Amazon Web Services ブログ
Amazon Nova Multimodal Embeddings 実践ガイド
本記事は 2026 年 2 月 5 日 に公開された「A practical guide to Amazon Nova Multimodal Embeddings」を翻訳したものです。
Embedding モデルは、セマンティック検索や Retrieval-Augmented Generation (RAG)、レコメンデーションシステム、コンテンツ理解など、多くのアプリケーションを支えています。ただし、Embedding モデルの選定は慎重に行う必要があります。データを取り込んだ後に別のモデルへ移行するには、コーパス全体の再 Embedding、ベクトルインデックスの再構築、検索品質のゼロからの検証が必要になるためです。適切な Embedding モデルは、高いベースライン性能を備え、特定のユースケースに適応でき、現在および将来必要なモダリティをサポートするものです。
Amazon Nova Multimodal Embeddings モデルは、テキストや画像の単一モダリティ検索から、ドキュメント、動画、混合コンテンツにまたがる複雑なマルチモーダルアプリケーションまで、特定のユースケースに合わせた Embedding を生成します。
本記事では、Amazon Nova Multimodal Embeddings を特定のユースケースで活用する方法を説明します。
- アーキテクチャの簡素化 — クロスモーダル検索とビジュアルドキュメント検索
- パフォーマンスの最適化 — ワークロードに合わせた Embedding パラメータの選択
- 一般的なパターンの実装 — メディア検索、EC サイトでの商品発見、ドキュメント検索のソリューションウォークスルー
本ガイドでは、メディアアセット検索システム、商品発見、ドキュメント検索アプリケーション向けに Amazon Nova Multimodal Embeddings を設定する実践的な基礎を解説します。
マルチモーダルのビジネスユースケース
Amazon Nova Multimodal Embeddings は、さまざまなビジネスシナリオで活用できます。代表的なユースケースとクエリ例を次の表にまとめます。
| モダリティ | コンテンツタイプ | ユースケース | 代表的なクエリ例 |
| 動画検索 | 短い動画の検索 | アセットライブラリとメディア管理 | 「クリスマスプレゼントを開ける子供たち」「海面を突き破るシロナガスクジラ」 |
| 長い動画のセグメント検索 | 映画・エンターテインメント、放送メディア、セキュリティ監視 | 「映画の特定シーン」「ニュースの特定映像」「監視カメラの特定行動」 | |
| 重複コンテンツの特定 | メディアコンテンツ管理 | 類似・重複動画の特定 | |
| 画像検索 | テーマ別画像検索 | アセットライブラリ、ストレージ、メディア管理 | 「海岸沿いを走るサンルーフ付きの赤い車」 |
| 画像参照検索 | EC、デザイン | 「これに似た靴」+<image> |
|
| 逆画像検索 | コンテンツ管理 | アップロード画像に基づく類似コンテンツの検索 | |
