Amazon Web Services ブログ
Amazon MWAA における Airflow ワーカープール最適化ガイド
本記事は、2026 年 5 月 1 日 に公開された A guide to Airflow worker pool optimization in Amazon MWAA を翻訳したものです。翻訳はクラウドサポートエンジニアの山本が担当しました。
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) は、AWS のフルマネージド Apache Airflow サービスです。Amazon MWAA で Airflow ワーカープールの設定を最適化することは、ワークフロー運用をスケールするうえで重要でありながら見過ごされやすいポイントです。タスクが長時間キューに滞留している場合、ワーカー不足が原因だと考えがちですが、実際には別の根本原因が潜んでいることがあります。スケールの判断は単純ではありません。DevOps エンジニアやシステム管理者は、ワーカーを追加すればパフォーマンスの問題が解決するのか、それとも根本原因に対処せずに運用コストが増えるだけなのかを見極める必要があります。
本記事では、Amazon MWAA におけるワーカースケーリングの判断パターンを、タスクプールの仕組みとワーカー割り当ての関係に焦点を当てて解説します。具体的なシナリオと実践的な判断フレームワークを示し、ワーカーの追加がパフォーマンス課題の適切な解決策かどうか、また適切な場合にどうスケーリングを実装するかの指針を提供します。
主なパターン
本セクションでは、ワーカーの追加が必要かどうかを検討するきっかけとなる、代表的な問題パターンを紹介します。
高い CPU 使用率
Airflow は、外部サービス上のタスク実行を調整・スケジュールするワークフロー管理プラットフォームです。AWS Glue、AWS Batch、Amazon EMR など、さまざまなデータ処理システム間のタスクをトリガーおよびモニタリングする中央オーケストレーターとして機能します。Airflow の強みは、データ処理そのものではなく、複数のシステムやサービス間でタスクの依存関係や実行順序を管理できる点にあります。
分析やビッグデータ基盤では、リソースが飽和すると自動的に容量の追加が必要だという誤解がよくあります。しかし Amazon MWAA では、スケーリングの判断に先立って、ワークフローの特性と最適化の余地を理解することが重要です。
ワークフローの規模が拡大すれば、Airflow クラスターのリソース使用率は当然高くなります。ワーカーが常にフル稼働している状況では、コンピューティングリソースの追加が最も手早い対処に見えるかもしれません。しかし、リソース追加は根本的な問題を解決するのではなく、問題を先送りにしてしまうだけです。
たとえば、Amazon MWAA で単一のタスクがワーカーの利用可能な CPU を 100% 消費している場合、ワーカーを追加しても問題は解決しません。タスクが最適化されていないか、より小さな部分に分割されていないためです。そのため、最小ワーカー数を増やしても期待した効果は得られず、運用コストが増加するだけです。
Amazon MWAA ワーカーの CPU またはメモリ使用率が常に 90% を超えている場合、重要な判断ポイントに達しています。対策を講じる前に、根本原因の理解が不可欠です。主に 3 つの対策があります。
- 水平スケーリング: ワーカーを追加して負荷を分散する。
- 垂直スケーリング: より大きな環境クラスにアップグレードして、ワーカーあたりのリソースを増やす。
- DAG とスケジューリングパターンの最適化: 効率を高めリソース消費を削減する。
各アプローチは異なる根本的な問題に対処するものであり、容量の制約、リソース集約型のタスク設計、ワークフローの非効率のいずれに直面しているかを特定したうえで適切な方法を選択します。最適化戦略のガイダンスについては、Performance tuning for Apache Airflow on Amazon MWAA を参照してください。
