Amazon Web Services ブログ
BIM データを生成 AI で活用する: IFC を RDF グラフに変換し Amazon Neptune で問い合わせるアーキテクチャ
はじめに
建設業界における BIM(Building Information Modeling)の導入は着実に進んでいます。BIM は建物の 3D 形状に加えて、各部材の寸法・材料・性能といった属性情報を一元的に持つ、いわば「建物のデータベース」とも言える存在です。しかし、その豊富なデータは、後述するいくつかの理由から、十分に活用されていない、という声もよく耳にします。
こうしたなか、BIM データ活用に向けた一つのアプローチとして注目されているのが生成 AI です。近年の生成 AI の発展により、「自然言語で BIM データを読み書きする」「AI エージェントが建物データを解釈して次のアクションに繋げる」といった使い方が現実的になりつつあります。本ブログでは、AWS Summit Japan 2025 の建設・不動産ブースで展示した IFC Viewer with GraphRAG を題材に、IFC ファイルをグラフに変換してグラフデータベースに格納し、生成 AI エージェントが情報を問い合わせる仕組みを、実装レベルで解説します。
なお本ブログは、1〜2 章で「なぜこの構成にしたのか」というアプローチと設計の考え方を、3 章で「どう実装したか」という詳細を扱い、4 章で発展的な拡張に触れる構成です。3 章以降は RDF グラフのモデリングや AI アプリの実装に踏み込む内容のため、グラフデータベースや生成 AI の開発経験があると読み進めやすくなりますが、各節の冒頭に要約を置いているため、詳細を読まなくても全体の流れは追えるようになっています。
1. BIM データを AI から扱うアプローチ
BIM が普及するにつれ、3D 形状と属性情報を一元的に持つ「建物のデジタルデータ」が、案件ごとに蓄積されるようになりました。生成 AI を活用することで、こうしたデータに自然言語で問い合わせたり、AI エージェントに解釈させて次の作業へ繋げたりといった応用に繋げることができます。
その入口としてまず候補になるのが、各種 BIM プラットフォームが提供する REST API を、AI エージェントの Tool、あるいは MCP(Model Context Protocol)サーバー経由で渡す方法です。BIM データに API 経由でアクセスできるサービスは増えており、データを別の形式に変換したり外部に書き出したりせず、プラットフォームに置いたまま AI から参照できます。導入の手間が小さく、認証認可の仕組みや、ビューワーまで BIM プラットフォームで完結する利点があります。半面、取得できるデータやロジックは、ベンダーが提供する API の範囲に縛られます。API が想定していない切り口での集計や、他システムのデータとの突き合わせといった使い方には対応しにくいという制約があります。
(補足: MCP はアプリケーションが AI にツールやデータソースを提供するための共通プロトコルで、対応していれば異なる AI クライアントから同じツールを使えます)
オープンフォーマットな BIM (IFC) を起点にする
特定ベンダーの API 範囲に縛られたくない場合、業界標準のオープンフォーマットである IFC(Industry Foundation Classes) を起点にする方法があります。IFC は、建設分野のオープンな BIM 標準を策定する、国際的な非営利団体である buildingSMART が定めた国際標準フォーマットで、特定ベンダーの製品に依存せず建物データを表現・交換できます。主要な BIM ツールは IFC のエクスポートに対応しているため、特定の製品で作成した BIM モデルであっても IFC 形式に変換できます。
ただし、IFC は AI がそのまま解釈できる形式にはなっていません。IFC は STEP 物理ファイル形式というテキスト形式で、中身は次のように、エンティティを #1234= のような ID 番号で繋いだフラットな構造になっています。
#129= IFCBUILDING('0w984V0GL6yR4z75XVLWOr',#41,'',$,$,#32,$,'',.ELEMENT.,$,$,#125);