| ドキュメント検索 | 特定情報のページ | 金融サービス、マーケティング資料、広告パンフレット | テキスト情報、データテーブル、チャートページ |
| ページ横断の総合情報 | ナレッジ検索の強化 | 複数ページのテキスト、チャート、テーブルからの総合的な情報抽出 | |
| テキスト検索 | テーマ別情報検索 | ナレッジ検索の強化 | 「原子炉廃炉手順の次のステップ」 |
| テキスト類似性分析 | メディアコンテンツ管理 | 重複見出しの検出 | |
| 自動トピッククラスタリング | 金融、ヘルスケア | 症状の分類と要約 | |
| 文脈関連検索 | 金融、法務、保険 | 「企業検査事故違反の最大請求額」 | |
| 音声検索 | 音声検索 | アセットライブラリとメディアアセット管理 | 「クリスマスの着信音楽」「自然で穏やかな効果音」 |
| 長い音声のセグメント検索 | ポッドキャスト、会議録音 | 「ポッドキャストのホストが神経科学と睡眠の脳への影響について議論」 |
特定のユースケースに合わせたパフォーマンス最適化
Amazon Nova Multimodal Embeddings モデルは、embeddingPurpose パラメータ設定で特定のユースケースに合わせてパフォーマンスを最適化します。ベクトル化戦略として、検索システムモードと ML タスクモードの 2 種類があります。
- 検索システムモード (
GENERIC_INDEXおよび各種*_RETRIEVALパラメータを含む) は情報検索シナリオを対象とし、ストレージ/INDEX とクエリ/RETRIEVAL の 役割の異なる 2 つのフェーズを区別します。検索システムのカテゴリとパラメータの選択方法を次の表にまとめます。
| フェーズ | パラメータの選択 | 理由 |
| ストレージフェーズ (全タイプ共通) | GENERIC_INDEX |
インデックス作成とストレージに最適化 |
| クエリフェーズ (混合モーダルリポジトリ) | GENERIC_RETRIEVAL |
混合コンテンツ内の検索 |
| クエリフェーズ (テキストのみのリポジトリ) | TEXT_RETRIEVAL |
テキストのみのコンテンツ内の検索 |
| クエリフェーズ (画像のみのリポジトリ) | IMAGE_RETRIEVAL |
画像 (写真、イラストなど) 内の検索 |
| クエリフェーズ (ドキュメント画像のみのリポジトリ) | DOCUMENT_RETRIEVAL |
ドキュメント画像 (スキャン、PDF スクリーンショットなど) 内の検索 |
| クエリフェーズ (動画のみのリポジトリ) | VIDEO_RETRIEVAL |
動画内の検索 |
| クエリフェーズ (音声のみのリポジトリ) | AUDIO_RETRIEVAL |
音声内の検索 |
- ML タスクモード (
CLASSIFICATIONおよびCLUSTERINGパラメータを含む) は機械学習シナリオを対象とします。ML タスクモードのパラメータにより、さまざまなダウンストリームタスクの要件に柔軟に対応できます。 - CLASSIFICATION: 生成されるベクトルは分類境界の識別に適しており、ダウンストリームの分類器トレーニングや直接分類に活用できます。
