AWS Cloud Operations Blog
How to fix SSH issues on EC2 Linux instances using AWS Systems Manager
In a previous blog post, we provided a walkthrough of how to fix unreachable Amazon EC2 Windows instances using the EC2Rescue for Windows tool. In this blog post, I will walk you through how to utilize EC2Rescue for Linux to fix unreachable Linux instances. This Knowledge Center Article describes how EC2Rescue for Linux can be used to “manually” fix common issues, such as OpenSSH file permissions, or gather system (OS) logs for analysis and troubleshooting. This blog post will demonstrate how the AWS Systems Manager AWSSupport-ExecuteEC2Rescue automation document can automate the same process smoothly.
Walkthrough
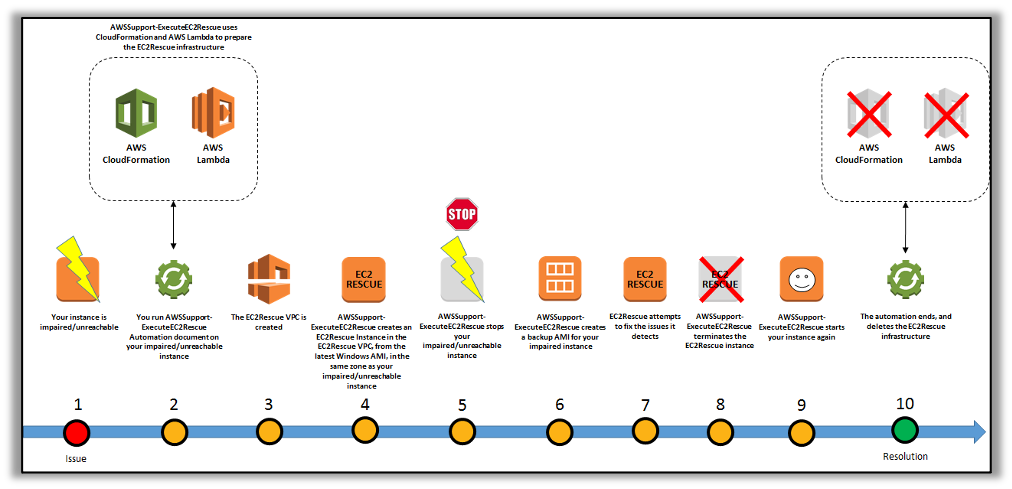
The AWS Systems Manager Automation Document, “AWSSupport-ExecuteEC2Rescue” uses the EC2Rescue for Linux and EC2Rescue for Windows tools.
The Automation document runs EC2Rescue for Linux on an offline instance by creating rescue EC2 instance, moving the target instance root volume to the rescue instance, and later reattaching the root volume to the original instance. These are conducted via an automated set of steps in the document::
- Specify the Instance ID of the unreachable instance and run the Automation workflow.
- The document creates a temporary Amazon VPC, and then it runs a series of AWS Lambda functions in order to configure the VPC. Otherwise, you can input the Subnet ID (optional) for the EC2 Rescue instance to be launched.
- The document identifies a subnet for your temporary VPC in the same Availability Zone as your original instance.
- The document launches a temporary, AWS Systems Manager enabled helper instance.
- The document stops your original instance, and then creates a backup. Next, it attaches the original root volume to the helper instance.
- The document utilizes Run Command to run EC2Rescue on the helper instance. EC2Rescue identifies and attempts to fix issues on the attached, original root volume. When finished, EC2Rescue reattaches the root volume back to the original instance.
- The document restarts your original instance, and then terminates the temporary instance. The system also terminates the temporary VPC and the Lambda functions created at the start of the automation.
Note: You do not need to worry about the problematic unreachable instance in order to have an SSM agent installed, because, as per workflow of this document, it will launch a rescue Instance that will have SSM-enabled.
To know more about this document walkthrough, check here.
Prerequisites
Before proceeding with the next steps, you need the following prerequisites:
- Instance ID of the unreachable instance. You will specify this ID in the procedure. This is a required parameter.
- In addition, the document takes optional parameters that you can refer here.
- An IAM role for this execution of this document. If no role is specified, AWS Systems Manager Automation will utilize your IAM permissions to execute this document. To know more about granting permissions by using IAM policies, refer here.
Next, I will illustrate how this document works with an example of a common Linux SSH issue.
Under EC2 console, I have selected the test instance where I will be modifying the permissions of /home/ec2-user for this example.

Issue: I have changed permissions of /home directory to 777 and now I am not able to SSH and getting a “Permission denied” error
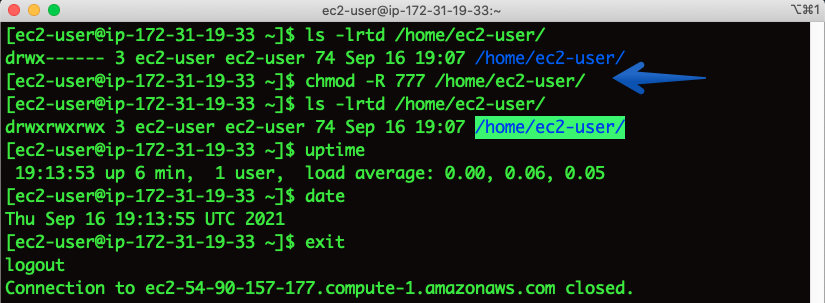
Checking SSH output:
# ssh -i “Linux.pem” ec2-user@ec2-54-90-157-177.compute.amazonaws.com

Getting the permission denied error.
Now, let’s use “AWSSupport-ExecuteEC2Rescue” Automation Document to fix this issue:
- Open the AWS Systems Manager via AWS Management Console, and Type “Systems Manager“
- In the navigation pane, choose Automation—-> Choose Execute Automation.
