Amazon Web Services ブログ
バグ修正のパラドックス:AI エージェントが正常なコードを壊してしまう理由
※ 本記事は 2026 年 2 月 19 日に公開された Jatin Arora による The bug fix paradox: why AI agents keep breaking working code を翻訳した記事となります。
過剰解決の問題
多くのチームが経験するパターンがあります。AI エージェントにバグ修正を依頼すると、3 つのヘルパー関数をリファクタリングし、防御的な null チェックを追加し、すでにパスしているエッジケースに対して何十もの新しいテストを書いてしまいます。さらに悪いことに、正常に動作していたアプリケーションの部分まで変更してしまいます。メスを求めたのに、スレッジハンマーが返ってきたようなものです。
エージェントは人間の約 2 倍の確率でガード節や防御的なエラーハンドリングを追加します。私たちなら「なぜ null なのか?」と問うところを、エージェントは if (x == null) を追加して先に進んでしまいます。適切な制約がなければ、エージェントと対話を重ねるほど、元の意図からどんどん乖離していきます。実際の修正は、不要な変更の山に埋もれてしまいます。問題の本質は、あなたとエージェントが「何を修正すべきか」と「何をそのままにすべきか」の境界を共有していないことにあります。Kiro のバグ修正ワークフローは、この境界を明示的にするために設計されています。私たちはこのアプローチをプロパティ指向コード進化 (property-aware code evolution) と呼んでいます。
プロパティ指向コード進化
すべてのバグ修正には 2つの目的があります。バグのある動作を修正することと、それ以外のすべての正常な機能を維持することです。この意図は入力空間を分割しますが、その分割は通常、暗黙的なままです。これを明示的かつテスト可能にすることができます。
バグ条件
バグ条件 C は、バグが発生するトリガーを特定します。入力空間を 2 つに分割します。
- C を満たすシナリオ → バグが現れる場所。ここでは修正が必要です。
- C を満たさないシナリオ → 動作が正しい場所。ここでは維持が必要です。
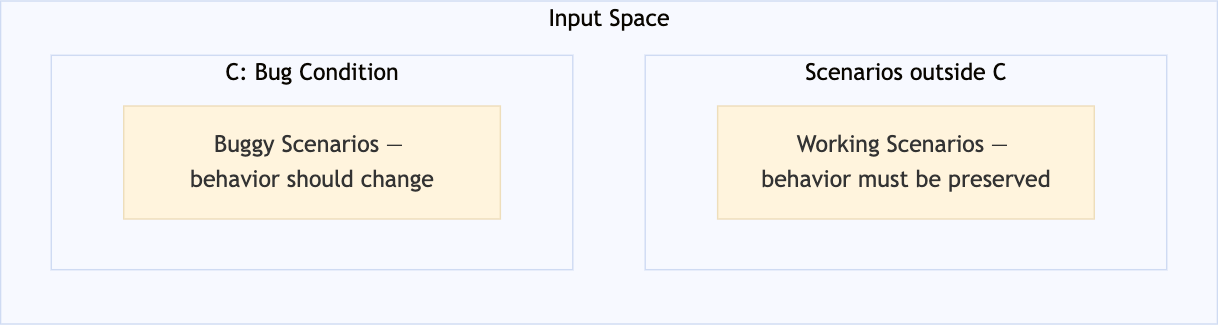
例えば、二分探索木( BST )からノードを削除する際、右の子に左の部分木がない場合にクラッシュするなら、C は「ノードが2つの子を持ち、かつ node.right.left がNone」となります。それ以外のすべての削除シナリオは C の範囲外であり、触れずにそのまま保つべきです。
経験豊富なエンジニアは誰もが C について考えていますが、多くの場合それは暗黙的です。しかし C が明示的で共有された成果物になっていない限り、エージェントの考える境界があなたの考える境界と一致している保証はありません。C が暗黙的なままだと、3 つの問題が起こり得ます。
- エージェントが境界から逸脱する : バグレポートが正確であっても、エージェントには境界の永続的な記録がありません。各ステップで境界をゼロから再解釈するため、複数のステップを経るうちに元の意図から乖離していきます。
