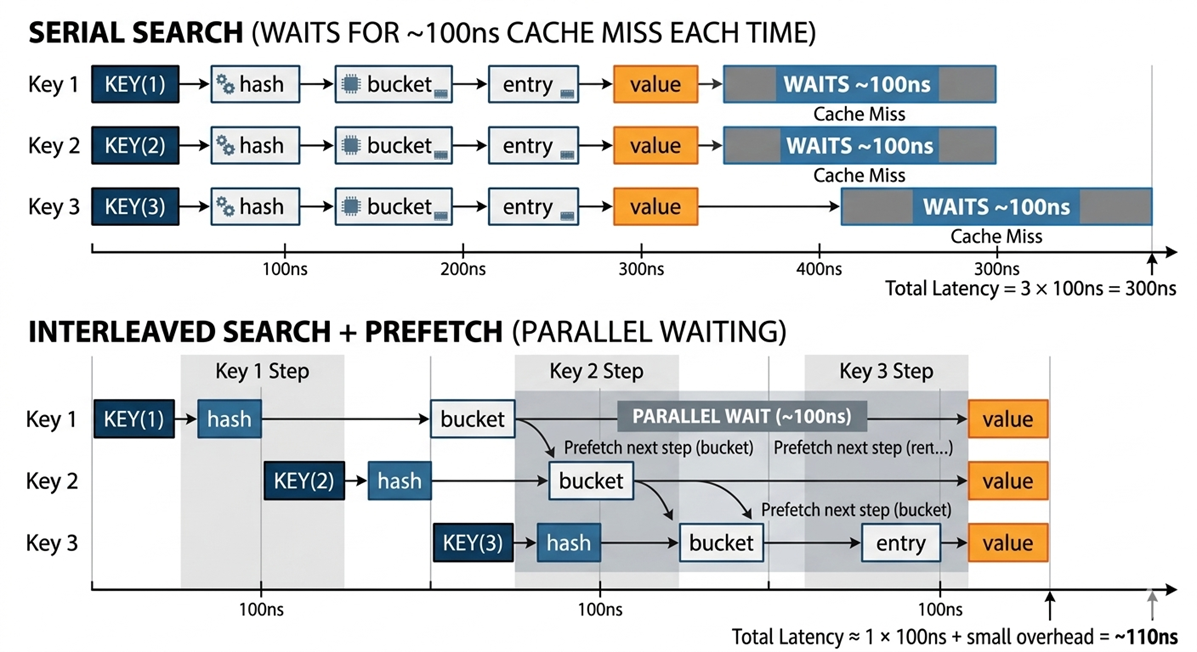
[图7:串行搜索与内存访问摊销的对比] |
从效果上看,ElastiCache Serverless 达到了每缓存 500 万的RPS(比 7.2 快 5 倍),其中内存访问摊销是关键提速手段之一。
4.2 管道内存预取(Pipeline Memory Prefetch)
Pipelining(流水线/管道)是一种批量发送命令的技术。一般情况下,客户端每发一条命令都要等服务器返回结果后才发下一条。而 Pipelining 是一次性发送多条命令,不等单条回复,最后统一接收所有响应。这在批量推荐计算、实时榜单刷新等一次性请求大量 key 的场景下非常实用。例如电商推荐系统中首页个性化加载:用户打开电商首页,推荐服务根据用户画像计算出数十个候选商品 ID,一次性向 ElastiCache 批量查询这些商品的缓存信息(商品标题、价格、图片 URL、促销标签等),通过 Pipeline内存预取可以大大降低加载速度。Valkey 9.0 在引擎层面利用 Pipeline 批量特性做了更激进的内存预取优化。具体流程如下:
- 命令解析:对所有 key 计算 hash → 定位 bucket → 发出 prefetch
- 内存预取:对key的hash table查找路径做交错预取
- 执行:CPU 真正执行
lookupKey时,数据已经从内存加载到 L1/L2 缓存
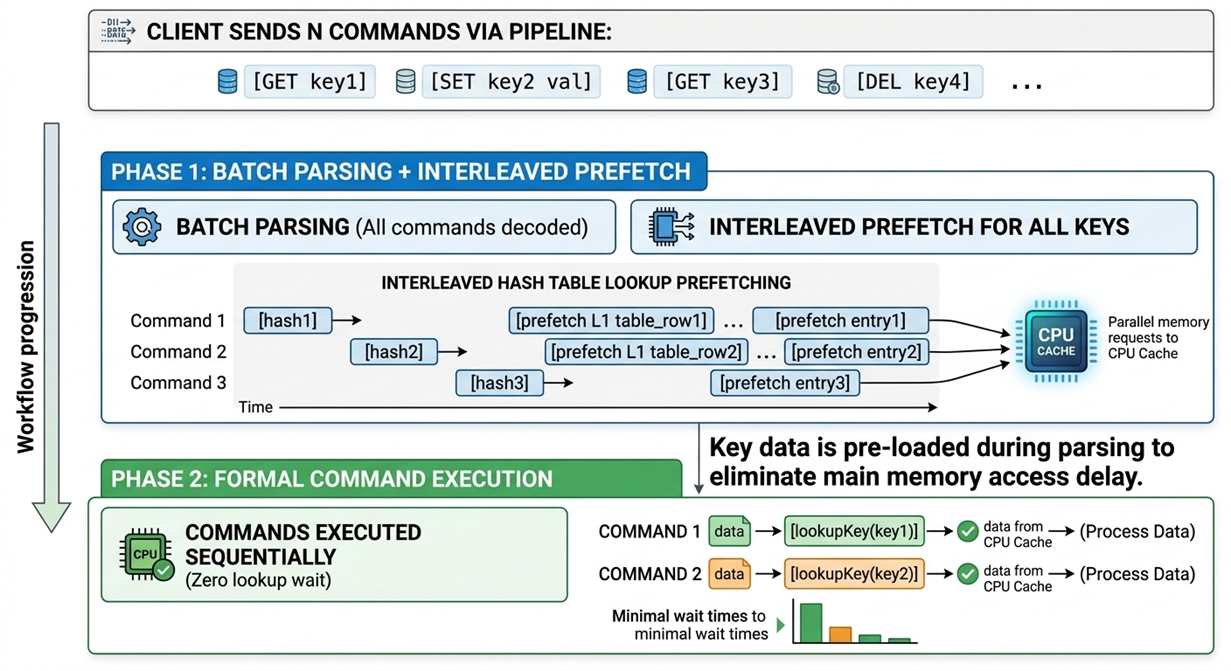
[图8:管道内存预取工作原理] |
在 Amazon ElastiCache 中,这项优化被描述为“引擎级流水线优化”:通过更快的命令解析、改进的内存预取和更高效的批量请求处理,为使用 Pipelining 的工作负载带来最高 40% 的吞吐量提升。从对比测试结果看,在批量读负载下相对 8.2 吞吐提升约 50–56%(测试环境:cluster mode, 3 分片 × 3 节点, cache.r7g.xlarge, TLS required, Multi-AZ;数据集:各 500 万 key, 128B value;负载:纯读 -t 8 -c 50, time=120s, pipeline 深度: {1, 10, 30, 50, 100})