ワーカーの CPUUtilization と MemoryUtilization をモニタリングするには、Accessing metrics in the Amazon CloudWatch console を参照し、対応するメトリクスを選択してください。
- 使用パターンを確認できる十分な時間枠を選択する。
- 期間を 1分 に設定する。
- 統計を 最大 に設定する。
長いキュー待ち時間
Airflow タスクがキュー状態で長時間滞留し、DAG が予定通りに完了しないことがあります。
Amazon MWAA では、各環境クラスに最小および最大ワーカーノード数が設定されています。各ワーカーには事前設定された同時実行数があり、任意の時点で各ワーカーが同時に実行できるタスク数を表します。この動作は celery.worker_autoscale=(max,min) で制御されます。
たとえば、最小 4 台の mw1.small ワーカーがあり、デフォルトの Airflow 設定の場合、20 個のタスクを同時実行できます (4 ワーカー × 5 max_tasks_per_worker)。システムが突然 20 を超えるタスクの同時実行を必要とすると、オートスケーリングイベントが発生します。Amazon MWAA はワーカーを効率的にスケールする方法を決定し、プロセスをトリガーします。ただし、オートスケーリングプロセスには新しいワーカーのプロビジョニングに追加の時間が必要なため、キュー状態のタスクが増加します。キューイングの問題を軽減するには、以下を検討してください。
- ワーカーの CPU 使用率が低い場合、
celery.worker_autoscale=(max,min)のmax値を増やすと、各ワーカーがより多くのタスクを同時処理できるため、タスクのキュー滞留時間を短縮できます。Airflow ワーカーは、自身のシステムリソースの空き状況に関係なく、定義されたタスク同時実行数までタスクを受け取れます。その結果、オートスケーリングが作動する前にワーカーの CPU/メモリ使用率が 100% に達する可能性があります。 - ワーカーのタスク同時実行数を増やしたくない場合、最小ワーカー数を増やすことも有効です。利用可能なワーカーが増えることで、より多くのタスクを同時実行できるようになります。
スケジューリングの遅延
新しい DAGの追加は、システムリソースに影響するだけでなく、スケジューリングのばらつきを発生させる可能性があります。環境全体のメトリクスが正常に見えても、リソースの競合によって一部の DAGの実行が遅延することがあります。このばらつきは、特定のタスクが常にキューで長く待機する一方、他のタスクはすぐに実行されるといった状況が発生します。
Amazon CloudWatch メトリクスで、特に DAG の実行数が多い期間において、実行開始時間のばらつきが増加している場合、環境の最適化が必要です。実行パターンとリソース使用率を分析した上で、以下を判断してください。
- ワーカーの追加はワークロードの分散に役立ちますが、高いリソース使用率が DAG のパースやスケジューリングのオーバーヘッドではなく、主にタスク実行の負荷によるものである場合に最も効果的です。最小ワーカー数を増やすと、より多くのタスクを並列実行できます。たとえば、
AWS/MWAA/ApproximateAgeOfOldestTaskの値が着実に増加している場合、ワーカーがキューからのメッセージを十分な速度で消費できていないことを意味します。さらに、AWS/MWAA/QueuedTasksをモニタリングして同様のパターンを特定することもできます。 - 環境クラスのアップグレードにより、スケジューリング容量が向上します。スケジューラーに負荷の兆候が見られる場合や、すべてのコンポーネントでリソース使用率が高い場合は、より大きな環境クラスへのアップグレードが最適な解決策かもしれません。スケジューラーとワーカーの両方により多くのリソースが提供され、DAG の複雑さとボリュームの増加に対応できます。検証するには、
AWS/MWAA/CPUUtilizationとAWS/MWAA/MemoryUtilizationのクラスターメトリクスでScheduler、BaseWorker、AdditionalWorkerメトリクスを選択してください。 - DAG スケジュールの再構成により、リソース競合を削減する。