#138= IFCBUILDINGSTOREY('0w984V0GL6yR4z75YWgVfX',#41,'Nivel 1',$,'Nivel:Nivel 1',#136,$,'Nivel 1',.ELEMENT.,0.);
#186= IFCWALLSTANDARDCASE('2idC0G3ezCdhA9WVjWemc$',#41,'Muro básico:Partición con capa de yeso:163541',...,#155,#182,'163541');
#6723= IFCWINDOW('2idC0G3ezCdhA9WVjWe$OB',#41,'Ventana simple:100 x 100 cm:164193',...,#25036,#6717,'164193',2.3,1.);壁 (#186) が所属する階 (#138) は #136 経由でたどり、窓 (#6723) が埋まっている壁は IFCRELVOIDSELEMENT / IFCRELFILLSELEMENT を介して参照する、といった具合です。エンティティの量(上記は数万行のうちの一部です)も相応にあり、AI にこの生テキストを渡してそのまま解釈させるのは現実的ではありません。
この IFC を扱いやすくするアプローチが、大きく 2 つあります。1 つは IFC を解釈できるライブラリを使ってその場で読む方法(A)、もう 1 つは IFC を別のデータモデルに変換し、データベースに格納してから問い合わせる方法(B)です。
(A) IFC を扱えるライブラリを AI のツールとして渡す
1 つ目は、IFC を扱えるオープンソースソフトウェア(OSS)を Tool として渡し、エージェントに探索させる方法です。代表的な OSS が IfcOpenShell で、先ほどのような生の STEP テキストを直接たどる必要はありません。by_type("IfcWall") で壁を一覧したり、#136 のような番号ではなく wall.Name のように属性名でアクセスしたり、ある要素を参照している関連要素を逆向きにたどったりと、IFC の構造を扱いやすい形で読み取ることができます。先ほど挙げたフラットさや参照の複雑さの多くは、こうしたライブラリが吸収します。
一方で、このアプローチには考慮すべき点もあります。問い合わせのたびに IFC ファイルを読み込んで探索する形になるため、エージェントにライブラリの API を組み合わせて目的の情報までたどらせると、問い合わせの内容によっては探索の手数が読みにくく、応答時間も安定しません。また、複数の建物をまたいだ横断検索や、大量要素の集計のように「あらかじめ整理されたデータ」を前提とする用途とは相性がよくありません。1 ファイルを対象とした素朴な参照には手軽で有効である一方、規模や横断性が増すほど追加の工夫を要する、という位置づけです。
(B) IFC を構造化してデータベースに格納し、AI が問い合わせる
2 つ目は、IFC を一度解釈し、用途に合わせたスキーマでデータベースに格納してから、エージェントには「データベースを問い合わせる Tool」を渡す方法です。問い合わせのたびにファイルを探索する代わりに、あらかじめ整理した状態を用意しておく、という発想です。
データの構造を案件・用途に合わせて設計できるので、カスタマイズの自由度が最も高くなります。複数ファイルをまたいだ横断検索や集計を書きやすい形に整えたり、他システムのデータと突き合わせやすいスキーマにしたりと、(A) では難しかった用途にも対応できます。半面、変換パイプラインとデータベースの両方を用意・運用する必要があり、導入コストは最も高くなります。
本ブログで扱うアプローチ
ベンダー API(最初に触れた方法)、ライブラリでの直接探索(A)、データベースへの構造化(B)と、後ろにいくほど構築の手間は増えますが、その分、任意の構造でデータを格納でき、検索・集計・横断分析の自由度が高くなります。本ブログでは、この (B) のアプローチを採用した実装例を取り上げます。次の章では、データベースとして何を選び、どう組み立てたかを見ていきます。
2. IFC をグラフに変換して、グラフデータベースに格納する
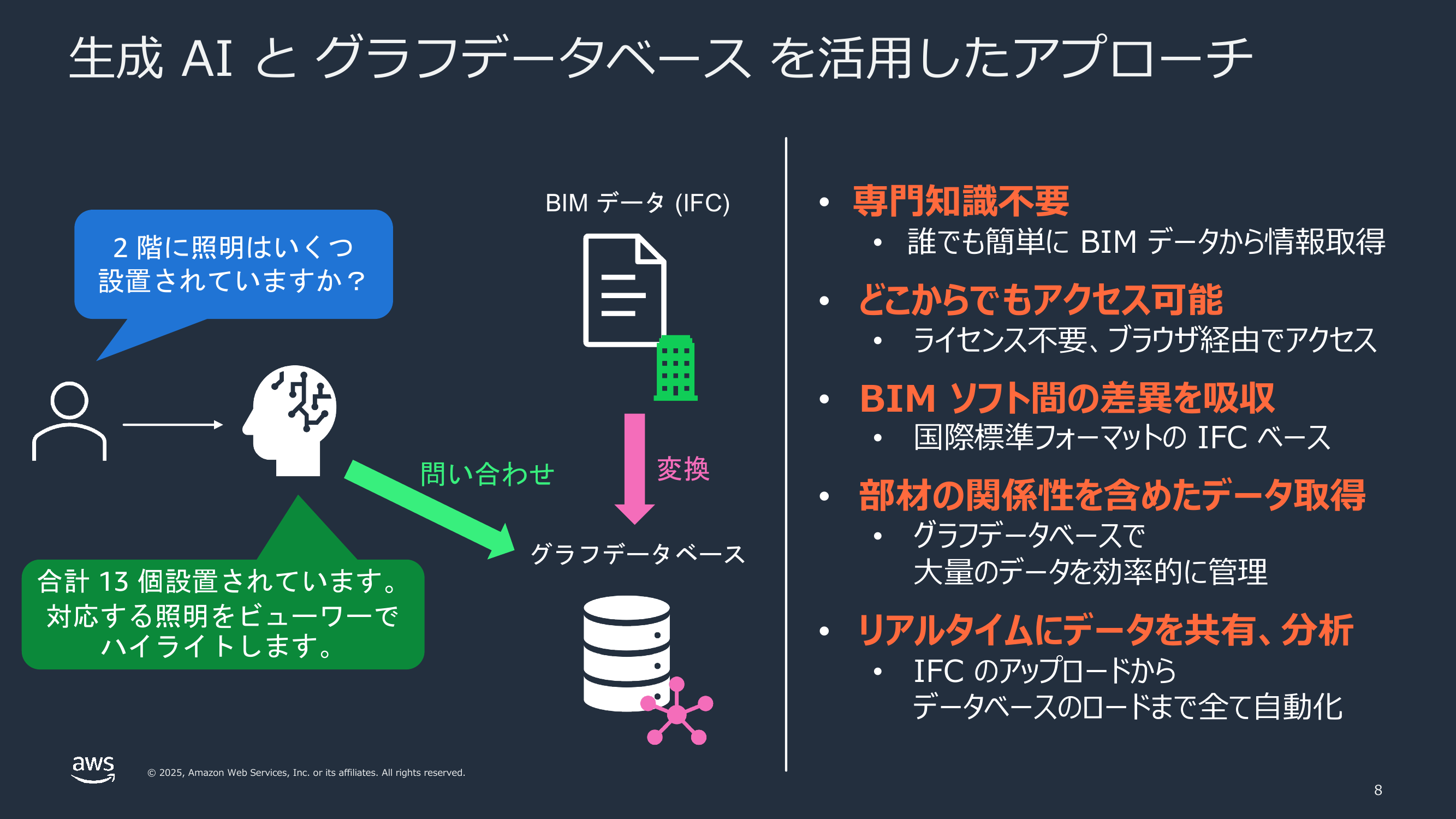