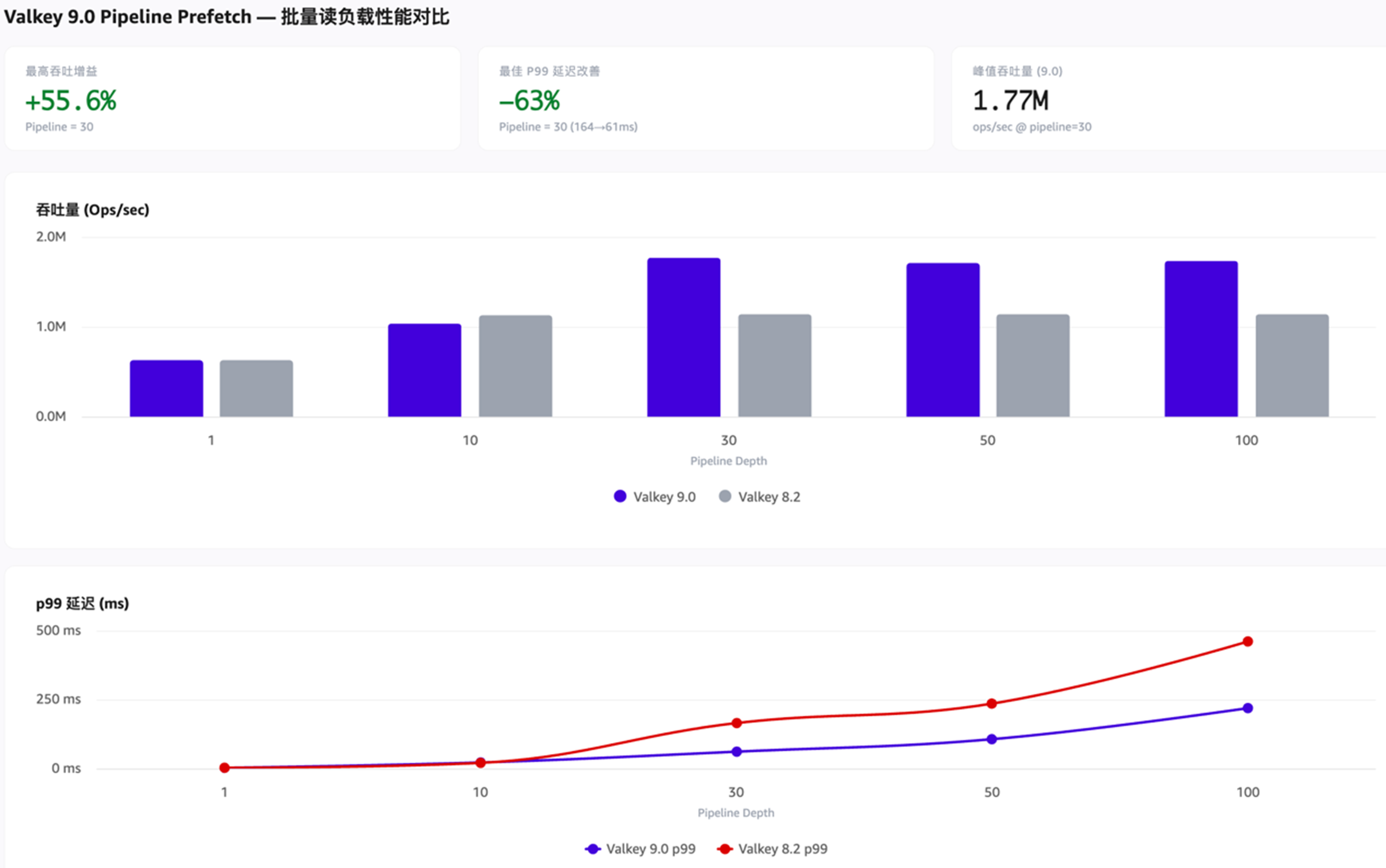
[图9:管道内存预取测试对比] |
4.3 SIMD 加速(Single Instruction, Multiple Data)
SIMD 是一种 CPU 并行计算指令集,核心思想是一条指令同时对多个数据执行相同操作。它最擅长的就是大量同构数据、相同操作、无数据依赖的场景。Valkey 9.0 引入了 SIMD 优化,主要用于两个场景:
- BITCOUNT 命令加速:BITCOUNT 命令用来计算字符串中被设为 1 的 bit 数量,通过SIMD并行计算,对大型的 bitmap数据类型,吞吐量可提升超过200%;
- HyperLogLog 计算加速:HyperLogLog 用于估算集合的基数,其核心操作是对大量 6-bit 寄存器做聚合计算。SIMD通过批量提取/并行计算等优化点,用于操作HyperLogLog 的PFCOUNT 和 PFMERGE命令的吞吐最高可以达到 200%的提升。
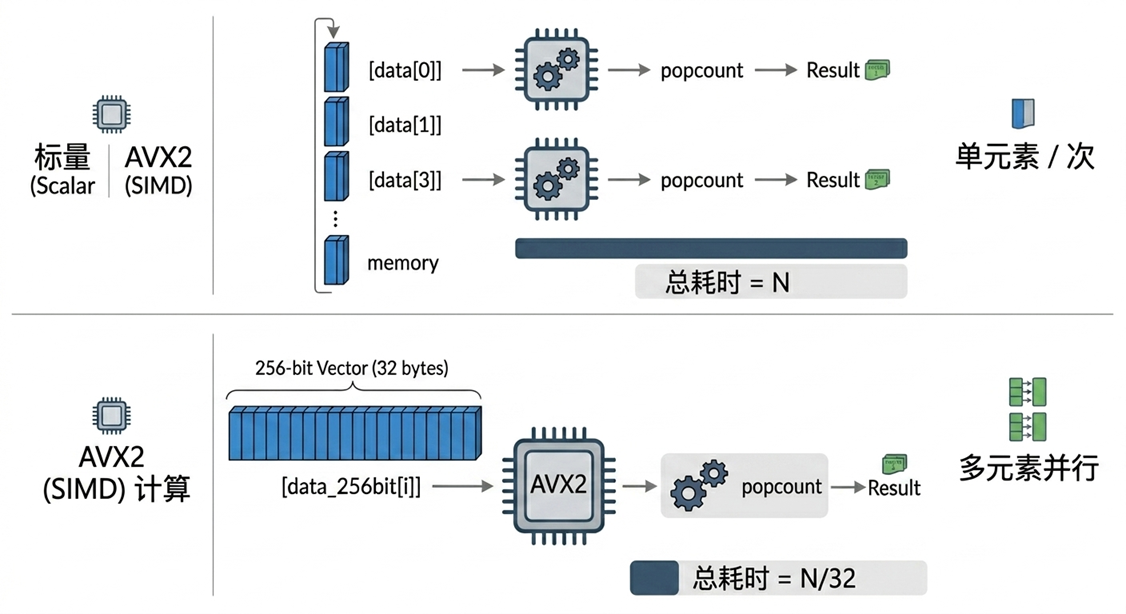
[图10:SIMD加速] |
Valkey 在编译时会检测 CPU 的能力,自动选择最优路径。这使得它在 AWS Graviton(ARM NEON)和 Intel/AMD(AVX2)上都能获得 SIMD 加速,无需用户手动配置。
五、数据结构与内存优化
5.1 Cache-Line 对齐的哈希表
一般来说,CPU 从主存加载数据时并不是按字节读取的,而是以固定大小的缓存行(Cache Line)为单位加载到 CPU 缓存中。现代硬件的 Cache Line 大小几乎都是 64 字节。如果相关数据能紧凑地放进同一个 64 字节块内,那么一次内存访问就能获取需要的信息,无需多次往返主内存。所以,对齐Cache-Line的哈希表的核心理念就是:把需要的数据塞进同一个 64 字节块中,让 CPU 一次性获取,将哈希查找从“追指针链”变为“扫描本地缓存”,从而大幅减少主内存访问延迟。
Valkey 8.0之前使用的是链式哈希表,查找一个key需要4+次访问,每次访问都可能跨越不同的 Cache Line,触发昂贵的主存读取。 8.1版本完全重写了哈希表,设计的核心就是让每个桶为64字节,从而精确匹配一个 Cache Line,一次内存加载就获得整个桶。
