AWS Big Data Blog
Announcing Amazon EMR Serverless (Preview): Run big data applications without managing servers
Today we’re happy to announce Amazon EMR Serverless, a new option in Amazon EMR that makes it easy and cost-effective for data engineers and analysts to run petabyte-scale data analytics in the cloud. With EMR Serverless, you can run applications built using open-source frameworks such as Apache Spark and Hive without having to configure, manage, optimize, or secure clusters. EMR Serverless automatically provisions and scales the compute and memory resources required by your applications, and you only pay for the resources that the applications use.
In this post, we discuss the benefits of EMR Serverless, walk you through the core concepts of EMR Serverless and how you can use it, and show you a quick demo.
Overview of EMR Serverless
Tens of thousands of customers use Amazon EMR, a managed service for running open-source analytics frameworks such as Apache Spark and Hive for large-scale data analytics applications. With Amazon EMR, you can provision clusters of any size in minutes. Amazon EMR automatically installs and configures the frameworks you choose, and provides a performance-optimized runtime that is compatible with and over twice as fast as standard open-source.
Amazon EMR customers have full control over cluster configuration. The ability to customize clusters allows you to optimize for cost and performance based on workload requirements. For example, you can use Amazon Elastic Compute Cloud (Amazon EC2) memory optimized instances to run SQL workloads with low latency, or use the EC2 Graviton2-based instances to improve performance. You can also use EC2 Spot Instances, which are integrated in Amazon EMR so that you can take advantage of unused EC2 capacity in the AWS Cloud to obtain instances at up to a 90% discount compared to On-Demand prices. If you run your applications on Kubernetes, you can use Amazon EMR on Amazon EKS to run your Amazon EMR analytics applications on Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
However, tuning clusters for optimal cost and performance requires engineers to have deep knowledge of the underlying analytics frameworks. Furthermore, the specific compute and memory resources needed to optimally run applications depend on various factors, such as the schedule and complexity of data processing jobs and the volume of data being processed. When these characteristics change over time, you need to reevaluate and reconfigure clusters. In addition, administrators have to secure and monitor clusters to ensure that they’re compliant with corporate security policies. Many customers don’t need this level of customization and control, and want a simpler way to process data using open-source frameworks and Amazon EMR’s performance-optimized runtime.
With this in mind, we built EMR Serverless. With EMR Serverless, you can get all the benefits of running Amazon EMR, but with a serverless environment. We had the following goals in mind when we built EMR Serverless:
- Provide a simpler experience – EMR Serverless is simple to use because you don’t have to configure, optimize, operate, or secure clusters. You don’t have to worry about instance types or cluster sizes, or about applying OS updates. You simply specify the framework and version that you want to use for your application, and submit your data processing jobs. You still get all the benefits that you expect out of Amazon EMR—open-source compatibility, open-source version currency, and performance-optimized runtime—but without the need to manage clusters.
- No need to guess cluster sizes – EMR Serverless eliminates the need to right-size clusters for varying jobs and data sizes. With EMR Serverless, you create an application using an open-source framework version, and submit jobs to the application. EMR Serverless automatically adds and removes workers at different stages of processing your job. As a result, you don’t have to reconfigure when data volumes change, and you only pay for what your jobs require. You can control costs by specifying the minimum and maximum number of concurrent workers, and the VCPU and memory per worker.
- Retain Amazon EMR’s performance-optimized runtime and open-source currency –EMR Serverless includes the Amazon EMR performance-optimized runtime for Apache Spark and Hive. The Amazon EMR runtime is API-compatible and over twice as fast as standard open-source, so your jobs run faster and incur less compute costs.
- Seamless integration with EMR Studio – EMR Serverless includes EMR Studio, which provides fully managed serverless Jupyter Notebooks and familiar open-source tools such as Spark UI and Tez UI to help you develop, visualize, and debug your applications.