- CLUSTERING: 生成されるベクトルはクラスター中心の形成に適しており、ダウンストリームのクラスタリングアルゴリズムに活用できます。
マルチモーダル検索・検索ソリューションの構築ウォークスルー
Amazon Nova Multimodal Embeddings は、マルチモーダルエージェント RAG システムの基盤となるマルチモーダル検索・検索ソリューション向けに設計されています。マルチモーダル検索・検索ソリューションの構築方法を次の図に示します。
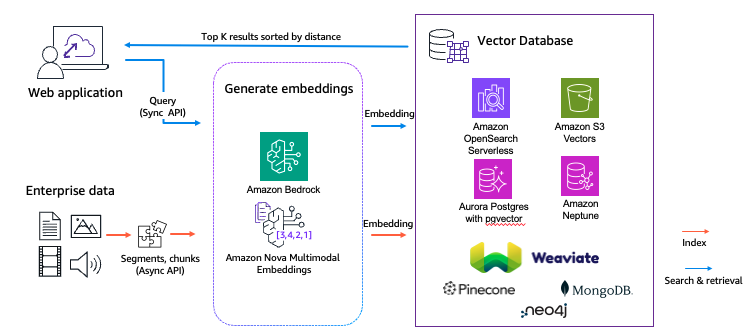
上図のマルチモーダル検索・検索ソリューションでは、テキスト、画像、音声、動画を含む生のコンテンツを、まず Embedding モデルでベクトル表現に変換し、セマンティック特徴を捉えます。次に、ベクトルをベクトルデータベースに格納します。ユーザーのクエリも同じベクトル空間内でクエリベクトルに変換されます。クエリベクトルとインデックス済みベクトル間の類似度を計算し、最も関連性の高い上位 K 件を取得します。マルチモーダル検索・検索ソリューションは Model Context Protocol (MCP) ツールとしてカプセル化でき、以下の図に示すマルチモーダルエージェント RAG ソリューション内でのアクセスが容易になります。
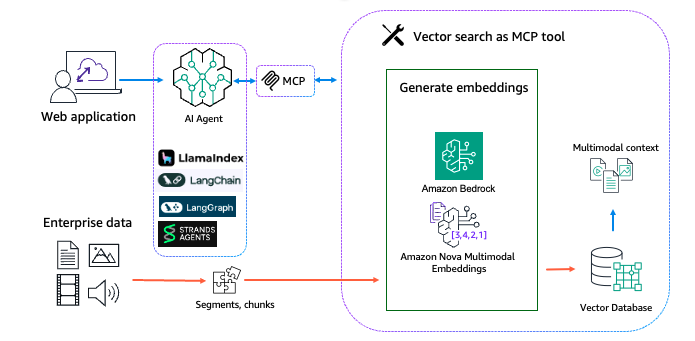
マルチモーダル検索・検索ソリューションは、2 つのデータフローに分けられます。
- データ取り込み
- ランタイム検索・検索
各データフローの共通モジュールと関連ツールを次の表にまとめます。
| データフロー | モジュール | 説明 | 一般的なツールとテクノロジー |
| データ取り込み | Embedding の生成 | 入力 (テキスト、画像、音声、動画など) をベクトル表現に変換 | Embedding モデル |
| ベクトルストアへの Embedding の格納 | 生成されたベクトルをベクトルデータベースまたはストレージ構造に格納し、後続の検索に備える | 一般的なベクトルデータベース | |
| ランタイム検索・検索 | 類似性検索アルゴリズム | クエリベクトルとインデックス済みベクトル間の類似度と距離を計算し、最も近いアイテムを取得 | 一般的な距離指標: コサイン類似度、内積、ユークリッド距離。Amazon OpenSearch k-NN などの k-NN および ANN をサポートするデータベース |
| Top K 検索と投票メカニズム | 検索結果から上位 K 件の最近傍を選択し、複数の戦略 (投票、リランキング、フュージョン) を組み合わせる | 例: 上位 K 件の最近傍、キーワード検索とベクトル検索のフュージョン (ハイブリッド検索) | |
| 統合戦略とハイブリッド検索 | キーワードとベクトル、テキストと画像の検索フュージョンなど、複数の検索メカニズムやモーダル結果を組み合わせる | ハイブリッド検索 (Amazon OpenSearch ハイブリッドなど) |
ここからは、クロスモーダルのユースケースと対応方法を紹介します。
ユースケース: 商品検索と分類
