Amazon Web Services ブログ
Amazon SageMaker – 機械学習を加速する
機械学習は多くのスタートアップやエンタープライズにとって重要な技術です。数十年に渡る投資と改善にも関わらず、機械学習モデルの開発、学習、そして、メンテナンスはいまだに扱いにくく、アドホックなままになっています。機械学習をアプリケーションに組み込むプロセスはしばしば一貫しない仕組みで数ヶ月間に及ぶエキスパートチームによるチューニングと修正を伴います。企業と開発者は機械学習に対する生産パイプラインに対するのエンド・エンドな製品を望んでいます。
Amazon SageMaker の紹介
Amazon SageMaker はフルマネージドなエンド・エンド機械学習サービスで、データサイエンティストや開発者、機械学習のエキスパートがクイックに機械学習モデルをスケーラブルにビルド・学習・ホストすることを可能とします。このサービスが機械学習に関する全ての試みを急激に加速し、プロダクションアプリケーションに素早く機械学習を追加可能とします。
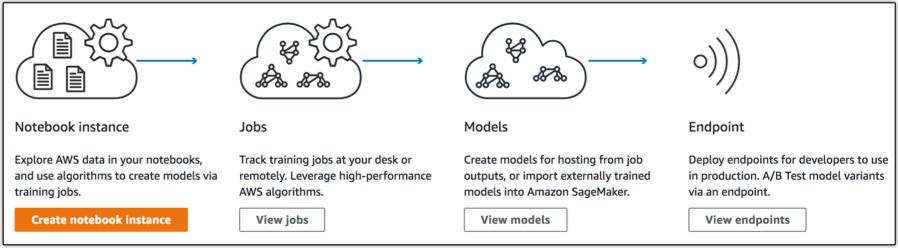
Amazon SageMaker には3つの主要なコンポーネントが存在します:
- オーサリング:データに関する調査・クレンジング・前処理に対してセットアップ無しで利用可能な Jupyter notebook IDE をCPUベースのインスタンスやGPUを利用可能なインスタンスで実行することが可能です。
- モデルトレーニング:モデルトレーニングは分散モデル構築/学習/評価サービスです。ビルトインされた共通の教師あり/教師なし学習アルゴリズムやフレームワークの利用や Docker コンテナによる独自の学習環境を作ることも可能です。学習では、より高速なモデル構築を可能とするため、数十のインスタンスにスケールすることが可能です。学習データは S3 から読み出され、モデルアーティファクト が S3 に保存されます。モデルアーティファクトはデータと分離されたモデルのパラメータであり、モデルを使って推論を可能とするような実行コードではありません。この分離により、IoT デバイスのような他のプラットフォームに SageMaker で学習したモデルをデプロイすることが容易になります。
- モデルホスティング:モデルをホストするサービスで、リアルタイムに推論結果を取得するためにモデルを呼び出す HTTPS エンドポイントを提供します。エンドポイントはトラフィックに対処するためにスケールすることができ、同時に複数モデルで A/B テストすることを可能とします。加えて, ビルトインの SDK を利用してエンドポイントを構築できるだけでなく、カスタム設定で Docker イメージを利用することができます。
これらコンポーネントはそれぞれ分離して利用することができ、分離されていることが、存在するパイプラインのギャップを埋めるために Amazon SageMaker を採用することを本当に簡単にしています。故、エンド・エンドにサービスを使用するときに有効になる、本当に強力な事象がいくつも存在します。
Working with SageMaker
これから Apache MXNet による画像分類器を構築、学習、デプロイしてみます。言語は Gluon、データは CIFAR-10データセット、モデルアーキテクチャには ResNet V2 を利用します。
Jupyter Notebook によるオーサリング

notebook インスタンスを生成すると、Anaconda パッケージと deep learning で利用される共通ライブラリ、5GB のストレージボリューム、そして、様々なアルゴリズムをデモするためのサンプル notebook が利用可能な機械学習計算用のインスタンスが起動します。オプションで、VPCサポートを設定することができます。VPCサポートは自分のリソースに簡単かつ安全にアクセスするためのENI を自分の VPC 内に生成します。
インスタンスが使えるようになったら notebook を開き、コードを書き始めることができます!

