亚马逊AWS官方博客
短剧视频字幕位置自动识别:OpenCV + Amazon Nova 2 Lite 混合方案
摘要:本文介绍了一种短剧视频字幕位置自动识别方案,通过 OpenCV 图像处理 + Amazon Nova 2 Lite 视觉大模型 的混合方法,在 30 个测试视频(覆盖 15 种语言)上达到 83% 准确率(偏差 ≤5%)。
目录
1. 问题背景
在视频翻译流程中,字幕擦除需要先知道字幕在画面中的垂直位置范围(如 0.68,0.82 表示字幕在画面 68%~82% 处)。人工逐个标注费时费力,尤其面对几十上百个多语言视频时。
我们在短剧视频翻译 PoC 中,探索了自动化字幕位置识别方案,最终通过 OpenCV 图像处理 + Amazon Nova 2 Lite 视觉大模型 的混合方案,在 30 个测试视频上达到了 83% 的准确率(偏差 ≤5%)。
本文记录完整的思考过程、方案迭代和测试数据。完整代码已开源:aws-samples/sample-for-video-subtitle-detection-via-nova-2-lite。
2. 前提条件
本方案部署在 AWS 云上,使用 Amazon EC2 运行 OpenCV 和 FFmpeg 处理,通过 Amazon Bedrock 调用 Amazon Nova 2 Lite 模型。
环境配置
- 一个 AWS 账户,并已在 Amazon Bedrock 控制台 开通 Amazon Nova 2 Lite 模型访问权限
- 一台 Amazon EC2 实例(推荐 m8g.large 或同等配置),安装以下软件:
- Python 3.12+
- OpenCV:pip install opencv-python boto3
- FFmpeg:用于视频抽帧(Ubuntu: sudo apt install ffmpeg,Amazon Linux: sudo yum install ffmpeg)
- IAM 角色需附加到 EC2 实例,并具备 bedrock:InvokeModel 权限,最小权限策略示例:
完整的环境搭建和使用步骤请参考开源仓库的 README:aws-samples/sample-for-video-subtitle-detection-via-nova-2-lite。
3. 问题分析:短剧字幕的特点
通过观察大量短剧视频帧,我们总结出字幕的几个特点:
有利于检测字幕的特点: – 对白字幕通常在画面下半部分(约 55%~85%) – 字幕文字通常是白色或黄色,与背景有对比度 – 字幕行横跨画面中央,宽度通常超过 25%