- Automatic and fine-grained scaling – EMR Serverless automatically scales up workers at each stage of processing your job and scales them down when they’re not required. You’re charged for aggregate vCPU, memory, and storage resources used from the time a worker starts running until it stops, rounded up to the nearest second with a 1-minute minimum. For example, your job may require 10 workers for the first 10 minutes of processing the job, and 50 workers for the next 5 minutes. With fine-grained automatic scaling, you only incur cost for 10 workers for 10 minutes and 50 workers for 5 minutes. As a result, you don’t have to pay for underutilized resources.
- Resilience to Availability Zone failures – EMR Serverless is a Regional service. When you submit jobs to an EMR Serverless application, it can run in any Availability Zone in the Region. A job is run in a single Availability Zone to avoid performance implications of network traffic across Availability Zones. In case an Availability Zone is impaired, a job submitted to your EMR Serverless application is automatically run in a different (healthy) Availability Zone. When using resources in a private VPC, EMR Serverless recommends that you specify the private VPC configuration for multiple Availability Zones so that EMR Serverless can automatically select a healthy Availability Zone.
- Enable shared applications – When you submit jobs to an EMR Serverless application, you can specify the AWS Identity and Access Management (IAM) role that must be used by the job to access AWS resources such as Amazon Simple Storage Service (Amazon S3) objects. As a result, different IAM principals can run jobs on a single EMR Serverless application, and each job can only access the AWS resources that the IAM principal is allowed to access. This enables you to set up scenarios where a single application with a pre-initialized pool of workers is made available to multiple tenants wherein each tenant can submit jobs using a different IAM role, but use the common pool of pre-initialized workers to immediately process requests.
- Enable interactive applications – Interactive applications that allow data scientists and analysts to run SQL queries and scripts for data exploration require a fast response time to user requests. For such applications, EMR Serverless allows you to pre-initialize a pool of workers. You can start your EMR Serverless application and pre-initialize the pool of workers as soon as a user starts the application, and stop the application to stop workers when no interactive users are active. If processing user requests requires more workers than what have been pre-initialized, EMR Serverless automatically adds more workers up to the maximum concurrent limits that you specify. Therefore, by controlling the number of workers to pre-initialize and the maximum concurrent workers, you can optimize user experience and cost for your interactive applications.
- Make it easy to switch from one deployment model to another – The same Amazon EMR releases are provided for applications using EMR clusters, Amazon EMR on EKS, and EMR Serverless. When you build an application using an Amazon EMR release (for example a Spark job using Amazon EMR release 6.4), you can choose to run it on an EMR cluster, Amazon EMR on EKS, or EMR Serverless without having to rewrite the application. This allows you to build applications for a given framework version, and retain the flexibility to change the deployment model based on future operational needs.
Core concepts
In this section, we discuss the core concepts in EMR Serverless: applications, jobs, workers, and pre-initialized workers.
Application
With EMR Serverless, you can create one or more applications that use open-source analytics frameworks. To create an application, you specify the open-source framework that you want to use (for example, Apache Spark or Apache Hive), the Amazon EMR release for the open-source framework version (for example, Amazon EMR release 6.4, which corresponds to Apache Spark 3.1.2), and a name for your application. After you create an application, you can submit data processing jobs or interactive requests to your application.
The following are a few examples where you may want to create multiple applications:
- To use different open-source frameworks (for example, Hive or Spark)
- To use different versions of open-source frameworks for different use cases (for example, use a newer version of Spark for a new application without having to upgrade older applications)
- To perform A/B testing when upgrading from one version to another (for example, migrating from Spark 2.4 to Spark 3.1)
- To maintain separate logical environments for test and production scenarios
- To provide separate logical environments for different teams with independent cost controls and usage tracking
- To logically separate different line-of-business applications (for example, finance vs. marketing)
Job
A job is a request submitted to an EMR Serverless application that is asynchronously run and tracked through completion. You can run multiple jobs concurrently in an application.
Workers
An EMR Serverless application internally uses workers to run your jobs. Depending on the open-source framework, EMR Serverless uses a default number of VCPU, memory, and local storage per worker. You can override these defaults for your application.