採用したアプローチを一言でまとめると、「IFC をグラフ (RDF グラフ) に変換してグラフデータベース (Amazon Neptune Serverless) に格納し、AI エージェントがクエリ言語 (SPARQL) で問い合わせる」というものです。
(B) のデータモデルとして RDF グラフを選んだ理由は、BIM データの性質にあります。BIM データは「壁が窓を含む」「階が要素を持つ」といった、モノ同士の関係の集まりで、構造的にはグラフそのものです。また、検索する際も、関係をいくつもたどっていく問い合わせが中心になります。こうした「関係をたどる」処理は、テーブルを JOIN し続けるリレーショナルデータベースよりも、関係をそのままエッジとして持つグラフデータベースのほうが素直に記述できます。
RDF(Resource Description Framework)についても簡単に補足します。RDF は、あらゆる事実を「主語 – 述語 – 目的語」の 3 つ組(トリプル)で表す W3C 標準のデータモデルです。たとえば「Wall_001 は Window_002 を含む」という事実は、Wall_001 - hasSubElement - Window_002 というトリプルで表せます。これを大量に集めると、ノード(モノ)とエッジ(関係)からなるグラフになります。
グラフの表現方法は他にもありますが、今回 RDF を選んだのは、既存の資産をそのまま活かせるためです。建設業界で広く使われている IFC を Linked Building Data(LBD)系のオントロジーで RDF 化する考え方や OSS が整備されており、さらに Amazon Neptune がマネージドサービスとして RDF / SPARQL をサポートしています。これにより、変換パイプラインとデータベース運用のいずれも、ゼロから構築する必要がありません。
アーキテクチャ
全体のアーキテクチャは以下の通りです。
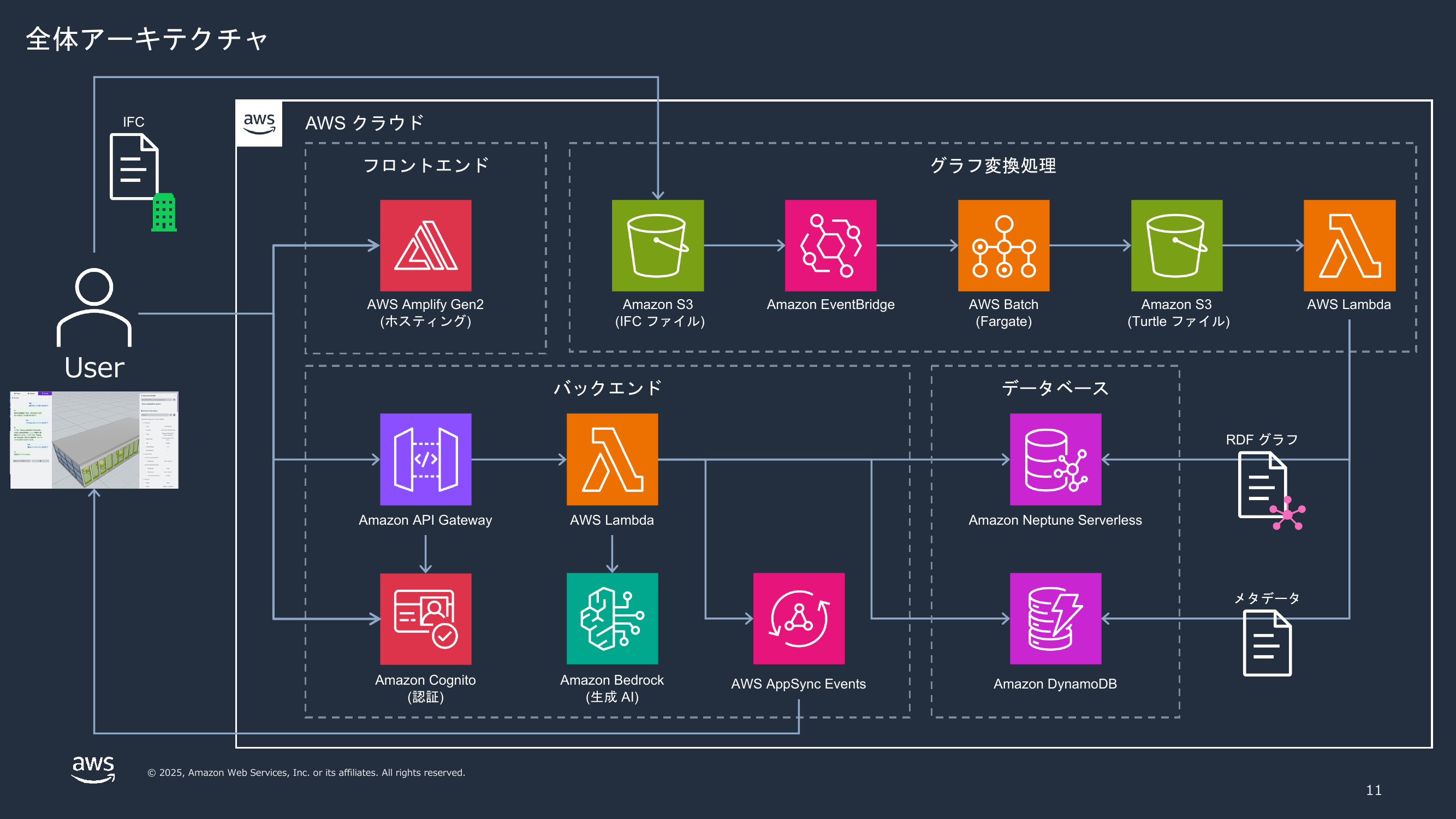
処理の流れは大きく 2 系統に分かれます。
(1) 取り込み系: IFC → RDF グラフ → Neptune へのロード
- ユーザーが IFC ファイルを Amazon S3 にアップロード
- S3 イベントを Amazon EventBridge で受け、AWS Batch で変換用コンテナを起動
- コンテナ内で IFC → Turtle 変換ツールを実行し、IFC を Turtle 形式(RDF を表現するテキスト形式の 1 つ)のファイルに変換して S3 へ書き戻す
- Turtle ファイルの S3 PUT イベントが AWS Lambda を起動し、Amazon Neptune の bulk loader API でグラフをロード
- 同じ Lambda が、後段の問い合わせで使うメタデータを Turtle から抽出して Amazon DynamoDB に保存
(2) 問い合わせ系: ユーザーの質問 → SPARQL → 自然言語回答
- ユーザーがフロントエンドから自然言語の建物に関する質問を投げる
- Amazon API Gateway を経由して、エージェント実装の Lambda を起動
- Lambda は対象 IFC のメタデータを DynamoDB から読み出し、Amazon Bedrock(Anthropic Claude)で SPARQL クエリを生成
- 生成した SPARQL を Neptune 上で実行し、結果を Bedrock で自然言語に整形してユーザーに返す
- 中間結果と最終回答は AWS AppSync Events で配信し、フロントの 3D ビューワー上で対象オブジェクトをハイライト
なお、ここで出てきた「Turtle(タートル)」は RDF を表現するファイル形式の 1 つで、人間が読み書きしやすいように設計された構文です。次章で実例を載せます。
3. 主要コンポーネントの実装
ここからは実装の中身に入ります。(B) のアプローチで実装上のポイントになるのは、「IFC をどんな形の RDF グラフにするか」と「AI にどう SPARQL を書かせるか」の 2 点です。この章では RDF グラフのモデリングや AI アプリの実装に踏み込むため、グラフデータベースや生成 AI の開発経験があると読み進めやすい内容です。各節の冒頭に要約を置いているので、詳細を飛ばしても流れは追えるようにしています。