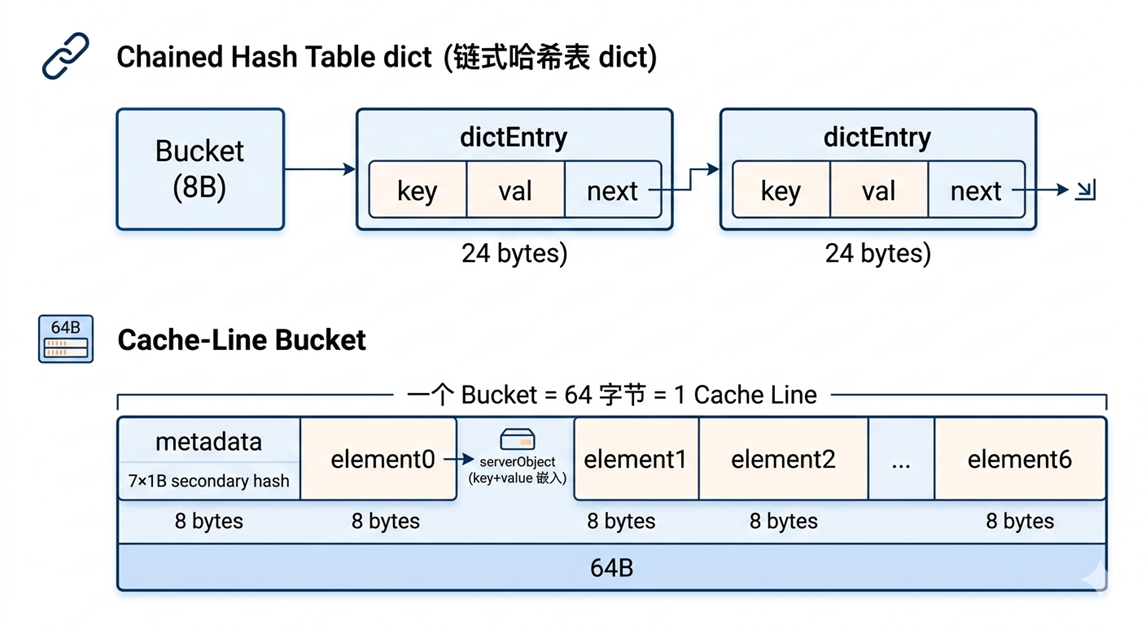
[图11:链式哈希表和Cache-Line桶的对比] |
在新哈希表的加持下,内存访问次数从4次变为2次,每 key 内存节省约20字节。比如一个电商平台在 ElastiCache 中缓存了 1 亿个用户 Session(每个 key 16B,value 16B)。旧哈希表下每个 key 约 56 字节开销,1 亿 key 的纯结构开销 ≈ 5.2 GB。升级到新哈希表后,每 key 开销降到 36 字节,总结构开销节省约 1.8 GB。这意味着实例可以从 r7g.xlarge 降级到 r7g.large,直接节省 50% 节点成本,且无需修改任何业务代码。
5.2 每槽字典(Per-Slot Dictionary )+ Fenwick Tree
集群模式下,16384 个 hash slot 需要维护 slot→key 的映射关系。旧方案中,每个 key 需要额外存储 16 字节的双向链表指针以保存映射关系。Valkey 8.0 后改为每个 slot 一个独立字典,彻底消除了这 16 字节。但拆分后又带来了新的问题:如何在 16384 个字典中快速完成全局操作(遍历、随机采样、淘汰)?答案是 Fenwick Tree。
Fenwick Tree,也叫 Binary Indexed Tree (BIT),由 Peter Fenwick 于 1994 年提出,是一种用于处理前缀和查询和单点更新的数据结构,可以做到O(log n)的时间复杂度。典型的应用场景有动态前缀和(数据频繁修改时求区间和),逆序对计数 (离散化后统计比当前元素小的已出现元素个数),区间频次统计等。比如ElastiCache 集群扩容的本质是将slot 重新分配:部分 slot 从老节点迁移到新节点。系统需要快速决定哪些 slot 迁过去能让各节点数据量均衡。Fenwick Tree 通过前缀和查询,快速算出任意 slot 区间的 key 总数,瞬间制定好迁移计划。
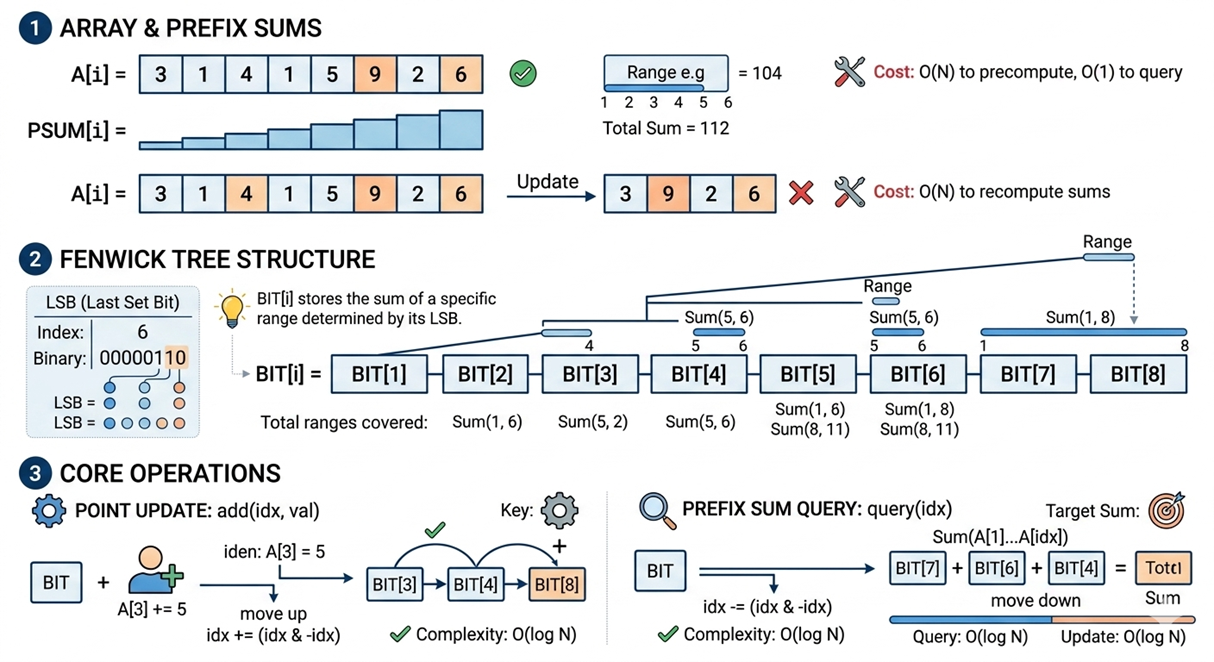
[图12:Fenwick Tree在Valkey中的使用] |
