AWS Big Data Blog
A guide to Airflow worker pool optimization in Amazon MWAA
Optimizing the Airflow worker pool configuration in Amazon Managed Workflows for Apache Airflow (Amazon MWAA), the AWS fully managed Apache Airflow service, is an important yet often overlooked strategy for scaling workflow operations. Tasks queued for longer periods can create the illusion that additional workers are the solution, when in reality the root cause might lie elsewhere. The decision to scale isn’t always straightforward. DevOps engineers and system administrators frequently face the challenge of determining whether adding more workers will solve their performance issues or only increase operational cost without addressing the root cause.
This post explores different patterns for worker scaling decisions in Amazon MWAA, focusing on the task pool mechanism and its relationship to worker allocation. By examining specific scenarios and providing a practical decision framework, this post helps you determine whether adding workers is the right solution for your performance challenges, and if so, how to implement this scaling effectively.
Main patterns
This section discusses the most frequently seen problems that raise the question if adding additional workers would improve the health of your environment.
High CPU
Airflow serves as a workflow management platform that coordinates and schedules tasks to be run on external processing services. It acts as a central orchestrator that can trigger and monitor tasks across various data processing systems like AWS Glue, AWS Batch, Amazon EMR, and other specialized data processing tools. Rather than processing data itself, Airflow’s strength lies in managing complex workflows and coordinating jobs between different systems and services.
In Analytics and Big Data environments, there is a prevalent misconception that saturated resources automatically warrant adding more capacity. However, for Amazon MWAA, understanding your workflow characteristics and optimization opportunities should precede scaling decisions.
As you scale up your workflows, resource utilization of the Airflow clusters naturally increases. When workers consistently operate at full capacity, it may seem intuitive to add additional compute resources. However, this approach often masks underlying inefficiencies rather than resolving them.
For example, in Amazon MWAA if you are running a single task that is consuming 100% of the available CPU on your Amazon MWAA worker, adding additional workers will not resolve the problem as the task is not optimized nor split into smaller parts. As such, increasing the number of minimum workers will not bring the expected effect but will only increase the operating costs.
When your Amazon MWAA workers are consistently running above 90% CPU or Memory utilization, you’ve reached a critical decision point. Before taking actions, it is essential to understand the root cause. You have three primary options:
- Scale horizontally by adding additional workers to distribute the load.
- Scale vertically by upgrading to a larger environment class for more resources per worker.
- Optimize your DAGs and scheduling patterns to be more efficient and consume fewer resources.
Each approach addresses different underlying issues, and choosing the right path depends on identifying whether you are facing a capacity constraint, resource-intensive task design, or workflow inefficiency. For guidance on optimization strategies, please refer to Performance tuning for Apache Airflow on Amazon MWAA.
To monitor the CPUUtilization and MemoryUtilization on the workers, refer to the Accessing metrics in the Amazon CloudWatch console and choose the corresponding metrics.
- Select a time window long enough to show usage patterns.
- Set period to 1 Minute.
- Set statistics to Maximum.
Long queue time
Sometimes Airflow tasks are stuck in a queued state for a long time, which prevents DAGs from completing on time.
In Amazon MWAA, each environment class comes with configured minimum and maximum worker nodes. Each worker provides a pre-configured concurrency, which is the number of tasks that can run simultaneously on each worker at any given time. The behavior is controlled through celery.worker_autoscale=(max,min).
For example, if you have minimum 4 mw1.small workers, with default Airflow configuration, you will be able to run 20 concurrent tasks (4 workers x 5 max_tasks_per_worker). If your system suddenly requires more than 20 tasks to execute concurrently, this will result in an autoscaling event. Amazon MWAA will decide how to scale your workers efficiently, and trigger the process. The autoscaling process, however, requires additional time to provision new workers resulting in additional tasks in queued status. To mitigate this queuing issue, consider the following:
- If the CPU utilization on the workers is low, increasing the
maxvalue incelery.worker_autoscale=(max,min)can reduce the time tasks stay in queued state as each worker will be able to process more tasks concurrently. Airflow worker can take tasks up to the defined task concurrency regardless of the availability of its own system resources. As a result, the base worker may reach 100% CPU/Memory utilization before Autoscaling takes effect. - If you do not want to increase the task concurrency on the workers, increasing the minimum worker count can also be beneficial because having more available workers allows a higher number of tasks to run concurrently.
Scheduling delays
Adding new DAGs can not only affect your system resources, but it can also create uneven scheduling patterns. Some DAGs may experience delayed execution because of resource competition, even when the overall environment metrics appear healthy. This scheduling skew often manifests as inconsistent task pickup times, where certain workflows consistently wait longer in the queue while others execute promptly.
