Analytique sur AWS
Ensemble complet de fonctionnalités pour chaque charge de travail analytique, qui permettent d’optimiser la rentabilité et la mise à l’échelle
Présentation
AWS propose un ensemble complet de fonctionnalités pour chaque charge de travail analytique. Du traitement des données et de l’analytique SQL au streaming, à la recherche et à la veille stratégique, AWS offre des prix, des performances et une capacité de mise à l’échelle inégalés, ainsi qu’une gouvernance intégrée. Choisissez des services spécialement conçus et optimisés pour des charges de travail spécifiques ou rationalisez et gérez vos données et vos flux de travail d’IA avec Amazon SageMaker. Que vous commenciez votre parcours vers les données ou que vous recherchiez une expérience intégrée, AWS vous propose les fonctionnalités d’analytique appropriées pour vous aider à réinventer votre activité grâce aux données.
Obtenez des résultats commerciaux tangibles grâce à l’analytique sur AWS
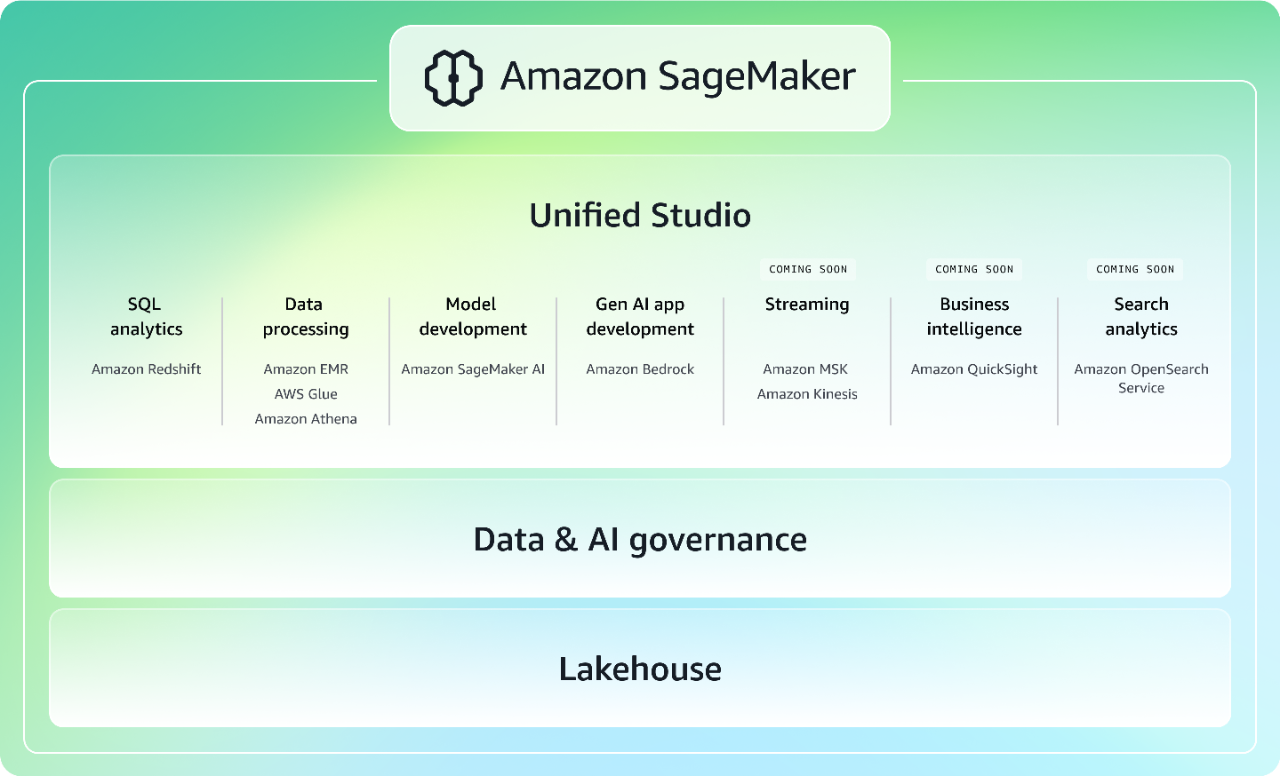
Accélérez les données, l’analytique et l’IA grâce à une expérience intégrée
Associant des fonctionnalités de machine learning (ML) et d’analytique largement adoptées par AWS, la nouvelle génération d’Amazon SageMaker propose une expérience intégrée pour l’analytique et l’IA avec un accès unifié à toutes vos données. Collaborez et créez plus rapidement à partir d’un studio unifié en utilisant des outils AWS familiers pour le développement de modèles, le développement d’applications d’IA générative, le traitement des données et l’analytique SQL, accélérés par Amazon Q Developer, l’assistant d’IA générative le plus performant pour le développement de logiciels. Accédez à toutes vos données, qu’elles soient stockées dans des lacs de données, des entrepôts de données ou des sources de données tierces ou fédérées, avec une gouvernance intégrée afin de répondre aux besoins de sécurité de votre entreprise. En savoir plus sur SageMaker.