- In the Automation document section categories, choose “Self service support workflows”, check for the Document named – “AWSSupport-ExecuteEC2Rescue”, and click “Next”
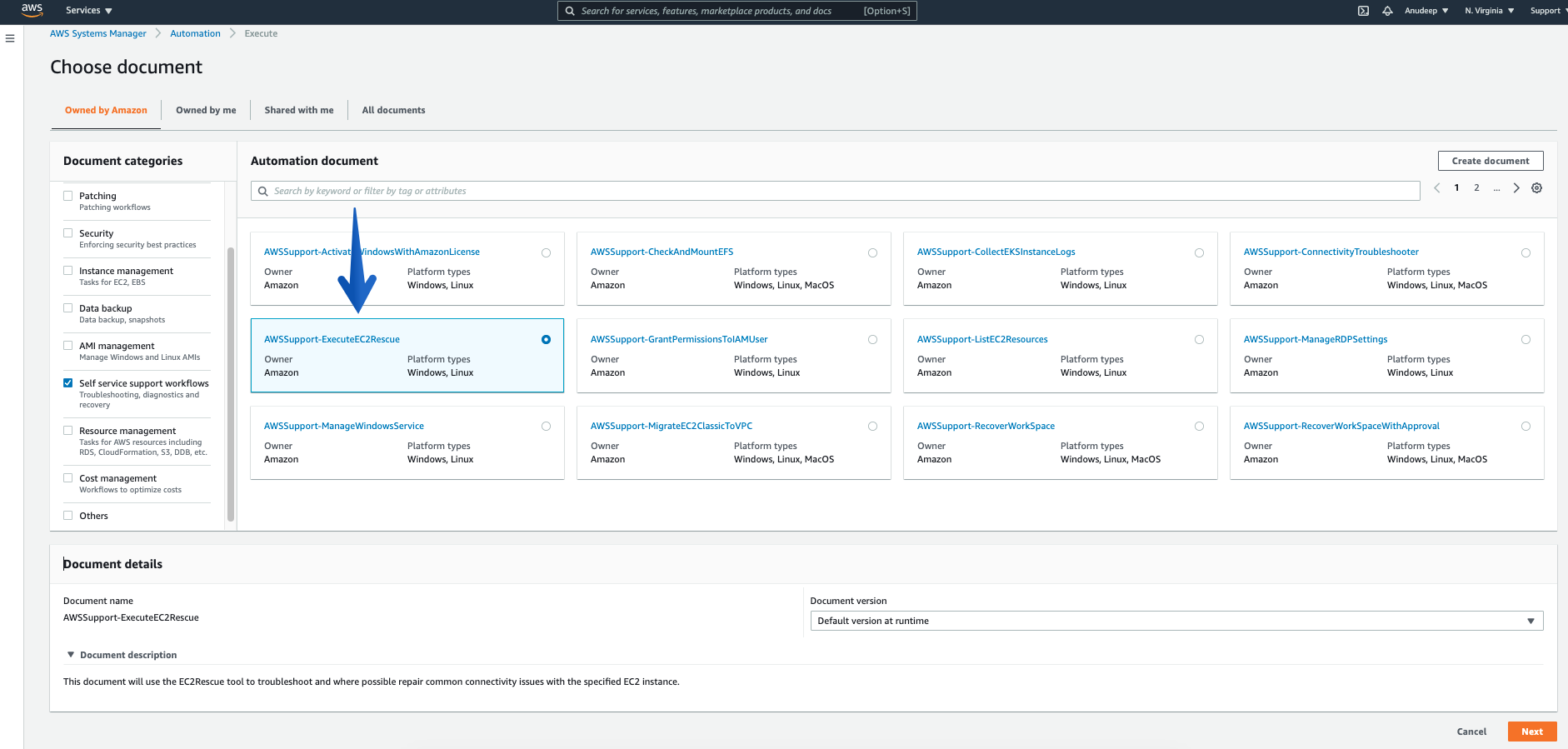
- Please provide the Instance ID of unreachable Instance (Required), and then click the Execute button to start Automation workflow:
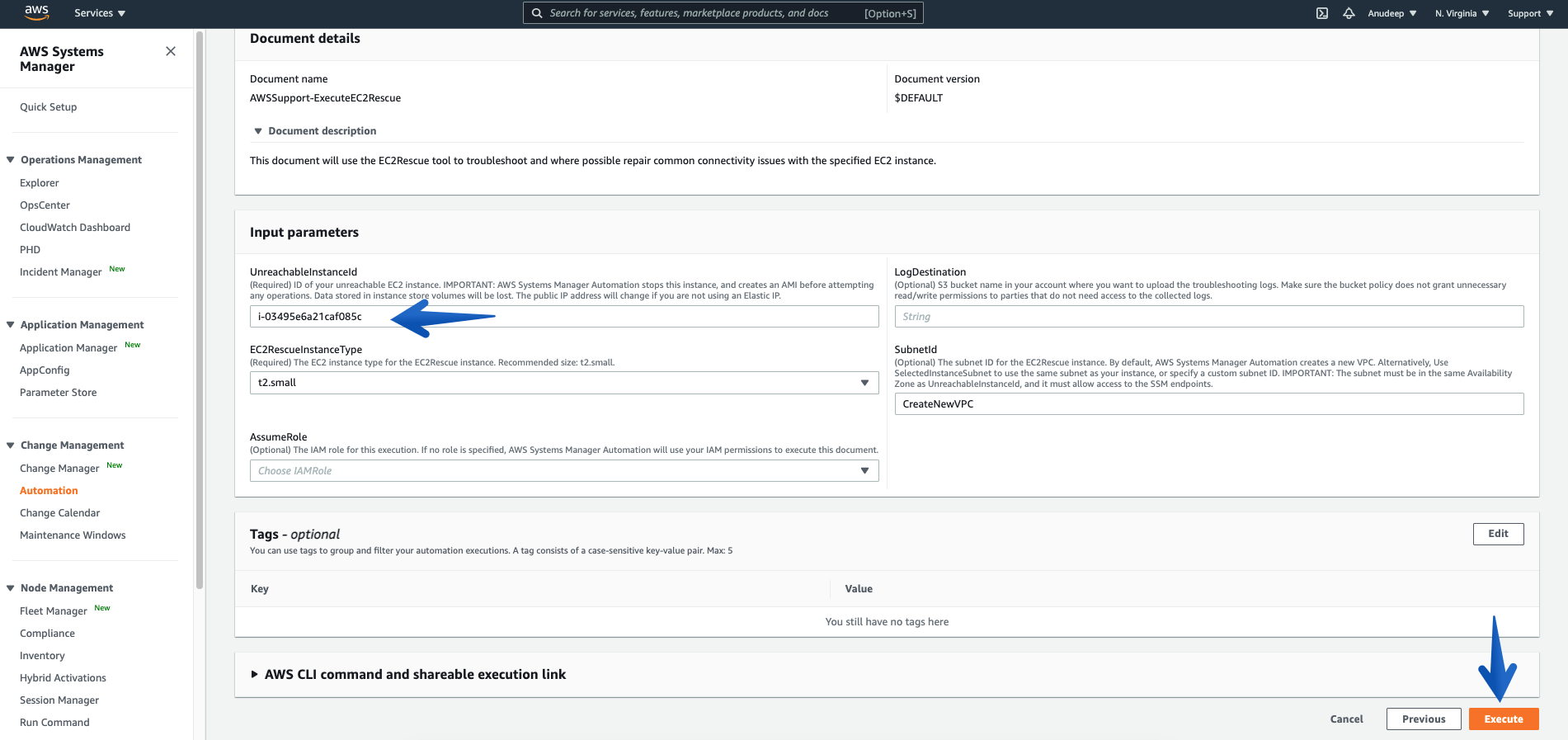
Some Information about Input Parameters:
Mandatory/Required:
- UnreachableInstanceId : (Required) ID of your unreachable EC2 instance.
IMPORTANT: AWS Systems Manager Automation stops this instance, and then creates an AMI before attempting any operations. Data stored in instance store volumes will be lost. The public IP address will change if you are not using an Elastic IP address.
