Amazon Web Services ブログ
金融サービスのデータ管理と分析をシンプル化する新しい Amazon FinSpace
データの管理は、金融サービス業界 (FSI) における中核です。私がプライベートバンキングや資金管理会社で働いていたときは、アナリストがポートフォリオ管理、注文管理、および会計システムなどの内部データソースだけでなく、リアルタイムのマーケットフィードと株式価格の推移、および代替データシステムなどの外部データソースからも、数百ペタバイトにおよぶ収集して、それらを集約し、分析できるように援助しました。その頃、規模と複雑さが増加する一方の環境で、私は組織のサイロにまたがるデータにアクセスし、アクセス許可を管理して、反復的なタスクを自動化するシステムを構築しようとすることに時間を費やしていました。
本日、私がこのようなプロジェクトに費した時間を短縮したであろうソリューション、Amazon FinSpace がローンチされます。Amazon FinSpace は、金融サービス業界専用に構築されたデータ管理と分析のソリューションです。Amazon FinSpace は、データを見つけて準備するためにかかる時間を数か月から数分に短縮するため、アナリストは分析により多くの時間を費やすことができます。
お客様からのご意見
アナリストは、データを統合して分析する前に、市場、金融商品、または地域ごとに特化された複数の部門にまたがるデータを探し出してアクセスすることに数週間、または数か月を費やします。この論理的な分離に加えて、データは異なる IT システム、ファイルシステム、またはネットワークで物理的にも分離されています。データへのアクセスはガバナンスとポリシーによって厳密に管理されているため、アナリストはコンプライアンス部門に対するアクセス要請を準備して、それを説明する必要があります。これは手作業に大きく依存するアドホックなプロセスです。
アクセス権が付与されると、アナリストはしばしば、分析のためにデータを準備する、またはデータから情報を引き出すために、より大きなデータセットで計算ロジック (ボリンジャーバンド、指数移動平均、またはATR (Average True Range) など) を実行しなければなりません。多くの場合、これらの計算はキャパシティーが限られたサーバーで実行されます。サーバーは、現代の金融世界におけるワークロードのサイズを処理するように設計されていないからです。サーバー側のシステムでさえも、格納して分析しなければならないデータセットの留まるところを知らない増加に合わせてスケールアップし、対応することが難しくなっています。
Amazon FinSpace を役立てる方法
Amazon FinSpace は、データの保存、準備、管理、およびデータへのアクセスの監査に必要となる、差別化につながらない重労働を排除して、分析のためのデータの検索と準備にかかわる手順を自動化します。Amazon FinSpace は、業界および内部のデータ分類規則を使用してデータを保存し、編成します。アナリストは Amazon FinSpace ウェブインターフェイスに接続し、使い慣れたビジネス用語 (「S&P500」、「CAC40」、「ユーロでのプライベートエクイティファンド」など) を使用してデータを検索します。
アナリストは、時系列データのための 100 を超える専用関数の組み込みライブラリを使用して、選択したデータセットを準備できます。また、統合された Jupyter ノートブックを使用してデータを試し、これらの財務データの変換をクラウド規模で数分のうちに並列化することもできます。最後に、Amazon FinSpace は、データへのアクセスを管理し、いつ、誰が、どのデータにアクセスしているのかを監査するためのフレームワークを提供します。このフレームワークは、データの使用状況を追跡し、コンプライアンスレポートと監査レポートを生成します。
Amazon FinSpace は、履歴データでの作業も簡単にします。信用リスクを計算するモデルを構築したとしましょう。このモデルは利率とインフレ率に依存し、これらは頻繁に更新されます。顧客に関連付けられたリスクレベルは、インフレ率と利率が異なっていた数か月前のものであるため、現在は変わってしまっています。データアナリストがデータを現在の状態、および過去の状態で検証するモデリングは、bitemporal modeling と呼ばれます。Amazon FinSpace では、時間をさかのぼり、モデルが複数の次元に沿ってどのように進化しているかを比較することが容易になります。
Amazon FinSpace の仕組みを説明するため、アナリストとデータサイエンティストのチームがあり、彼らにデータを検索、準備、および分析するためのツールを提供したいとしましょう。
Amazon FinSpace 環境を作成する方法
AWS アカウント管理者として、金融アナリストのチームのための作業環境を作成します。これは 1 回限りのセットアップです。
Amazon FinSpace コンソールに移動して、[Create environment] (環境を作成する) をクリックします。

