(補足:本記事は2017年6月にAWS Bigdata Blogにポストされた記事の翻訳です。一部の記載を現時点の状況に合わせて更新してあります)
クラウドサービスの採用が増加するにつれて、組織は重要なワークロードをAWSに移行しています。これらのワークロードの中には、セキュリティとコンプライアンスの要件を満たすために監査が必要な機密データを格納、処理、分析するものがあります。監査人が良くする質問は、誰がどの機密データをいつ照会したのか、いつユーザが最後に自分の資格情報を変更/更新したのか、誰が、いつシステムにログインしたかということです。
デフォルトでは、Amazon Redshiftは、ユーザーの接続情報、変更情報、アクティビティに関連するすべての情報をデータベースに記録します。ただし、ディスク領域を効率的に管理するために、ログの使用状況と使用可能なディスク容量に応じて、ログは2〜5日間のみ保持されます。より長い時間ログデータを保持するには、データベース監査ロギングを有効にします。有効にすると、Amazon Redshiftは指定したS3バケットに自動的にデータを転送します。
Amazon Redshift Spectrumにより、Amazon S3に格納されたデータにクエリすることを可能にし、さらにAmazon Reshift のテーブルと結合することも可能です。 Redshift Spectrumを使い、S3に格納されている監査データを確認し、すべてのセキュリティおよびコンプライアンス関連の質問に答えることができます。AVRO、Parquet、テキストファイル(csv、pipe delimited、tsv)、シーケンスファイル、およびRCファイル形式、ORC、Grokなどのファイルをサポートしています。 gzip、snappy、bz2などのさまざまな圧縮タイプもサポートしています。
このブログでは、S3に保存されたAmazon Redshift の監査データを照会し、セキュリティーやコンプライアンスの質問への回答を提供する方法を説明します。
作業手順
次のリソースを設定します。
- Amazon Redshift クラスタとパラメータグループ
- Amazon Redshift に Redshift Spectrumアクセスを提供するIAMロールとポリシー
- Redshift Spectrum外部表
前提条件
- AWS アカウントを作成する
- AWS CLI にて作業ができるように設定する
- Amazon Redshift にアクセスできる環境を用意する。(psqlやその他クライアント)
- S3バケットを作成する
クラスタ要件
Amazon Redshift クラスタは、次の条件を満たす必要があります。
- 監査ログファイルを格納しているS3バケットと同じリージョンにあること
- バージョン1.0.1294以降であること
- ログ蓄積用のS3バケットに読み込み、PUT権限を設定されていること
- AmazonS3ReadOnlyAccessとAmazonAthenaFullAccessの少なくとも2つのポリシーを追加したIAMロールにアタッチしていること
Amazon Redshift のセットアップ
ユーザーのアクティビティーをロギングするために、新しいパラメータグループを作ります。
aws redshift create-cluster-parameter-group --parameter-group-name rs10-enable-log --parameter-group-family Redshift-1.0 --description "Enable Audit Logging"
aws redshift modify-cluster-parameter-group --parameter-group-name rs10-enable-log --parameters '{"ParameterName":"enable_user_activity_logging","ParameterValue":"true"}'
Amazon Redshift クラスタを上記で作成したパラメータグループを使い作成します。
aws redshift create-cluster --node-type dc1.large --cluster-type single-node --cluster-parameter-group-name rs10-enable-log --master-username <Username> --master-user-password <Password> --cluster-identifier <ClusterName>
クラスターが出来るまで待ち、作成されたらロギングを有効にします。
aws redshift enable-logging --cluster-identifier <ClusterName> --bucket-name <bucketname>
※S3のバケットポリシーなどはこちらを御覧ください。
※もしくは下記のようにマネージメントコンソールからログ用のS3のバケットを新規で作成するとバケットポリーが設定された状態のバケットが作成できます。
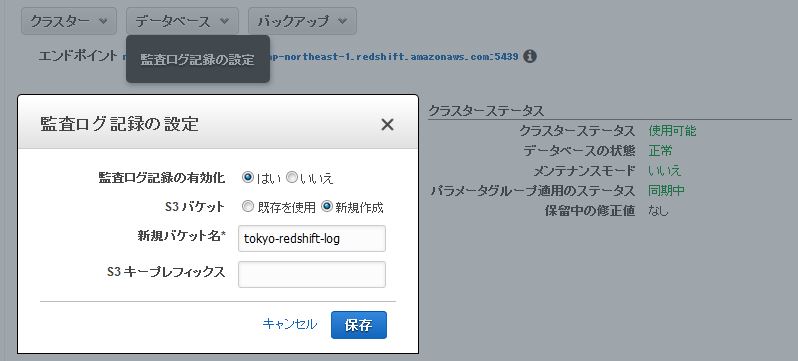
Redshift Spectrumをセットアップします。
Redshift Spectrumをセットアップするために、IAM ロールとポリシー、External Database,External Tablesを作成します。
IAM ロールとポリシー
Redshift データベースからS3バケットにアクセスするためのIAMロールを作成します。
RedshiftAssumeRole.json ファイルを作成し、下記のコマンドを実行してください。
aws iam create-role --role-name RedshiftSpectrumRole --assume-role-policy-document file://RedshiftAssumeRole.json
RedshiftAssumeRole.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
AmazonS3ReadOnlyAccess および AmazonAthenaFullAccess の2つのポリシーをアタッチします。
aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/AmazonAthenaFullAccess --role-name RedshiftSpectrumRole
aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess --role-name RedshiftSpectrumRole
作成したロールをAmazon Redshift クラスタに追加します。 <ClusterName> と <accountNumber> を自身のものに置き換えます。
aws redshift modify-cluster-iam-roles --cluster-identifier <ClusterName> --add-iam-roles arn:aws:iam::<accountNumber>:role/RedshiftSpectrumRole
ここまでの操作で、Amazon Redshift クラスタから S3 にアクセスできるように、Redshift Spectrum は設定されました。
External DatabaseとSchema
Amazon Redshift データベースにログインして、外部データベースとスキーマ、外部表を作成し、S3 に格納されたデータにアクセスできるよう設定します。
例えばpsql でアクセスする場合は下記がコマンド例になります。
本手順で作成している場合は、dev という名前のデータベースが作成されています。
psql -h <ご自身の設定したものを確認して変更ください>.ap-northeast-1.redshift.amazonaws.com -p 5439 -U dbadmin -d dev -W
Amazon Redshift で作成された外部データベースは、Amazon Athena データカタログに格納することが出来、Athena からも直接アクセスできます。
※本Blog (英語版)が書かれたあとにAWS Glue がリリースしておりますので、こちらも参考にしてください。
監査ログデータを照会するには、Amazon Redshift で外部データベースとスキーマを作成します。 DDL を実行する前に、以下のアカウント番号、ロール名、リージョン名を更新してください。
CREATE external SCHEMA auditLogSchema
FROM data catalog
DATABASE 'auditLogdb'
iam_role 'arn:aws:iam::<AccountNumber>:role/<RoleName>'
REGION '<regionName>'
CREATE external DATABASE if not exists;
REGION パラメータは、Athena データカタログのリージョンを指定します。 デフォルトの値は、Amazon Redshift クラスタと同じリージョンになります。(東京リージョンは、ap-northeast-1 になります。)
外部表の作成
Redshift Spectrum は S3 上のデータに対してクエリ可能になる外部表が作成可能です。 外部表は読取り専用であり、 現在、Spectrum を使用して S3 上のデータを変更することはできません。外部表は、表名の前にスキーマ名を付けた形で指定します。
3つの異なる監査ログ・ファイルを照会するための下記3つの表を作成します。
・ユーザーDDL:ユーザーが実施した DDL(CREATEやDROPなど)を記録します。
・ユーザー接続:成功または失敗したすべてのログオン情報をログに記録します。
・ユーザーアクティビティ:ユーザーが実行したすべてのクエリを記録します。
ユーザーDDL とユーザー接続のデータファイル形式は、パイプ区切りのテキストファイルです。 どちらのファイルもgzipユーティリティを使用して圧縮されています。 ユーザーアクティビティログはフリーフローテキストです。 各クエリは新しい行で区切られます。 このログも、gzip ユーティリティを使用して圧縮されています。
次のクエリのS3 バケットの場所を自身のバケットになおして実行してください。
CREATE external TABLE auditlogschema.userlog
(
userid INTEGER,
username CHAR(50),
oldusername CHAR(50),
action CHAR(10),
usecreatedb INTEGER,
usesuper INTEGER,
usecatupd INTEGER,
valuntil TIMESTAMP,
pid INTEGER,
xid BIGINT,
recordtime VARCHAR(200)
)
row format delimited
fields terminated by '|'
stored as textfile
location 's3://<bucketName>/AWSLogs/<accountNumber>/redshift/<regionName>/YYYY/MM/DD/';
CREATE external TABLE auditlogschema.connectionlog
(
event CHAR(50) ,
recordtime VARCHAR(200) ,
remotehost CHAR(32) ,
remoteport CHAR(32) ,
pid INTEGER ,
dbname CHAR(50) ,
username CHAR(50) ,
authmethod CHAR(32) ,
duration BIGINT ,
sslversion CHAR(50) ,
sslcipher CHAR(128) ,
mtu INTEGER ,
sslcompression CHAR(64) ,
sslexpansion CHAR(64) ,
iamauthguid CHAR(36)
)
row format delimited
fields terminated by '|'
stored as textfile
location 's3://<bucketName>/AWSLogs/<accountNumber>/redshift/<regionName>/YYYY/MM/DD/';
CREATE external TABLE auditlogschema.activitylog
(
logtext VARCHAR(20000)
)
row format delimited
lines terminated by '\n'
stored as textfile
location 's3://<bucketName>/AWSLogs/<accountNumber>/redshift/<regionName>/YYYY/MM/DD/';
guest ユーザーを作成して簡単な作業をしログを作成する。
ユーザー “guest” を作成してログインし、 “person” という表を作成します。次に、テーブルに対してクエリーを実行します。
管理ユーザーとしてログインし、新しいユーザー “guest” を作成します。