重要なのは、ワークフローパターンを理解し、スケジューリングの遅延がワーカー容量の不足によるものか、その他の環境上の制約によるものかを特定することです。
アンチパターン
ワーカーを追加することでパフォーマンスが改善するという誤った結論につながりやすい、よくあるアンチパターンを紹介します。
稼働率の低いワーカー
Amazon MWAA のパフォーマンスボトルネックを評価する際は、環境をスケールアップする前に、リソース制約と DAG 設計の非効率を区別することが重要です。
Amazon MWAA 環境が 100 タスクを同時実行できる容量を持っていても、キューメトリクス (AWS/MWAA/RunningTasks) ではほとんどの時間で 20 タスクしかアクティブでなく、キュー状態のタスクも残っていないことがあります。その場合、ピークワークロード時に既存ワーカーの CPU とメモリ使用率が常に低いかどうかを Amazon CloudWatch で確認してください。リソース使用率が低い場合、通常は DAG 設計、スケジューリングパターン、または Airflow 設定が非効率であることを示しています。
対処には主に 2 つの選択肢があります。
1. ダウンサイズ: ワークロードの増加が見込まれない場合、クラスターが過剰にプロビジョニングされていると判断できます。まず余分なワーカーを削除し、最終的に環境クラスのダウンサイズを検討してください。
2. 最適化: プールや同時実行数の Airflow 設定を通じて DAG スケジューリングを調整し、システムのスループットを向上させてください。
人為的なボトルネックを生む Airflow 設定の誤り
Apache Airflow では、実際のリソース制約ではなく設定によってパフォーマンスボトルネックが発生することがよくあります。コンピューティングリソースの不足ではなく、同時実行数の設定ミスによって DAG の実行が遅延します。
Amazon MWAA を効率的に使用するには、ワーカーとスケジューラーのリソース使用率だけでなく、人為的なボトルネックとなる同時実行数設定も確認する必要があります。1 つの制限的な設定が、より大きな環境や追加ワーカーのスケーリング効果を打ち消してしまうことがあります。システムメトリクスに余裕があるにもかかわらずパフォーマンスが制限されている場合は、Airflow 設定を監査してください。
重要な考慮事項: Amazon MWAA は、環境クラスを変更してもワーカーの同時実行数設定を自動的に更新しません。スケーリング時にこの動作を理解しておくことが重要です。最初に mw1.small 環境を作成した場合、各ワーカーはデフォルトで最大 5 つの同時タスクを処理できます。medium 環境クラス (デフォルトでワーカーあたり 10 の同時タスクをサポート) にアップグレードしても、インプレース更新された環境では同時実行数の設定は 5 のままです。新しい環境クラスの容量を最大限に活用するには、同時実行数の設定を手動で更新する必要があります。
このため、環境クラスを更新する際は、同時実行数を制御する Airflow 設定も更新する必要があります。環境クラスのアップグレード後に同時実行数の設定を更新するには、Apache Airflow 設定オプションの celery.worker_autoscale 設定を変更してください。ワーカーが新しい環境クラスでサポートされる最大同時タスク数を処理できるようになります。
また、Amazon MWAA 環境が実際のリソース制限ではなく、max_active_runs や DAG 同時実行数の制御によって制約されている場合もあります。設定ベースのスロットルは、ワーカーインスタンスにワークロードを処理する利用可能なコンピューティングリソースがあっても、タスクの実行を妨げます。
この 2 つには重要な違いがあります。設定による制限は並列処理の人為的な上限として機能し、真のリソース制限はワーカーが CPU またはメモリ容量をフルに使用していることを示します。どちらの制約が環境に影響しているかを理解することで、設定を調整すべきかインフラストラクチャをスケールすべきかを判断できます。