環境に名前を付けます。保存中のデータの暗号化に使用される KMS 暗号化キーを選択します。次に、AWS Single Sign-On との統合、または Amazon FinSpace でのユーザー名とパスワードの管理のいずれかを選択します。AWS Single Sign-On との統合は、アナリストが企業の Active Directory などの外部システムを使用して認証し、Amazon FinSpace 環境にアクセスすることを可能にします。この例では、認証情報を自分で管理することを選択します。

Amazon FinSpace 環境での管理権限を持つスーパーユーザーを作成します。[Add Superuser] (スーパーユーザーを追加) をクリックします。
 一時パスワードをメモしておきます。スーパーユーザーに送信するメッセージのテキストをコピーします。このメッセージには、環境への初回接続のための接続手順が記載されています。
一時パスワードをメモしておきます。スーパーユーザーに送信するメッセージのテキストをコピーします。このメッセージには、環境への初回接続のための接続手順が記載されています。

スーパーユーザーは、Amazon FinSpace 環境自体で他のユーザーを追加し、これらのユーザーのアクセス許可を管理する権限を持っています。
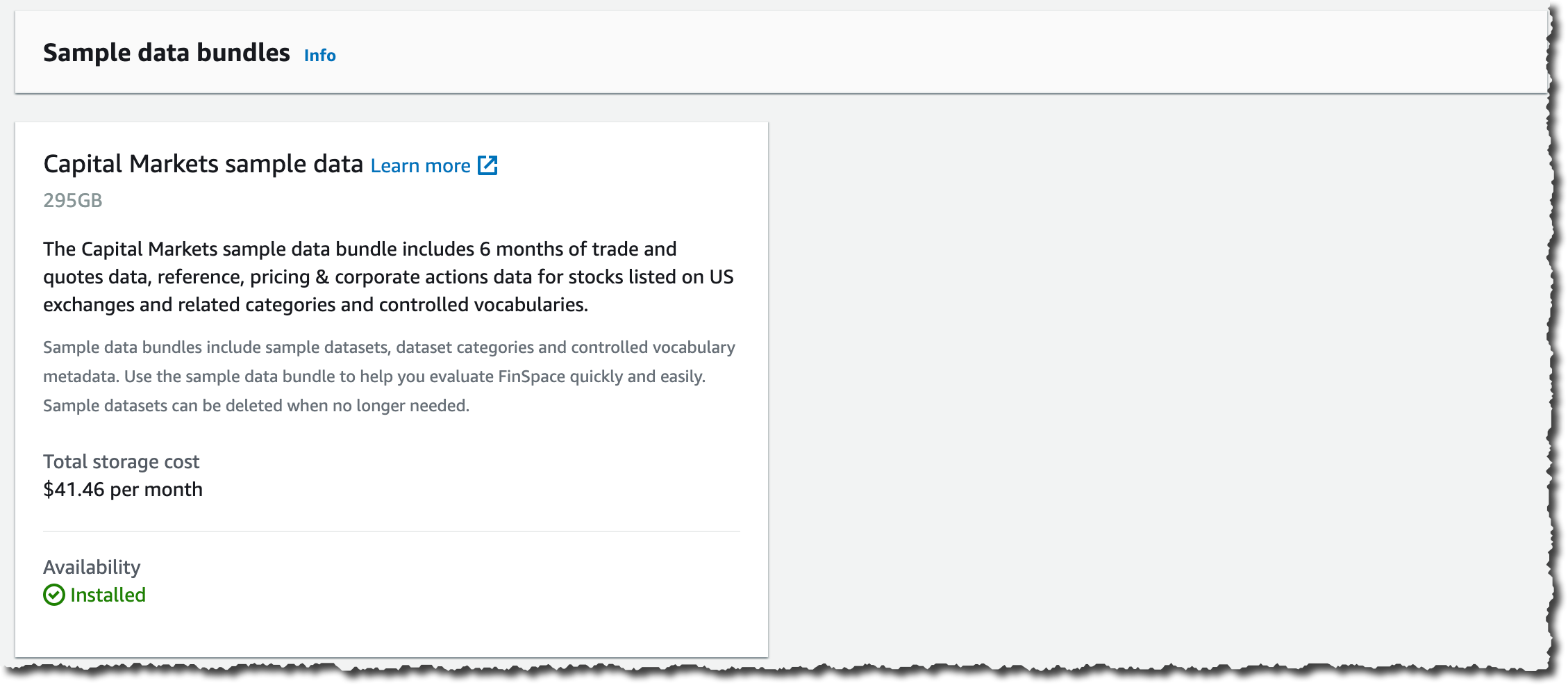
最後に、このデモのためだけに、初期のデータセットのインポートを選択します。こうすることで、環境内にいくつかのデータがある状態で始めることができます。これは、コンソールで 1 回クリックするだけで実行できます。このデータセットのストレージコストは 41.46 USD/月で、いつでも削除できます。
[Sample data bundles] (サンプルデータバンドル) の [Capital Markets sample data] ( 資本市場サンプルデータ) で、[Install dataset] (データセットをインストールする) をクリックします。これには数分かかるので、立ち上がって足を伸ばし、コーヒーを一杯飲むのにちょうど良いタイミングです。
Amazon FinSpace 環境の使用方法