增加检测难度的因素: – 画面底部有 品牌 logo 和推广条(彩色文字,约 85%~97%) – 顶部有片名/章节标题 – 部分帧是 APP UI 截图,大量非字幕文字 – 有些帧恰好没有对白(过场画面) – 19 种语言的字幕颜色、字体、位置各不相同
核心挑战:如何区分对白字幕和其他文字元素(标题、推广条、水印)。
下图展示了短剧视频帧的典型结构,蓝色虚线标注了对白字幕的实际位置范围:
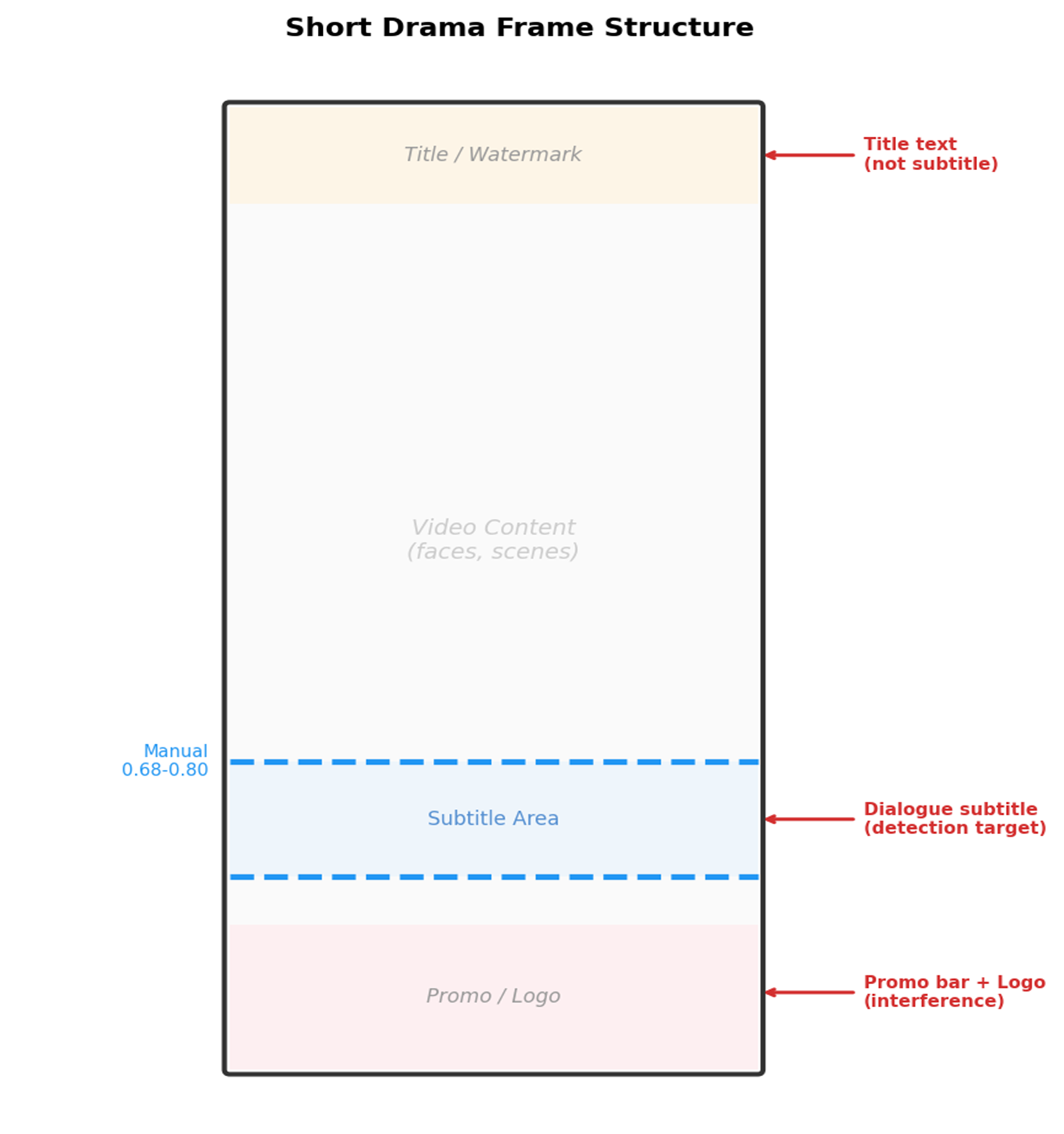
[图1:短剧视频帧结构示意图] |
4. 方案迭代过程
4.1 早期探索:从 30% 到 53%
我们先后尝试了四种方案,逐步发现 OpenCV 和 Nova 各自的优劣势:
第一版:纯 OpenCV(准确率 30%)
在画面 ROI(Region of Interest,感兴趣区域)55%~85% 范围内,通过白色/黄色阈值检测 + 形态学膨胀 + 轮廓过滤来定位字幕行。
ROI:指图像中需要重点分析的区域。这里限定在画面垂直方向 55%~85%,排除顶部标题和底部推广条。
问题:上边界经常偏低(误检衣服花边、地板反光等亮色区域),下边界偏高(推广条白色文字被误检),7 个视频完全漏检。
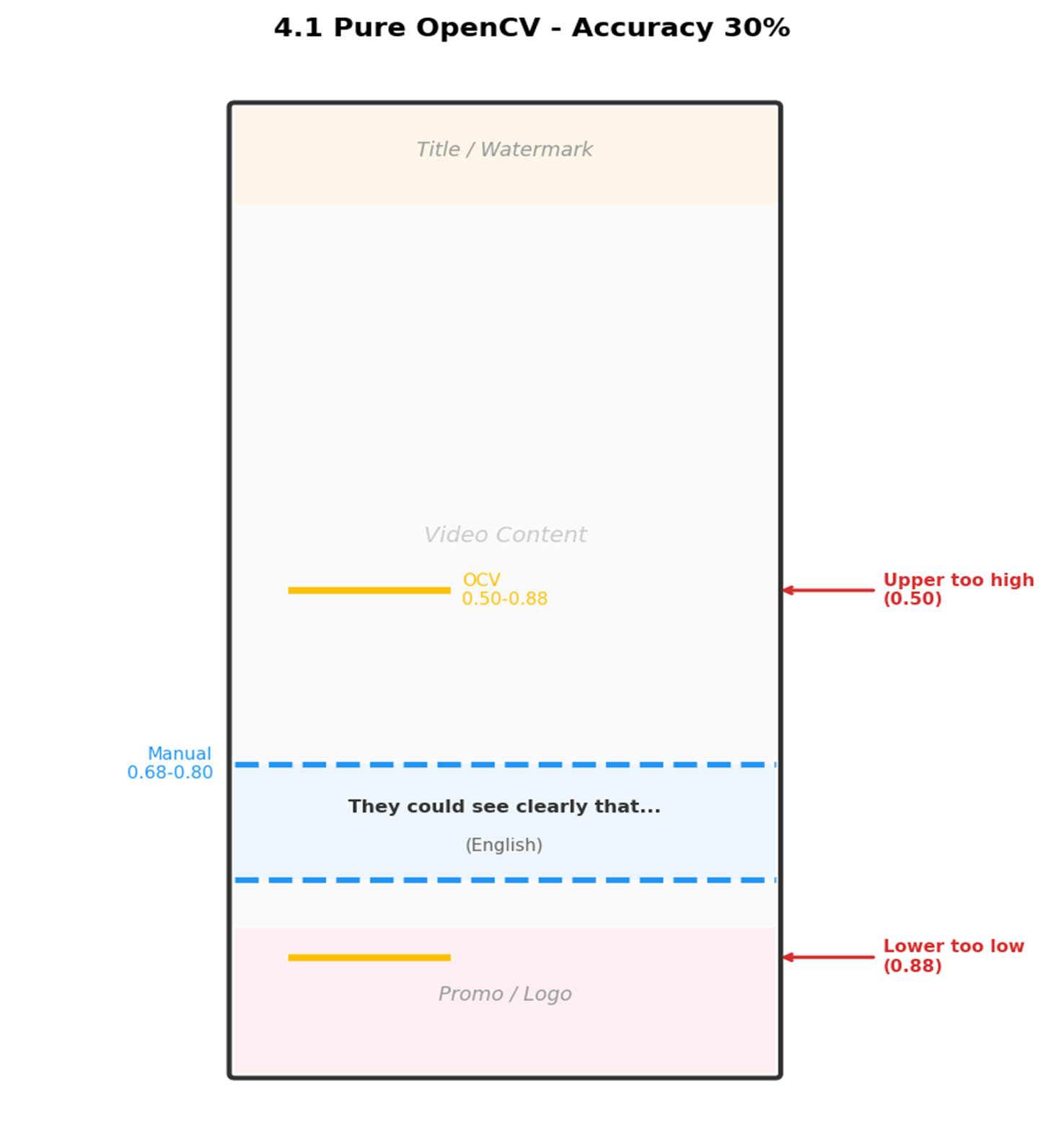
[图2:4.1 OpenCV 检测示意图] |
第二版:纯 Nova 2 Lite(准确率 30%)
改用视觉大模型。直接让 Nova 返回百分比效果不好,改用 bounding box 检测格式(0-1000 坐标空间)后效果显著提升:
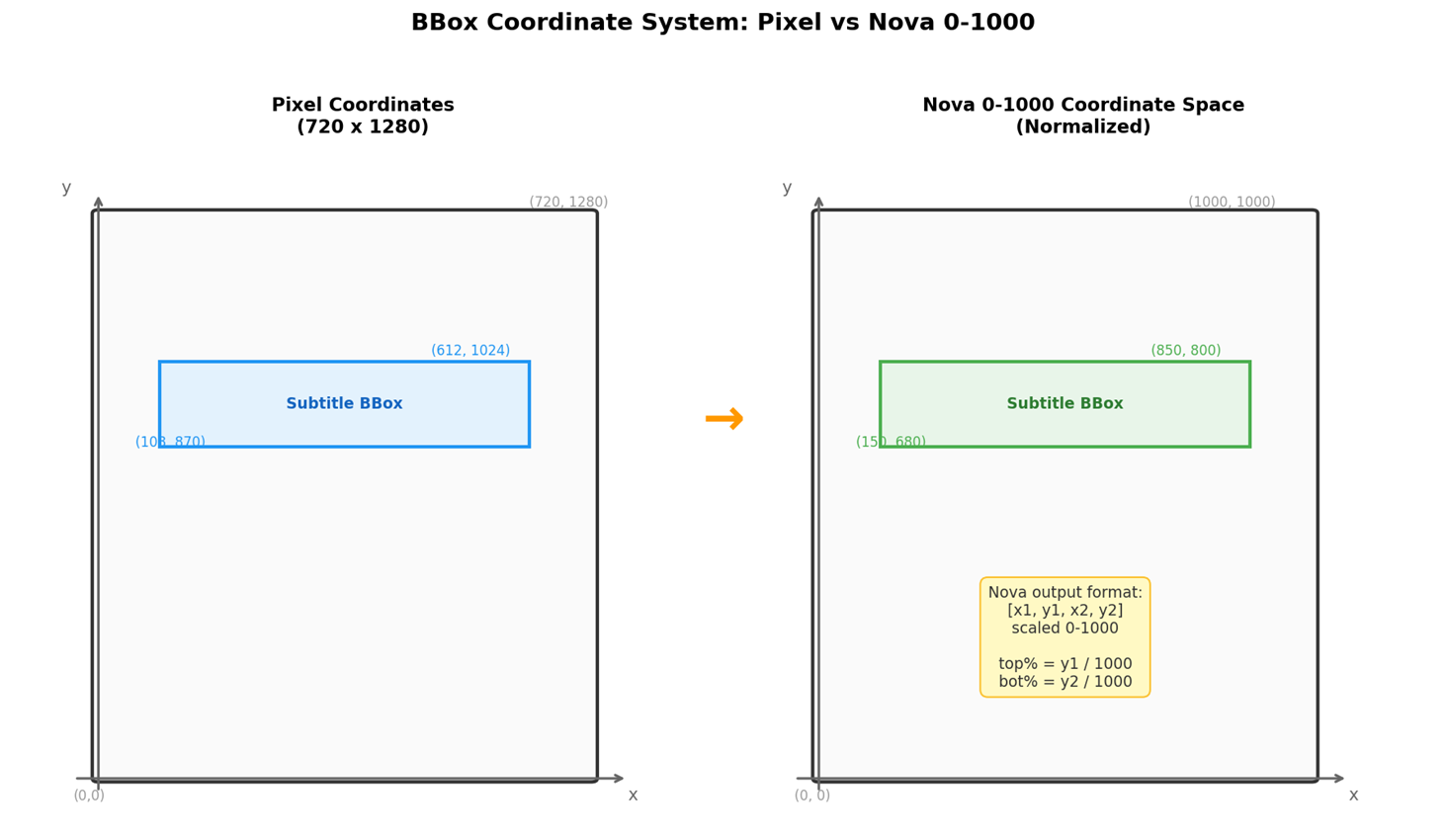
[图3:BBox 坐标系说明] |
发送给 Nova 2 Lite 的提示词(Prompt):
优势:上边界非常准确(偏差 ≤3%)。问题:下边界经常到 0.90+,把推广条也框进去了。
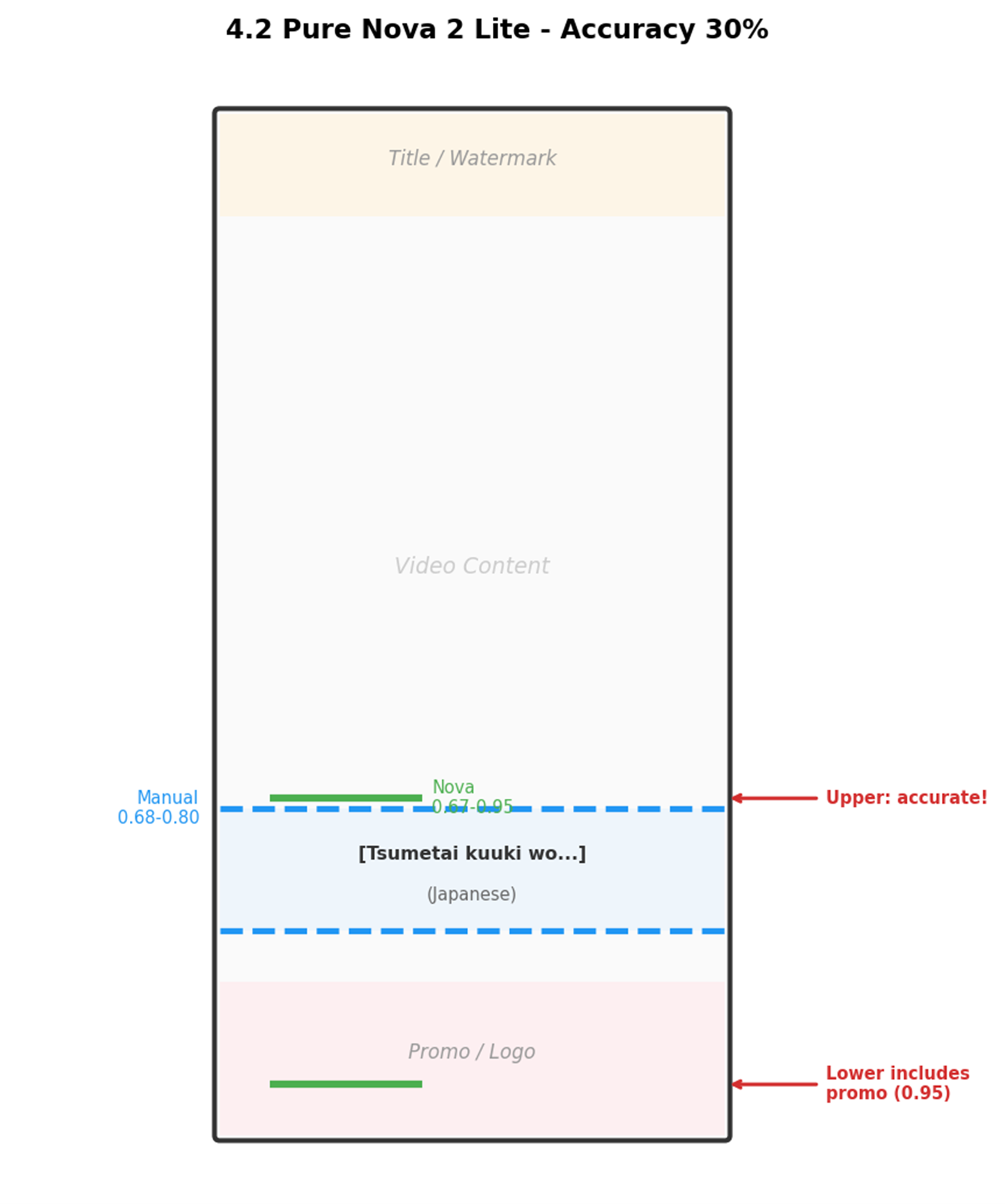
[图4:4.2 Nova bbox 检测示意图] |
第三版:Nova 分类 + OpenCV 检测(准确率 56%)
先用 Nova 判断每帧有无字幕,过滤后再用 OpenCV 检测。但瓶颈在于 OpenCV 本身——Nova 过滤掉的帧本来 OpenCV 也检测不到,过滤没有带来额外收益。
第四版:OpenCV + Nova 取交集(准确率 53%)