3.1 IFC を RDF グラフに変換する
要約: IFC を RDF に変換すると、「建物 → 階 → 要素」という階層構造が、そのままグラフのノードとエッジになります。リレーショナルデータベースのような JOIN なしで関係をたどれるので、後段の問い合わせが書きやすくなります。
本ブログで紹介するソリューションでは、IFC からの RDF 変換に IFCtoLBD という OSS を使用しています。これは、IFC ファイルを、グラフとして扱いやすい RDF(Turtle 形式)に変換してくれるツールです。変換後のデータは、Linked Building Data(LBD)で整備されている公開オントロジー(建物データの語彙を定めたもの。建物トポロジーを表す BOT など)に沿った形になります。本実装では、この変換作業を AWS Batch のコンテナで実行しています。
変換後の Turtle は、たとえば次のようになります(1 章で示した IFC と同じ建物の変換結果からの抜粋です)。
@prefix bot: <https://w3id.org/bot#> .
@prefix props: <http://lbd.arch.rwth-aachen.de/props#> .
@prefix inst: <https://lbd.example.com/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# 建物(Building)— 配下に階が 2 つ
inst:building_3a24811f-0105-46f1-b13d-1c585f560635
a bot:Building ;
bot:hasStorey inst:storey_3a24811f-0105-46f1-b13d-1c58a0a9fa61 ,
inst:storey_3a24811f-0105-46f1-b13d-1c58a0a9ff4b ;
props:numberOfStoreys_property_simple 2 ;
props:globalIdIfcRoot_attribute_simple "0w984V0GL6yR4z75XVLWOr" .
# 階(Storey)が要素(Element)を含む
inst:storey_3a24811f-0105-46f1-b13d-1c58a0a9fa61
a bot:Storey ;
rdfs:label "Nivel 1" ;
props:elevationIfcBuildingStorey_attribute_simple "0."^^xsd:double ;
bot:containsElement inst:wall_ac9cc010-0e8f-4c9e-b289-81fb60a309bf ,
inst:slab_76178dce-ff53-4da5-b52a-f5f1ad7930e7 ,
inst:window_ac9cc010-0e8f-4c9e-b289-81fb60a3f63e .
# ... (door, furniture など同階の要素が続く)
# 壁(Element)— 9 つの窓をサブ要素として持つ
inst:wall_ac9cc010-0e8f-4c9e-b289-81fb60a309bf
a bot:Element ;
rdfs:label "Muro básico:Partición con capa de yeso:163541" ;
props:globalIdIfcRoot_attribute_simple "2idC0G3ezCdhA9WVjWemc$" ;
props:objectTypeIfcObject_attribute_simple "Muro básico:Partición con capa de yeso" ;
props:loadBearing_property_simple false ;
props:isExternal_property_simple false ;
bot:hasSubElement inst:window_ac9cc010-0e8f-4c9e-b289-81fb60a3f60b ,
inst:window_ac9cc010-0e8f-4c9e-b289-81fb60a3f608 ,
inst:window_ac9cc010-0e8f-4c9e-b289-81fb60a3f673 .