- エージェントが境界を独自に作り上げる : バグレポートが曖昧な場合、エージェントはエンジニアと同様にギャップを自分の推測で埋めます。違いは、エージェントがその推測を明示しないことです。コードレビューで不一致に気づいた時には、パッチはすでにその推測を前提に構築されています。
- エージェントが境界を守ったかどうかを確認できない : 明示的な C がなければ、他のすべてが正常に動作しているかを体系的に確認する方法がありません。エージェントは修正を確認できますが、境界内に留まったかどうかは確認できません。
C は境界を引きますが、それだけでは不十分です。C はバグが発生するタイミングを教えてくれますが、「修正された」とはどういう意味かは教えてくれません。事後条件 (postcondition) P がそのギャップを埋めます。P は C が成立する入力に対してコードが何をすべきかを定義します。BST の削除がクラッシュする場合、P は「削除操作がクラッシュせず、ノードを削除し、BST の不変条件を保持する」となります。
P がなければ、エージェントは try/except でエラーを抑制して「修正済み」と判断してしまいます。P によって、「正しい」とはどういう意味かに沿った実装が強制されます。
修正プロパティと保持プロパティ
プロパティ指向コード進化では、コードを書く前にプロパティを定義します。プロパティとはテスト可能な主張です。ある条件を満たすすべての入力に対して、ある保証が成立するというものです。バグ条件 C と事後条件 P を使って、2 つのプロパティを定義します。
- 修正プロパティ (C ⟹ P): C が成立する場合、パッチ適用後のコードは P を満たします。
- 例: 修正プロパティは「ノードが 2 つの子を持ち
node.right.leftが None であるツリーに対して、delete が P を満たす」と主張します。そのようなツリーで delete を実行することで確認できます。1 つでもクラッシュすれば、プロパティは失敗です。
- 例: 修正プロパティは「ノードが 2 つの子を持ち
- 保持プロパティ (not C ⟹ 変化なし): C が成立しない場合、パッチ適用後のコードは元のコードと同一の動作をします。
- 例: 保持プロパティは「他のすべてのツリーに対して delete が同一の動作をする」と主張します。修正前後で C の外側のツリーに対して delete を実行して確認します。動作が変わればプロパティは失敗です。
この 2 つのプロパティは入力空間全体をカバーし、エージェントが修正を書く際の制約になります。どのパッチも、保持プロパティを壊すことなく修正プロパティをパスしなければなりません。私たちはこの方法論をプロパティ指向コード進化と呼んでいます。
Kiro のバグ修正ワークフローは、この方法論を内部で使用しています。Kiro はバグ条件、事後条件、修正プロパティと保持プロパティを提案します。あなたはそれらを一緒に洗練させ、Kiro が生成する仕様、テスト、修正はすべてそれらのプロパティから導き出されます。