- EC2RescueInstanceType : (Required) The EC2 instance type for the EC2Rescue instance. Recommended size: t2.small. (it is auto-selected by default)
Optional:
- LogDestination: (Optional) Amazon Simple Storage Service (S3) bucket name in your account where you want to upload the troubleshooting logs. Make sure that the bucket policy does not grant unnecessary read/write permissions to parties that do not need access to the collected logs.
- SubnetId: (Optional) The subnet ID for the EC2Rescue instance. By default, AWS Systems Manager Automation creates a new VPC. Alternatively, use SelectedInstanceSubnet to use the same subnet as your instance, or specify a custom subnet ID.
IMPORTANT: The subnet must be in the same Availability Zone as UnreachableInstanceId, and it must allow access to the SSM endpoints.
- AssumeRole: (Optional) The IAM role for this execution. If no role is specified, AWS Systems Manager Automation will utilize your IAM permissions to execute this document. To know more about granting permissions by using IAM policies, refer here.
Now, let’s proceed:
- Once you click the “Execute” button, the Automation will start, and you can see the Status “In Progress”:
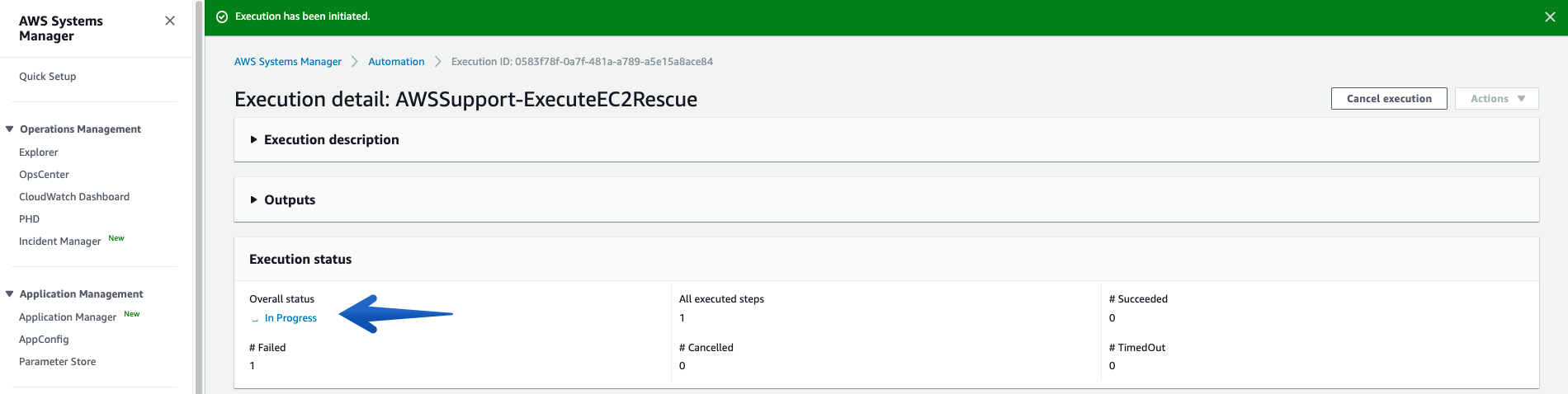
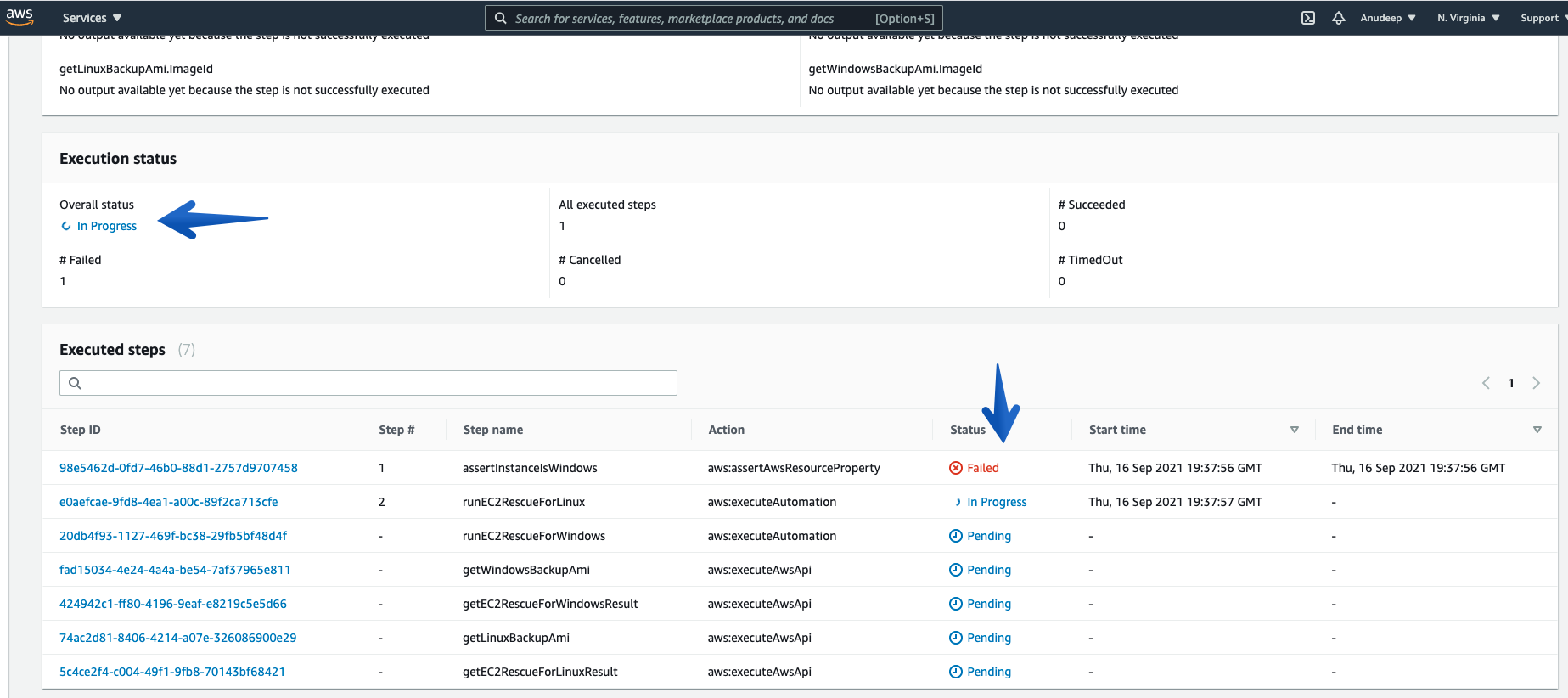
- See more details under Executed Steps.