关键发现:Nova 上边界准,OpenCV 下边界紧,取交集互补:top = max(ocv_top, nova_top), bot = min(ocv_bot, nova_bot)。
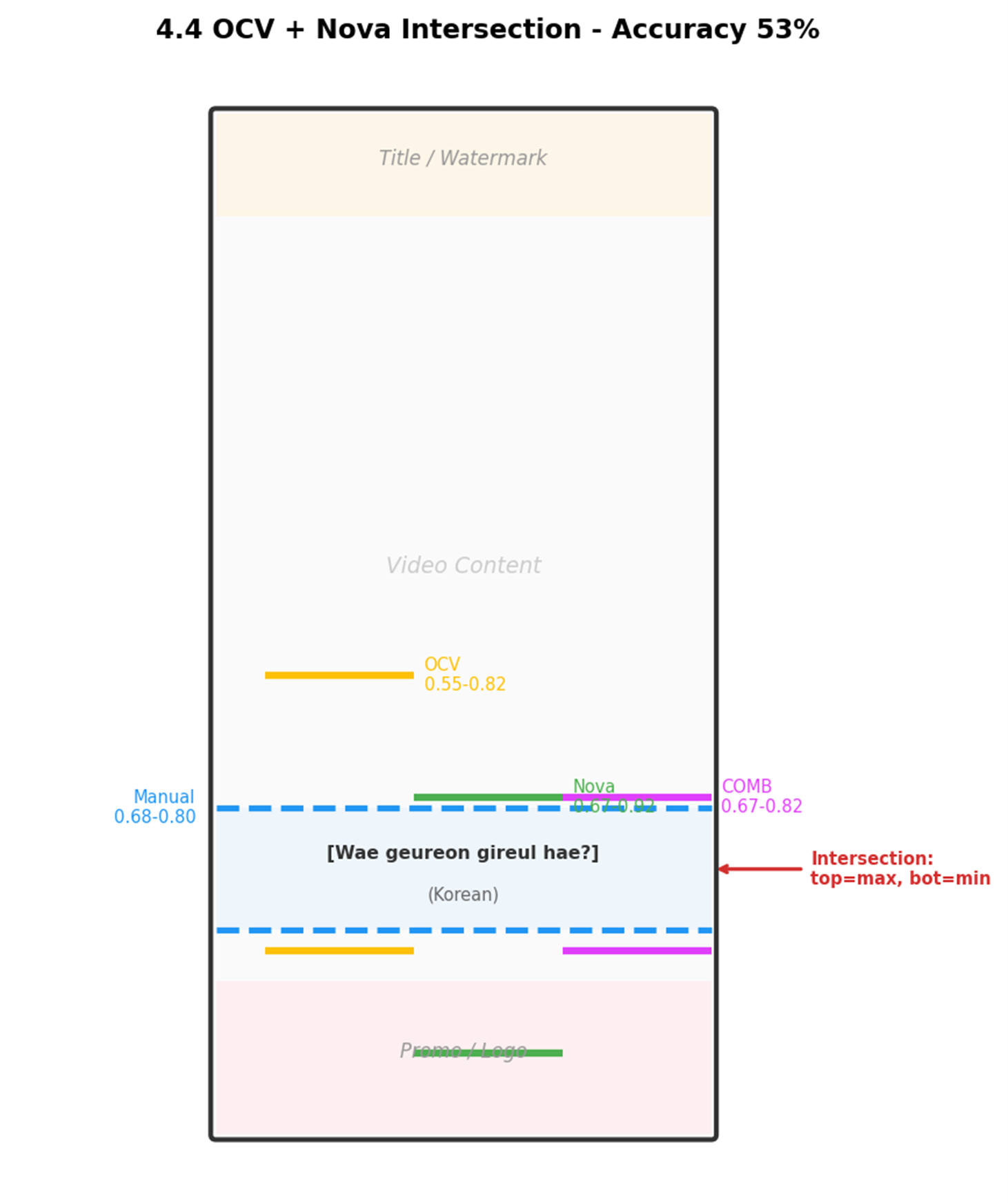
[图5:4.4 取交集示意图] |
早期探索的核心教训:单一方法不够——OpenCV 擅长精确定位但容易误检,Nova 擅长语义理解但位置不够精确。取交集是正确方向,但仍需进一步优化。
4.2 第五版:智能抽帧 + 结合 + 下边界封顶(准确率 76%→80%)
在第四版基础上加入三个优化:
优化 1:智能抽帧
之前固定抽 5 帧(10%/30%/50%/70%/90%),很多帧恰好没有字幕。改为: – 从 5% 开始,每隔 5% 抽一帧 – 用 OpenCV 快速判断该帧是否有字幕 – 没有字幕则跳过,继续抽下一帧 – 直到收集到 5 帧有字幕的帧为止
下图展示了智能抽帧的工作流程:
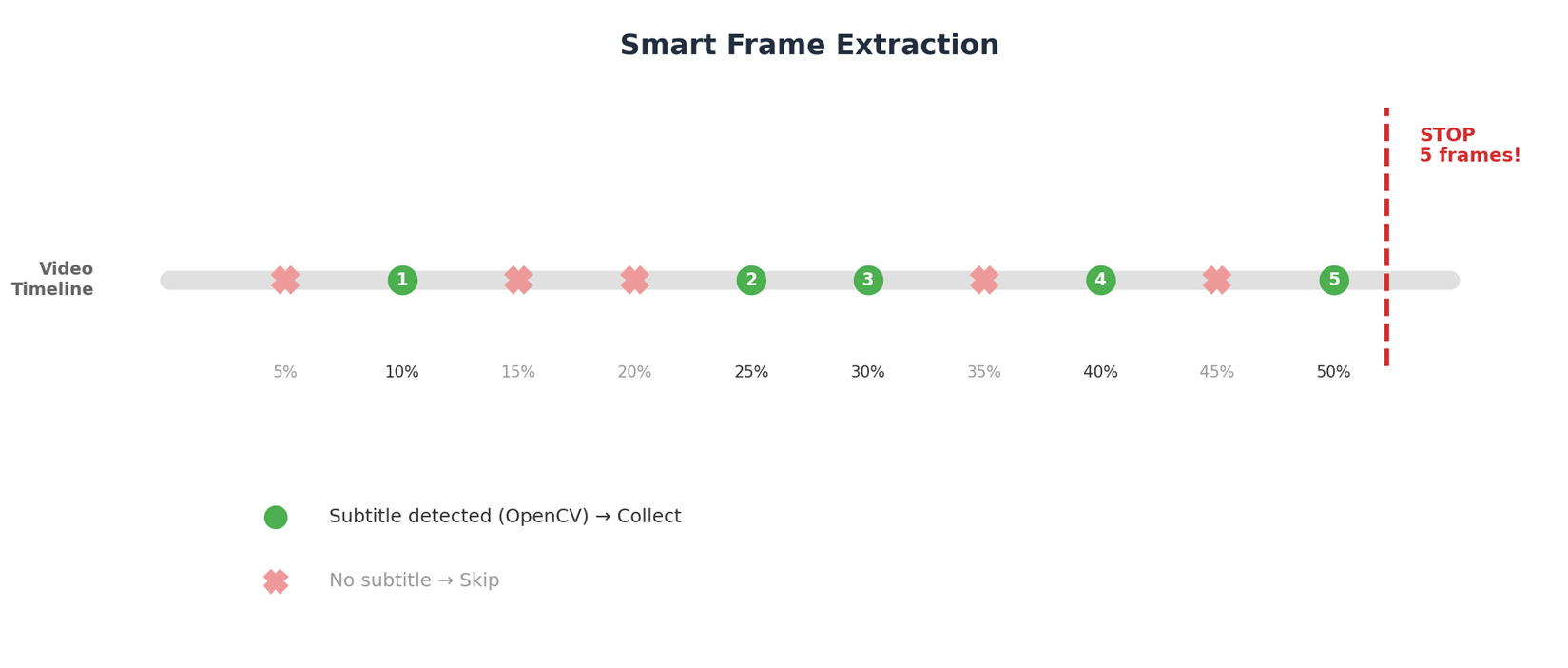
[图6:智能抽帧流程] |
这样确保每个视频都有足够的有效帧用于检测。
优化 2:下边界封顶 0.85
通过观察发现,对白字幕几乎不会出现在 85% 以下。85% 以下的检测结果基本都是推广条。直接将下边界 cap 在 0.85。
优化 3:聚合策略
- 上边界:取所有帧检测结果的最小值 – 2%(确保覆盖最高的字幕)
- 下边界:取所有帧检测结果的最大值 + 2%(确保覆盖最低的字幕),但不超过 0.85
测试结果:OpenCV 单独 40%,Nova 全帧 63%,两者结合达到 80%。
下图为德语视频帧示例,智能抽帧 + 下边界封顶后,三种方法的检测结果都更加精准:
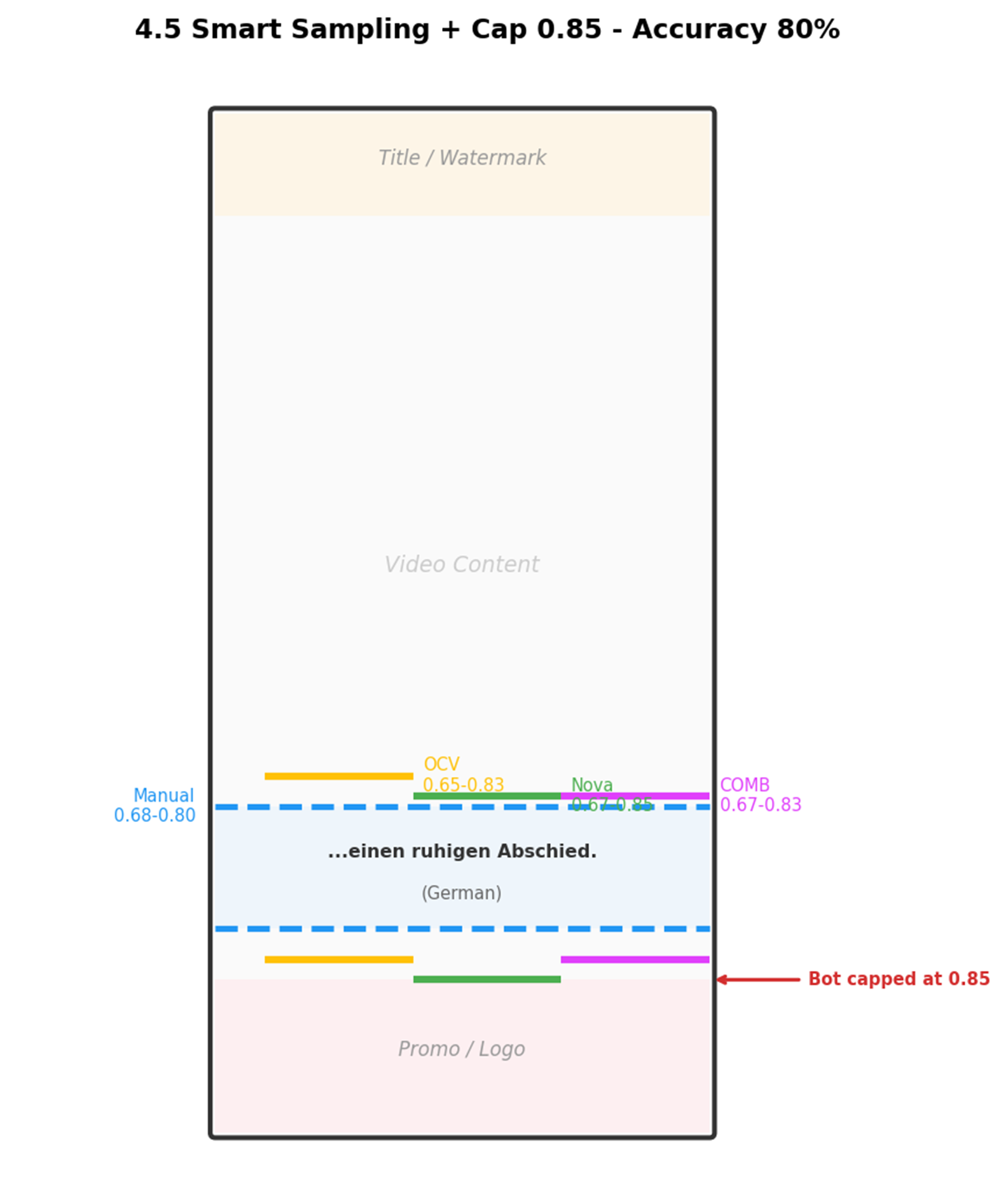
[图7:4.5 智能抽帧+封顶示意图] |
4.3 第六版:裁剪字幕区域再检测(准确率 83%)
第五版中 Nova 的主要问题是下边界偏大——把底部推广条(logo + 彩色标题文字)也框进去了。
关键洞察:如果把画面裁剪到只剩 50%~85% 的区域再给 Nova 检测,推广条和顶部标题都不在画面里了,Nova 就不会被干扰。
下图展示了裁剪 + 坐标映射的完整流程——这是本方案最关键的优化:
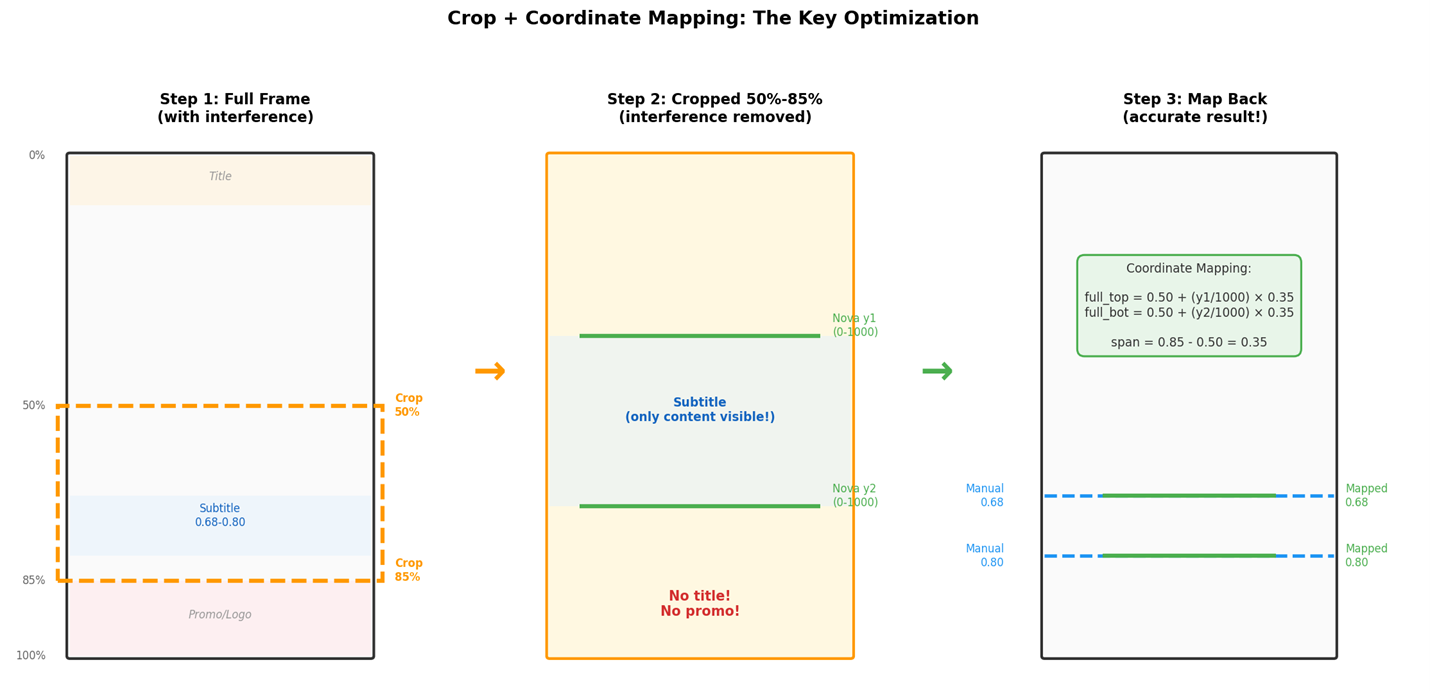
[图8:裁剪+坐标映射流程] |
坐标映射:Nova 返回的是裁剪图片内的 0-1000 坐标,需要映射回全帧:
