AWS Big Data Blog
Prepare data for model-training and invoke machine learning models with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Amazon Athena has announced a public preview of a new feature that provides an easy way to run inference using machine learning (ML) models deployed on Amazon SageMaker directly from SQL queries. The ability to use ML models in SQL queries makes complex tasks such as anomaly detection, customer cohort analysis, and sales predictions as simple as writing a SQL query.
Overview
Users now have the flexibility to use ML models trained on proprietary datasets or to use out-of-the-box, pre-trained ML models deployed on Amazon SageMaker. You can now easily invoke a variety of ML algorithms across text analysis, statistical tools, and any algorithm deployed on Amazon SageMaker. There is no additional setup required. Users can invoke ML models in SQL queries from the Athena console, Athena APIs, and through use of Athena’s JDBC and ODBC drivers in tools such as Amazon QuickSight. Within seconds, analysts can run inferences to forecast sales, detect suspicious logins to an application, or categorize all users into customer cohorts.
During the preview, you are not charged for the data scanned from federated data sources. However, you are charged standard Athena rates for data scanned from Amazon S3. Additionally, you are charged standard rates for the AWS services that you use with Athena, such as Amazon S3, AWS Lambda, AWS Glue, Amazon SageMaker, and AWS Serverless Application Repository. For example, you are charged S3 rates for storage, requests, and inter-region data transfer. By default, query results are stored in an S3 bucket of your choice and are also billed at standard Amazon S3 rates. If you use AWS Lambda, you are charged based on the number of requests for your functions and the duration, the time it takes for your code to execute.
Athena has also added support for federated queries and user-defined functions (UDFs). This blog demonstrates how to:
- Ingest, clean, and transform a dataset using Athena SQL queries to ready it for model training purposes
- Use Amazon SageMaker to train the model
- Use Athena’s ML inference capabilities to run prediction queries in SQL using the model created in Step 2
For illustration purposes, consider an imaginary video game company whose goal is to predict which games will be successful.
Assume that the video game company has a raw dataset in Amazon S3 with the schema represented by the following SQL statement.
A screenshot of the sample dataset in Athena follows.

Diagram 1: Screenshot of the sample dataset in our example.
Data Analysis and Cleaning
To prepare the dataset for training the model using Amazon SageMaker, you need to select the relevant data required to train the ML model. You don’t need columns that are not relevant for training, such as game_id, name, year_of_release, sales, critic_count, user_count, and developer.
Additionally, this example defines success as the scenario in which sales of a particular game exceed 1,000,000. You can create a success column that is either 0 (denoting no success) or 1 (denoting success) in the dataset to reflect success.
A sample query and screenshot showing the success column follow:

Diagram 2: Screenshot of our sample dataset with the columns that are irrelevant for training our ML model deleted.
ML models typically do not work well with String Enums. To optimize performance and improve model accuracy, convert the platform, genre, publisher, and rating to integer Enum constants. You can use Athena’s UDF functionality to accomplish this.
The following sample code creates an AWS Lambda function that you can invoke in the Athena SQL query as UDF.
A sample Athena Query that normalizes the dataset using the functions created above follows:
The following screenshot shows the normalized dataset:

Diagram 3: Screenshot after defining, and invoking our UDFs that help to normalize our dataset.
Creating the machine learning model
Next, create the ML model in Amazon SageMaker.
Open an Amazon Sagemaker Notebook instance with Permissions to Execute Athena Queries and execute the following sample Athena query. The query first imports the required Amazon SageMaker libraries and PyAthena into your Amazon SageMaker Notebook, executes an Athena query to retrieve the training dataset, invokes the training algorithm on this dataset, and deploys the resulting model on the selected Amazon SageMaker instance. PyAthena allows you to invoke Athena SQL queries from within your Amazon SageMaker Notebook.
Note that you can also train your model using a different algorithm and evaluate your model. For more details on using Amazon SageMaker, please visit the SageMaker documentation.
Using the model in SQL queries
Having trained the ML model and deployed it on Amazon SageMaker, your next task is to use this model in your Athena SQL queries to predict whether a given video game will be a success.
A sample prediction query follows. You can run this query in your Amazon SageMaker notebook after loading PyAthena, or using the Athena Console. You can also submit this query using Athena’s APIs or using the Athena Preview JDBC driver.
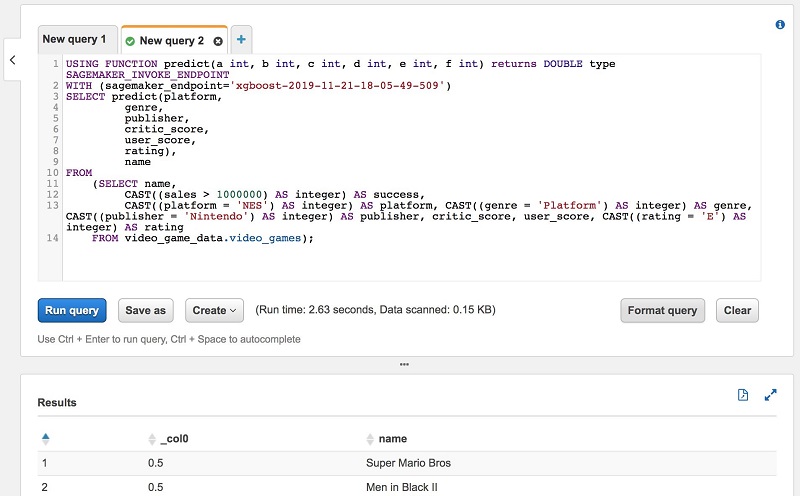
Conclusion
In this blog, we introduced Athena’s new functionality that enables you to invoke your machine learning models in SQL queries to run inference. Using an example, we saw how to use Athena’s UDF functionality. We defined and invoked our functions to ready our dataset for machine learning model training purposes. To train our model, we used PyAthena to invoke Athena SQL queries in Amazon SageMaker and finally, invoked our ML model in SQL query to run inference.
Amazon Athena’s ML functionality is available today in preview in the us-east-1 (N. Virginia) region. Begin your preview now by following these Athena FAQ.
To learn more about the feature, please visit our querying ML model documentation.
About the Authors
 Janak Agarwal is a product manager for Athena at AWS.
Janak Agarwal is a product manager for Athena at AWS.
 Ronak Shah is a software development engineer for Athena at AWS.
Ronak Shah is a software development engineer for Athena at AWS.