刚才已经说过,Valkey引入了每槽字典后带来了新的挑战:遍历时需要跳过空槽,随机淘汰时需要按 key 的数量加权随机选一个槽,等等。而这些操作的核心需求都可以抽象为两个原语:单点更新,前缀和查询。这正是Fenwick的用武之处!Valkey 维护了一棵大小为 16384 的 Fenwick Tree,BIT[slot] = 该 slot 中的 key 数量,单点更新 O(log 16384) 最多只需要 14 次加法。加权随机也演变成在树上做二分查找。总之,Fenwick Tree 在 Valkey 集群中扮演的角色是16384 个 每槽字典的索引,它用极低的内存和时间代价换取了优异的性能:
| 指标 | 值 |
| 内存开销 | 128K(16384 个 int64) |
| 更新延迟 | O(log 16384) ≈ 14 次加法,纳秒级 |
| 查询延迟 | O(log 16384),纳秒级 |
六、集群与分布式优化
6.1 Gossip 协议与大集群优化
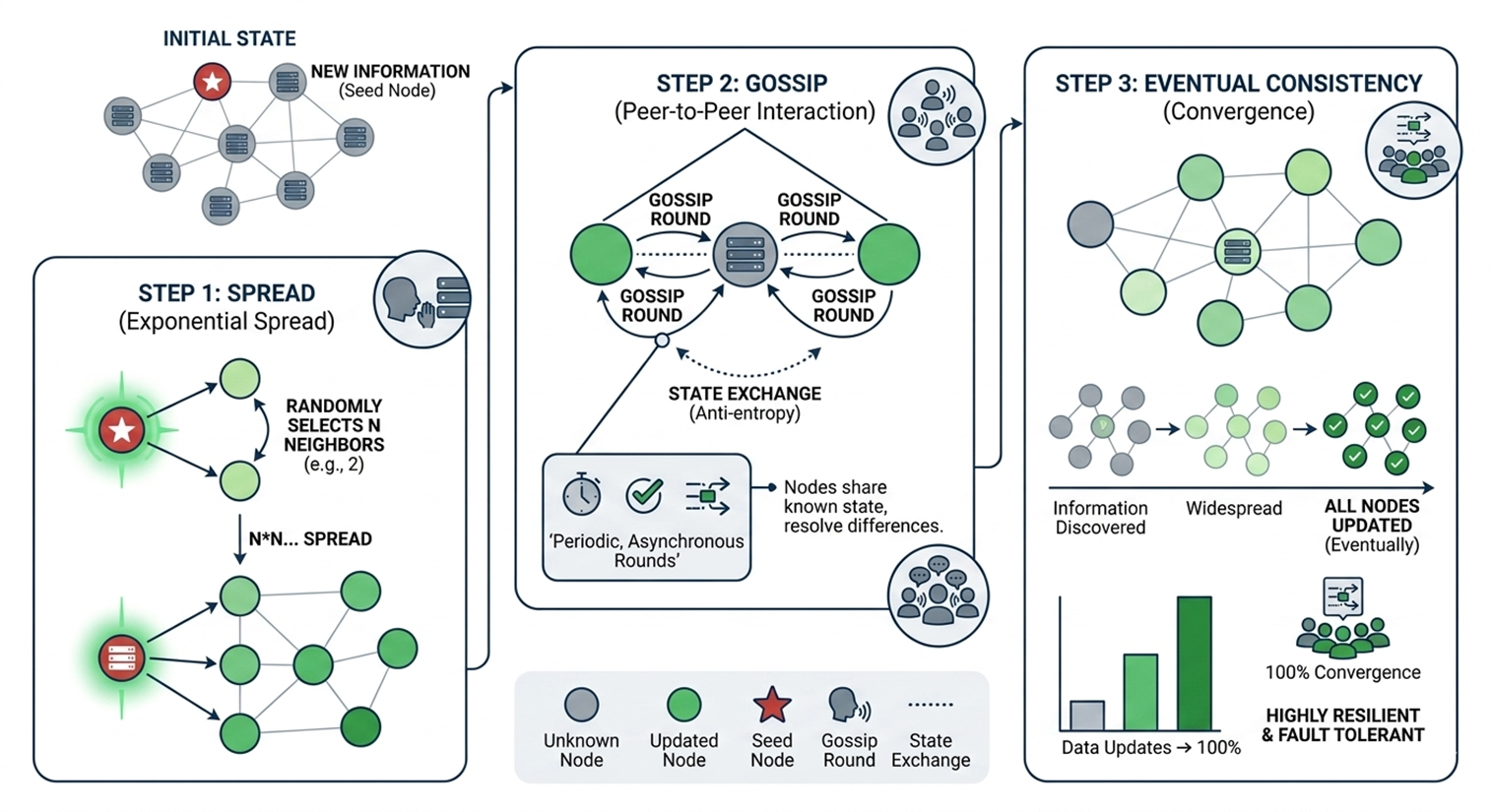
Gossip 协议也叫 Epidemic Protocol,俗称流言/传染协议,是一种去中心化的信息传播机制,灵感来源于流行病学中病毒传播的数学模型。它的工作方式很简单也非常有意思:每个节点周期性地随机选择几个邻居,把自己知道的信息告诉对方,就像传播八卦一样,每个人告诉几个朋友,几轮之后所有人都知道了。比如Grafana Loki 在集群模式下就是通过Gossip 发现成员的。
[图13:Gossip协议工作原理] |
在Valkey 集群中,Gossip 协议让所有节点保持对集群拓扑的最终一致认知:
- 每秒随机选几个节点发送
PING,对方回复PONG - PING/PONG 消息中携带自己已知的部分节点状态
- 通过多轮交换,所有节点最终达成一致(谁负责哪些 slot、谁挂了)
Gossip 协议用“每人随机告诉几个人”的八卦传播方式,在 O(log N) 轮内让整个分布式集群达成信息一致,简单、健壮、可扩展,且保证最终一致性。
6.2 原子 Slot 迁移
Valkey 集群中的key是以hash的方式分配到不同节点的,每个节点负责一部分 slot。当集群需要扩缩容时,就需要把 slot 从一个节点迁移到另一个节点。Key-by-Key 迁移方案需要循环批量的将key发送到目标节点,缺点也很明显:迁移慢,客户端重定向,大key阻塞等等。