金融アナリストとしての役割を担う私に、AWS アカウント管理者から Amazon FinSpace 環境に接続するための URL と、関連する認証情報が記載された E メールが送信されます。Amazon FinSpace 環境に接続します。
ウェルカムページには、注目すべき点がいくつかあります。まず、右上の歯車アイコンをクリックして環境設定にアクセスします。ここでは、他のユーザーを追加して、ユーザーのアクセス権を管理できます。次に、左側でカテゴリ別に異なるデータを参照する、または画面上部の検索バーに検索クエリを入力して特定の用語を検索し、左側での検索を絞り込むことができます。
Amazon FinSpace はデータハブとして使用できます。データは API 経由で投入する、またはワークステーションから直接ロードできます。データセットを説明するためにタグを使用します。データセットはデータのコンテナです。変更はバージョン管理され、データの履歴ビューを作成する、または Amazon FinSpace によって維持される自動更新データビューを使用することができます。
このデモでは、ポートフォリオマネージャーから、AMZN 株式の実現ボラティリティを示す、5 分の時間バーを使用したグラフを要望するリクエストを受けたとします。検索バーを使用してデータを特定してから、ノートブックを使用してそのデータを分析する方法を見ていきましょう。
まず、データセットで、5 分間隔の時間バーを使った株式価格の要約を検索します。検索ボックスに「equity」(株式) と入力します。幸運にも、最初に表示された結果が目的のデータセットです。必要な場合は、左側のファセットを使用して結果を絞り込むことも可能です。

データセットを見つけたら、その説明、スキーマ、およびその他の情報を調べます。これらに基づいて、このデータセットがポートフォリオマネージャーのリクエストに答えるために適切なものかどうかを判断します。

[Analyze in notebook] (ノートブックで分析する) をクリックして、Jupyter ノートブックを起動します。ノートブックでは、PySpark を使ってデータをさらに掘り下げることができます。ノートブックが開いたら、まずそれが Amazon FinSpace PySpark カーネルの使用向けに正しく設定されていることをチェックします (カーネルの起動には 5〜8 分かかります)。

