AWS for M&E Blog
Extracting value from video archives using AI: Videofashion case study
For M&E companies with large content archives, the principal challenge is surfacing the most relevant content for use by producers or licensors. Taking it further, some customers such as sports leagues (that have access to decades’ worth of content) want to make their content archives available to their fanbase via an API so that the entire archive is searchable by the end user and licensable via an API. Unfortunately, most content metadata has been manually entered across different systems until recently, making it too resource intensive to be practical for owners of large media libraries to get a thorough understanding of what is in their archives.
Machine learning applications such as facial recognition for celebrity detection can automate the generation of searchable metadata tags by timecode, enabling new levels of search and discovery in content libraries. Modern cloud-based asset management systems leverage these additional metadata and can provide a unified search interface.
For example, Videofashion is the world’s largest fashion video licensor. Working with AWS partner GrayMeta, it was able to automate generating time-coded metadata for thousands of hours of fashion show footage going back four decades.
Videofashion is leveraging GrayMeta Curio for a web portal that allows licensees to easily search for individuals by name (either separately or when they appear together) and metadata that was across multiple systems prior.
With this new system, licensees are able to pull up only those relevant clips. They are then able to download and license the relevant clip for use directly from Videofashion’s web portal.
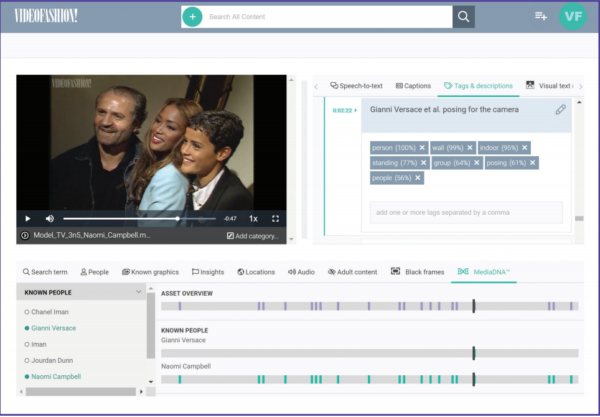
This post originally appeared as part of a larger article in the 2019 M&E Journal.