Pre-initialized workers
EMR Serverless provides an optional feature to pre-initialize workers when your application starts up, so that the workers are ready to process requests immediately when a job is submitted to the application. Pre-initialized workers allow you to maintain a warm pool of workers for the application your application can start in seconds.
Common usage patterns applied to EMR Serverless
Now let’s examine some common usage scenarios and how EMR Serverless provides you a simple solution.
Pattern #1: Data pipelines
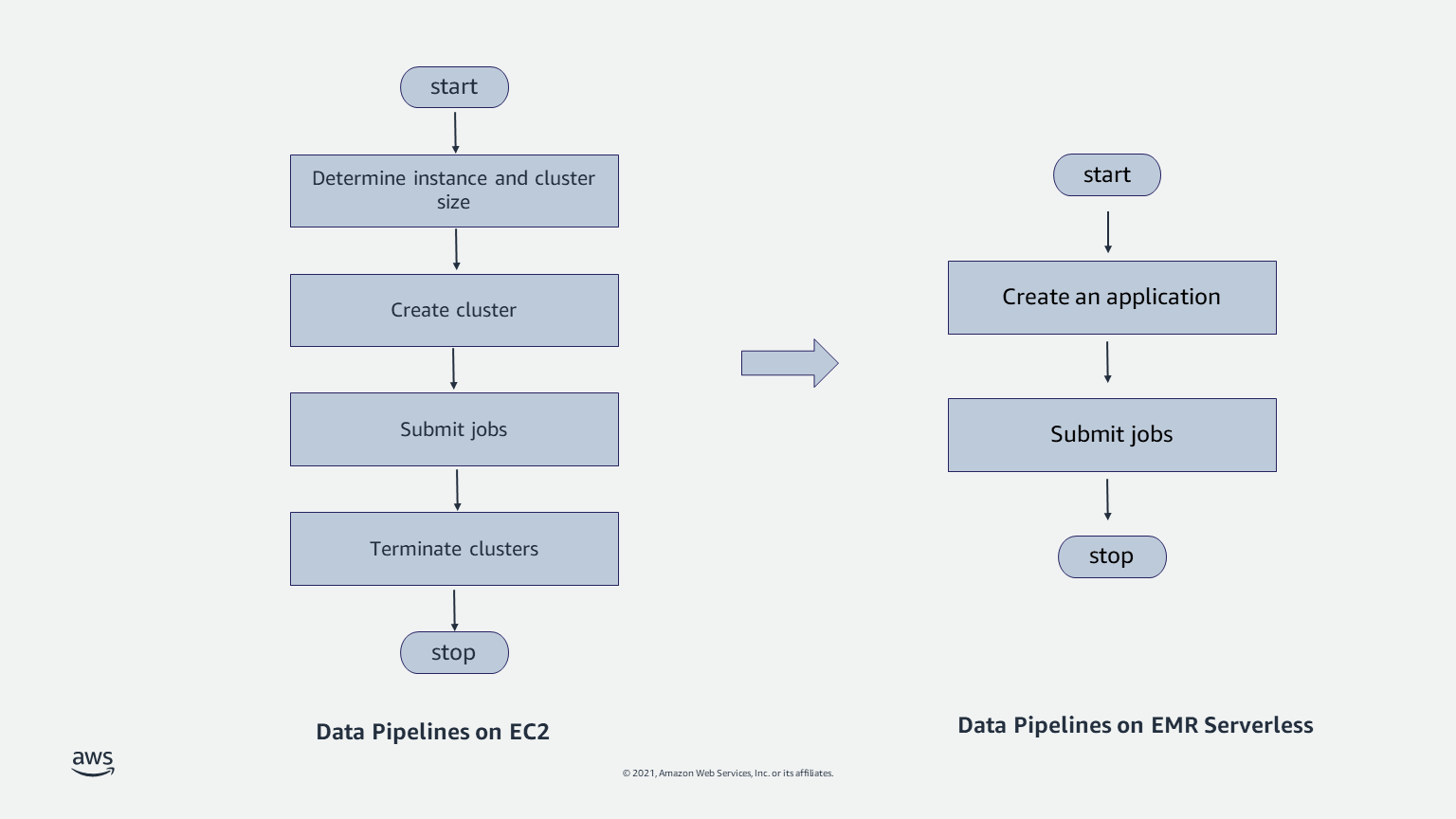
Data pipelines are the backbone of your analytics workloads. A common pattern with data pipelines is to start a cluster, run a job, and stop the cluster when the job is complete. Because data is separated from compute, the inputs and outputs for each job are persisted separately from the cluster (for example, in Amazon S3). These steps are frequently automated using workflow orchestration applications such as Apache Airflow. You can also use AWS services such as AWS Step Functions and AWS Managed Workflows for Apache Airflow (Amazon MWAA) to create such workflows.