# ... (計 9 個の窓が続く)
# 窓(Element)— IFC 由来の属性がリテラル値で並ぶ
inst:window_ac9cc010-0e8f-4c9e-b289-81fb60a3f60b
a bot:Element ;
rdfs:label "Ventana simple:100 x 100 cm:164193" ;
props:globalIdIfcRoot_attribute_simple "2idC0G3ezCdhA9WVjWe$OB" ;
props:objectTypeIfcObject_attribute_simple "Ventana simple:100 x 100 cm" ;
props:overallWidthIfcWindow_attribute_simple "1."^^xsd:double ;
props:overallHeightIfcWindow_attribute_simple "2.3"^^xsd:double ;
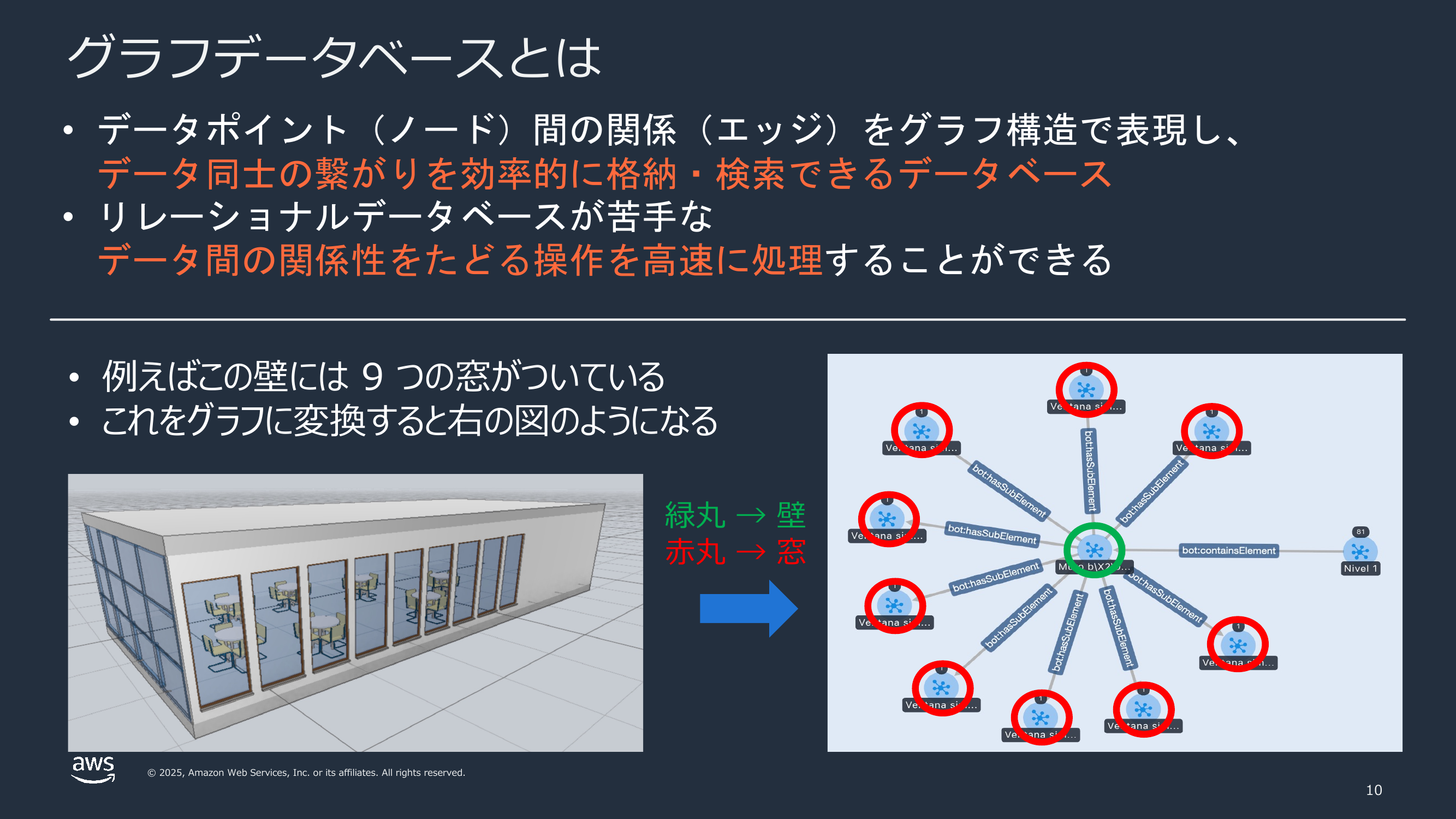
props:thermalTransmittance_property_simple 6.7069 .注目してほしいのは次の点です。
bot:Building/bot:Storeyの階層とbot:Elementのフラットな要素集合: 建物 → 階など、馴染みのある階層関係がbot:hasStoreyでグラフ化されます。各階が直接持つ部材はbot:containsElementで壁・スラブ・窓・扉・家具・方立などを指し、これらはすべてbot:Elementクラスでラベル付けされます- 壁と窓のようなサブ要素の関係: 壁に埋まっている窓は
bot:hasSubElementで壁と関係性を持ちます。上の壁は 9 個の窓を含む要素で、これをたどれば「この壁には窓が何個あるか」という質問がそのまま 1 ホップのグラフ走査になります props:接頭辞の属性: 寸法・面積・体積・グローバル ID・熱貫流率(thermalTransmittance)・外部面かどうか(isExternal)といった IFC 由来の属性は、props:名前空間配下のプロパティとしてリテラル値で付与されます。props:globalIdIfcRoot_attribute_simpleは IFC のGlobalIdにあたり、ビューワー上のハイライトなど、3D モデルのオブジェクトと紐付ける際のキーになります。
このように、「Wall ノードが Window ノードを hasSubElement で含み、寸法はリテラル属性として持つ」というシンプルなモデルで建物全体を表現できます。リレーショナルデータベースのように「壁テーブル」「窓テーブル」を JOIN する必要はなく、関係をそのまま辿ることができます。
3.2 ファイル単位で名前空間を分ける(Named Graph)
要約: 複数の IFC を 1 つの Neptune に同居させると要素 URI が衝突します。RDF の Named Graph でファイルごとにグラフ空間を分けておくと、衝突を防ぎつつ「特定の建物だけに問い合わせる」のも簡単になります。
複数の IFC ファイルを 1 つの Neptune クラスタに同居させると、要素 URI が衝突したり、特定のファイルだけを対象にした問い合わせが書きづらくなったりします。本実装では RDF の Named Graph を使い、ファイルごとに専用のグラフ空間を割り当てています。
- ファイル
building-A.ifc→ Named Graph URIhttp://example.com/graphs/ifc/building-A - ファイル
building-B.ifc→ Named Graph URIhttp://example.com/graphs/ifc/building-B
SPARQL では GRAPH <...> 句で対象を絞り込めるため、後述のクエリも基本的にこの形になります。Neptune の bulk loader はリクエストパラメータの parserConfiguration.namedGraphUri でロード先のグラフを指定できるので、ロードの時点で分割しています。
3.3 自然言語を SPARQL に変換する(text-to-SPARQL)
要約: ユーザーの質問を AI が SPARQL に翻訳し、Neptune で実行し、結果を再び自然言語に戻します。LangChain の既製チェーンをベースに、LangGraph で 2 ノード構成にまとめています。クエリの精度を上げるうえで一番効くのは、「お手本のクエリ例(Few-Shot)」をプロンプトに同梱することです。
問い合わせ系の中心は、ユーザーの自然言語の質問を SPARQL クエリに変換し、結果を再び自然言語で返す、いわゆる text-to-SPARQL の処理です。
本実装のベースには LangChain の create_neptune_sparql_qa_chain を採用しています。これは「スキーマを AI に渡して SPARQL を生成 → Neptune で実行 → 結果を AI に渡して自然言語化」という一連のチェーンが実装されています。
全体の処理フローは以下のとおりです。
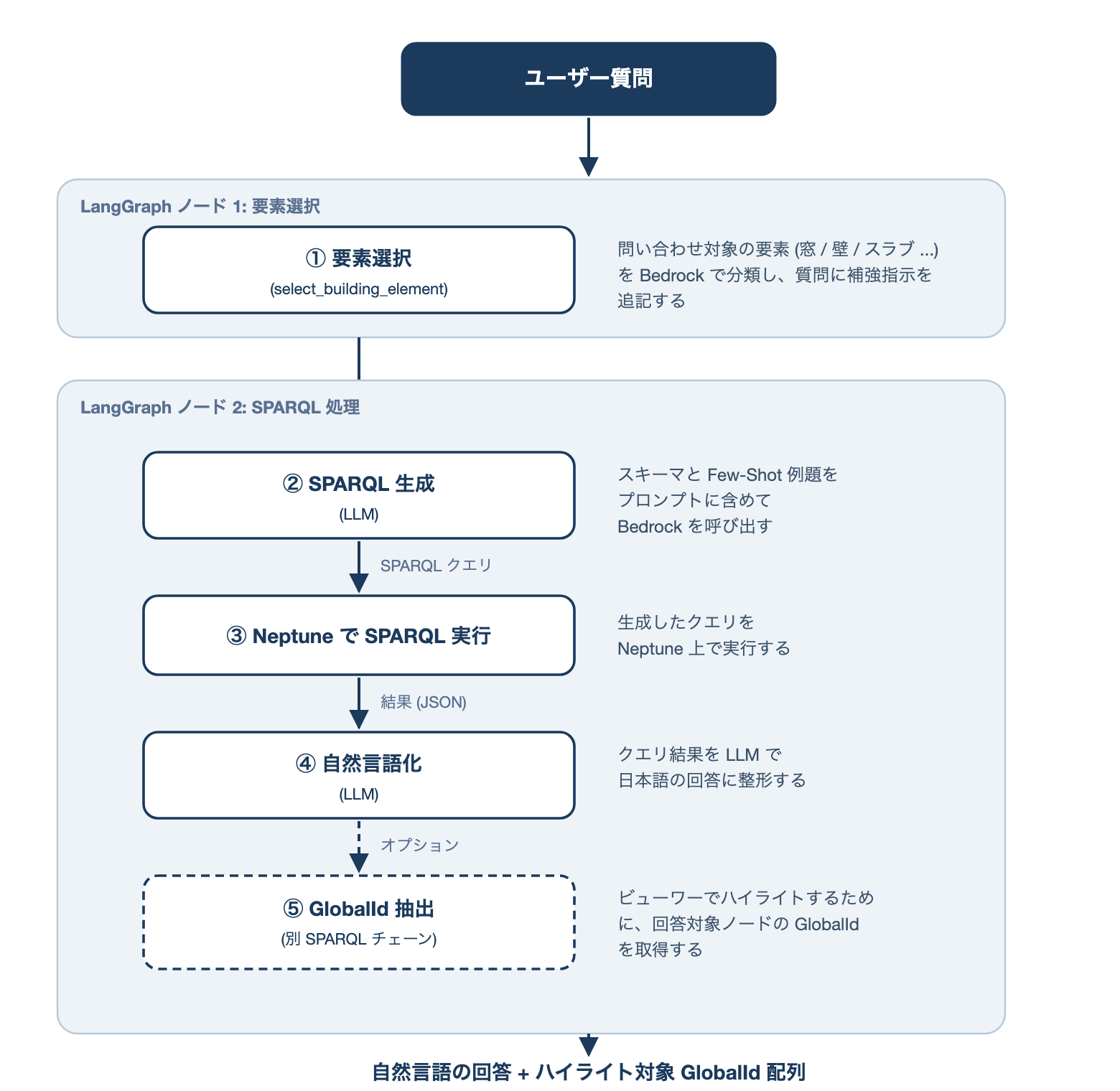
実装上は、LangGraph を使って ① の要素選択ノード と ② 〜 ⑤ をまとめた SPARQL 処理ノード の 2 ノードにまとめており、後者のノードの中で LangChain のチェーンを順に呼び出しています。
AI に SPARQL を生成させるときに効果的になるのが Few-Shot プロンプティング、つまり「こういう質問にはこういうクエリを書く」という例題をプロンプトに同梱することです。本実装では、IFC ファイルをロードするタイミングで、その IFC に含まれる要素タイプを参考にしながら、問い合わせ例の質問・SPARQL ペアを自動生成して DynamoDB に保存しています。問い合わせ時にはここから読み出してプロンプトに差し込みます。
3.4 必要なスキーマだけを DynamoDB から読み出す
要約: 既製チェーンをそのまま使うと、DB 上の全クラス・全述語をプロンプトに載せてしまい、IFC のように要素が多いと応答が遅く、コストもかさみます。本節では、必要なスキーマだけを事前に切り出して持っておく工夫を紹介します。
LangChain の create_neptune_sparql_qa_chain をデフォルトのまま使うと、内部の NeptuneRdfGraph が、対象データベース上のすべてのクラスと述語をスキーマとして取得し、まるごとプロンプトに含めます。小さいオントロジーなら問題ありませんが、IFC のように要素タイプ・属性が多い場合は、初回応答の遅さとプロンプトサイズの増加が問題になります。既製チェーンの「全スキーマをそのまま渡す」前提が、IFC の規模では合わなくなる、ということです。