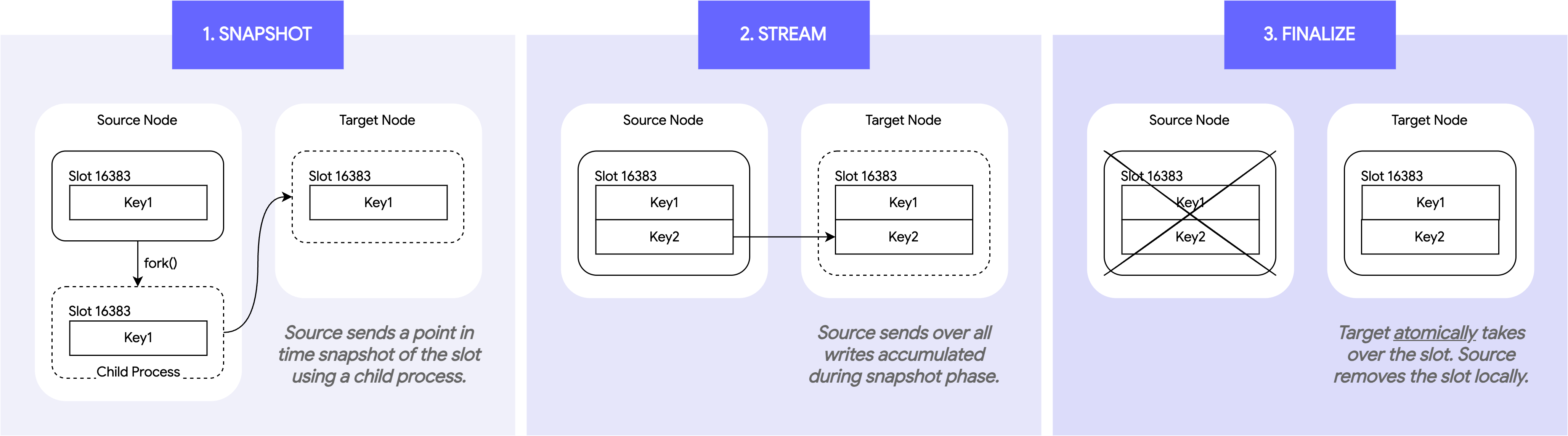
Valkey 9.0提供的原子Slot迁移的核心思想是:像复制(replication)一样迁移 slot,最后原子切换所有权。它的过程主要分3个阶段:
- 快照阶段:源节点首先将所有迁移槽中的即时数据快照发送到目标节点。快照通过子进程异步完成,允许父进程继续处理请求。快照格式化为可以逐字消费的命令流。
- 流传输阶段:源节点会持续跟踪所有对迁移槽的新变更。一旦快照完成,源节点将所有增量变更流传输给目标。
- 最终化阶段:一旦变更流发送到目标,源节点会短暂暂停变更。只有目标完全处理完后,才会获得迁移槽的所有权并向集群广播所有权。源节点得知后删除旧槽,并将暂停的客户端重定向到目标节点。
[图14:原子Slot迁移] |
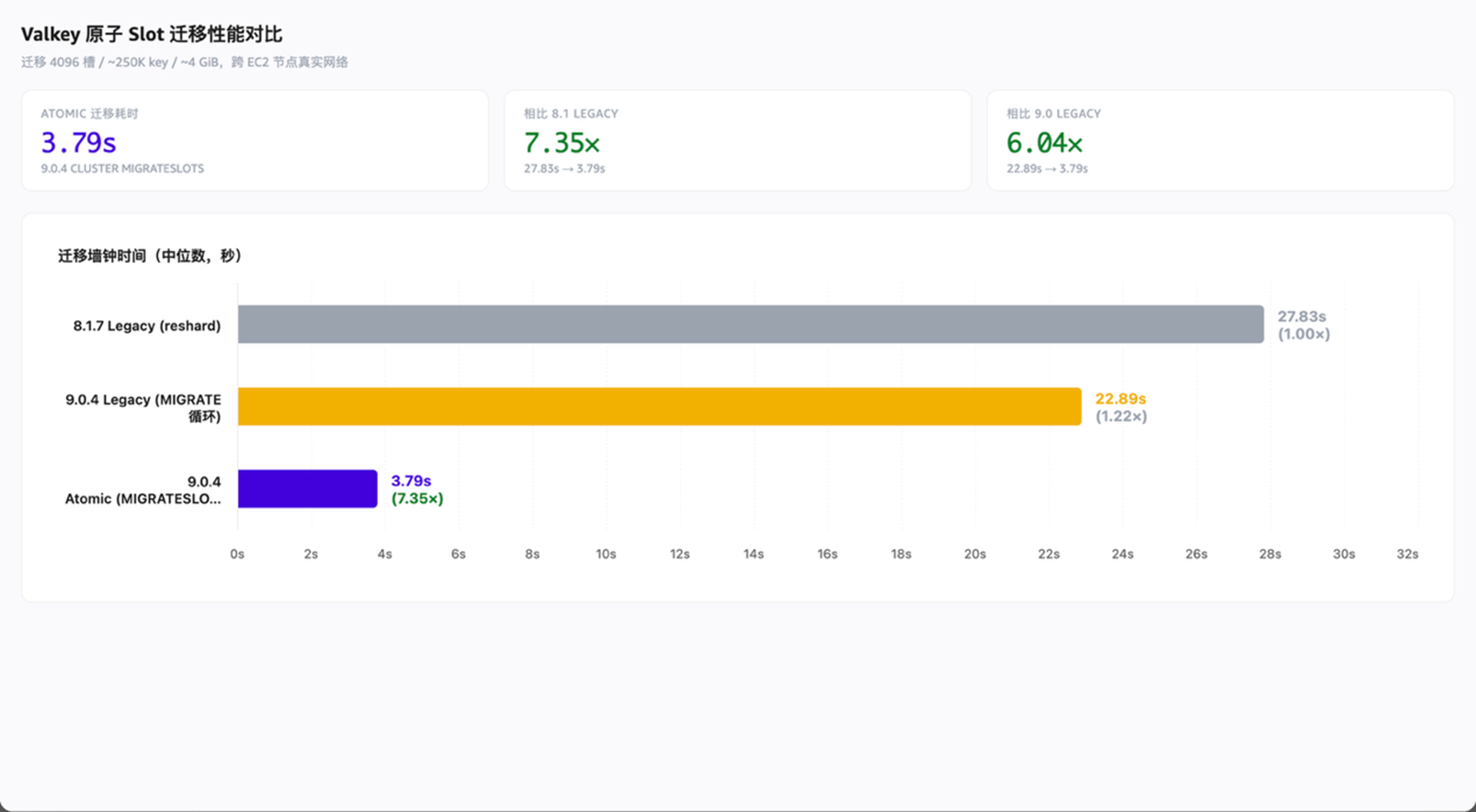
原子slot迁移完全透明,客户端无感知,内存平稳,可消除迁移期间的性能抖动。下图是在2台r7g.2xlarge实例上自建Valkey集群进行的测试,数据规模100万key,迁移4096个槽,约4G数据。可以看到,原子slot迁移的速度有7倍多的提升。
[图15:原子slot迁移速度测试] |
七、搜索引擎加速(Valkey-Search)
7.1 HNSW 向量搜索
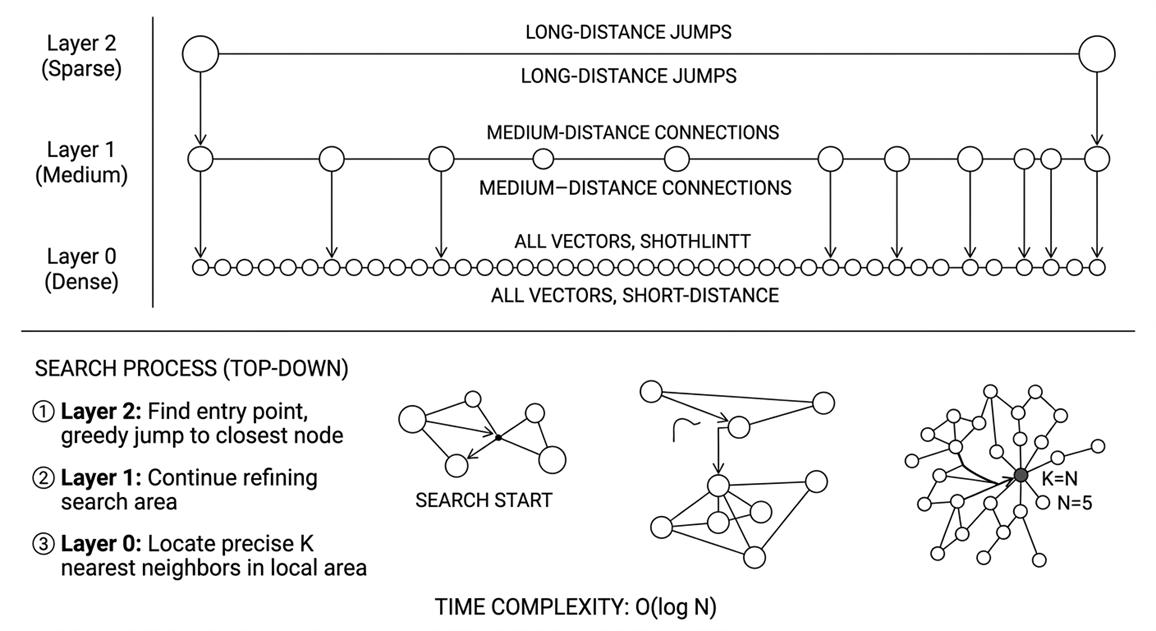
HNSW (Hierarchical Navigable Small World)是一种用于“高维向量近似最近邻搜索”(ANN)的图索引算法,广泛应用于 AI/ML 场景中的向量数据库。比如在广告素材管理场景下,运营人员需要从数百万张素材图片中快速找到与当前图片类似的素材。首先,每张素材通过 Embedding 模型转换为多维向量存入。查询时,用户上传的目标图片生成向量,HNSW搜索会在毫秒级返回 Top-K 最相似素材,而同样规模的暴力搜索需要好几秒才能完成。Valkey-Search 模块使用了 HNSW 作为其向量搜索的核心索引结构。算法的核心思想是将数据点组织成一个多层级跳跃的图结构,上层稀疏(少量高速公路节点),下层稠密(所有数据点),搜索时从上层快速定位大致区域,在逐层下降做精细搜索。