プール、同時実行数、max_active_runs などの Airflow 設定を調整することで、ワーカーをスケールせずにパフォーマンスの問題を解決できます。制御に使用できる設定の一部を以下に示します。
- max_active_runs_per_dag (DAG レベル): 特定の DAG について同時に許可される DAG 実行数を制御します。2 に設定すると、ワーカー容量に余裕があっても同時に 2 つの DAG 実行しか実行できません。追加の実行はキューに入り、ワーカーがアイドル状態でも DAG の実行が遅くなります。
- max_active_tasks: DAG 定義の concurrency フィールド (または環境レベルの設定) を制御し、システム全体の容量やワーカー数に関係なく、その DAG から同時に実行されるタスク数を制限します。
- プール: プールは、特定の種類 (多くの場合リソース集約型) のタスクが同時に実行できる数を制限します。3 スロットのプールは、そのプールに割り当てられた 3 を超えるタスクをスロットルし、ワーカーをアイドル状態にします。
- 実行タイムアウトとリトライ: 適切に調整されていない場合、失敗したタスクが不必要にスロットを占有し、スタックしたタスクがワーカースロットをブロックしてキュー処理を遅延させる可能性があります。
- スケジューリング間隔と依存関係: 重複する非効率なスケジューリングは、アイドル期間やリソースの過度な競合を引き起こし、実際のスループットに影響する可能性があります。
Airflow 設定の相互上書き
Airflow には、同時実行数とスケジューリングを制御する複数のレイヤーがあります。環境レベル、DAG/タスクレベル、プール用のものがあります。より制限的な設定がより許容的な設定を上書きし、予期しないキューの蓄積を引き起こすことがあります。
DAG レベル vs 環境レベル: “max_active_runs_per_dag” (DAG レベル) が環境レベルの “max_active_runs_per_dag” やシステム全体の同時実行数より低い場合、DAG の設定が使用され、環境がより多くの処理を行えるにもかかわらずタスクがスロットルされます。
タスクレベルの上書き: 個々のタスク定義には “max_active_tis_per_dag” などの独自のパラメータを設定でき、グローバル設定より低く設定するとボトルネックを生み出す可能性があります。
優先順位: 任意のレベル (環境、DAG、タスク) で最も制限的な設定が、並列タスク実行の上限を実質的に決定します。
| 設定場所 | 設定 | タスクスループットへの影響 |
| 環境レベル | parallelism | スケジューラーで実行される最大タスク総数 |
| DAG レベル | max_active_runs | 同時 DAG 実行の最大数 |
| タスクレベル | concurrency | その DAG の最大同時タスク数 |
パフォーマンスの問題はリソース枯渇のように見えることが多いですが、実際には過度に制限的な設定に起因しています。上記のパラメータをすべて慎重に監査してください。制限的な値を段階的に緩和し、クラスターのスケールを決定する前に効果をモニタリングできます。アイドル容量に対して支払うことなく、クラウドリソースを最適かつコスト効率よく使用できます。
メモリリークによる緩やかなリソース枯渇
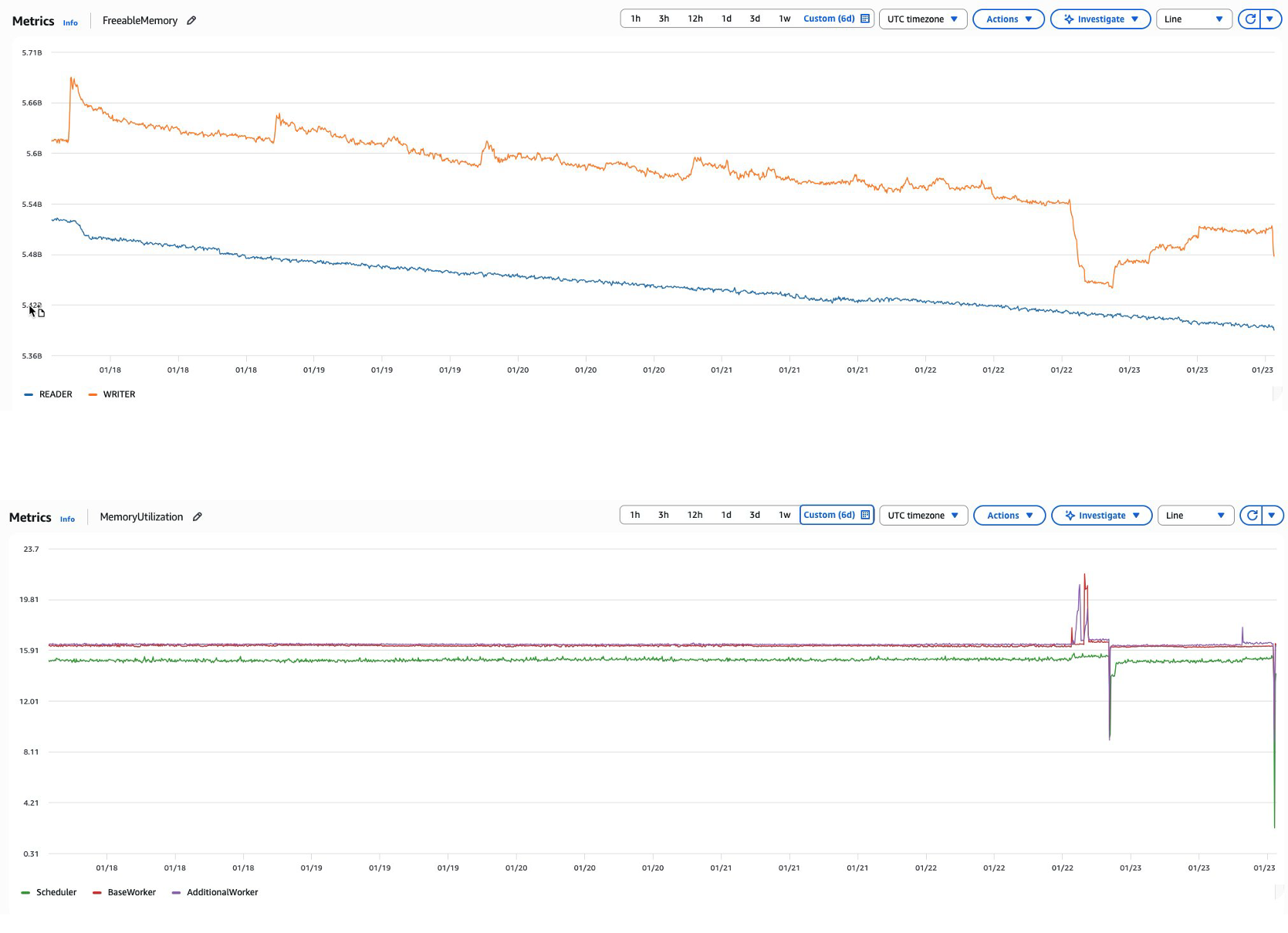
Amazon MWAA でメモリリークや緩やかなリソース枯渇が発生する一般的なシナリオは、DAG やタスクが時間の経過とともに失敗したり遅くなったりする場合です。ワーカーのスケールや環境サイズの拡大では根本的な問題は解決しません。根本原因は容量不足ではなく、持続的な枯渇を引き起こすアプリケーションレベルのリークであるためです。
たとえば、Airflow がタスクの実行と DAG のパースを継続的に行うと、環境全体のメモリ消費が着実に増加する可能性があります。ワークロードが一定または減少しているにもかかわらず、Amazon MWAA メタデータデータベースの FreeableMemory メトリクスが低下するという形で現れることがあります。メモリリソースがスケジューラー/ワーカーおよびメタデータデータベースで制約されると、データベースクエリのパフォーマンスが徐々に低下し、Airflow はメタデータデータベースに重要な操作を大きく依存しているため、最終的に環境全体の応答性に影響します。アプリケーションがデータベース接続を適切に閉じずに作成し、リソース枯渇に至るのと似た状況です。
