AWS Big Data Blog
Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum
This post was last reviewed and updated July, 2022 to update the policy for the crawler.
With the increased adoption of cloud services, organizations are moving their critical workloads to AWS. Some of these workloads store, process, and analyze sensitive data that must be audited to satisfy security and compliance requirements. The most common questions from the auditors are around who logs in to the system when, who queried which sensitive data when, and when did the user last modify or update his or her credentials.
By default, Amazon Redshift logs all information related to user connections, user modifications, and user activity on the database. However, to efficiently manage disk space, log tables are only retained for 2–5 days, depending on log usage and available disk space. To retain the log data for longer period of time, enable database audit logging. After it’s enabled, Amazon Redshift automatically pushes the data to a configured S3 bucket periodically.
Amazon Redshift Spectrum is a recently released feature that enables querying and joining data stored in Amazon S3 with Amazon Redshift tables. With Redshift Spectrum, you can retrieve the audit data stored in S3 to answer all security and compliance–related questions. Redshift Spectrum can also combine the datasets from the tables in the database with the datasets stored in S3. It supports files in Parquet, text file (CSV, pipe-delimited, TSV), sequence file, ORC, OpenCSV, AVRO, RegexSerde, Ion, JSON and RC file format. It also supports different compression types like gzip, snappy, and bz2.
In this post, we’ll demonstrate querying the Amazon Redshift audit data logged in S3 to provide answers to common use cases described preceding.
Walkthrough
You set up the following resources:
- Amazon Redshift cluster and parameter group
- IAM role and policies to give Redshift Spectrum access to Amazon Redshift
- Redshift Spectrum external tables
Prerequisites
- Create an AWS account
- Configure the AWS Command Line Interface (AWS CLI) to access your AWS account
- Get access to a query tool compatible with Amazon Redshift
- Create an S3 bucket
Cluster requirements
These must be true of your Amazon Redshift cluster:
- Be in the same AWS Region as the S3 bucket storing the audit log files.
- Be version 1.0.1294 or later.
- Configure S3 bucket policy for Redshift audit logging.
- Have an IAM role attached that has read access to S3 bucket where the audit logs will be created and AWS Glue access to read the data through external tables.
Set up Amazon Redshift
Create a new parameter group to enable user activity logging:
Create the Amazon Redshift cluster using the new parameter group created:
Wait for the cluster to build. When it is complete, enable audit logging:
After this is completed, you should see that Amazon Redshift is creating audit log data into the path s3://<bucketname>/AWSLogs. The structure under this prefix will be created by the Amazon Redshift audit logger, and follows this format:
Configure the AWS Glue Data Catalog
The next step is to add this audit log location into the AWS Glue Data Catalog, which allows you to easily work with this data from a variety of tools. These include AWS Glue applications, Amazon Athena, and Amazon Redshift Spectrum.
To configure the AWS Glue Data Catalog, complete the following steps:
- Open AWS Glue console.
- Choose Crawlers.
- Choose Add crawler.
- For Crawler name, enter
redshift-audit-log, and choose Next. - For Crawler source type and Repeat crawls of S3 data stores, leave as it is, and choose Next
- For Include path, enter
s3://<bucketname>/AWSLogs/. - For Exclude patterns, enter
**/*_useractivitylog_*.gzand**/*_userlog_*.gz, and choose Next. - For Add another data store, choose No, and Next.
- For IAM role, choose your IAM role, and Next.
- For Frequency, choose Run on demand, and Next.
- For Database, choose Add database to create a new database.
- For Prefix added to tables (optional), you can enter your preferred table prefix optionally.
- For Grouping behavior for S3 data (optional), select Create a single schema for each S3 path. Choose Next.
- Choose Finish.
- Select the Glue crawler
redshift-audit-log, and choose Run crawler. - Wait for the Glue crawler
redshift-audit-logto be Ready.
After the crawler has run, you should have a new table (in this example, we use redshift_audit_logs):
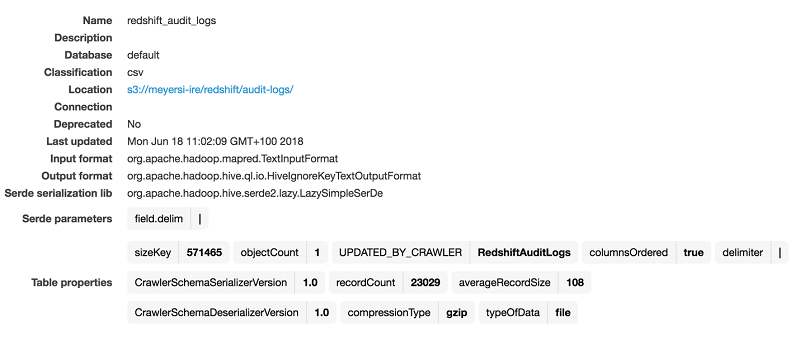
This table only has positional column names, because the audit log files are CSV format, and will include ‘col0’ through ‘col15’. The crawler will also have created partition columns for each of the parts of the prefix that are added automatically by the Amazon Redshift audit logger including account number, region, and year/month/day. These are placed into columns named ‘partition_0’ through ‘partition_7’.
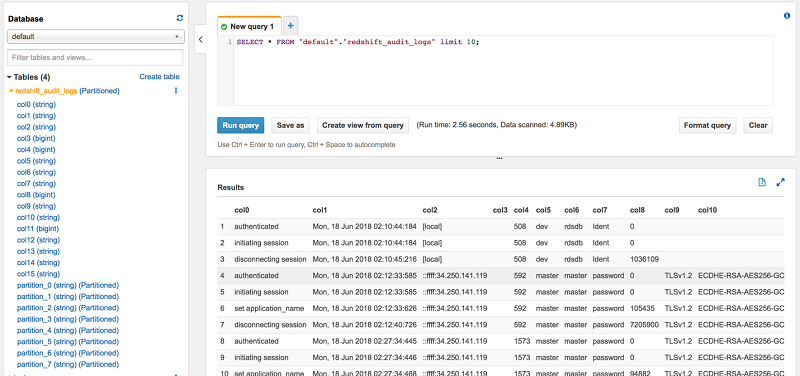
We can now immediately query this data by going to the Athena console and previewing the contents of this table:
Set up Redshift Spectrum
We can now set up Redshift Spectrum to allow us to query this dataset on S3. We first configure Amazon Redshift with the correct IAM privileges to access S3 (remember that no AWS service has rights to access other services by default!).
IAM role and policies
Create an IAM role for Redshift Spectrum to access the S3 bucket from an Amazon Redshift database:
Create and attach the following policy to grant redshift access to S3 bucket to write audit logs and for redshift spectrum to read the logs:
Add the role that you just created to the Amazon Redshift cluster. Replace the account number with your account number.
At this point, you now have Redshift Spectrum completely configured to access S3 from the Amazon Redshift cluster.
External database and schema
The next step is to create a relationship between your Amazon Redshift cluster and the AWS Glue Data Catalog database that contains your Amazon Redshift audit logs. This is done using direct SQL statements to create an EXTERNAL SCHEMA that defines a mapping of a database. For this database, metadata locations exist either in the catalog or in a user-specified Apache Hive metastore server, to a local schema inside the Amazon Redshift cluster. This mapping allows table definitions to be shared between Athena and Amazon Redshift, or even different infrastructure setups between Amazon Redshift, Apache Spark, and Apache Hive.
To query audit log data, create an external database and schema in Amazon Redshift:
The catalog database parameter references the database in AWS Glue Data Catalog where you configured your crawler to create tables, and the region parameter specifies the AWS Region of the Athena data catalog. By default, this is the same AWS Region as the Amazon Redshift cluster.
You should now be able to see the audit log table from the AWS Glue Data Catalog in your external schema by querying the SVV_EXTERNAL_TABLES view:
Summary
In this post, we discussed how to configure Amazon Redshift audit logging and how to query these audit logs data stored in S3 directly from Amazon Athena or Redshift Spectrum. Doing this can help you to answer security and compliance-related queries with ease.
To learn more about Amazon Redshift Spectrum, visit this page. You can also visit the Get Started page to know more about new features.
If you have any questions or suggestions, comment below.
Additional Reading
Learn how to improve query performance by orders of magnitude in the Amazon Redshift Engineering’s Advanced Table Design Playbook.

About the Authors
 Sandeep Kariro is a Consultant for AWS Professional Services. He is a seasoned data center migration specialist to AWS. Sandeep also provides data-centric design solutions optimal for Cloud deployments while keeping security, compliance and operations as top design principles. He also acts as a liaison between the customer and AWS product teams to request new product features and communicate top customer asks. He loves travelling around the world and has traveled to several countries around the globe in last decade.
Sandeep Kariro is a Consultant for AWS Professional Services. He is a seasoned data center migration specialist to AWS. Sandeep also provides data-centric design solutions optimal for Cloud deployments while keeping security, compliance and operations as top design principles. He also acts as a liaison between the customer and AWS product teams to request new product features and communicate top customer asks. He loves travelling around the world and has traveled to several countries around the globe in last decade.
 Ian Meyers looks after the Database Services Customer Advisory Team. He is based in London, UK, and has been with AWS for 6 years as a specialist in Database and Analytics. When he’s not doing cloudy stuff, he’s likely to be found with his family and the dog by the Thames riverside.
Ian Meyers looks after the Database Services Customer Advisory Team. He is based in London, UK, and has been with AWS for 6 years as a specialist in Database and Analytics. When he’s not doing cloudy stuff, he’s likely to be found with his family and the dog by the Thames riverside.