Checking what it does in the background:
- Procedure creates an SSM helper Instance/recovery Instance with the name tag AWS-Support-EC2Rescue-I-xxxx

- Creates an AMI for backup purpose before it runs further steps:

- Stops the Problematic Unreachable Instance, Detaches the Root Volume from it, and Attaches on the SSM enabled Recovery/Helper Instance:
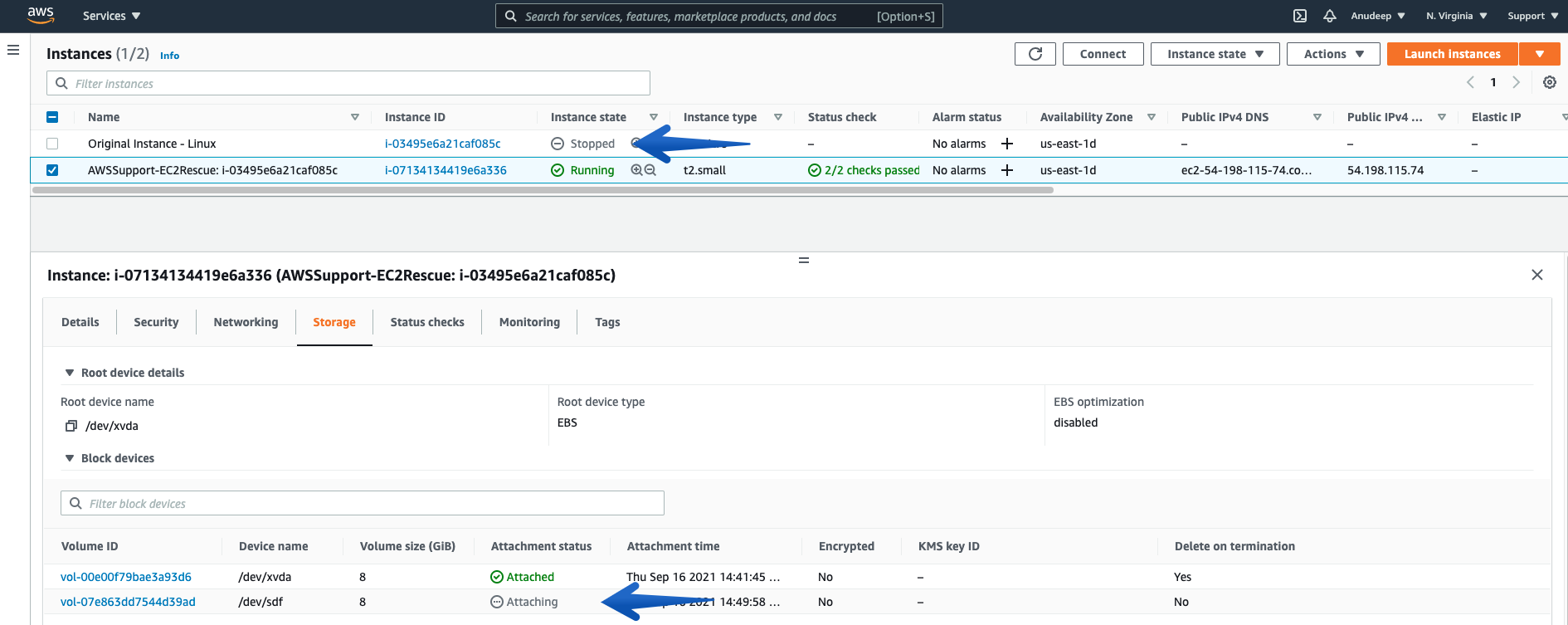
- Then, the procedure runs EC2Rescue for Linux over rescue Instance in order to Fix the Issue and you can also track the steps below:
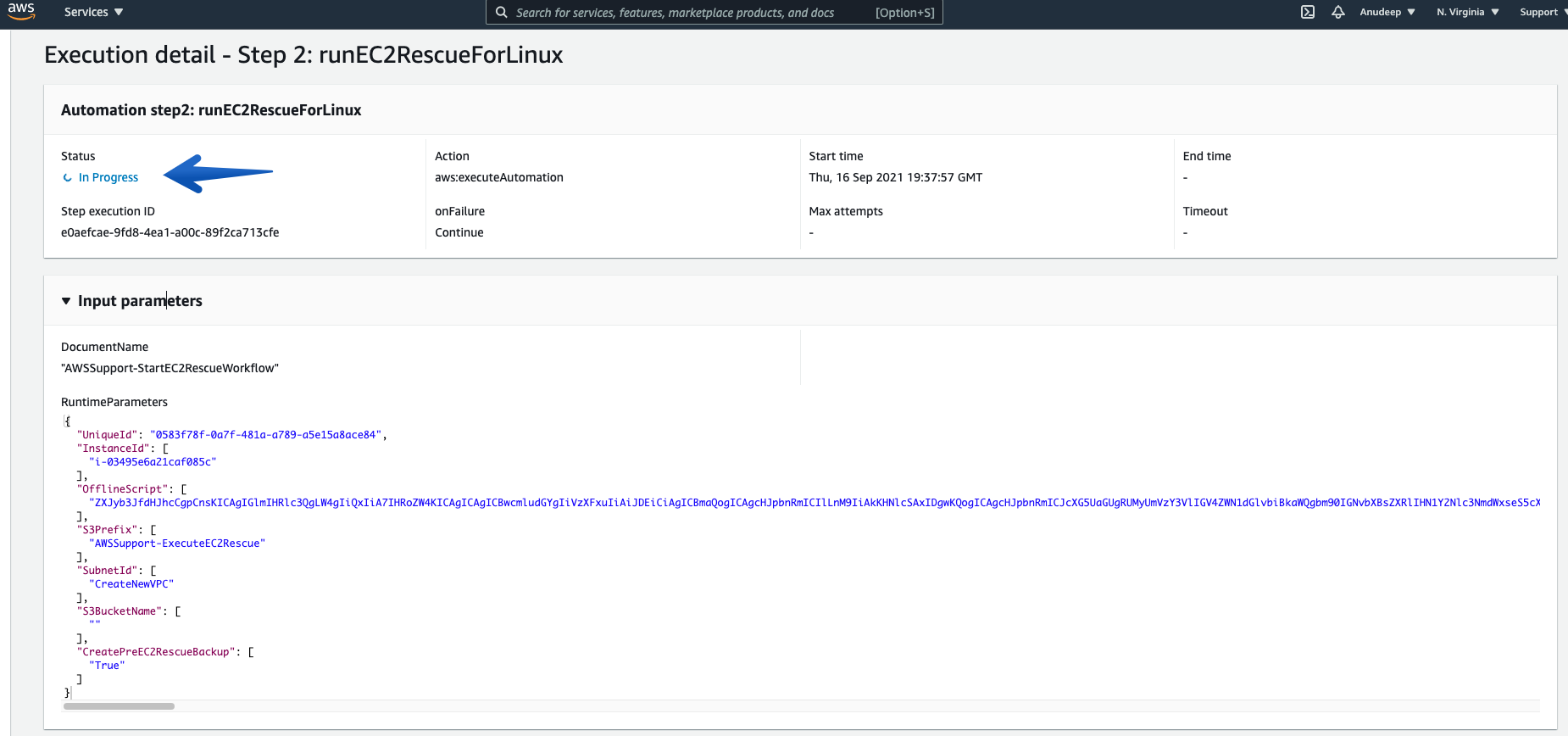
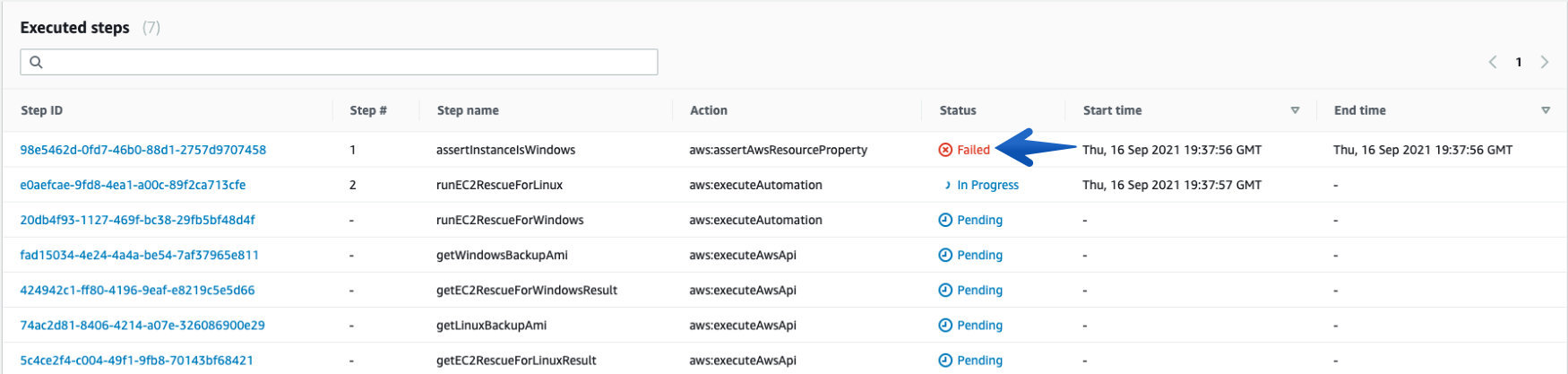
- You can always check the details of each “Execution ID” and its Associated steps using “Step ID”.