When Amazon CloudWatch metrics show increasing variance in task scheduling times, particularly during periods of high DAG activity, it signals the need for environment optimization. This scenario requires careful analysis of execution patterns and resource utilization to determine if:
- While adding workers can help distribute the workload, this solution is most effective when the high utilization is primarily because of task execution load rather than DAG parsing or scheduling overhead. Adding more minimum workers will allow you to execute more tasks in parallel. For example, if you observe the value of
AWS/MWAA/ApproximateAgeOfOldestTaskto be steadily increasing, it means that the workers are not able to consume the messages from the queue fast enough. Additionally, you can also monitor theAWS/MWAA/QueuedTasksto identify similar patterns. - Upgrading the environment class would provide better scheduling capacity. If the Scheduler is showing signs of strain or if you’re seeing high resource utilization across all components, upgrading to a larger environment class might be the most appropriate solution. This provides more resources to both the Scheduler and Workers, allowing for better handling of increased DAG complexity and volume. To validate the same, use
AWS/MWAA/CPUUtilizationandAWS/MWAA/MemoryUtilizationin the Cluster metrics and chooseScheduler,BaseWorkerandAdditionalWorkermetrics. - Restructuring DAG schedules would reduce resource contention.
The key is to understand your workflow patterns and identify whether the scheduling delays are because of insufficient worker capacity or other environmental constraints.
Anti patterns
This section showcases the most common anti patterns which make MWAA users think that adding more workers will improve performance.
Underutilized workers
When evaluating Amazon MWAA performance bottlenecks, it’s important to distinguish resource constraints and DAG design inefficiencies before scaling the environment.
Sometimes the Amazon MWAA environment has the capacity to run 100 tasks concurrently but your queue metrics (AWS/MWAA/RunningTasks) show only 20 tasks active most of the time with no tasks remaining in queued state. In such scenarios, you are advised to check Amazon CloudWatch for consistently low CPU and memory usage on existing workers during peak workload times. If this is confirmed, it is usually an indication of inefficiencies in DAG design, scheduling patterns, or Airflow configuration.
You have two primary options to address this:
1. Downsize: If you do not expect your workload to increase, it is safe to assume you have over-provisioned your cluster. Start by removing any extra workers first and finally resolve to downsizing your environment class.
2. Optimize: Fine tune your DAG scheduling and airflow configuration through Pools and Airflow configuration for concurrency to increase the throughput of your system.
Misconfigured Airflow configurations that create artificial bottlenecks
In Apache Airflow, performance bottlenecks often occur because of configuration settings, not actual resource constraints. At such times, DAG executions get delayed not because of insufficient compute, but because of incorrect concurrency configuration.
Efficient use of Amazon MWAA requires reviewing not only resource utilization for Workers and Schedulers but also concurrency configurations for artificially created bottlenecks. Sometimes one restrictive configuration prevents the scaling benefits of larger environment or additional workers. Always audit Airflow configurations if performance seems limited even when system metrics suggest spare capacity.
Important consideration: Amazon Managed Workflows for Apache Airflow (Amazon MWAA) does not automatically update the worker concurrency configuration when you change the environment class. This behavior is important to understand when scaling your environment. If you initially create an mw1.small environment, where each worker can handle up to 5 concurrent tasks by default. When you upgrade to a medium environment class (which supports 10 concurrent tasks per worker by default), the concurrency setting remains at 5 for in-place updated environments. You must manually update the concurrency configuration to take full advantage of the increased capacity available in the medium environment class.
Because of this you need to also update the Airflow configurations that control concurrency whenever you update the environment class. To update the concurrency setting after upgrading your environment class, modify the celery.worker_autoscale configuration in your Apache Airflow configuration options. This makes sure your workers can process the maximum number of concurrent tasks supported by your new environment class.
Other times, an Amazon MWAA environment can be constrained by max_active_runs or DAG concurrency controls instead of actual resource limits. These configuration-based throttles prevent tasks from running, even when the worker instances have available compute to handle the workload.
There is an important distinction between the two. Configuration limits act as artificial caps on parallelism, while true resource limits indicate that workers are fully utilizing their CPU or memory capacity. Understanding which type of constraint affects your environment helps you determine whether to adjust configuration settings or scale your infrastructure.
Adjusting Airflow configurations such as Pools, concurrency, max_active_runs solves performance problems without scaling workers. Some of the configurations you can use to control this behavior:
- max_active_runs_per_dag (DAG level): Controls how many DAG runs for a given DAG are allowed at the same time. If set to 2, only 2 DAG runs can run concurrently, even if there is plenty of worker capacity left. Extra runs queue, making the DAG executions slow even though workers are idle.