そこで本実装では、NeptuneRdfGraph を継承した NamedGraphAwareNeptuneRdf クラスを用意し、次の 2 点を変えました。
- スキーマクエリを Named Graph 単位に絞る:
GRAPH <namedGraphUri> { ... }で囲み、ファイル単位のスキーマだけを取得する - DynamoDB から事前ロード済みスキーマを使う: IFC ロード時にスキーマを抽出して DynamoDB に保存しておき、問い合わせ時は Neptune ではなく DynamoDB から読み出す
DynamoDB には、IFC ファイル 1 つにつき 1 レコードの形でメタデータを保存しています。1 レコードには、そのファイルのスキーマ(登場するクラスや述語の一覧)、Few-Shot 用のサンプルなどをまとめています。中身のイメージは次のとおりです。
{
"loadStatus": "READY",
"fileName": "small-l1-p",
"namedGraphUri": "http://example.com/graphs/ifc/small-l1-p",
"schema": {
"classes": [ {"uri": "https://w3id.org/bot#Building", "local": "Building"}, ... ],
"rels": [ {"uri": "https://w3id.org/bot#hasSubElement", "local": "hasSubElement"}, ... ],
"dtprops": [ {"uri": ".../thermalTransmittance_property_simple", "local": "..."}, ... ],
"oprops": []
},
"resourceTypes": { "wall": 3, "window": 10, "door": 1, "slab": 2, ... },
"examples": "<question>...</question><sparql>...</sparql>"
}これにより、Neptune へのスキーマ問い合わせの往復が省けて応答時間が短くなり、プロンプトに載せるスキーマもそのファイルに必要な分だけになるので、コンテキストの消費とトークンコストを抑えられます。
参考までに、最終的に AI が生成する SPARQL は次のような形になります(ユーザーの質問は「特定の壁に含まれる窓の数は?」)。
PREFIX props: <http://lbd.arch.rwth-aachen.de/props#>
PREFIX bot: <https://w3id.org/bot#>
PREFIX inst: <https://lbd.example.com/>
SELECT (COUNT(?window) AS ?windowCount) WHERE {
GRAPH <http://example.com/graphs/ifc/small-l1-p> {
?wall props:globalIdIfcRoot_attribute_simple "2idC0G3ezCdhA9WVjWemc$" .
?wall bot:hasSubElement ?window .