效果验证:以之前全帧 Nova 完全漏检的 日语_08_90.jpg 为例,裁剪后 Nova 成功检测到字幕位置 0.70-0.78(手动标注 0.68-0.83),因为裁剪后画面中只有对白字幕,没有推广条干扰。
最终结合方式:OpenCV 检测 + 裁剪后 Nova bbox 检测,取交集:
我们还尝试了用 Nova 裁剪分类来做智能抽帧(替代 OpenCV 抽帧),但效果反而下降(83% → 73%)。原因是 Nova 分类会把只有推广文字(无对白字幕)的帧也判为”有字幕”,这些帧被选入后 OpenCV 在上面检测到推广文字,拉偏了范围。而 OpenCV 抽帧天然过滤了这些帧——OCV 检测不到推广文字就跳过,反而是更好的过滤器。
| 抽帧方式 | OCV 单独 | Nova 裁剪 bbox | Combined |
| OCV 抽帧 | 40% | 80% | 83% |
| Nova 裁剪分类抽帧 | 46% | 66% | 73% |
结论:OCV 抽帧 + OCV 检测 + Nova 裁剪 bbox + 取交集 = 83%,是所有组合中最优的。
全部方法对比
| 方法 | ≤5% 准确率 | 偏差大 | 漏检 |
| OpenCV 单独 | 12/30 (40%) | 18 | 0 |
| Nova 全帧 bbox | 19/30 (63%) | 11 | 0 |
| 裁剪分类 + OCV | 15/30 (50%) | 15 | 0 |
| 裁剪 bbox 单独 | 24/30 (80%) | 6 | 0 |
| OCV + Nova 全帧 | 24/30 (80%) | 6 | 0 |
| OCV + 裁剪 bbox | 25/30 (83%) | 5 | 0 |
裁剪后 Nova 单独就达到了 80%(全帧只有 63%),结合 OpenCV 后达到 83%。
下图为保加利亚语视频帧的最终方案检测示例,裁剪后 COMB(粉色)结果与人工标注(蓝色)高度吻合:
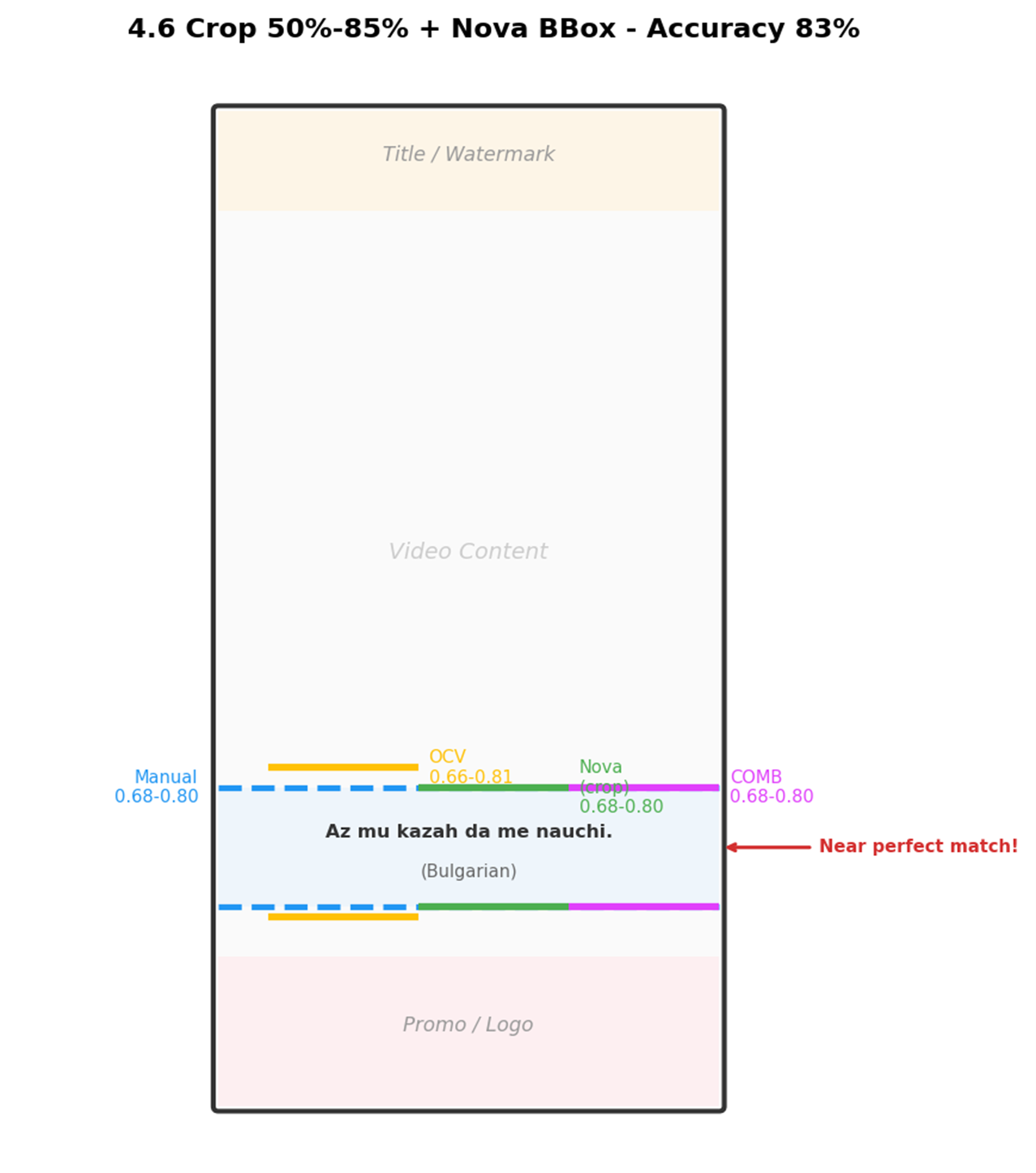
[图9:4.6 裁剪bbox最终方案示意图] |
5. 最终方案架构
5.1 逻辑架构
下图展示了字幕位置检测的数据处理流程:视频文件经过智能抽帧后,每帧同时送入 OpenCV 和 Nova 2 Lite 两条检测路径,最后通过取交集和多帧聚合得到最终的字幕位置范围。
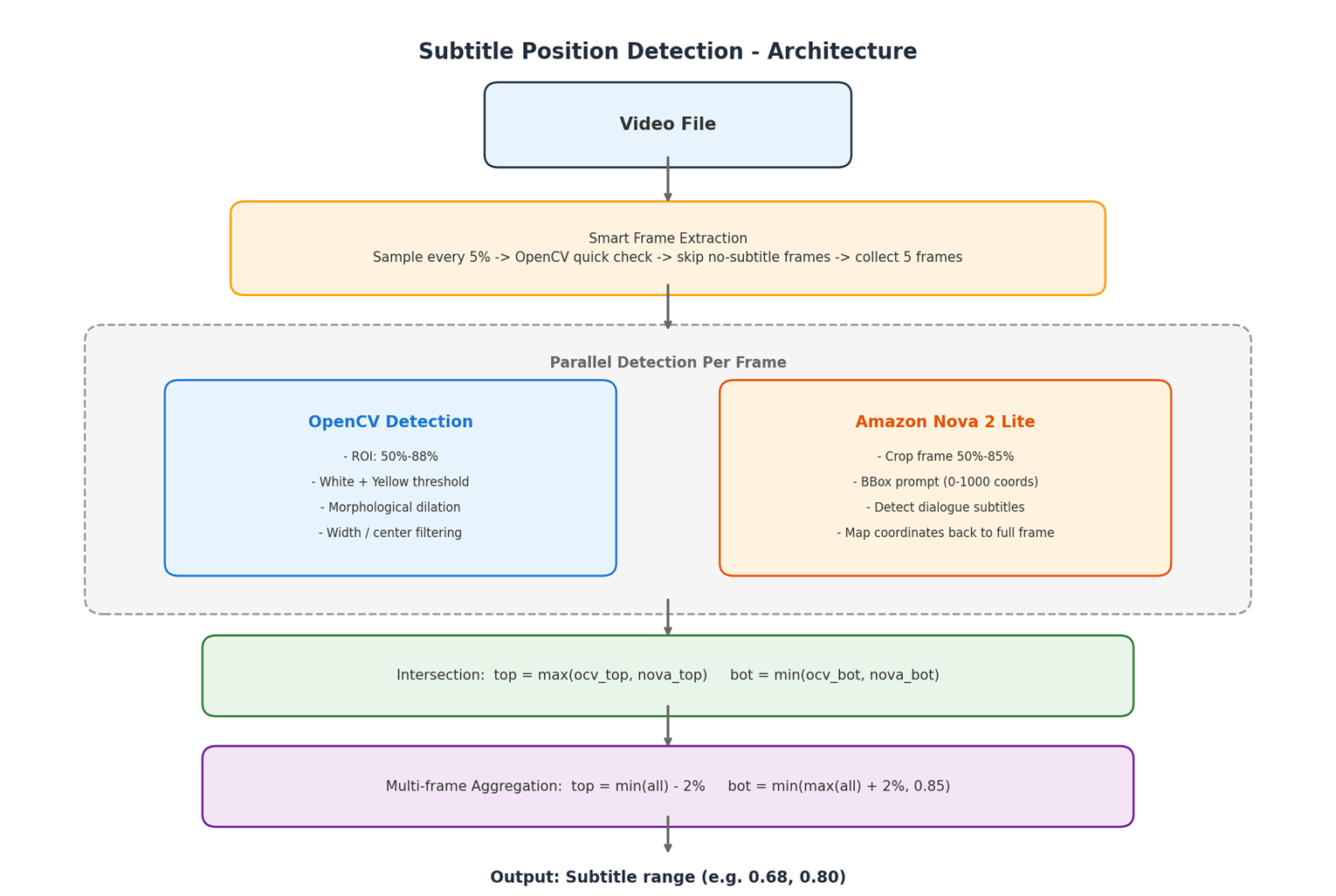
[图10:逻辑架构] |
5.2 物理架构
下图展示了方案在 AWS 上的部署架构:视频存储在 Amazon S3 中,EC2 实例(Graviton4)负责抽帧和 OpenCV 处理,通过 Amazon Bedrock API 调用 Nova 2 Lite 模型进行字幕检测,检测结果写回 S3。