Note: Linux Instances will have a “Failed” status for the first step every time.
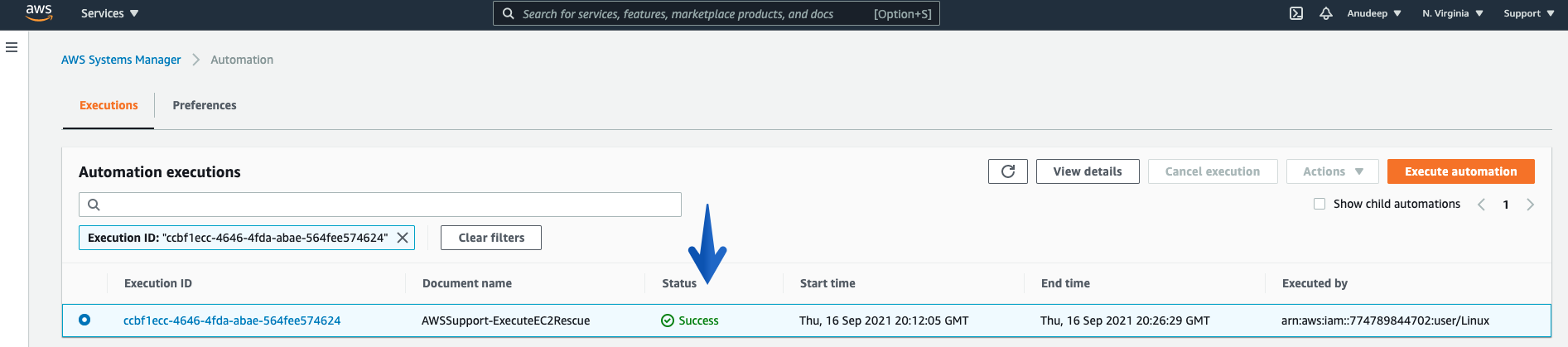
- Monitor the Overall Status of the Procedure using the Execution Status tab under Automation Executions, and wait for it to get “Success”, which marks it as complete.
- Now, checking the Instance state again, you can see the Rescue / SSM enabled Rescue Instance has been terminated and Automation have Started the Original Unreachable Instance again after fixing the issue:

Now, let’s try to connect to the Instance:
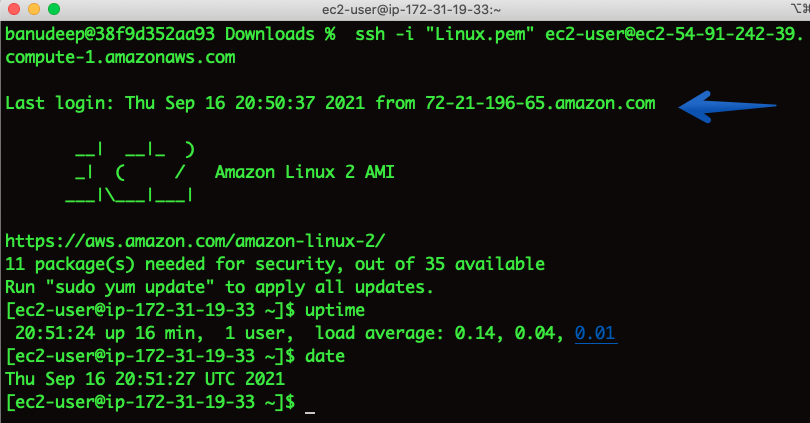
I am able to SSH and Issue has been fixed. ?
Note: As the instance has a public IP address associated with it, after a stop/start of the instance during the automation runtime, the Public IP address has changed. If you would like to have a static IP, please associate an Elastic IP to the instance.
How to check the logs for what steps our procedure conducted on Instance:
Check the details of Step ID “runScriptForLinux”, which will provide you with a location of the log presence on instance.
