AWS Compute Blog
Optimizing nested JSON array processing using AWS Step Functions Distributed Map
When you’re working with large datasets, you’ve likely encountered the challenge of processing complex JSON structures in your automated workflows. You need to preprocess arrays within nested JSON objects before you can run parallel processing on them. Extracting data used to require custom code and extra processing steps, delaying you from building your core application logic.
With AWS Step Functions Distributed Map, you can process large datasets with concurrent iterations of workflow steps across data entries. Using the enhanced ItemsPointer feature of Distributed Maps, you can extract array data directly from JSON objects stored in Amazon S3. Alternatively, for JSON object as state input, you can use Items (JSONata) or ItemsPath (JSONPath). With this enhancement you can point directly to arrays nested within JSON structures, eliminating the need for custom preprocessing of your data. With ItemsPointer, Items, and ItemsPath you can select the nested array data and simplify your workflows.
In this post, we explore how to optimize processing array data embedded within complex JSON structures using AWS Step Functions Distributed Map. You’ll learn how to use ItemsPointer to reduce the complexity of your state machine definitions, create more flexible workflow designs, and streamline your data processing pipelines—all without writing additional transformation code or AWS Lambda functions.
This post is part of a series of post about AWS Step Functions Distributed Map:
|
Use case: e-commerce product data enrichment
In this e-commerce use case example, you’ll build a sample application that demonstrates processing of product inventory data for an e-commerce application using AWS Step Functions Distributed Map. The application receives a JSON file from an upstream application containing an array of product information. The Step Functions workflow reads the JSON file containing product data from an S3 bucket and iterates over the array to enrich each product data in the array.
The following diagram presents the AWS Step Functions state machine.
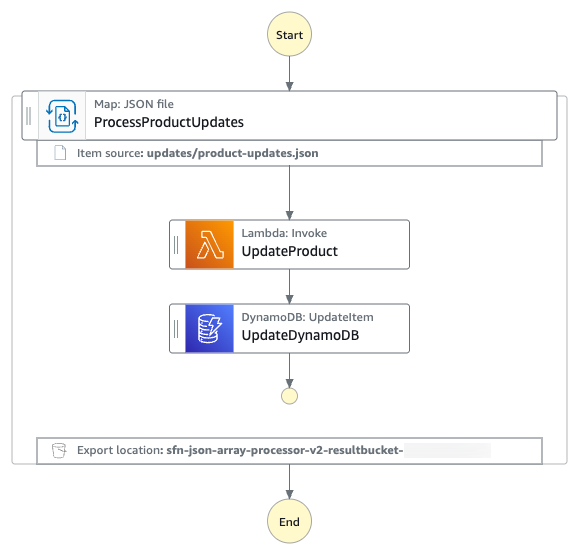
JSON array processing workflow
The JSON array is processed using the following workflow:
- The state machine reads the product-updates.json file from an input S3 bucket. The file contains a JSON array of products.
- The Distributed Map state in the state machine, selects the JSON array node using
ItemsPointerand iterates over the JSON array. - For each of the items within the array, the state machine invokes a Lambda function for data enrichment. The Lambda function adds product stock and price information to the product data.
- The state machine saves the updated product data in an Amazon DynamoDB table.
- Finally, the state machine uploads the execution metadata into an output S3 bucket. See limits related to state machine executions and task executions.
MaxConcurrency can be configured to specify the number of child workflow executions in a Distributed Map that can run in parallel. If not specified, then Step Functions doesn’t limit concurrency and runs 10,000 parallel child workflow executions.
You can read a JSON file from a S3 bucket using ItemReader and its sub-fields. If the JSON file, from the S3 bucket, contains a nested object structure, you can select the specific node with your data set with an ItemsPointer. For example, the following input JSON file:
The following JSONata-based workflow configuration extracts a nested list of products from productUpdates/items:
For JSONPath-based workflow note that Arguments is replaced with Parameters:
The ItemReader field is not needed when your dataset is JSON data from a previous step. ItemsPointer is only applicable when the input JSON objects read from an S3 bucket. If you are using JSON as state input to a Distributed Map, then you can use the ItemsPath (for JSONPath) or Items (for JSONata) field to specify a location in the input that points to JSON array or object used for iterations.
Prerequisite
To use Step Functions Distributed Map, verify you have:
- Access to an AWS account through the AWS Management Console and the AWS Command Line Interface (AWS CLI). The AWS Identity and Access Management (IAM) user that you use must have permissions to make the necessary AWS service calls and manage AWS resources mentioned in this post. While providing permissions to the IAM user, follow the principle of least-privilege.
- AWS CLI installed and configured. If you are using long-term credentials like access keys, follow manage access keys for IAM users and secure access keys for best practices.
- Git Installed
- AWS Serverless Application Model (AWS SAM) installed
- Python 3.13+ installed
Set up and run the workflow
Run the following steps to deploy the Step Functions state machine.
- Clone the GitHub repository in a new folder and navigate to the project folder.
- Run the following commands to deploy the application.
Enter the following details:
- Stack name: Stack name for CloudFormation (for example, stepfunctions-json-array-processor)
- AWS Region: A supported AWS Region (for example, us-east-1)
- Accept all other default values.
The outputs from the sam deploy will be used in the subsequent steps.
- Run the following command to generate
product-updates.jsonfile containing a nested JSON array of sample products and upload theproduct-updates.jsonfile to the input S3 bucket. ReplaceInputBucketNamewith the value from sam deploy output. - Run the following command to start execution of the Step Functions workflow. Replace the
StateMachineArnwith the value fromsam deployoutput.The state machine reads the input
product-updates.jsonfile and invokes a Lambda function to update the database for every product in the array after adding price and stock information. The execution metadata is also uploaded into the results bucket.
Monitor and verify results
Run the following steps to monitor and verify the test results.
- Run the following command to get the details of the execution. Replace
executionArnwith your state machine ARN.Wait until the status shows
SUCCEEDED. - Run the following commands to validate the processed output from
ProductCatalogTableNameDynamoDB table. Replace the valueProductCatalogTableNamewith the value from sam deploy output. - Check that the DynamoDB table contains the enriched product data including price and stock attributes. Example output:
Clean up
To avoid costs, remove all resources you’ve created while following along with this post.
Run the following command after replacing the <placeholder> variable to delete the resources you deployed for this post’s solution:
Conclusion
In this post, you learned how to use Step Functions Distributed Map for extracting array data natively from JSON objects stored in a S3 bucket. By removing custom data extraction code, you can simplify the processing of your large-scale parallel workloads. With ItemsPointer you can extract array data within JSON files stored in a S3 bucket , and with Items(JSONata) or ItemsPath (JSONPath), you can extract arrays from complex JSON state input, adding flexibility to your workflow designs.
New input sources for Distributed Map are available in all commercial AWS Regions where AWS Step Functions is available. For a complete list of AWS Regions where Step Functions is available, see the AWS Region Table. To get started, you can use the Distributed Map mode today in the AWS Step Functions console. To learn more, visit the Step Functions developer guide.
For more serverless learning resources, visit Serverless Land.