EC アプリケーションでは、手動タグ付けなしに商品画像を自動分類し、類似商品を特定する機能が求められます。ソリューションの概要を次の図に示します。
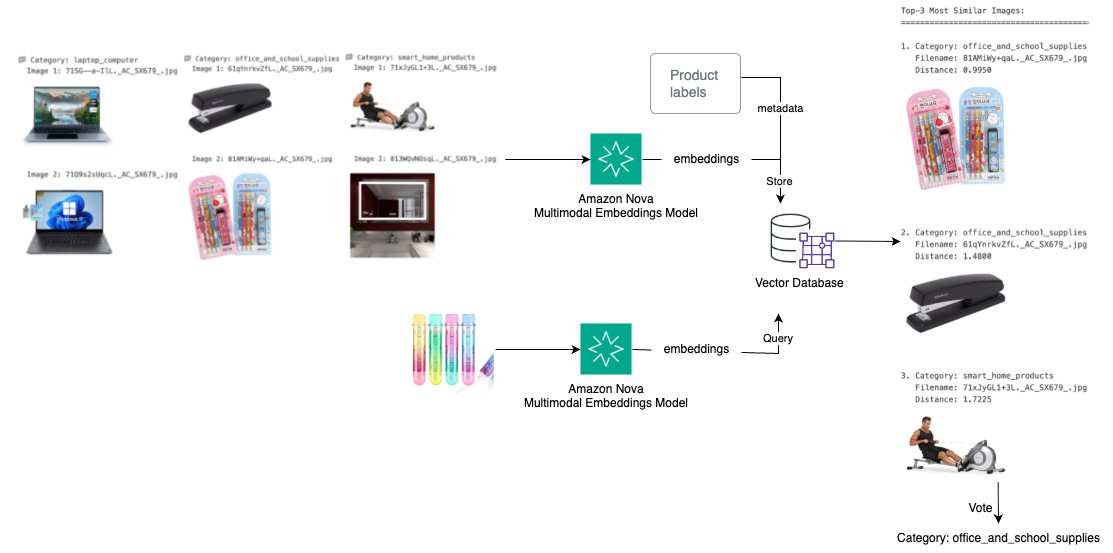
- Amazon Nova Multimodal Embeddings で商品画像を Embedding に変換
- Embedding とカテゴリ情報をメタデータとしてベクトルデータベースに格納
- 新しい商品画像でクエリし、上位 K 件の類似商品を検索
- 検索結果に対する投票メカニズムでカテゴリを予測
主な Embedding パラメータ:
| パラメータ | 値 | 目的 |
embeddingPurpose |
GENERIC_INDEX (インデックス作成) および IMAGE_RETRIEVAL (クエリ) |
商品画像検索に最適化 |
embeddingDimension |
1024 |
精度とパフォーマンスのバランス |
detailLevel |
STANDARD_IMAGE |
商品写真に適切 |
ユースケース: ドキュメント検索
金融アナリスト、法務チーム、研究者は、複雑な複数ページのドキュメントから特定の情報 (テーブル、チャート、条項) を手動レビューなしに素早く見つける必要があります。ソリューションの概要を次の図に示します。
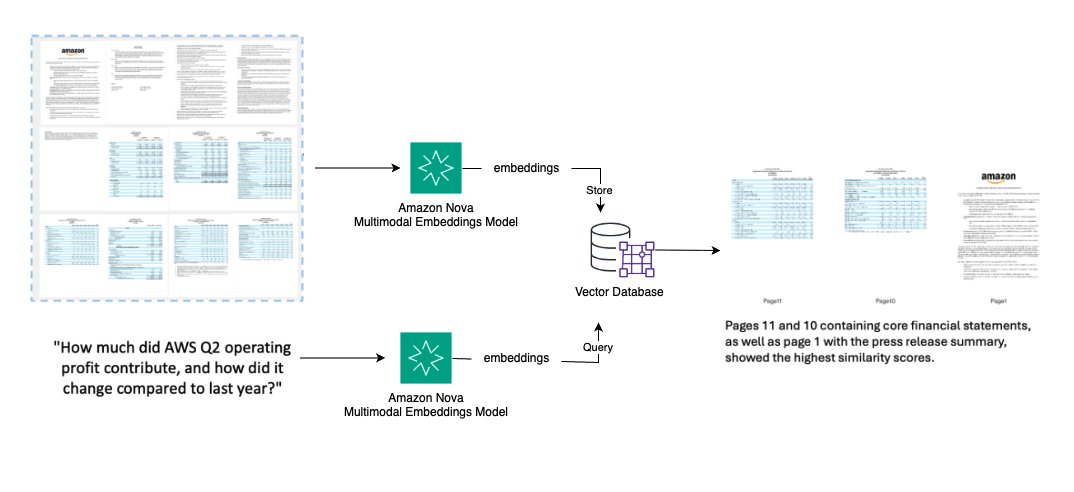
- 各 PDF ページを高解像度画像に変換
- すべてのドキュメントページの Embedding を生成
- Embedding をベクトルデータベースに格納
- 自然言語クエリを受け付け、Embedding に変換
- セマンティック類似度に基づいて最も関連性の高い上位 K ページを取得
- 財務テーブル、チャート、特定コンテンツを含むページを返却
主な Embedding パラメータ:
| パラメータ | 値 | 目的 |
embeddingPurpose |
GENERIC_INDEX (インデックス作成) および DOCUMENT_RETRIEVAL (クエリ) |
ドキュメントコンテンツの理解に最適化 |
embeddingDimension |
3072 |
複雑なドキュメント構造に対する最高精度 |
detailLevel |
DOCUMENT_IMAGE |
テーブル、チャート、テキストレイアウトを保持 |
ビジュアル要素のないテキストベースのドキュメントの場合は、テキストコンテンツを抽出してチャンキング戦略を適用し、インデックス作成に GENERIC_INDEX、クエリに TEXT_RETRIEVAL を使用することを推奨します。
ユースケース: 動画クリップ検索
メディアアプリケーションでは、自然言語の説明を使って大規模な動画ライブラリから特定の動画クリップを効率的に見つける方法が求められます。動画とテキストクエリを統一されたセマンティック空間内の Embedding に変換し、類似度マッチングで関連する動画セグメントを取得できます。ソリューションの概要を次の図に示します。
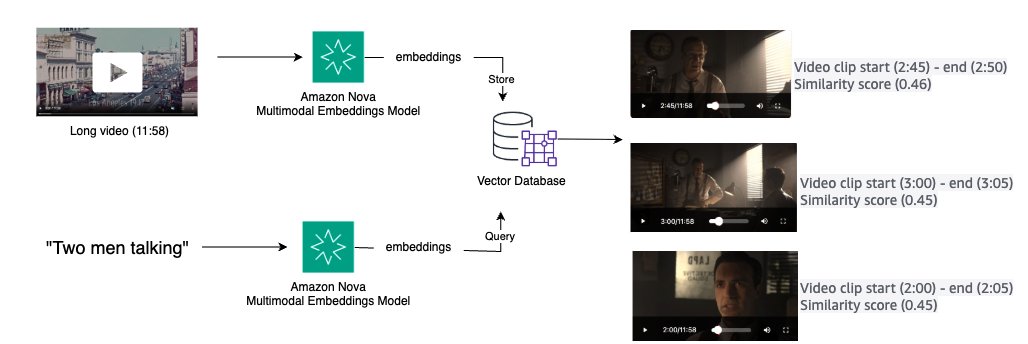
- 短い動画には
