Amazon Web Services ブログ
自分で事前にトレーニングした MXNet または TensorFlow のモデルを Amazon SageMaker に導入する
Amazon SageMaker は、ML モデルをトレーニングおよびホストするための容易なスケーラビリティとディストリビューションを提供するだけでなく、モデルをトレーニングするプロセスとモデルのデプロイメントを分離するようにモジュール化されています。これは、Amazon SageMaker 以外でトレーニングされたモデルを SageMaker に導入してデプロイできることを意味します。すでにトレーニングを受けたモデルがあり、パイプライン全体ではなく SageMaker のホスティング部分だけを使用したい場合は、これは非常に便利です。また、これは自分のモデルをトレーニングしないが、事前にトレーニングされたモデルを購入する場合にも便利です。
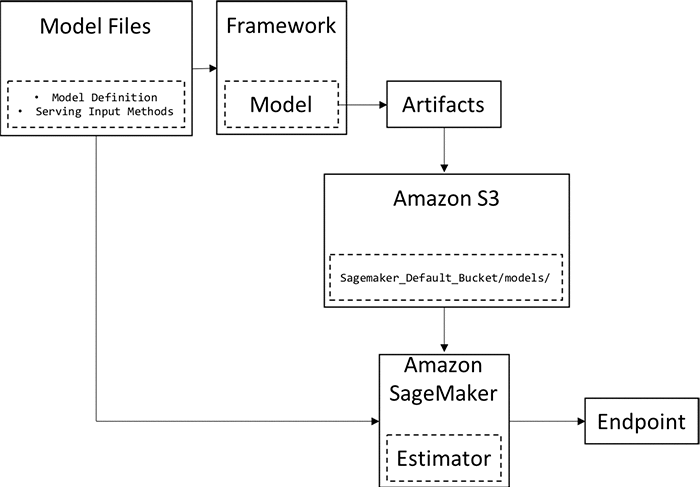
このブログ記事では、TensorFlow または MXNet でトレーニングした自分のモデルを Amazon SageMaker にデプロイする方法について説明します。以下は、プロセス全体の概要です。
- ステップ 1: モデル定義を、選択したフレームワークで記述します。
- ステップ 2: モデルを、そのフレームワークでトレーニングします。
- ステップ 3: モデルをエクスポートし、Amazon SageMaker が理解できるモデル成果物を作成します。
- ステップ 4: モデル成果物を Amazon S3 バケットにアップロードします。
- ステップ 5: モデル定義、モデル成果物、Amazon SageMaker Python SDK を使用して、SageMaker モデルを作成します。
- ステップ 6: SageMaker モデルをエンドポイントとしてデプロイします。
モデルとは何か?、そしてどうすれば手に入るのか?
トレーニングされたモデルファイルとは、単にトレーニングプロセスによって作成されたモデル成果物です。これには、モデルのすべてのパラメータの値と、モデルのアーキテクチャに関する追加のメタデータが含まれていて、これらのパラメータが互いにどのように接続されているかを示します。フレームワークが異なると、モデルファイルをエクスポートする方法も異なります。
TensorFlow
TensorFlow のモデルは、トレーニングされた TensorFlow Estimator からエクスポートできます。モデルファイルは、Amazon SageMaker がそれを理解できるようにするためのプロトコルに従わなければなりません。 単純な TensorFlow Estimator の次の定義を考えてみましょう。
これは、4 次元の数値列機能を入力として予想する分類子モデルであり、 INPUT_TENSOR_NAME を辞書キーとします。すべての TensorFlow モデルのエクスポートには、入力をサーブする機能が必要です。入力をサーブする機能のジョブは、エクスポートされたモデルがデプロイされたときに入力パイプラインを提供することです。幸いにも、TensorFlow には、このサービング機能を作成するためのビルダーがあります。以下のコードを検討してみましょう。
このメソッドは、 feature_spec を作成しますが、これは、文字列→TensorFlow モデルが予想する特徴の値の辞書です。これは、 estimator_fn が入力の特徴に予想するのと 同じ構造と次元を持つ必要があります。TensorFlow のエクスポートメソッドを使用して、モデルをエクスポートすることができます。

Amazon SageMaker は、TensorFlow モデルが「ターボール」 (tar.gz ファイル) であり、エクスポートされたときに、辞書 export/Servo 内にすべての成果物があると予想しています。以下のコードは、これをどのように達成できるかを示しています。
MXNet
TensorFlow Estimator と同様に、MXNet は MXNet モジュールを使用してモデルを表現します。 モデルのパラメーターファイルがチェックポイントメソッドを使用して保存されていることに加えて、Amazon SageMaker は入力データシェイプが .json ファイルとして保存されている必要があります。MXNet チェックポイントセーバーを変更するだけで、Amazon SageMaker が理解できる適切なモデル成果物を作成することができます。以下のコードがこれを実現します。
Amazon SageMaker でモデルをホストする方法
モデルをホスティングする前に、モデル成果物を Amazon S3 バケットに移動する必要があります。成果物が S3 バケットに入った後、モデルをエンドポイントとして Amazon SageMaker でデプロイできます。これらのタスクを実行するために、Amazon SageMaker に付属するものを使用できます。Python SDK は、モデルを S3 にアップロードするのに便利な API を提供します。
このアップロードを確認するには、AWS アカウントですでに作成されている Amazon SageMaker のデフォルトバケットを確認します。プレフィックスは、モデルが保存されているディレクトリです。S3 にあるこのモデルを Amazon SageMaker エンドポイントに変換するには、2 ステップのプロセスが必要です。まず、SageMaker モデルを作成し、デプロイするモデルを準備し、モデルコンストラクタを初期化します。
TensorFlow モデル成果物の場合:
MXNet モデル成果物の場合:
どちらのフレームワークの構文も似ており、 SageMaker Estimator モデルを初期化します。 このentry_point 引数は、モデル成果物が作成されたコードを含むファイルになります。モデルの定義と、エンドポイントでモデルを再構築するために必要なサービス機能が含まれているため、このファイルは重要です。コードが記述されたとき、またはモデルが作成されたときを制限しません。モデルとコードのバージョン管理が一致する限り、同じように動作します。 API の単純な deploy コマンドがモデルをホストします。
引数は、モデルをデプロイするインスタンスの数とタイプを選択するオプションを提供します。見た目はシンプルですが、実際には多くのことを行います。ファイルとモデルを含むコンテナを作成し、仕様に従ってハードウェアをプロビジョニングし、推論を実行できるエンドポイントを返します。このメソッドが完了するまでに数分かかる場合があります。エンドポイントの作成後、SDK はエンドポイントを照会するメソッドも提供します。TensorFlow モデルの場合、特徴の次元は 4 でした。TensorFlow エンドポイントを照会するには、次の操作を行います。
作業が終わったら、使用していないコンピューティングリソースに課金されないために、エンドポイントを破棄する必要があります。SDK には、エンドポイントを削除するメソッドも用意されています。
自分のモデルを SageMaker フレームワークに組み込む場合、特定のバージョンのフレームワークに対して、Amazon SageMaker エンドポイントのコンテナが独立して管理されることを念頭においてください。たとえば、MXNet 1.0 でトレーニングされたモデルは、MXNet バージョン 0.12 をサポートする SageMaker コンテナにはデプロイできません。成果物ビルダーは、互換性がある成果物が構築されることを保証する必要があります。これにより、バージョン選択に適切なパラメータを使用して複数のバージョンのモデルを導入することができます。
ノートブック
このブログ記事にあるコードと詳細は、ノートブック形式でも入手できます。Amazon SageMaker にモデルを導入する方法を、TensorFlow および MXNet のそれぞれの場合について示す 2 つのノートブックがあります。完全なチュートリアルを参照してください。
まとめ
このブログ記事では、TensorFlow または MXNet を使用して Amazon SageMaker のセットアップ以外でトレーニングを受けたモデルを、Amazon SageMaker を使用してデプロイする方法を紹介しました。このブログでは、TensorFlow または MXNet から Amazon SageMaker で使用できる形式にモデルをエクスポートする方法を紹介しています。
今回のブログ投稿者について
 Ragav Venkatesan は、AWS ディープラーニングの研究科学者です。彼は、アリゾナ州立大学で電気工学の修士号とコンピュータサイエンスの博士号を取得しています。現在の研究領域には、ニューラルネットワーク圧縮とコンピュータビジョンアルゴリズムが含まれます。
Ragav Venkatesan は、AWS ディープラーニングの研究科学者です。彼は、アリゾナ州立大学で電気工学の修士号とコンピュータサイエンスの博士号を取得しています。現在の研究領域には、ニューラルネットワーク圧縮とコンピュータビジョンアルゴリズムが含まれます。