AWS Big Data Blog
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.
Apache Hive is an open-source data warehouse and analytics package that runs on top of an Apache Hadoop cluster. A Hive metastore contains a description of the table and the underlying data making up its foundation, including the partition names and data types. Hive is one of the applications that can run on EMR.
Most of the solutions that this post presents assume that you use Apache Hadoop to manage your metastore, which provides scalability for Hive. If you don’t use Hadoop, see documentation for Amazon EMR.
Hive metastore deployment
You can choose one of three configuration patterns for your Hive metastore: embedded, local, or remote. When migrating an on-premises Hadoop cluster to EMR, your migration strategy depends on your existing Hive metastore’s configuration.
Bear in mind a few key facts while considering your set-up. Apache Hive ships with the Derby database, which you can use for embedded metastores. However, Derby can’t scale for production-level workloads.
When running off EMR, Hive records metastore information in a MySQL database on the master node’s file system as ephemeral storage, creating a local metastore. When a cluster terminates, all cluster nodes shut down, including that master node, which erases your data.
To get around these problems, create an external Hive metastore. This helps ensure that the Hive metadata store can scale with your implementation and that the metastore persists even if the cluster terminates.
There are two options for creating an external Hive metastore for EMR:
- Use the AWS Glue Data Catalog
- Use Amazon RDS or Amazon Aurora
Using the AWS Glue Data Catalog as the Hive metastore
The AWS Glue Data Catalog is flexible and reliable, making it a great choice when you’re new to building or maintaining a metastore. Because AWS manages the service for you, it means investing less time and resources to the process, but it also sacrifices some fine control. The Data Catalog is highly available, fault-tolerant, maintains data replicas to avoid failure, and expands hardware depending on usage.
You don’t have to manage the Hive metastore database instance separately, maintain ongoing replication, or scale up the instance. An AWS Glue Data Catalog can supply one EMR cluster or many, as well as supporting Amazon Athena and Amazon Redshift Spectrum. You can also download the source code for the AWS Glue Data Catalog client for Apache Hive Metastore and use that code as a reference implementation for building a compatible client.
AWS Glue Data Catalog still allows you plenty of control. You can enable encryption on your files, or configure action access to allow or forbid certain processes. Bear in mind that the Data Catalog doesn’t currently support column statistics, Hive authorizations, or Hive constraints.
An AWS Glue Data Catalog has versions, which means a table can have multiple schema versions. AWS Glue stores that information in the Data Catalog, including the Hive metastore data. Based on the catalog configuration, you can adopt the new schema version or ignore new versions.
When you create an EMR cluster using release version 5.8.0 and later, you can choose a Data Catalog as the Hive metastore. The Data Catalog is not available with earlier releases.
Specify the AWS Glue Data Catalog using the EMR console
When you set up an EMR cluster, choose Advanced Options to enable AWS Glue Data Catalog settings in Step 1. Apache Hive, Presto, and Apache Spark all use the Hive metastore. Within EMR, you have options to use the AWS Glue Data Catalog for any of these applications.
Specify the AWS Glue Data Catalog using the AWS CLI or EMR API
To specify the AWS Glue Data Catalog when you create a cluster in either the AWS CLI or the EMR API, use the hive-site configuration classification. Set the value of hive.metastore.client.factory.class property to com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory.
When you create an EMR cluster, save the configuration classification to a JSON file and then specify that file when you create the cluster. For more information, see Configuring Applications in the Amazon EMR Release Guide.
Using Amazon RDS or Amazon Aurora as the Hive metastore
If you want full control of your Hive metastore and want to integrate with other open-source applications such as Apache Ranger or Apache Atlas, then you can host your Hive metastore on Amazon RDS.
Always keep in mind that your Hive metastore is a single point of failure. Amazon RDS doesn’t automatically replicate databases, so you should enable replication when using Amazon RDS to avoid any data loss in the event of failure.
There are three main steps to set up your Hive metastore using RDS or Aurora:
- Create a MySQL or Aurora database.
- Configure the hive-site.xml file to point to MySQL or Aurora database.
- Specify an external Hive metastore.
Create a MySQL or Aurora database
Begin by setting up either your MySQL database on Amazon RDS or an Amazon Aurora database. Make a note of the URL, username, password, and database name, as you need all this information for the configuration process.
Update your database’s security group to allow JDBC connections between the EMR cluster and a MySQL database port (default: 3306).
Configure EMR for an external Hive metastore
To configure EMR, create a configuration file containing the following Hive site classification information:
- jdo.option.ConnectionDriverName should reflect to driver org.mariadb.jdbc.Driver (preferred driver).
- jdo.option.ConnectionURL, javax.jdo.option.ConnectionUserName and javax.jdo.option.ConnectionPassword should all point to the newly created database.
Specify an external Hive metastore
After you save your configuration, specify an external Hive metastore. You can do this with either the EMR console or the AWS CLI.
On the EMR console, enter the classification settings created in the previous step as JSON file from S3 or embedded text.
If you are using the AWS CLI, save the classification information as a file named hive-configuration.json and pass the configuration file as a local file or from S3.