Mise en place de stratégies multicloud avec AWS
AWS propose une gamme complète de puissants services analytique qui permettent un accès et un traitement fluides des données dans des environnements multicloud et hybrides. Vous pouvez bénéficier de cette flexibilité grâce à des requêtes fédérées, à l'intégration des données, à un transfert sécurisé des données et à la compatibilité avec les normes ouvertes, ce qui vous permet d'obtenir des informations sur toutes vos données, quel que soit leur emplacement.
Amazon Athena vous permet d'interroger et d'obtenir des informations à partir de sources de données stockées dans diverses sources de données externes, notamment le stockage lac de données Azure, Google Cloud Storage, Microsoft SQL Server et bien d'autres, sans avoir à copier ou à transformer les données.
AWS Glue simplifie la découverte, la préparation et l'intégration de toutes vos données à n'importe quelle échelle, grâce à des connecteurs pour plus de 100 sources de données différentes couvrant le stockage dans le cloud, les bases de données et les services d'analytique. Les intégrations Zero-ETL de Glue permettent d'ingérer et de répliquer facilement des données provenant d'applications tierces telles que Salesforce, SAP, Facebook Ads et Instagram Ads directement dans vos lacs, lacs de données et entrepôts de données AWS. AWS Glue assure également l'interopérabilité des données grâce à la prise en charge de standards ouverts tels qu'Apache Hive, Apache Parquet et Apache Iceberg.
La prochaine génération d'Amazon SageMaker repose sur une architecture de lac de données ouverte, fournissant un accès unifié aux lacs de données et aux entrepôts de données sur AWS, ainsi qu'à des sources de données fédérées telles que Google BigQuery et Snowflake. Cette architecture Lakehouse est entièrement compatible avec Apache Iceberg, ce qui vous permet d'accéder aux données et de les interroger sur place à l'aide de tous les outils et moteurs compatibles avec Iceberg.
Exploiter l'analytique au service des humains et de l'IA
Optimisez l'analytique à grande échelle grâce à des services spécialement conçus pour stocker, interroger, diffuser, traiter et gérer les données. Des formats Open Table (OTF) à l'infrastructure des agents, AWS fait évoluer ses moteurs et ses applications d'analytiques pour s'adapter à l'évolution rapide du paysage analytique. Au cours de cette session, découvrez comment AWS propose des solutions optimisées conçues à la fois pour les utilisateurs humains et pour les flux de travail des agents.

Services
|
Catégorie analytique
|
Description
|
Service et fonctionnalités AWS
|
|---|---|---|
|
Streaming
|
Créez, mettre à l’échelle et exploitez des pipelines de données et des applications en temps réel sans vous soucier de la gestion de l’infrastructure. |
|
|
Lakehouse de données, entrepôt de données, lac de données
|
Accédez à et analysez l’intégralité de vos données dans les entrepôts de données, les entrepôts de données et les lacs de données. |
|
|
Traitement des données
|
Analysez, préparez et intégrez vos données pour l’analytique et l’IA à l’aide de cadres open source. |
|
|
Business intelligence
|
Créez, découvrez et partagez des informations pertinentes grâce à des tableaux de bord interactifs modernes, des rapports ultraprécis, des requêtes en langage naturel et une analytique intégrée. |
|
|
Analytique de recherche
|
Exploitez en toute sécurité la recherche, la supervision et l’analyse en temps réel de vos données métiers et opérationnelles. |
|
|
Gouvernance des données et de l’IA
|
Cataloguez, découvrez, partagez et gérez les données stockées sur AWS, sur site et auprès de sources tierces. |
L'impact économique total de la stratégie de données moderne d'AWS
Économies de coûts et avantages commerciaux grâce à la stratégie de données moderne d’Amazon Web Services, selon Forrester.
Statistiques
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages