Amazon Web Services ブログ
NTT西日本の AWS 事例:Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットの開発
本ブログは、NTT西日本グループ 吉田 健哉氏、同 中井 智絵氏、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 川岸 が共同で執筆しました。
はじめに
NTT西日本株式会社(以下、NTT西日本)では、ビジネスチャット『elgana』(エルガナ)をサービス提供しています。2022 年 7 月にアマゾン ウェブ サービス (AWS) へプラットフォームを移行し、生成 AI による新機能開発も加速しています。
elgana Project 「AI Lab.チーム」では、生成 AI を実際の業務にどう活かせるかをテーマにトライアル開発を進めています。本記事では、営業担当者支援を目的として Amazon Bedrock Knowledge Bases を活用した RAG を構築し、そのトライアルを実施した取り組みについて紹介します。
取り組み背景
elgana は一般の企業様を中心にご利用いただいているサービスですが、生成 AI による新機能開発は社内向けに検証を開始しました。NTT西日本グループにおいて営業担当者は日々多様な商材を扱い、膨大なマニュアルや資料を参照しています。しかし実際には、情報が複数のシステムに散在しており、必要な情報を探し出すのに時間がかかる・属人化してしまうといった課題がありました。加えて、商材の問い合わせ窓口である社内ヘルプデスクは限られた対応時間の中で運用されており、すべての問い合わせに即時対応することは難しい状況でした。そこで、生成 AI に社内ナレッジを組み合わせる RAG を活用し、効率的に「聞ける・探せる・使える」仕組みを提供できないか検証することにしました。AWS サービスとの親和性、日本語対応、セキュリティ設計の容易さから、Amazon Bedrock Knowledge Bases を採用しました。
営業支援 AI ボット
営業支援 AI ボットは elgana 上に構築しました。トークルーム上で営業支援 AI ボットに対して商材に関する質問を入力すると、AI ボットが即時に回答を提示する仕組みです。また、AI ボットからの回答には、補足情報として関連するマニュアルページへのリンクを設けることで、裏付けとなる情報を容易に確認できる設計としました。
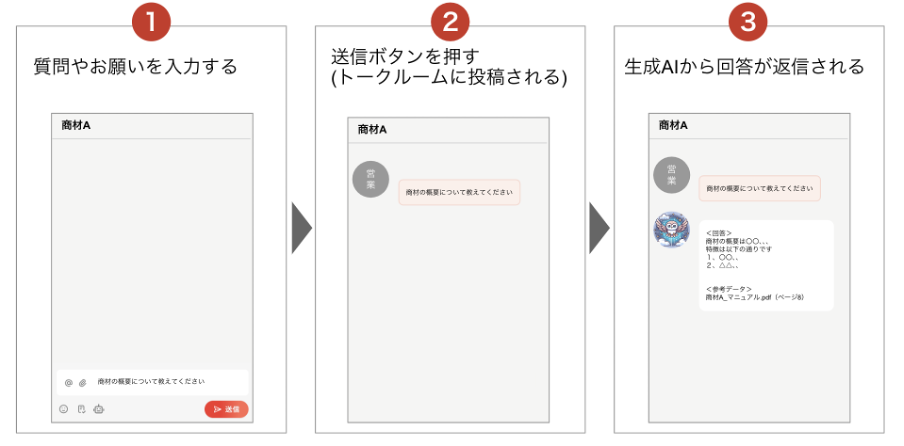
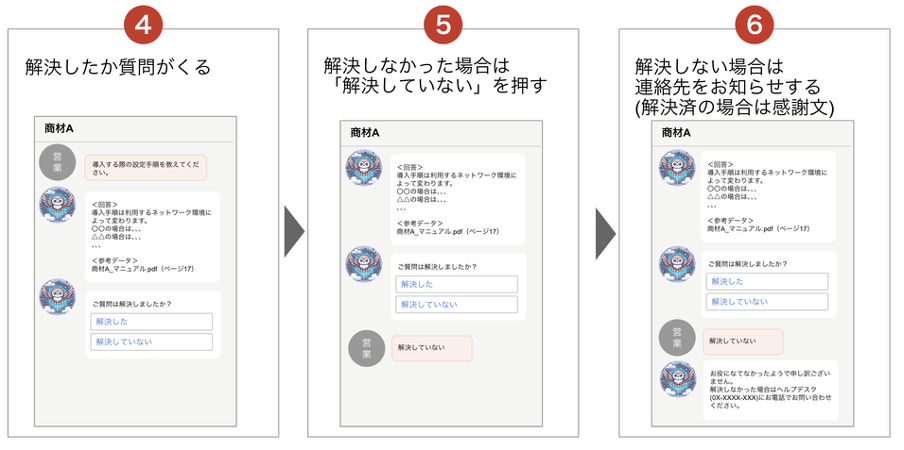
さらに、回答後には「解決した/解決していない」の簡易アンケートを設け、解決率を収集するとともに、未解決のユーザーをヘルプデスクに誘導する流れを設けています。これにより、AI の強みと有人対応を組み合わせた実用的なサポート体験を実現しています。
アーキテクチャ
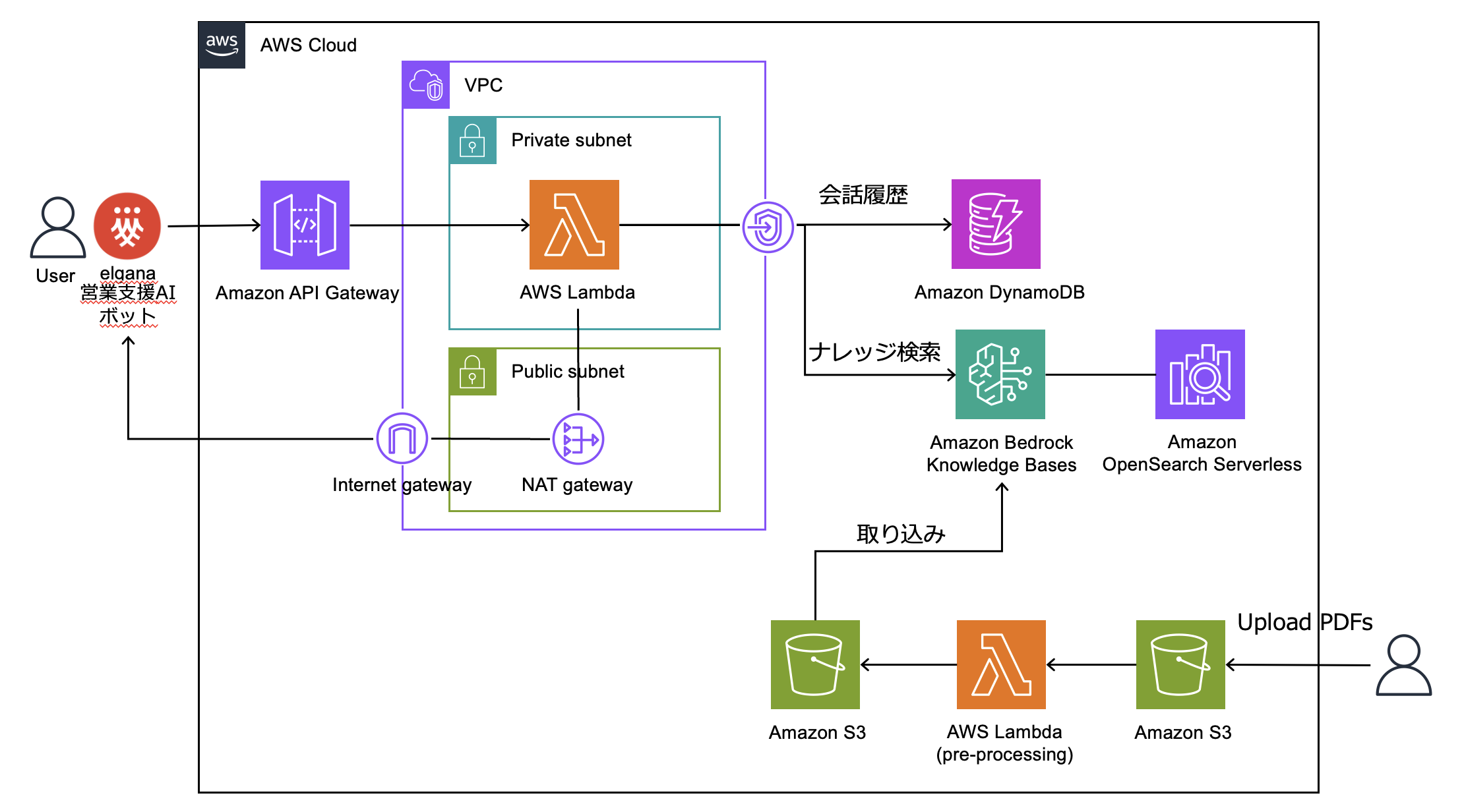
本システムでは、AWS のマネージドサービスをフル活用して構成し、最新技術の活用、インフラ運用の負担軽減とアプリレイヤの改善への集中を実現しています。elgana 上で営業支援 AI ボットに質問すると、Amazon API Gateway と AWS Lambda で実装したアプリケーションがメッセージを受信し、Amazon Bedrock Knowledge Bases を呼び出して質問に回答します。ナレッジのドキュメントの保存先のベクトルストアとして Amazon OpenSearch Serverless を利用しています。
営業支援 AI ボットでは、利用者体験を向上させるため、回答生成に利用したマニュアルのページ番号まで案内すること、関連するサービスマニュアルのナレッジだけを参照するようメタデータフィルタリングを活用して検索対象を絞り込むことで回答精度を向上させる工夫をしています。
具体的な処理内容としては、運用者が Amazon S3 にアップロードしたマニュアルの pdf ファイルは AWS Lambda (pre-processing) を通じて、(A) ページ分割した上で、Markdown 形式に変換、(B) マニュアルに付与するメタデータを作成、の 2 つの処理が行われた後、Amazon S3 に格納されます。(A) の処理では、ページ分割することで RAG 回答で参照したマニュアルのページ番号をファイル名から特定できるようにしています。また、マニュアルに含まれる表データの抽出精度向上のため、pdf 文書をテキスト化するための python ライブラリである pdfminer を用いて HTML 化し、その後 Claude 3.5 Sonnet で Markdown 形式に変換しています。なお、Claude 3.5 Sonnet はマルチモーダル対応 LLM であるため、画像認識による情報抽出も可能ですが、検証時点では pdfminer を介す方法の方が優れていると判断しました。(B) の処理では、S3 のオブジェクトキー情報からカテゴリ情報等を抽出して、.metadata.json メタデータファイルを作成しています。
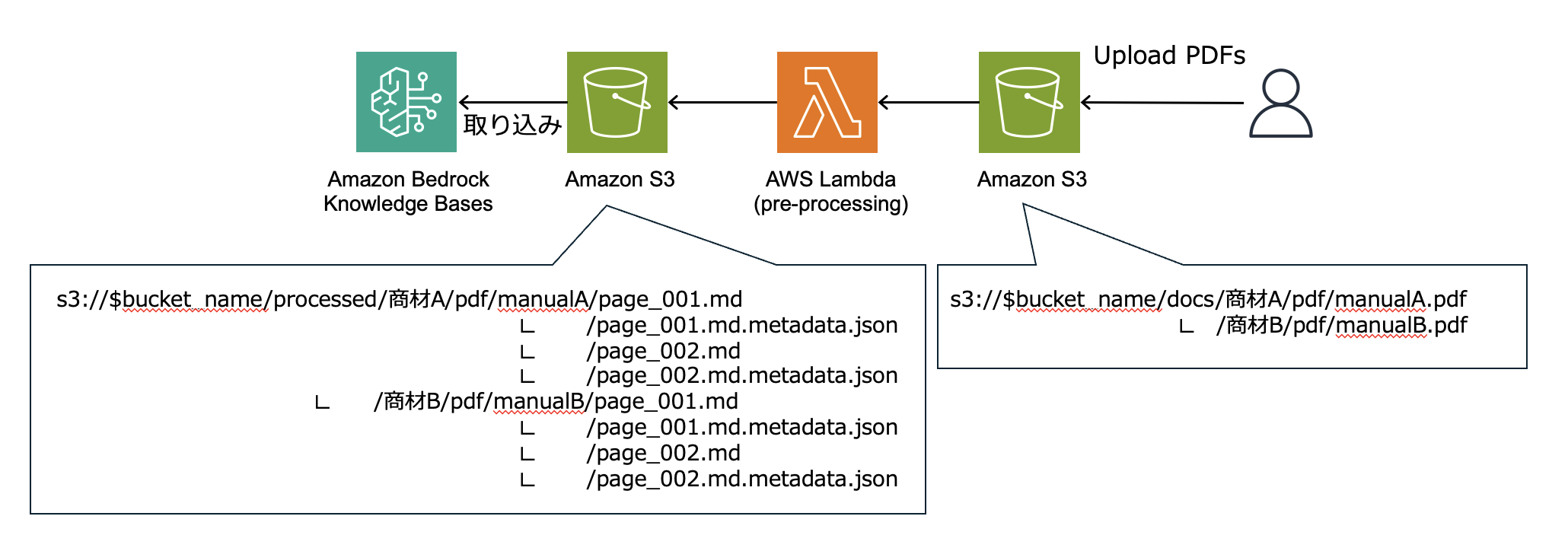
以下はメタデータファイルの中身の例です。
{
"metadataAttributes": {
"original-s3-key": "docs/商材A/pdf/manualA.pdf",
"file-type": "pdf",
"category": "商材A"
}
}このメタデータは、ベクトルストアからドキュメント検索する際に、メタデータに基づき事前にフィルタリングした上で、関連するドキュメントを検索できます。上記の例では、単一の Knowledge Base に複数の商材のマニュアルを格納していた場合にも、category = 商材A でフィルタリングすることで関連する情報を取得できるため、検索精度向上に寄与します。
トライアル結果
今回の取り組みでは、実際の営業担当者に数週間トライアル利用していただき、その後、ユーザーアンケートを実施し様々な評価を得ました。利用者からは「知りたい情報に素早くアクセスできる」「マニュアルを探す時間が減った」といった声が多く寄せられ、業務効率化につながる手応えを実感していただいており、現場での実用性を確認する結果となりました。一方で、「回答速度を上げてほしい」や「回答の幅(サービスの種類)を広げてほしい」などの改善意見もポイントも挙げられました。こうした声を踏まえ、今後も更なる機能改善を繰り返し利用者がさらに安心して業務に取り入れられるよう、進化させていく予定です。
今後の展望
今回のトライアルで得られた成果をもとに機能改善を重ねて実運用を目指していく予定です。
また、開発した RAG 基盤は Amazon S3 にナレッジドキュメントを格納するだけで対象商材に特化した検索基盤を自動的に構築できる仕組みであり、幅広い業務で活用できる柔軟な基盤へ発展させることも視野に入れています。将来的には Amazon Bedrock AgentCore 等を活用することで、単なる検索や回答にとどまらずタスク実行まで支援できる「Agentic RAG」へ時代に即した価値創出を目指します。
まとめ
本ブログでは、NTT西日本グループによる、 Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットによる情報検索効率化の取り組み事例をご紹介しました。生成 AI の業務利用にあたっては、ハルシネーションのような不確実性を課題視されるお客様もいらっしゃると思います。本事例では、関連マニュアルのページ番号まで明示することで情報の正確性を迅速に確認できる仕組みを構築するとともに未解決の場合にはヘルプデスクに誘導する仕組みを設け、AI の強みと有人対応を組み合わせた実用的なサポート体験を実現しています。皆様の生成 AI 活用の参考になれば幸いです。
著者
吉田 健哉
NTTビジネスソリューションズ株式会社 バリューデザイン部 システム開発部門
中井 智絵
NTT西日本株式会社 ビジネス営業本部 バリューデザイン部 DXプラットフォーム部門
川岸 基成
アマゾン ウェブ サービス ジャパン合同会社 技術統括本部 ストラテジックインダストリー技術本部 通信グループ
ソリューションアーキテクト