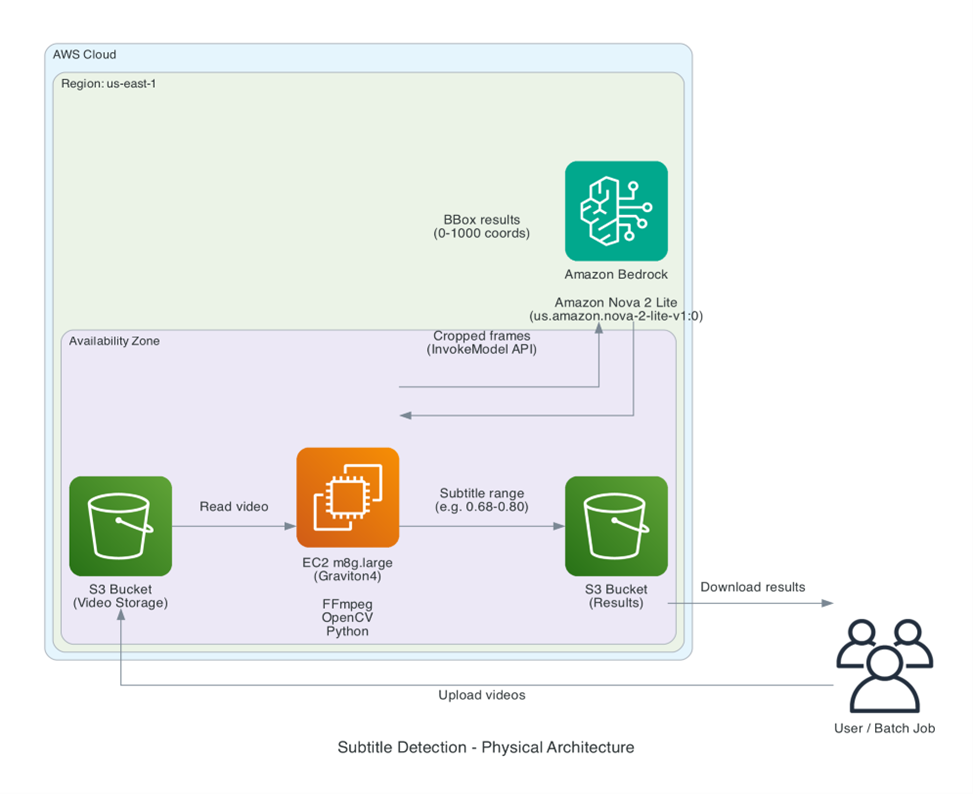
[图11:物理架构] |
6. 标注帧说明
测试过程中生成了标注帧用于可视化对比,每帧画面上有 4 种标注线:
| 标注 | 颜色 | 位置 | 说明 |
| MANUAL | 蓝色 | 全宽横线 | 人工标注的基准线(ground truth) |
| OCV | 黄色 | 左 1/3 段 | OpenCV 单独检测结果 |
| NOVA | 绿色 | 中 1/3 段 | Nova 2 Lite 单独检测结果 |
| COMB | 紫色 | 右 1/3 段 | 两者结合的最终结果 |
每种方法画上下两条同色线,分别表示字幕区域的上边界和下边界。蓝色基准线贯穿全宽,方便一眼看出各方法与人工标注的偏差。
文件命名格式:{语言}_{集数}_{时间百分比}.jpg,如 韩语_09_50.jpg 表示韩语第 9 集在 50% 时间点的帧。
7. 详细测试数据
7.1 测试集
30 个视频,覆盖 15 种语言,每种语言 2 个视频。人工标注的字幕位置作为 ground truth。
表中”视频”列为剧集编号,“人工标注”列为字幕在画面中的垂直位置范围(0 表示画面顶部,1 表示画面底部,如 0.68-0.78 表示字幕位于画面 68%~78% 处):
| 语言 | 剧集编号 | 字幕位置(上边界-下边界) |
| 泰语 | 10, 03 | 0.68-0.78, 0.78-0.78 |
| 葡语 | 09, 10 | 0.62-0.74, 0.68-0.83 |
| 罗马语 | 10, 09 | 0.69-0.84, 0.66-0.80 |
| 土耳其 | 09, 03 | 0.62-0.74, 0.63-0.79 |
| 德语 | 08, 07 | 0.68-0.79, 0.62-0.74 |
| 印尼语 | 09, 03 | 0.58-0.73, 0.68-0.79 |
| 英语 | 09, 02 | 0.60-0.75, 0.67-0.82 |
| 保加利亚语 | 09, 10 | 0.68-0.83, 0.66-0.81 |
| 西语 | 09, 10 | 0.63-0.78, 0.68-0.79 |
| 法语 | 08, 10 | 0.68-0.82, 0.68-0.79 |
| 日语 | 08, 09 | 0.68-0.83, 0.61-0.74 |