最初のコードボックスで「play」をクリックして、Spark クラスターに接続します。

データセットを分析して PM からの具体的な質問に答えるには、PySpark コードを少し入力する必要があります。このデモには、Amazon FinSpace GitHubリポジトリからのサンプルコードを使用しています 。ノートブックは環境にアップロードすることができます。上の画面の左上に表示されている上矢印をクリックして、ローカルマシンからのファイルを選択します。
このノートブックは、先ほど見つけた Amazon FinSpace カタログ「US Equity Time-Bar Summary」のデータからデータを取得し、その後 Amazon FinSpace の組み込み分析関数 realized_volatility() を使用して、一連のティッカーと取引イベントタイプの実現ボラティリティを計算します。
グラフを作成する前に、データセットの内容を把握しましょう。データの時間範囲はどれくらいですか? このデータセットにはどのティッカーがありますか? これらの質問については、Amazon FinSpace が提供するシンプルな select() または groupby() 関数で回答します。以下のコードを使って FinSpaceAnalyticsAnalyser クラスを準備します。
from aws.finspace.analytics import FinSpaceAnalyticsManager
finspace = FinSpaceAnalyticsManager(spark = spark, endpoint=hfs_endpoint)
sumDF = finspace.read_data_view(dataset_id = dataset_id, data_view_id = view_id)完了したら、データセットの調査を開始できます。

2019 年 10 月 1 日から 2020 年 3 月 31 日までの 561778 件の AMZN 株式の取引と株価があるのがわかります。
実現ボラティリティをプロットするために、Panda を使って値をプロットします。

このコードブロックを実行すると、以下が表示されます。

同様に、ボリンジャーバンド分析を開始して、ボラティリティスパイクによってAMZN 株式の売られ過ぎ状態が発生したのかどうかをチェックできます。今回も Panda を使用して値をプロットします。

このグラフを生成します。
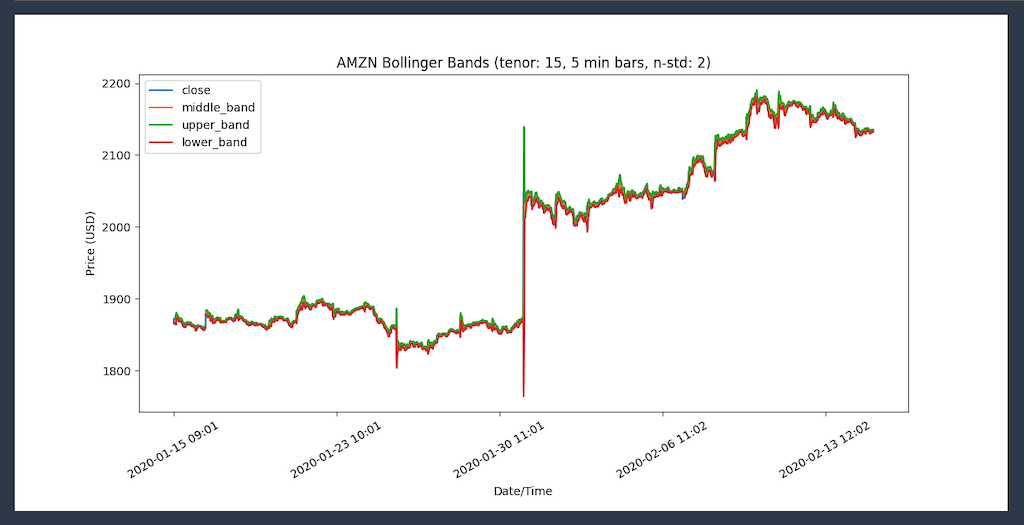
これで、ポートフォリオマネージャーの質問に答える準備ができました。しかし、2020 年 1 月 30 日にスパイクが発生したのはなぜだったのでしょうか? その答えは、「Amazon soars after huge earnings beat」というニュースを読めばわかります。:-)
利用可能なリージョンと料金
Amazon FinSpace は、本日から米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド)、およびカナダ (中部) でご利用いただけます。
いつものように、請求されるのはプロジェクトで使用するリソースの料金のみです。料金は、サービスにアクセスできるアナリストの人数、取り込まれたデータの量、および変換の適用に使用されたコンピューティング時間の 3 つの側面に基づいています。詳しい料金情報は、サービスの料金ページに記載されています。
今すぐ Amazon FinSpace を試して、フィードバックをお聞かせください。