invoke_modelAPI、セグメント分割が必要な長い動画にはstart_async_invokeAPI を使用して、Amazon Nova Multimodal Embeddings で Embedding を生成 - Embedding をベクトルデータベースに格納
- 自然言語クエリを受け付け、Embedding に変換
- ベクトルデータベースから上位 K 件の動画クリップを取得し、レビューまたは編集に活用
主な Embedding パラメータ:
| パラメータ | 値 | 目的 |
EmbeddingPurpose |
GENERIC_INDEX (インデックス作成) および VIDEO_RETRIEVAL (クエリ) |
動画のインデックス作成と検索に最適化 |
embeddingDimension |
1024 |
精度とコストのバランス |
embeddingMode |
AUDIO_VIDEO_COMBINED |
映像と音声コンテンツを融合 |
ユースケース: オーディオフィンガープリンティング
音楽アプリケーションや著作権管理システムでは、重複または類似する音声コンテンツを特定し、著作権検出やコンテンツ認識のために音声セグメントをソーストラックとマッチングする必要があります。ソリューションの概要を次の図に示します。
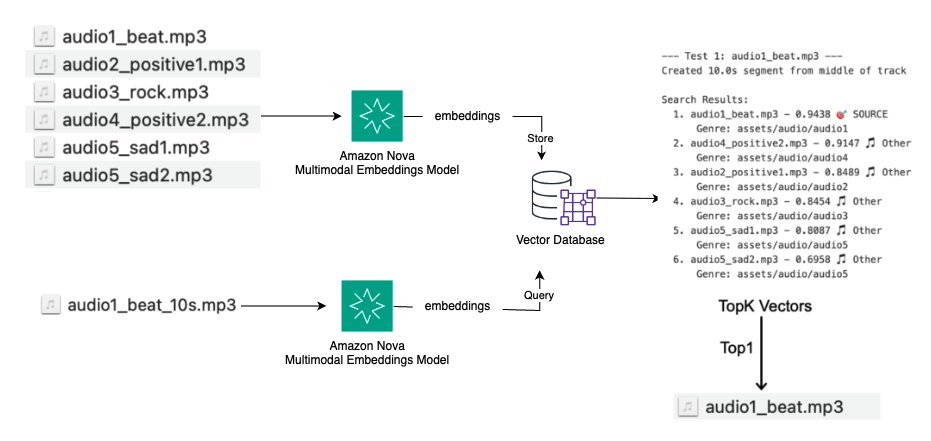
- Amazon Nova Multimodal Embeddings で音声ファイルを Embedding に変換
- Embedding をジャンルなどのメタデータとともにベクトルデータベースに格納
- 音声セグメントでクエリし、上位 K 件の類似トラックを検索
- 類似度スコアを比較してソースの一致を特定し、重複を検出
主な Embedding パラメータ:
| パラメータ | 値 | 目的 |
embeddingPurpose |
GENERIC_INDEX (インデックス作成) および AUDIO_RETRIEVAL (クエリ) |
オーディオフィンガープリンティングとマッチングに最適化 |
embeddingDimension |
1024 |
音声類似性の精度とパフォーマンスのバランス |
まとめ
Amazon Nova Multimodal Embeddings を使用すると、統一されたセマンティック空間内で多様なデータタイプを扱えます。テキスト、画像、ドキュメント、動画、音声を柔軟な目的別最適化 Embedding API パラメータでサポートしており、より効果的な検索システム、分類パイプライン、セマンティック検索アプリケーションを構築できます。クロスモーダル検索、ドキュメントインテリジェンス、商品分類のいずれを実装する場合でも、Amazon Nova Multimodal Embeddings は非構造化データから大規模にインサイトを抽出する基盤となります。Amazon Nova Multimodal Embeddings: エージェント RAG とセマンティック検索のための高性能 Embedding モデルと GitHub サンプルを参考に、Amazon Nova Multimodal Embeddings をアプリケーションに統合してみてください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。