| 意大利 | 03, 09 | 0.65-0.79, 0.69-0.82 |
| 越南语 | 08, 09 | 0.68-0.79, 0.62-0.74 |
| 俄语 | 06, 07 | 0.61-0.73, 0.68-0.80 |
| 韩语 | 09, 10 | 0.62-0.74, 0.68-0.79 |
7.2 方案迭代准确率对比
| 版本 | OpenCV | Nova 全帧 | Nova 裁剪 | Claude 4.6 | OCV+Nova 全帧 | OCV+Nova 裁剪 |
| V1 固定5帧 | 30% | 30% | — | — | 53% | — |
| V2 智能抽帧 | 40% | 63% | 80% | 30% | 80% | 83% |
7.3 Claude Sonnet 4.6 对比测试
我们额外测试了 Claude Sonnet 4.6 作为视觉大模型的对比方案,使用百分比格式的 prompt 让 Claude 直接返回字幕的上下位置。
结果:9/30(30%),是所有方法中最差的。
失败原因分析: – 下边界全部偏大:Claude 返回的下边界几乎都超过 85%,说明它无法区分对白字幕和底部推广条 – 上边界偏差也较大:经常偏高 5-10%,像素级位置感知不够精确 – 不支持 bbox 格式:尝试用 Nova 的 bbox prompt(0-1000 坐标)让 Claude 输出,结果更差,坐标完全不准
结论:Nova 2 Lite 专门针对物体检测和 bbox 坐标输出做过训练,在精确定位任务上明显优于 Claude。Claude 更擅长语义理解和内容分析,但对像素级位置感知较弱。字幕位置检测这类精确定位任务,应优先选择 Nova 2 Lite 而非通用大模型。
下图为同一帧的检测对比示例。Nova 2 Lite(绿色线)的上下边界与人工标注(蓝色线)高度吻合,而 Claude 返回的下边界通常超过 85%,将底部推广条也包含在内:

[图12:Nova vs Claude 对比示意图] |
7.4 最终版逐视频结果
30 个视频中 25 个准确(偏差 ≤5%),5 个偏差较大,详见第 8 节失败案例分析。其中 10 个视频完全精准(偏差为 0),如德语/07、土耳其/09、英语/09、葡语/09 等。
8. 失败案例分析
5 个偏差 >5% 的视频,失败原因归为三类:
8.1 下边界偏大(2 个)
印尼语/09、西语/09
原因:这些视频的推广条紧贴字幕区域(间隔不足 6%),即使裁剪后仍有部分推广文字残留在裁剪区域内。
影响:下边界多出 7%,字幕擦除时会多擦一些区域,但不会漏擦。