- max_active_tasks:Controls the concurrency field in a DAG definition (or setting at environment level) limits the number of tasks from the DAG running at any moment, regardless of overall system capacity or number of workers.
- Pools:Pools restrict how many tasks of a certain type (often resource heavy) can run at once. A pool with only 3 slots will throttle any tasks above 3 assigned to that pool, leaving workers idle.
- Execution timeouts and retries: If not tuned, failed tasks might fill up slots unnecessarily, stuck tasks can block worker slots and slow queue processing.
- Scheduling intervals and dependencies: Overlapping or inefficient scheduling may cause idle periods or excess contention for resources, affecting real throughput.
How Airflow configurations can override each other
Airflow has multiple layers of concurrency and scheduling controls. Some at the environment level, some at the DAG/task level, and others for pools. Sometimes more restrictive settings override more permissive ones, resulting in unexpected queue buildup.
DAG level vs Environment level: If “max_active_runs_per_dag” (DAG level) is lower than the environment-level “max_active_runs_per_dag” or system wide concurrency, the DAG setting is used, throttling tasks even if the environment could do more.
Task level overrides: Individual task definitions can have their own parameters like “max_active_tis_per_dag” which can cap runs per task and create a bottleneck if set lower than global settings.
Order of precedence: The most restrictive relevant configuration at any level (Environment, DAG, Task) effectively sets the upper bound for parallel task execution.
| Setting Location | Setting | Effect on task throughput |
| Environment Level | parallelism | Max total tasks running on Scheduler |
| DAG Level | max_active_runs | Max simultaneous DAG runs |
| Task Level | concurrency | Max concurrent task for that DAG |
Performance issues often resemble resource exhaustion, but actually derive from overly restrictive configurations. Audit all the preceding parameters carefully. You can loosen restrictive values step by step and monitor their effect before deciding to scale your cluster further. This approach ensures optimal and cost-efficient usage of your cloud resources without paying for idle capacity.
Slow resource depletion from memory leaks
A common scenario for memory leak or slow resource depletion in Amazon MWAA is when DAGs and tasks begin to fail or slow down over time. Scaling workers or increasing environment size does not resolve the underlying issue. This happens because the root cause is not a lack of capacity but rather an application-level leak that causes persistent exhaustion.
For example, as Airflow continuously runs tasks and parses DAGs over time, memory consumption can steadily increase across the environment. This might manifest as an Amazon MWAA metadata database experiencing declining FreeableMemory metrics despite consistent or even reduced workloads. When this occurs, database query performance gradually declines as memory resources become constrained for scheduler/worker & metadata database, ultimately affecting overall environment responsiveness since Airflow depends heavily on its metadata database for critical operations. This scenario is similar to how an application might create database connections without properly closing them, leading to resource exhaustion over time.