Although automating these steps isn’t complex, data engineers have to spend time determining the appropriate EC2 instance and cluster size. They have to determine the Availability Zone where the cluster is run, and handle failover. They have to test their applications when adopting OS updates. When data sizes change over time, they have to resize clusters, or use features like Amazon EMR managed scaling that automatically resize clusters. EMR Serverless provides a simpler solution by eliminating the need for you to handle these scenarios. You simply choose the open-source framework and version for your application, and submit jobs. You don’t have to worry about instance selection, cluster sizes, cluster startup, cluster resize, stopping nodes, Availability Zone failover, or OS updates.
Pattern #2: Shared clusters
Another common pattern is for teams to use a shared long-running cluster to run multiple jobs. In this case, engineers implement queues in Apache YARN for different workloads on a common cluster, and set up rules to automatically scale the cluster up or down based on overall workload. With Amazon EMR on EC2 clusters, you can use Amazon EMR managed scaling, a feature that automatically scales clusters up or down depending on the workload. With EMR Serverless, workers are assigned to each job when required, so your jobs get the resources they need. Moreover, because you only pay for the workers that your jobs require, you don’t incur cost for over-provisioned resources. Finally, because each job can specify the IAM role that should be used to access AWS resources when running the job, you don’t have to set up complex configurations to manage queues and permissions.
Pattern #3: Interactive workloads
A third pattern of use is when teams keep a cluster of instances available to support interactive analysis. In this case, the cluster is set up and initialized with applications that wait for interactive user requests. Applications are pre-initialized so that they can immediately start processing user requests and provide an interactive user experience. EMR Serverless enables this scenario without requiring you to manage clusters. You can specify the number of workers that you want to pre-initialize when you start an EMR Serverless application. Subsequently, when users submit requests, the pre-initialized workers can be used to immediately process user requests. If processing the user requests requires more workers than what you have chosen to pre-initialize, EMR Serverless automatically adds more workers (up to the maximum concurrent limit that you specify). After the requests are processed, EMR Serverless automatically reverts back to maintaining the pre-initialized workers that you specified. You can control when the pre-initialized workers are active by controlling when to start and stop your EMR Serverless application. For example, you can start your application when users begin interactive analysis and turn it off when there are no user requests and the application is idle.
Demo
Conclusion
In this post, we discussed the core concepts and common usage patterns of EMR Serverless, and showed you a quick demonstration video. EMR Serverless is in Preview, and you can sign up for the preview to run workloads using Spark 3.1.2 and Hive 2.0 using the API, AWS Command Line Interface (AWS CLI), and SDK. For more information, see EMR Serverless documentation.
About the Authors
 Damon Cortesi is a Principal Developer Advocate with Amazon Web Services.
Damon Cortesi is a Principal Developer Advocate with Amazon Web Services.
 Mehul Y. Shah is the GM for Amazon EMR.
Mehul Y. Shah is the GM for Amazon EMR.
 Abhishek Sinha is a Principal Product Manager at Amazon Web Services.
Abhishek Sinha is a Principal Product Manager at Amazon Web Services.