8.2 上边界偏大(2 个)
- 日语/08:上边界 0.78 vs 实际 0.68,OpenCV 在某些帧检测到了画面中的白色花边装饰,拉高了上边界
- 法语/10:上边界 0.51 vs 实际 0.68,某帧中画面亮色区域被 OpenCV 误检
8.3 字幕位置特殊(1 个)
- 泰语/03:字幕位置在 0.78(非常靠下且范围极窄),但其他帧的检测结果在 0.67 附近,拉低了上边界
以下示意图展示了三类失败案例的检测偏差:
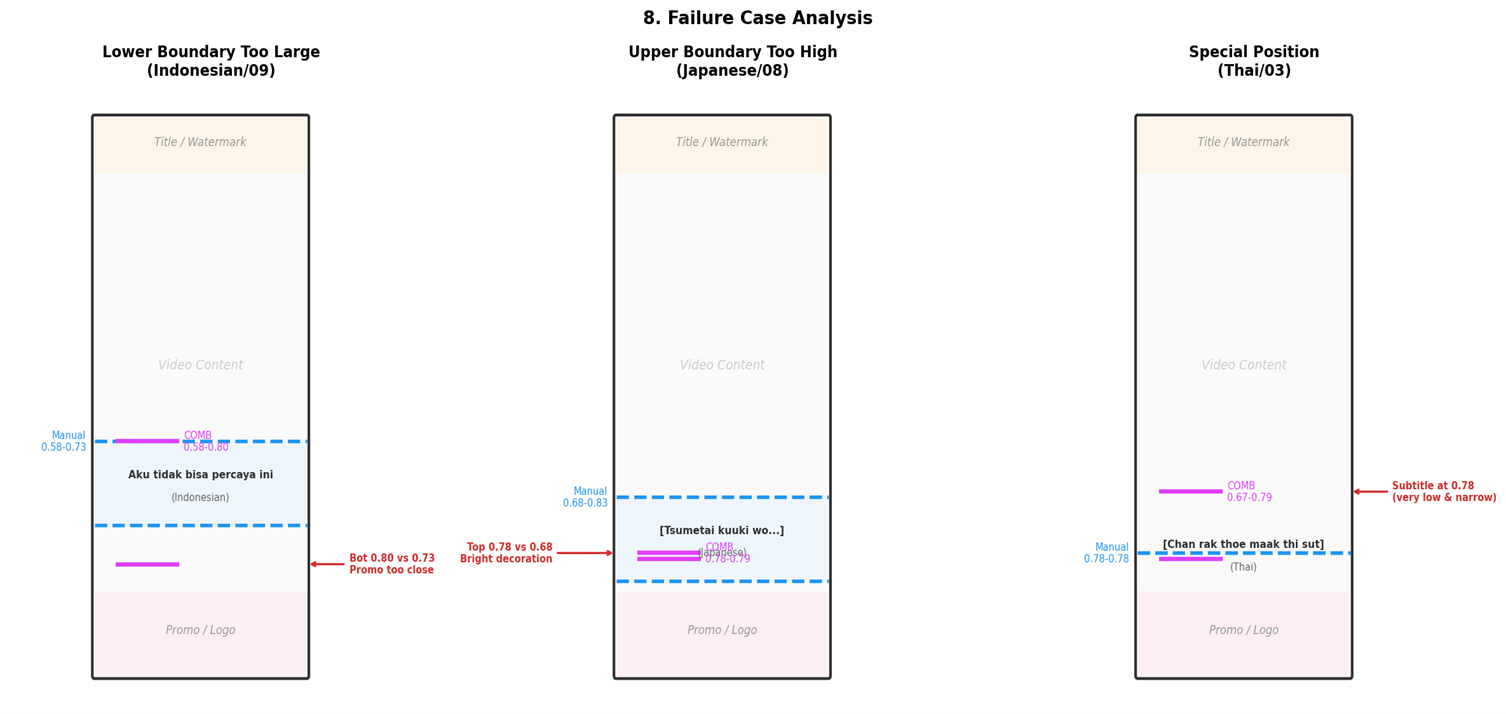
[图13:失败案例示意图] |
9. 成本分析
| 项目 | 成本 |
| EC2 实例(OpenCV + FFmpeg 处理) | 按实例类型计费,如 m8g.large(2vCPU/8GB Graviton4,约 $0.077/小时),单视频处理约 10 秒 |
| Amazon Nova 2 Lite 调用 | 约 $0.0003/帧(input image ~1000 tokens) |
| 单视频(5 帧) | EC2 约 $0.0002 + Nova 约 $0.0015 ≈ $0.002 |
| 100 个视频 | 约 $0.20 |
整体成本极低,适合大规模批量处理。
10. 关键代码
以下为核心逻辑片段。
10.1 智能抽帧
从 5% 开始每隔 5% 抽一帧,用 OpenCV 快速判断是否有字幕,跳过无字幕帧,收集 5 帧有效帧:
10.2 OpenCV 字幕检测
在 50%~88% 的 ROI 区域内,通过白色/黄色阈值 + 形态学膨胀 + 轮廓过滤检测字幕行:
10.3 Nova 2 Lite 裁剪 bbox 检测
将画面裁剪到 50%~85% 区域后送入 Nova 2 Lite,使用 bbox 格式(0-1000 坐标空间)检测字幕,再映射回全帧坐标:
为什么要裁剪? Nova 全帧检测时经常把底部推广条也框为字幕,导致下边界到 0.90+。裁剪到 50%-85% 后,推广条不在画面中,下边界精度大幅提升(准确率从 63% → 80%)。
10.4 取交集 + 聚合
11. 总结与展望
11.1 方案优势
- 83% 准确率:大部分视频可自动检测,显著减少人工标注工作量
- 零漏检:智能抽帧确保每个视频都能检测到
- 成本低:OpenCV 免费 + Nova 2 Lite 每视频约 $0.002
- 偏差可容忍:即使偏差 >5%,通常是下边界偏大(多擦一点),不会漏擦字幕
11.2 核心经验