Graph: Declining FreeableMemory and MemoryUtilization
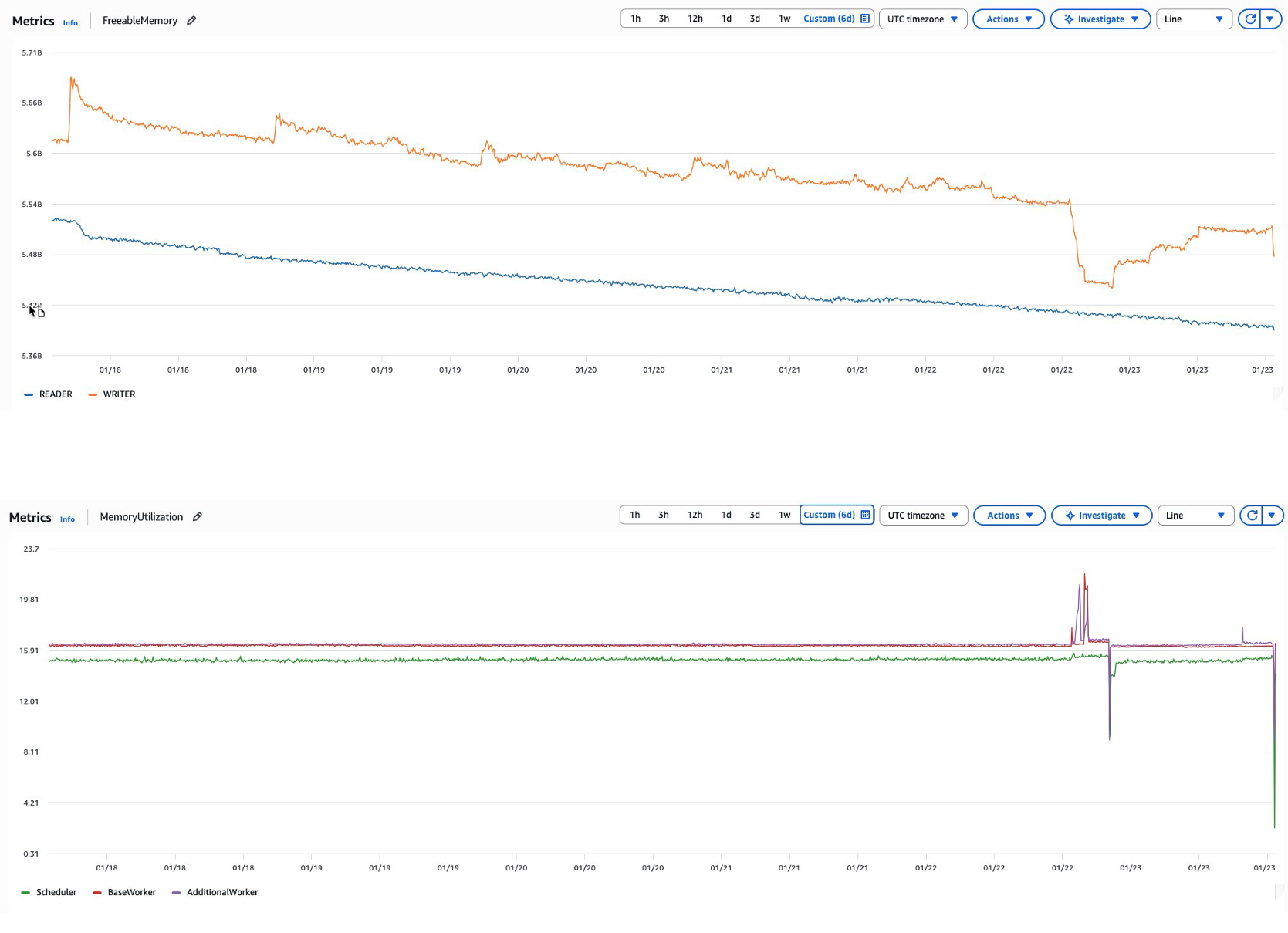
Common causes:
- Connection pool exhaustion: DAGs that fail to properly close database connections can lead to connection pool exhaustion and memory leaks in the database.
- Resource-intensive operations: Complex, long-running queries or XCOM operations against the metadata database can consume excessive memory.
- Inefficient DAG design: DAGs with numerous top-level Python calls can trigger database queries during DAG parsing. For instance, using variable.get() calls at the DAG level rather than at the task level creates unnecessary database load.
Recommended solutions:
- Implement Amazon CloudWatch monitoring: Establish Amazon CloudWatch alarms for FreeableMemory with appropriate thresholds to detect issues early.
- Regular database maintenance: Perform scheduled database clean-up operations to purge historical data that is no longer needed.
- Optimize DAG code: Refactor DAGs to move database operations like variable.get() from the DAG level to the task level to reduce parsing overhead.
- Connection management: Make sure all database connections are properly closed after use to prevent connection pool exhaustion.
By following the preceding recommendations you can maintain healthy memory utilization for the metadata database and maintain optimal performance of your Amazon MWAA environment without needing to scale workers.
Conclusion
The decision to add workers in Amazon MWAA environments requires careful consideration of multiple factors beyond simple task queue metrics. In this post, we showed that while adding workers can address certain performance challenges, it’s often not the optimal first response to system bottlenecks.
Key considerations before scaling workers include:
- Root cause analysis
- Verify whether high CPU/memory usage stems from task optimization issues.
- Examine if queuing problems result from configuration constraints rather than resource limitations.
- Investigate potential memory leaks or resource depletion patterns.
- Configuration optimization
- Review and adjust Airflow parameters (concurrency settings, pools, timeouts).
- Understand the interaction between different configuration layers.
- Optimize DAG design and scheduling patterns.
The most successful Amazon MWAA implementations follow a systematic approach: first optimizing existing resources and configurations, then scaling workers only when justified by data-driven capacity planning. This approach ensures cost-effective operations while maintaining reliable workflow performance.
Remember that worker scaling is only one tool in the Amazon MWAA optimization toolkit. Long-term success depends on building a comprehensive performance management strategy that combines proper monitoring, proactive capacity planning, and continuous optimization of your Airflow workflows.
In the next post, we discuss capacity planning and the steps you need to perform before adding additional DAGs in your environment so that you can plan for the additional load and make sure you have enough headroom.
To get started, visit the Amazon MWAA product page and the Performance tuning for Apache Airflow on Amazon MWAA page.
If you have questions or want to share your MWAA scaling experiences, leave a comment below.