- Hive-configuration.json file in local path:
aws emr create-cluster --release-label emr-5.17.0 --instance-type m4.large --instance-count 2 \
--applications Name=Hive --configurations ./hive-configuration.json --use-default-roles
- Hive-configuration.json file in Amazon S3:
aws emr create-cluster --release-label emr-5.17.0 --instance-type m4.large --instance-count 2 \
--applications Name=Hive --configurations s3://emr-sample/hive-configuration.json --use-default-roles
Hive metastore migration options
When migrating Hadoop-based workloads from on-premises to the cloud, you must migrate your Hive metastore as well. Depending on the migration plan or your requirements, you can migrate a metastore one of two ways:
- A one-time metastore migration, which moves an existing Hive metastore completely to AWS.
- An ongoing metastore sync, which migrates the Hive metastore but also keeps a copy on-premises so that the two metastores can sync in real time during the migration phase.
One-time metastore migration
A one-and-done migration option allows you to shift your workspace entirely and never worry about migrating again. This situation is perfect if you plan to run your existing Hive workloads on EMR. The following diagram illustrates this scenario.
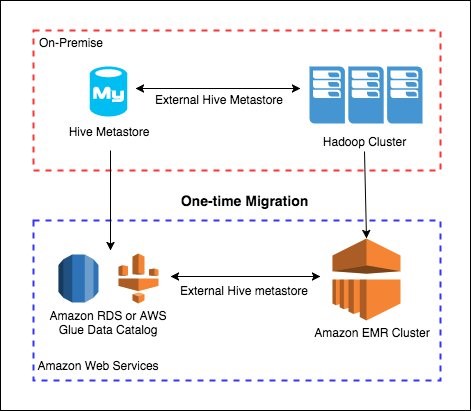
Migrating your Hive metastore to AWS Glue Data Catalog
In this case, your goal is to migrate existing Hive metastore from on-premises to an AWS Glue Data Catalog. There are multiple ways to navigate this migration, but the easiest uses an AWS Glue ETL job to extract metadata from your Hive metastore. You then use AWS Glue jobs to load the metadata and update the AWS Glue Data Catalog. Many scripts to manage this process already exist on GitHub.
Migrating your Hive metastore to Amazon RDS or Amazon Aurora
Instead of using the AWS Glue Data Catalog, you can move your Hive metastore data from an on-premises database to AWS based storage. Depending on your database source and the desired target in AWS, the process requires different steps. For more information, see the following topics:
- Migrate On-Premises MySQL Data to Amazon RDS (and back)
- Migrating Data from a MySQL DB Instance to an Amazon Aurora MySQL DB Cluster by Using a DB Snapshot
- Importing Data into PostgreSQL on Amazon RDS
- Migrating Data from an RDS PostgreSQL DB Instance to an Aurora PostgreSQL DB Cluster by Using an Aurora Read Replica
- Importing Data into Oracle on Amazon RDS
Ongoing metastore sync
Large-scale migrations benefit from an ongoing sync process, allowing you to keep running your Hive metastore in your data center as well as in the cloud during the migration phase.
The ongoing sync process keeps both Hive metastores accurate and up-to-date with any changes entered during the migration process. Use only one application for updating the Hive metastore. Otherwise, the metastore is out-of-sync.
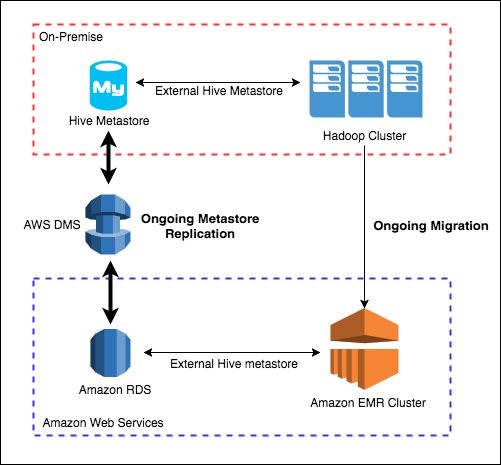
AWS DMS is a data migration service ideal for on-going replication and custom-built for this need. You can also replicate the external database to Amazon RDS using the binary log file positions of replicated transactions.
Conclusion
This post pointed you to the various existing resources that can make your Hive migration as smooth and easy as possible.
The content of this blog post is part of the EMR Migration guide, which provides a comprehensive overview of advantages and disadvantages of each migration approach of Hadoop ecosystems. To read the paper, download the Amazon EMR Migration Guide now.
If you have additional insights or feedback, leave a comment here or reach out on Twitter!
About the Author
 Tanzir Musabbir is an EMR Specialist Solutions Architect with AWS. He is an early adopter of open source Big Data technologies. At AWS, he works with our customers to provide them architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena & AWS Glue. Tanzir is a big Real Madrid fan and he loves to travel in his free time.
Tanzir Musabbir is an EMR Specialist Solutions Architect with AWS. He is an early adopter of open source Big Data technologies. At AWS, he works with our customers to provide them architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena & AWS Glue. Tanzir is a big Real Madrid fan and he loves to travel in his free time.