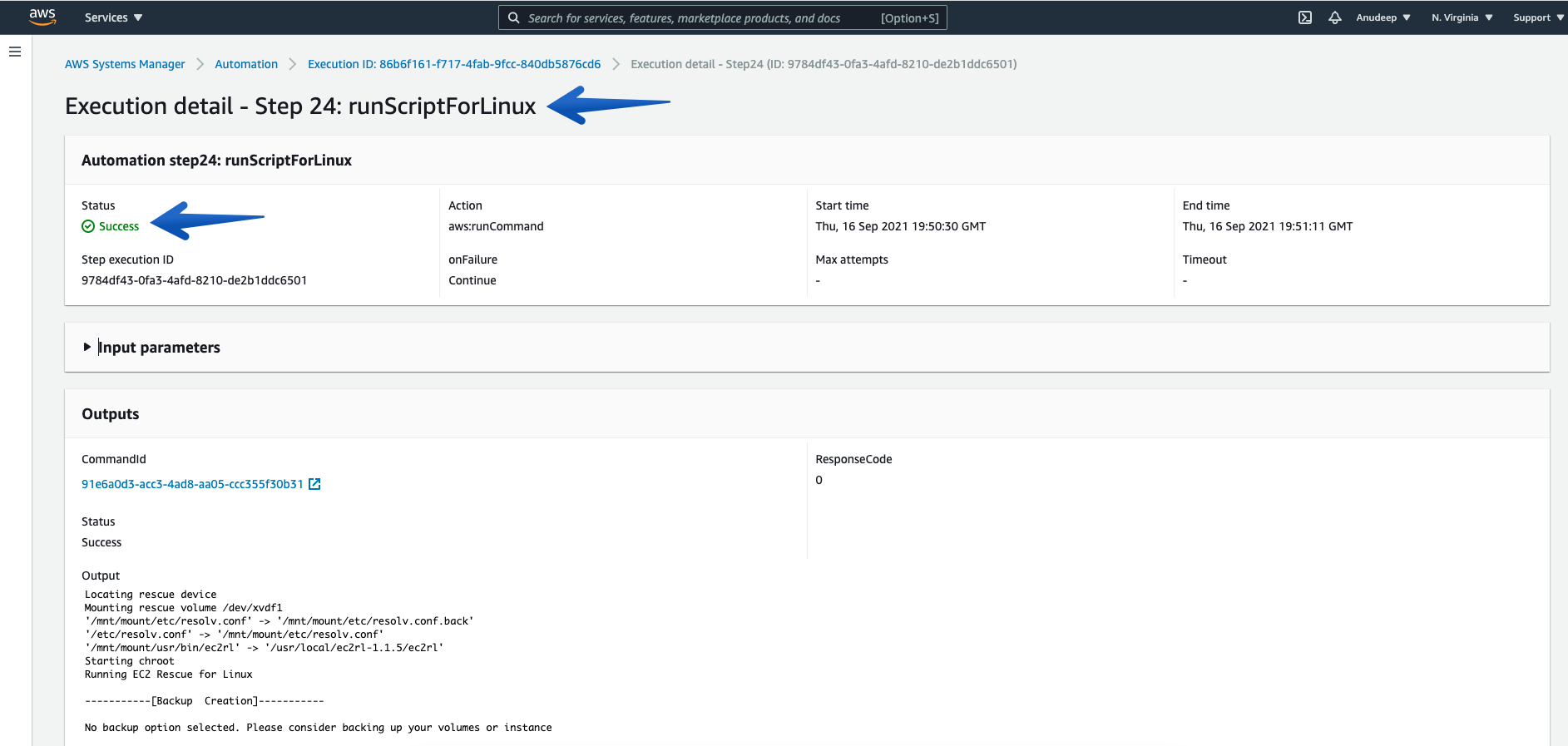
- Please note the location displayed there. For example, in my case the output logs are located in /var/tmp/ec2rl/2021-09-16T19_50_33.565132
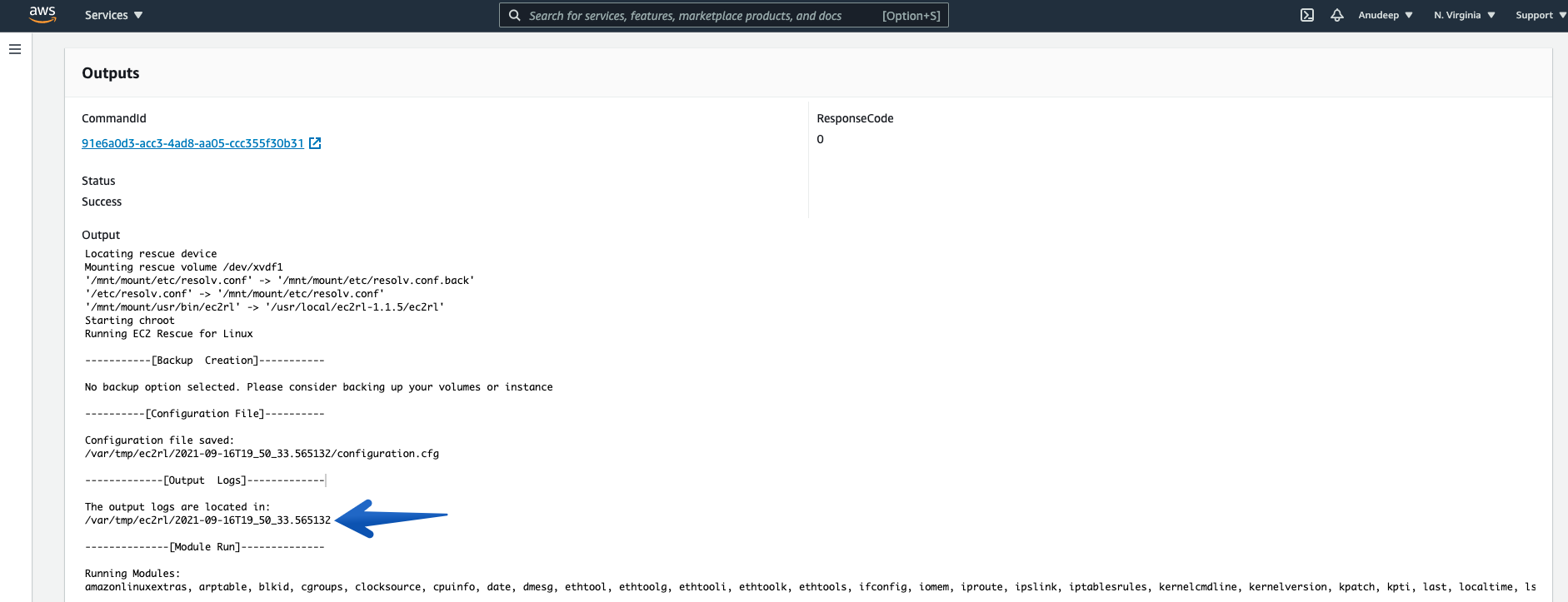
- Now, I will check the Log location and see detailed information as follows:

Therefore, I have also identified what fixes have been applied by EC2Rescue for Linux over instance to fix the issue in an automated way.