グラフ: FreeableMemory と MemoryUtilization の低下(上: メタデータデータベース、下: スケジューラー及びワーカー)
一般的な原因:
- コネクションプールの枯渇: データベース接続を適切に閉じない DAG は、コネクションプールの枯渇とデータベースのメモリリークを引き起こす可能性があります。
- リソース集約型の操作: メタデータデータベースに対する複雑で長時間実行されるクエリや XCOM 操作は、過剰なメモリを消費する可能性があります。
- 非効率な DAG 設計: トップレベルに多数の Python 呼び出しを持つ DAG は、DAG パース中にデータベースクエリをトリガーする可能性があります。たとえば、タスクレベルではなく DAG レベルで variable.get() を呼び出すと、不要なデータベースの負荷が発生します。
推奨される解決策:
- Amazon CloudWatch モニタリングの実装: FreeableMemory に適切なしきい値で Amazon CloudWatch アラームを設定し、問題を早期に検出する。
- 定期的なデータベースメンテナンス: 不要になった履歴データをパージするスケジュールされたデータベースクリーンアップ操作を実行する。
- DAG コードの最適化: variable.get() などのデータベース操作を DAG レベルからタスクレベルに移動するよう DAG をリファクタリングし、パースのオーバーヘッドを削減する。
- 接続管理: すべてのデータベース接続が使用後に適切に閉じられるようにし、コネクションプールの枯渇を防止する。
上記の推奨事項に従うことで、メタデータデータベースのメモリ使用率を健全に維持し、ワーカーをスケールせずに Amazon MWAA 環境の最適なパフォーマンスを維持できます。
まとめ
Amazon MWAA 環境でワーカーを追加する判断には、単純なタスクキューメトリクスを超えた複数の要因の検討が必要です。本記事では、ワーカーの追加が特定のパフォーマンス課題に対処できる一方で、システムボトルネックへの最適な最初の対応ではないことが多い点を示しました。
ワーカーをスケールする前に考慮すべき重要なポイント:
- 根本原因の分析
- 高い CPU/メモリ使用率がタスク最適化の問題に起因するかどうかを確認する。
- キューイングの問題がリソース制限ではなく設定の制約に起因するかどうかを調べる。
- メモリリークやリソース枯渇のパターンがないか調査する。
- 設定の最適化
- Airflow パラメータ (同時実行数の設定、プール、タイムアウト) を確認・調整する。
- 異なる設定レイヤー間の相互作用を理解する。
- DAG 設計とスケジューリングパターンを最適化する。
最も成功している Amazon MWAA の実装は、体系的なアプローチに従っています。まず既存のリソースと設定を最適化し、データに基づくキャパシティプランニングで正当化された場合にのみワーカーをスケールします。信頼性の高いワークフローパフォーマンスを維持しながら、コスト効率の高い運用が実現します。
ワーカーのスケーリングは、Amazon MWAA 最適化ツールキットの 1 つのツールにすぎません。長期的な成功は、適切なモニタリング、プロアクティブなキャパシティプランニング、Airflow ワークフローの継続的な最適化を組み合わせたパフォーマンス管理戦略の構築にかかっています。
次の記事では、環境に追加の DAG を投入する前に実行すべきキャパシティプランニングの手順について説明します。追加の負荷に対する計画を立て、十分なヘッドルームを確保する方法を解説します。
開始するには、Amazon MWAA の製品ページと Performance tuning for Apache Airflow on Amazon MWAA ページをご覧ください。
ご質問がある場合や MWAA のスケーリング経験を共有したい場合は、以下にコメントを残してください。