FILTER(STRSTARTS(STR(?window), STR(inst:window_)))
}
}GRAPH <...> で対象 IFC を絞り、hasSubElement で壁配下の要素をたどり、URI 接頭辞 inst:window_ の一致で窓に絞る、という意図がそのままクエリになっています。先ほどの 9 個の窓を持つ壁にこのクエリを実行すると、windowCount = 9 が返ります。
3.5 動作イメージ
ここまでの仕組みを通すと、ユーザーから見た動作は次のようになります。自然言語で質問を投げると、AI が SPARQL を生成・実行して自然言語で回答を返し、同時に該当する建物要素が 3D ビューワー上でハイライトされます。

質問する側は SPARQL や IFC の内部構造を知らなくても、「窓の熱貫流率を教えて」「家具は全部で何個ある?」と尋ねるだけで、回答と該当箇所の表示を同時に得られます。1 章で触れた、IFC の構造を知らないと素朴な問い合わせすら難しいという問題が、この画面の中で解消されていることが見て取れます。
4. GNN(Graph Neural Network)と組み合わせた発展
要約: text-to-SPARQL は「決まった問い合わせ」に強い一方、BIM の繋がり方そのものから何かを予測するタスクは、生成 AI 単体では扱いづらい領域です。Neptune に格納したグラフデータを起点に、用途に応じたグラフを構築して GNN を併用すると、干渉解消・熱負荷予測・意味付け補強といったタスクに広げられます。
生成 AI の発展により、「以前は自前で機械学習モデルを訓練していたタスクも、AI エージェントに任せれば対応できる」場面は増えています。本ブログの text-to-SPARQL もその流れの上にあります。
一方で、BIM のように、ノードとエッジの繋がり方そのものに意味があるデータに対しては、グラフ構造を学習する Graph Neural Network(GNN)が効果的なタスクも残っています。GNN は、各ノードの属性と隣接ノードからの情報を集約してベクトル表現を学習する深層学習モデルです。グラフデータベースに格納したデータを基盤として訓練データに利用できるため、本ブログのアーキテクチャと組み合わせやすい拡張先です。
BIM の分野で GNN が効果を発揮するユースケースを、3 つ紹介します。いずれも「答えが既存データの検索では得られず、予測が必要になる」という点で、GNN が効果的な領域です。
4.1 干渉解消(クラッシュ・レゾリューション)の予測
干渉チェックツールが検出した干渉を解消するには、どのコンポーネントを動かすかの判断が必要ですが、あるコンポーネントを動かすと依存関係を通じて別の干渉が新たに生じる(変更の波及)ため、全体として変更影響を最小化する解を見つけるのが難しいという課題があります。これが GNN に向いているのは、最適な変更対象が周辺コンポーネントとの依存関係に左右され、単体の属性だけでは決まらないからです。Hu ら(2023, Clash context representation and change component prediction based on graph convolutional network in MEP disciplines)は、干渉が起きたコンポーネントと周辺の依存関係をグラフで表現し、Graph Convolutional Network で「どのコンポーネントを修正すべきか」を予測する手法を提案しています。周辺への波及を加味して判断できる点が特徴です。
4.2 部屋やゾーンを跨いだ熱負荷・エネルギー予測
従来の機械学習モデルは、建物全体を 1 ゾーンとして扱うか、各ゾーンを独立に扱うかのどちらかで、ゾーン間の熱の相互作用を捉えきれないという課題がありました。GNN はゾーンをノード、ゾーン間の隣接関係をエッジとしてグラフ化できるので、熱伝達を構造として取り込んだ上で予測できます。Jia ら(2024, Temporal graph attention network for building thermal load prediction)は Graph Attention Network と GRU を組み合わせ、多ゾーンの熱負荷を同時に予測するモデルを提案しています。
4.3 BIM の意味付け補強(セマンティック・エンリッチメント)
BIM モデルは、設計者やツールの違いによって要素の分類ラベルや属性が不揃い・不完全になりやすく、これが下流の数量積算や確認申請の自動チェックに影響します。Austern ら(2024, Incorporating Context into BIM-Derived Data—Leveraging Graph Neural Networks for Building Element Classification)は、GNN ベースの要素分類が、幾何特徴のみを見る従来手法(ロジスティック回帰やランダムフォレストなど)よりも精度で上回ることを示しています。「予測ラベルと登録ラベルが食い違う要素」を要レビュー候補として抽出する整合性チェックにも応用でき、ルールエンジンだけでは難しい BIM データの品質維持に有効な領域です。
AWS でのアプローチ
GNN を AWS で動かす場合、まず候補になるのが Amazon Neptune ML です。Neptune に格納したグラフから、GNN モデルを訓練・推論できる機能で、ノード分類・回帰、エッジ分類・回帰、リンク予測が標準でサポートされています。
5. まとめ
本ブログでは、BIM データ(IFC)に AI エージェントからアクセスさせる 3 つのアプローチを整理した上で、そのうちの「IFC をグラフに変換してグラフデータベースに格納し、AI エージェントが問い合わせる」という構成を、実装レベルで解説しました。要点は次のとおりです。
- IFC → Turtle の変換を AWS Batch で実行し、
bot:/props:系のオントロジーで「建物 → 階 → 要素」のグラフを生成 - 自然言語の質問から SPARQL を生成して回答する仕組み(text-to-SPARQL)を構築。各ファイルのスキーマやサンプルクエリを事前に用意しておくことで AI エージェントが素早く正確に情報を取得できる
- 建物のグラフデータは、Amazon Neptune ML で GNN を組み合わせて、干渉解消の優先度予測・多ゾーンの熱負荷予測・BIM の意味付け補強といった、生成 AI 単体では解決しにくいタスクに広げられる可能性がある
このアプローチの一番の利点は、データ構造を自分たちの用途に合わせて設計できることです。1 章で見たアプローチの比較に戻ると、ベンダー API の範囲で実現する方法や、ライブラリで IFC をその場で読む方法に対して、本ブログで紹介した手法は IFC を予め整理した状態で持っておくことで、複数ファイルの横断検索や集計の書きやすさも、他システムのデータとの突き合わせもスキーマ設計で吸収できます。一方、柔軟性と引き換えに変換パイプラインやデータベースを設計・運用するコストがかかるため、ユースケースに応じて、上手く使い分けるのが良いでしょう。