How to conduct the above steps using AWS CLI:
- Running the Automation Document for an unreachable Instance (i-03495e6a21caf085c) :
- You can also see the Automation Scheduled (using Console):
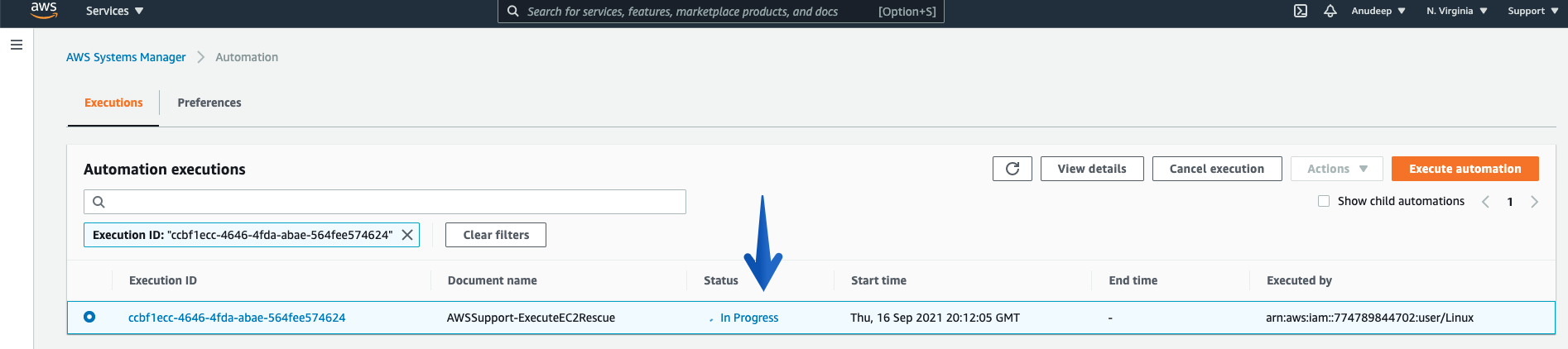
- Checking the Automation progress/Status:
- Let’s wait a few minutes to get this completed and Can check the Status again:
- You can also see this (using Console):
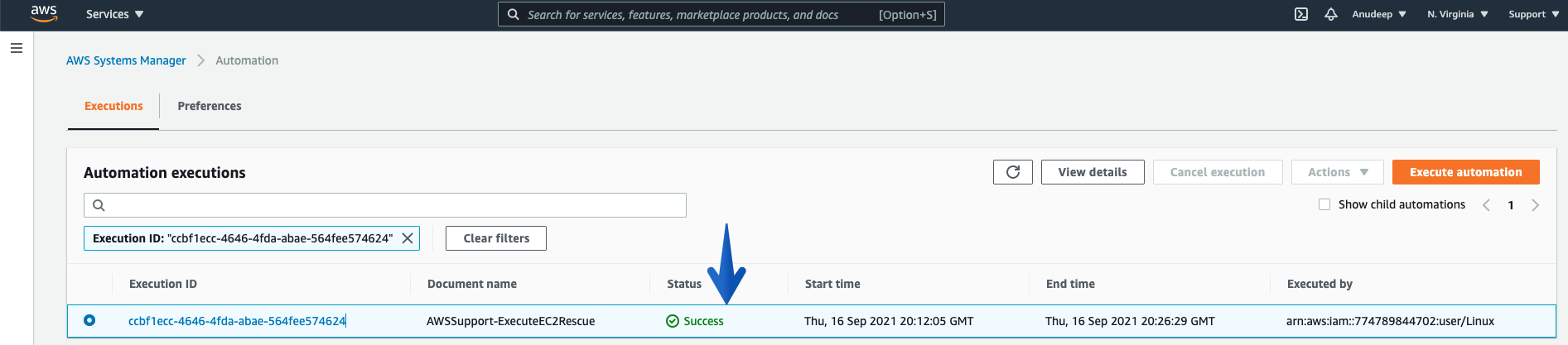
- After the Status is returned as “Success”, let’s try to SSH to the Instance again: (Success)
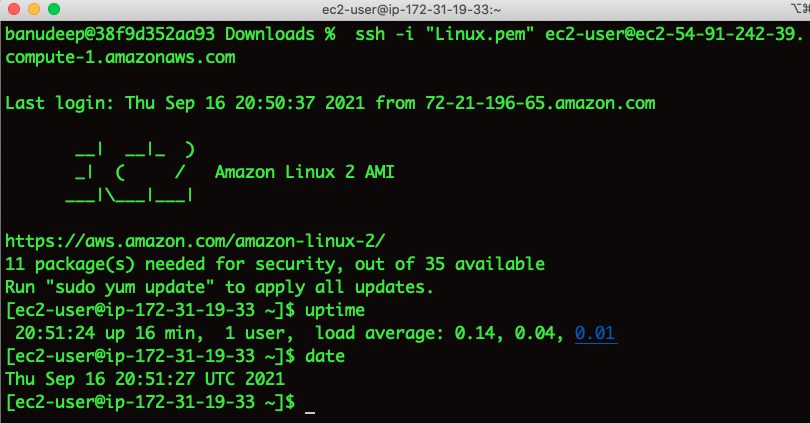
I am able to log in to the EC2 Instance now – Issue resolved. ?
Conclusion
AWSSupport-ExecuteEC2Rescue is a new Automation document that automates every step required to fix common issues on your unreachable Windows and Linux instance utilizing respective EC2Rescue for Linux and EC2Rescue for Windows tool tools.
In this blog post I have demonstrated how the integration between CloudWatch Events and Systems Manager Automation enables to run AWSSupport-ExecuteEC2Rescue automatically in response to an event in your infrastructure.