CREATE USER guest PASSWORD 'Temp1234';
ユーザー “guest” としてログインし、以下の DDL を実行します。
CREATE TABLE person (id int, name varchar(50),address VARCHAR(500));
INSERT INTO person VALUES(1,'Sam','7 Avonworth sq, Columbia, MD');
INSERT INTO person VALUES(2,'John','10125 Main St, Edison, NJ');
INSERT INTO person VALUES(3,'Jake','33w 7th st, NY, NY');
INSERT INTO person VALUES(4,'Josh','21025 Stanford Sq, Stanford, CT');
INSERT INTO person VALUES(5,'James','909 Trafalgar sq, Elkton, MD');
guest でログインしている間に、person テーブルでいくつかのクエリを実行して、アクティビティログを生成します。
SELECT *
FROM person;
SELECT *
FROM person
WHERE name='John';
次に、上記で作成した3つの外部表(それぞれのログ)毎に、1つのクエリーの具体例を説明します。
ユーザーDDL ログ
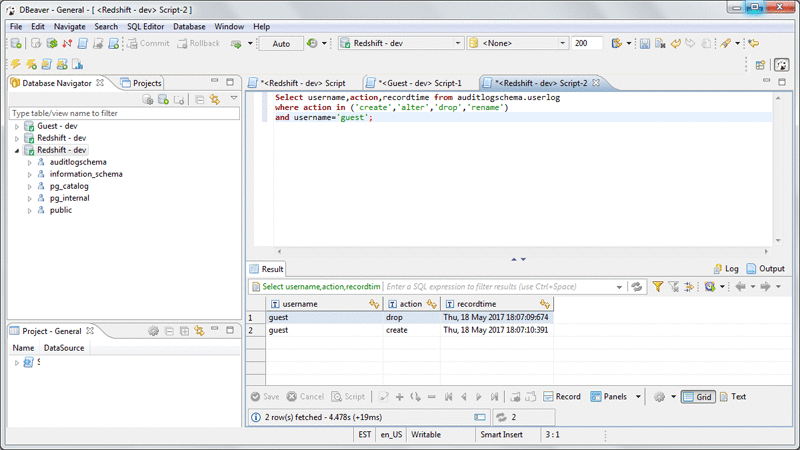
次のクエリは、ユーザー guest がその日に実行した作業が確認できます。
SELECT username
,action
,recordtime
FROM auditlogschema.userlog
WHERE action in ('create','alter','drop','rename')
AND username='guest';
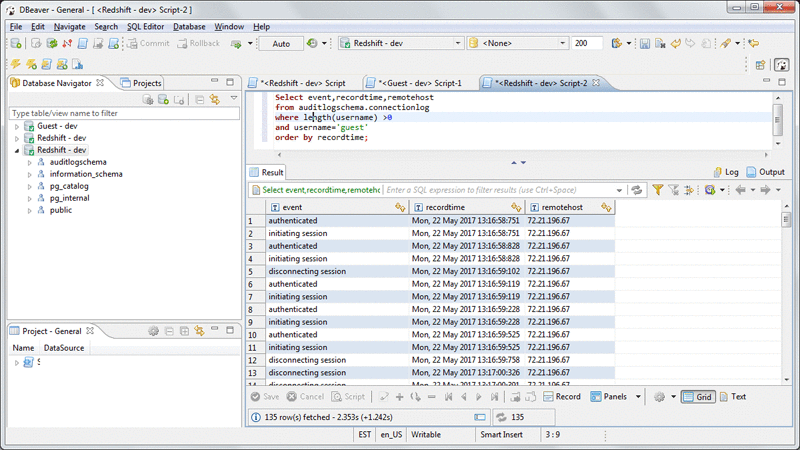
ユーザー接続ログ
次のクエリでは、ユーザー guest がログインした remotehost名、時刻を確認できます。
SELECT event
,recordtime
,remotehost
FROM auditlogschema.connectionlog
WHERE length(username) >0
AND username='guest'
ORDER BY recordtime;
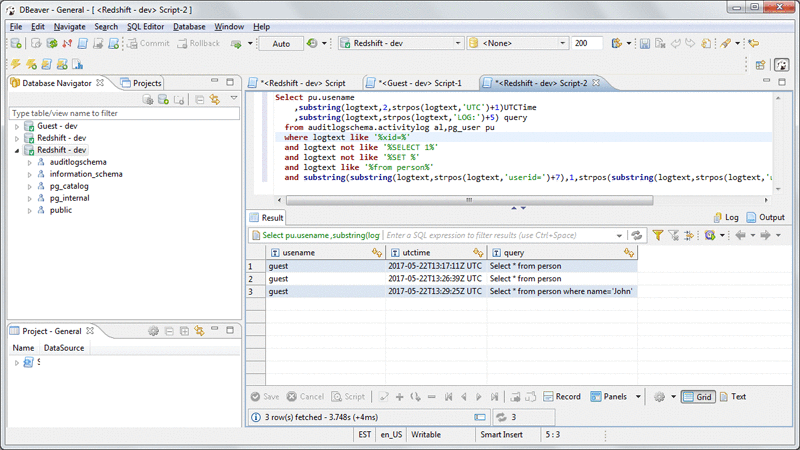
ユーザーアクティビティログ
次のクエリは、誰がいつ、person表 にアクセスしたか、またその際に流したクエリを確認できます。
SELECT pu.usename
,substring(logtext,2,strpos(logtext,'UTC')+1)UTCTime
,substring(logtext,strpos(logtext,'LOG:')+5) query
FROM auditlogschema.activitylog al,pg_user pu
WHERE logtext like '%xid=%'
AND logtext not like '%SELECT 1%'
AND logtext not like '%SET %'
AND logtext like '%from person%'
AND substring(substring(logtext,strpos(logtext,'userid=')+7),1,strpos(substring(logtext,strpos(logtext,'userid=')+7),' '))=pu.usesysid;
まとめ
このBlogでは、Amazon Redshift に新たに追加された機能 (Redshift Spectrum) を使用して、S3に格納されている監査ログデータを照会し、セキュリティおよびコンプライアンス関連の質問に簡単に回答する方法について説明しました。
Amazon Redshift Spectrum は2017年10月20日現在、東京リージョンでも利用可能となっております。
Amazon Redshift Spectrum の詳細については、こちらをご覧ください。 新機能についての詳細は、「Get Started」をご覧ください。
翻訳:パートナーソリューションアーキテクト 相澤