AWS Big Data Blog
Tag: EMR

Detect and resolve HBase inconsistencies faster with AI on Amazon EMR
In this post, we show you how to build an AI-powered troubleshooting solution using Amazon OpenSearch Service vector search and intelligent analysis. This solution reduces HBase inconsistency resolution from hours to minutes and root cause identification from days to hours through natural language queries over operational data. This democratizes HBase troubleshooting capabilities across teams and reducing dependency on specialized expertise.

A guide to Airflow worker pool optimization in Amazon MWAA
Optimizing the Airflow worker pool configuration in Amazon Managed Workflows for Apache Airflow (Amazon MWAA), the AWS fully managed Apache Airflow service, is an important yet often overlooked strategy for scaling workflow operations. Tasks queued for longer periods can create the illusion that additional workers are the solution, when in reality the root cause might […]

Build incremental data pipelines to load transactional data changes using AWS DMS, Delta 2.0, and Amazon EMR Serverless
Building data lakes from continuously changing transactional data of databases and keeping data lakes up to date is a complex task and can be an operational challenge. A solution to this problem is to use AWS Database Migration Service (AWS DMS) for migrating historical and real-time transactional data into the data lake. You can then […]

Apache Hive is 2x faster with Hive LLAP on EMR 6.0.0
Customers use Apache Hive with Amazon EMR to provide SQL-based access to petabytes of data stored on Amazon S3. Amazon EMR 6.0.0 adds support for Hive LLAP, providing an average performance speedup of 2x over EMR 5.29, with up to 10x improvement on individual Hive TPC-DS queries. This post shows you how to enable Hive […]

How Verizon Media Group migrated from on-premises Apache Hadoop and Spark to Amazon EMR
This is a guest post by Verizon Media Group. At Verizon Media Group (VMG), one of the major problems we faced was the inability to scale out computing capacity in a required amount of time—hardware acquisitions often took months to complete. Scaling and upgrading hardware to accommodate workload changes was not economically viable, and upgrading […]
Install Python libraries on a running cluster with EMR Notebooks
This post discusses installing notebook-scoped libraries on a running cluster directly via an EMR Notebook. Before this feature, you had to rely on bootstrap actions or use custom AMI to install additional libraries that are not pre-packaged with the EMR AMI when you provision the cluster. This post also discusses how to use the pre-installed Python libraries available locally within EMR Notebooks to analyze and plot your results. This capability is useful in scenarios in which you don’t have access to a PyPI repository but need to analyze and visualize a dataset.

Secure your Amazon EMR cluster from unintentional network exposure with Block Public Access configuration
This post discusses a new account level feature called Block Public Access (BPA) configuration that helps administrators enforce a common public access rule across all of their EMR clusters in a region.

Implement perimeter security in Amazon EMR using Apache Knox
Perimeter security helps secure Apache Hadoop cluster resources to users accessing from outside the cluster. It enables a single access point for all REST and HTTP interactions with Apache Hadoop clusters and simplifies client interaction with the cluster. For example, client applications must acquire Kerberos tickets using Kinit or SPNEGO before interacting with services on Kerberos enabled clusters. In this post, we walk through setup of Apache Knox to enable perimeter security for EMR clusters.

Run Spark applications with Docker using Amazon EMR 6.0.0 (Beta)
This post shows you how to use Docker with the EMR release 6.0.0 Beta. You’ll learn how to launch an EMR release 6.0.0 Beta cluster and run Spark jobs using Docker containers from both Docker Hub and Amazon ECR.
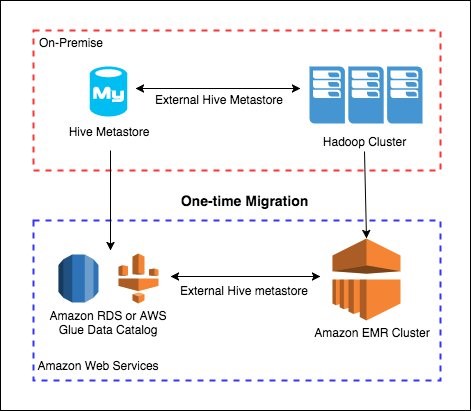
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.