モデルトレーニング
ここでは簡潔にするため、実際のモデルを学習するコードは省略しますが、大抵は Amazon SageMaker で共通のどんなフレームワークに対しても下記のようなシンプルな学習インタフェースを実装することが可能です。
def train(
channel_input_dirs, hyperparameters, output_data_dir,
model_dir, num_gpus, hosts, current_host):
pass
def save(model):
passAmazon SageMaker のインフラストラクチャで ml.p2.xlarge インスタンスを 4 つ利用し、分散学習ジョブを生成してみます。
なお、ローカルで学習に必要となるデータは既にダウンロード済みです。
import sagemaker
from sagemaker.mxnet import MXNet
m = MXNet("cifar10.py", role=role,
train_instance_count=4, train_instance_type="ml.p2.xlarge"
hyperparameters={'batch_size': 128, 'epochs': 50,
'learning_rate': 0.1, 'momentum': 0.9})
既にモデル学習ジョブを構成してあるので、次のようにメソッドを呼び出すことでデータを投入することができます。
m.fit("s3://randall-likes-sagemaker/data/gluon-cifar10").
ジョブコンソールを見てみると、ジョブが実行されているのを確認することができます!

ホスティングとリアルタイム推論
既にモデルの学習が完了しているので、予測結果を生成し始めることが可能です!前述した同じコードを利用し、エンドポイントを生成、ローンチします。
predictor = m.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge')それから、エンドポイントを呼び出すのは実行するのと同じくらいシンプルです:predictor.predict(img_input)!
以上が 100 行よりも少ないコードで実行できるエンド・エンドな機械学習パイプラインです。
Amazon SageMaker のモデルホスティングコンポーネントをどんな風に使うことができるのか、
もう一つの例で見てみたいと思います。
カスタム Docker コンテナを使う場合
Amazon SageMaker は Docker コンテナに対するシンプルな仕様を定義します。独自の学習アルゴリズムや推論コンテナを簡単に定義可能にします。
ここで記載したアーキテクチャに基づく既に存在するモデルを使って、リアルタイム推論を実行するためにモデルをホスティングしてみようと思います。
簡単な Dockerfile と推論用の Flask アプリケーションを作成しました。
実装方法は1つではないので、ここにモデルを読み込み、推論結果を生成するコードを残しておきました。基本的には、入力された URL から画像をダウンロードし、その画像を予測に使用する MXNet モデルに連携するようなメソッドを実装しています。
from flask import Flask, request, jsonify
import predict
app = Flask(__name__)
@app.route('/ping')
def ping():
return ("", 200)
@app.route('/invocations', methods=["POST"])
def invoke():
data = request.get_json(force=True)
return jsonify(predict.download_and_predict(data['url']))
if __name__ == '__main__':
app.run(port=8080)WORKDIR /app
COPY *.py /app/
COPY models /app/models
RUN pip install -U numpy flask scikit-image
ENTRYPOINT [“python”, “app.py”]
EXPOSE 8080
このイメージを ECR リポジトリにプッシュし、それから、新しいモデルを生成するために Amazon SageMaker のモデルコンソールに移動します。

モデルを生成したら、エンドポイントを使えるように設定します。

さあ、これで AWS Lambda やその他のアプリケーションからエンドポイントを呼び出すことができます!実際、このモデルをみていただくために Twitter アカウントを準備しました。モデルが位置情報を推測できるかどうか確認するため @WhereML に1枚の写真を Tweet してみてください!
import boto3
import json
sagemaker = boto3.client('sagemaker-runtime')
data = {'url': 'https://pbs.twimg.com/media/DPwe4kMUMAAWCd_.jpg'}
result = sagemaker.invoke_endpoint(
EndpointName='predict',
Body=json.dumps(data)
)利用料金
無料利用枠を利用して、無料で Amazon SageMaker を試すことができます。最初の2ヶ月間、1ヶ月あたり、notebook 利用に t2.medium インスタンスを 250時間、モデル学習に m4.xlarge インスタンスを 50 時間、ホスティングに m4.xlarge インスタンスを 125 時間ご利用いただけます。無料利用枠を超えた場合、リージョン毎に利用料金は異なりますが、サービスに関連する秒単位のインスタンス利用料、GB単位のストレージ、サービスに対する GB単位のデータ転送量が課金されます。
今年の re:Invent のブログを書く前に、Jeff が私にお気に入りを選ばないようにと言っていました。…が、失敗しました。まさにアメージングなローンチだったけど、Amazon SageMaker は re:Invent 2017 で私のお気に入りのサービスです。お客様が一連のツールを使ってどんなことを達成するのか待っていられません。