其搜索过程大致可以理解为:从顶层入口点出发,贪心方式跳到离目标最近的节点,如果当前层无法再靠近就下降到下一层,重复步骤直到底层,并做局部精确搜索。我举个简单的例子你能明白:有一年我去爬四姑娘雪山,目的地是到山脚下的大本营。从北京达到大峰大本营的路程如下:
- Layer 3:北京 → 成都(大城市直飞)
- Layer 2:成都 → 阿坝州小金县(省级交通)
- Layer 1:小金县 → 四姑娘山镇(地级路网)
- Layer 0:四姑娘山镇 → 登山大本营(徒步山路)
[图16:HNSW工作原理] |
下图展示了HNSW的测试结果,可以看到,其QPS比FLAT高一个数量级,EF 越大,探索的图节点越多,召回率越高。(测试环境: ElastiCache 9.0,cluster mode,3 分片 × r7g.8xlarge,32并发20s,数据集:合成聚类向量,N=1,000,000 条,D=768,FLOAT32)
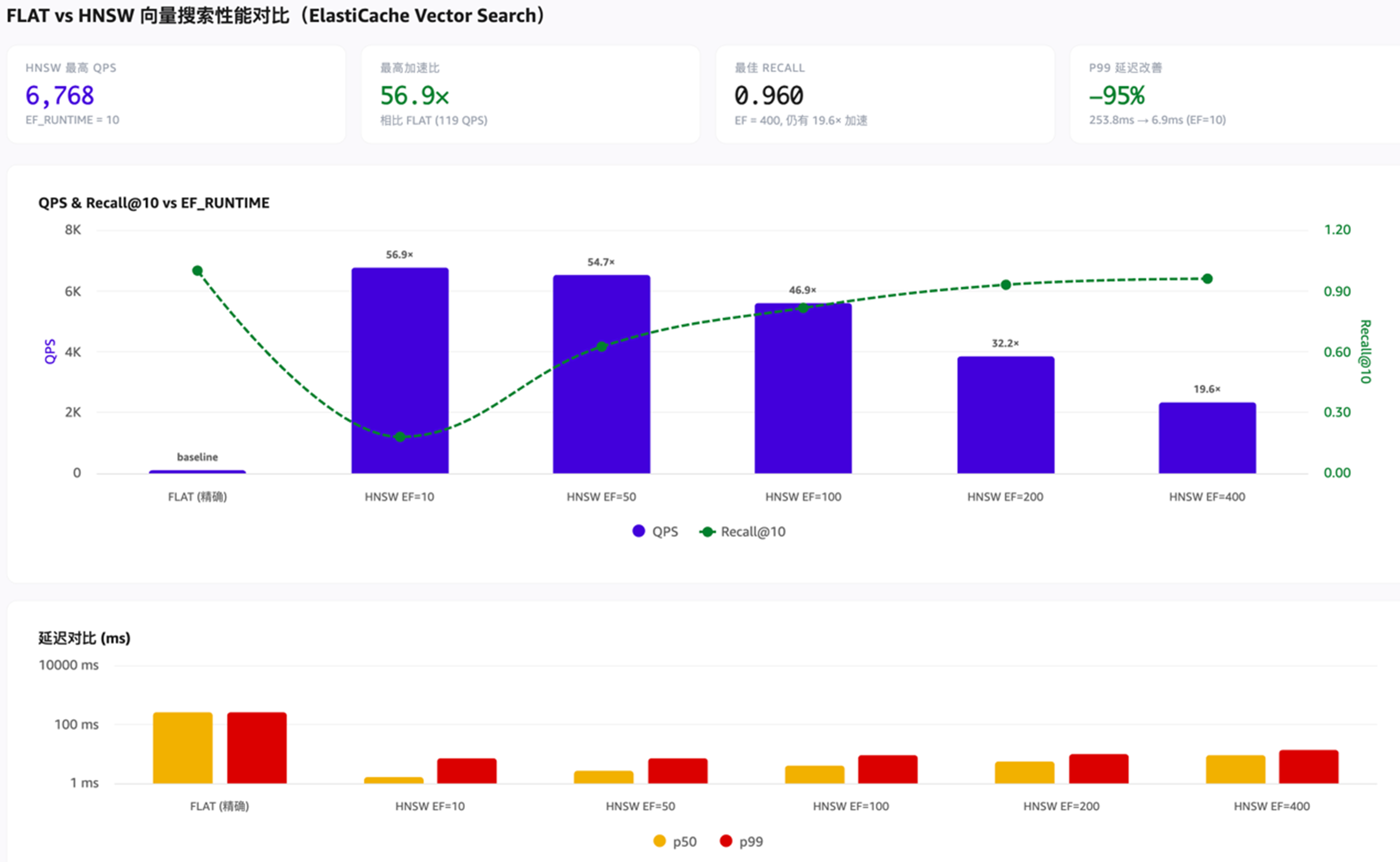
[图17:HNSW搜索测试对比] |
Valkey-Search 在 HNSW 上实现了毫秒级延迟,数十亿向量规模和99%+ 的召回率。通过 ElastiCache,用户可以直接使用 Valkey-Search 模块进行向量检索,作为 RAG、推荐系统、语义搜索的向量存储,无需额外部署和运维专用向量数据库,大幅降低架构复杂度。
7.2 混合查询优化
混合查询是指在一次搜索中同时结合向量相似度搜索和结构化过滤条件的搜索方法。相比单一检索方式,混合查询在“用户口语化表达 + 文档专业术语”的 场景中优势明显。例如:”找出价格在 100-500 之间、品牌是 Apple、且与用户查询语义最相似的 Top 10 产品”。这会同时涉及到:向量搜索(HNSW 近似最近邻),Tag过滤(brand=Apple),范围查询(100 ≤ price ≤ 500)和关键词/模糊/前缀匹配。一般的混合查询要么是先过滤后搜索,要么是先搜索后过滤,但都会面临召回率下降或性能退化的问题。
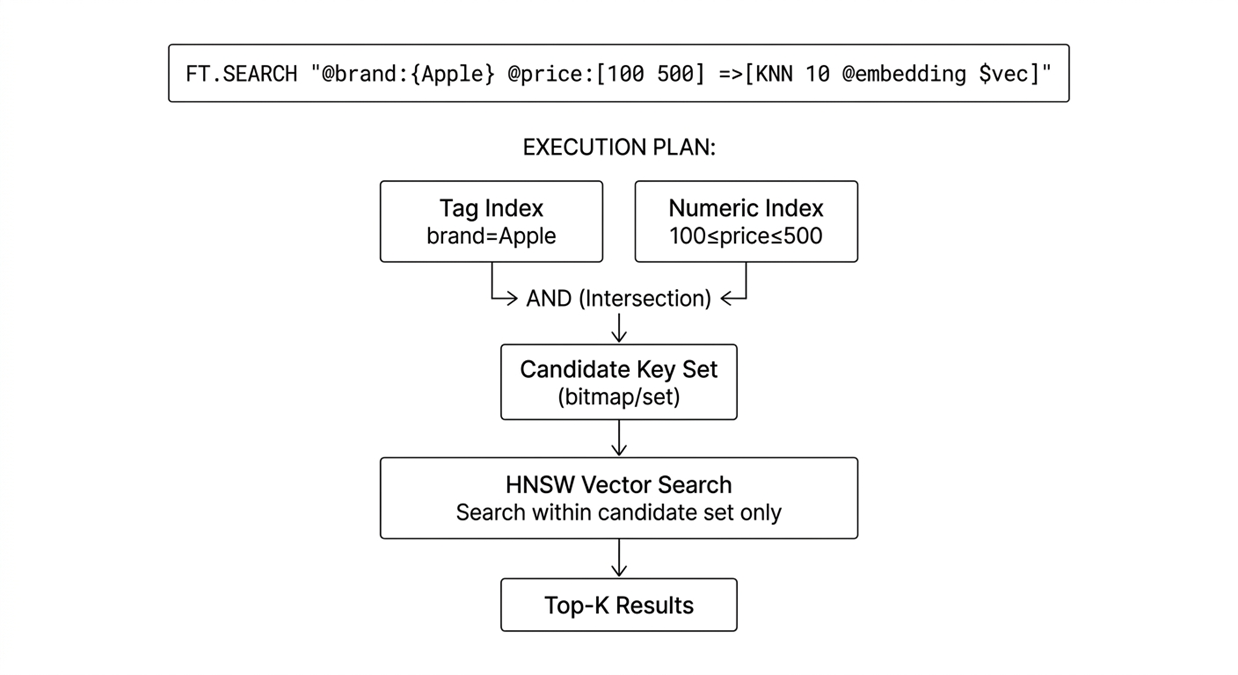