- 单一方法不够:OpenCV 擅长精确定位但容易误检,Nova 擅长语义理解但位置不够精确,结合才能互补
- Prompt 格式很重要:Nova 2 Lite 用 bbox 检测格式(0-1000 坐标)比直接问百分比准确得多
- 裁剪是关键优化:将画面裁剪到字幕可能出现的区域(50%-85%)再给 Nova 检测,消除了推广条和标题的干扰,Nova 单独准确率从 63% 提升到 80%
- 智能抽帧很重要:跳过无字幕帧,确保每个视频都有有效检测帧
- 简单规则很有效:下边界 cap 在 0.85 这一条规则就消除了大量推广条误检
11.3 后续优化方向
1. 更精准的推广条过滤:检测品牌 logo 的固定位置,自动排除其附近的文字区域
2. 多模型投票:用多个视觉模型(如 Nova 不同版本)做投票,取多数一致的结果
3. 视频级别特征:分析多帧的字幕位置一致性,排除偶发的异常检测
4. 针对性训练:收集更多短剧字幕样本,微调专用的字幕检测模型
如果您对本方案感兴趣,欢迎访问开源仓库 aws-samples/sample-for-video-subtitle-detection-via-nova-2-lite 获取完整代码并开始试用。如有问题或建议,欢迎在 GitHub 上提交 Issue。
➡️ 下一步行动:
相关产品:
- Amazon Nova — 提供前沿智能和最高性价比的基础模型
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon IAM — 身份管理和访问权限
相关文章:
- Amazon Nova Lite Fine-Tuning: 高性价比的视觉检测模型微调案例与实践
- JoyCastle 素材资产智能化之路:基于 Amazon Nova Multimodal Embeddings 的广告素材管理实践
- Amazon Nova Act 现已全面推出,助力构建可靠的人工智能代理,实现用户界面工作流程自动化
- 推出 Amazon Nova Forge:使用 Nova 构建自己的前沿模型
- 使用Amazon Nova模型实现自动化视频高光剪辑
12. 参考资料
- OpenCV 轮廓检测 | 形态学操作 | HSV 颜色过滤
- Amazon Nova 视觉理解 | 物体检测 BBox 格式
- Amazon Bedrock InvokeModel API
- FFmpeg 视频帧提取
- Amazon Bedrock 支持的模型
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