[图18:Valkey-Search中的混合查询优化] |
Valkey-Search 采用了智能混合执行的策略,通过多种二级索引(Tag/Numeric/Full-text)高效缩小候选集,与向量搜索协同,再通过多线程并行执行,可以在毫秒级延迟下返回结果。从官方文档中可以得知,Tag精确匹配的时间复杂度可以达到O(1) ~ O(N),范围和文本搜索可以达到O(log N)。ElastiCache 9.0已提供了混合查询能力。
八、总结
以上就是我们盘点的Valkey中的性能优化技术,总结到下面的表格中。Valkey 的性能故事不是单一的”银弹”,而是从网络到 CPU、从内存到集群的全栈系统级优化。
| 层面 | 技术 | 核心原理 | 效果 |
| 网络/IO | 多线程 I/O | I/O 卸载,主线程专注执行 | 3x 吞吐 |
| 网络/IO | RDMA | 内核旁路 + 零拷贝 | 2x QPS |
| 网络/IO | Multipath TCP | 多路径并行 | -25% 延迟 |
| 网络/IO | Zero-Copy | 避免内部 memcpy | +20% 吞吐 |
| CPU/执行 | Memory Access Amortization | 交错预取 | +50% |
| CPU/执行 | Pipeline Prefetch | Pipeline batch 预取 | +40% 吞吐 |
| CPU/执行 | SIMD | 向量化计算 | 2~3x |
| 数据/内存 | 新哈希表 | Cache-line 对齐 | -20B/key |
| 数据/内存 | Per-Slot Dict + Fenwick | 去指针化 + 前缀和索引 | -20% 内存 |
| 集群 | Gossip 优化 | 轻量头 + 去重 + 排序 | 2000 节点 |
| 集群 | 原子 Slot 迁移 | 整 slot 原子迁移 | 零中断 |
| 搜索 | HNSW + SIMD | 近似最近邻 + 向量化 | ms 级 |
这些性能黑科技并不只是文中的理论,它们已经以托管服务的形式在 Amazon ElastiCache 中落地。ElastiCache 为用户屏蔽了底层配置调优、集群运维的复杂性,让开发者专注于业务逻辑,同时享受 Valkey 带来的极致性能。如果你想亲身体验这些优化带来的提升,可以通过 Amazon ElastiCache 控制台快速创建一个 Valkey 集群。
➡️ 下一步行动:
相关产品:
- Amazon ElastiCache — 无服务器缓存
- Amazon EC2 — 安全且可调整大小的计算容量
相关文章:
- 使用Amazon SageMaker Hyperpod Cluster部署whisper模型
- 自己的工具自己控:MCP Server、Amazon Bedrock AgentCore、Quick Suite集成指南
- 给 Openclaw瘦身-利用Nova MME 和 S3 Vector实现Skill按需召回
- 基于 Amazon Bedrock AgentCore Runtime 部署 Apache Doris MCP Server为 Quick Suite 等 AI 客户端提供原生数据分析能力
- 从手动到智能:用 Kiro CLI + OpenSearch MCP 让每个人都成为 OpenSearch 专家
九、参考资料
- Unlock 1M RPS Part 1 – I/O Threads
- Unlock 1M RPS Part 2 – Memory Access Amortization
- A New Hash Table
- Storing More with Less – Memory Efficiency
- Introducing Valkey 9.0
- Scaling to 1 Billion RPS
- Introducing Valkey Search
- RDMA Support
- Valkey Pipelining
- Year One of Valkey: Open-Source Innovations and ElastiCache version 8.1 for Valkey
- Announcing Valkey 9.0 for Amazon ElastiCache
- Resharding, Reimagined: Introducing Atomic Slot Migration
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