Kiro のバグ修正ワークフローの実践: BST 削除バグ
以下は、古典的なデータ構造のバグを示す具体的なバグレポートです。
これを Kiro に貼り付けてバグ修正ワークフローを選択します。Kiro はすぐにパッチを書こうとはしません。1 行のコードも書く前に、バグのあるシナリオとそうでないシナリオを分割し、根本原因の仮説を立て、その仮説を検証します。
バグ修正ドキュメント
Kiro はバグレポートを分析し、3 つの要件カテゴリを含むバグ修正ドキュメントを生成します。現在の欠陥のある動作(Defect)、期待される修正(Correct)、そして維持されなければならない変更前の動作(Regression Prevention)です。
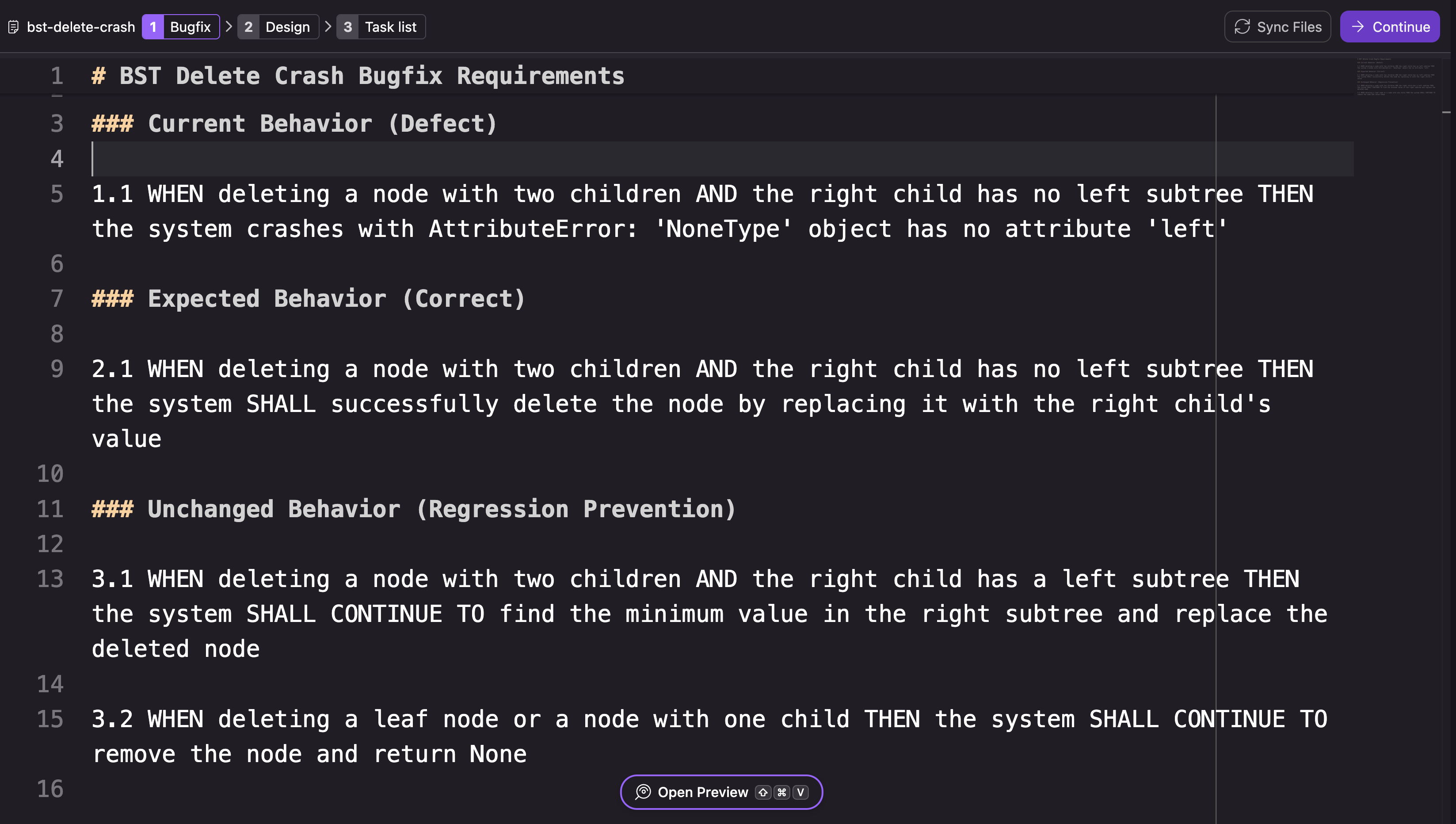
これはバグ条件 C によって定義された分割を反映しています。欠陥と修正の要件はバグのある入力を対象とし、維持の要件は変更されてはならない特定の動作を特定します。
設計: バグ条件と根本原因の仮説
バグ修正ドキュメントは自然言語でシナリオを分割します。Kiro はここでそれを形式化し、バグが存在する理由を調査します。
分割の形式化 : Kiro は欠陥と修正の要件からバグ条件 C を抽出します。
Kiro はまた、「修正された」とはどういう意味かを事後条件 P として形式化します。
根本原因のトレース : C と P が確立されたところで、Kiro はコードベースを読み込み、根本原因の仮説を構築します。C が成立する入力に対して、なぜクラッシュして P を満たさないのかを調べます。C が成立する入力の実行フローをトレースします。
C が成立する入力、例えば [5, 3, 7] から 5 を削除する場合、トレースは次のように評価されます。
仮説: _find_min が node.right ではなく node.right.left を受け取っています。C が成立する場合、node.right.left は定義上 None であるため、この呼び出しは常にクラッシュします。
チェックポイント : コードやテストを書く前に、Kiro は C、P、仮説をレビューのために提示します。この時点では何も生成されていません。C が狭すぎる、広すぎる、または間違ったシナリオを対象にしている場合、あなたはフィードバックして修正することが可能です。仮説が間違っている場合は、次のフェーズで検出されます。修正プロパティのテストは、修正前のコードで AttributeError で失敗するはずです。別の理由で失敗したり、まったく失敗しなかったりした場合、仮説は反証され、Kiro は修正を書く前に再分析します。
根本原因の仮説は設計フェーズをドキュメント以上のものにします。それは反証可能な予測です。この後のテスト戦略全体が、その仮説を確認または反証するために設計されています。
タスクプラン: 仮説の検証
Kiro は C を満たす入力がクラッシュするのは _find_min が None を受け取るためであると言う仮説を持っています。タスクプランは修正をする前にこの仮説を検証します。

Kiro はすべてのテストをまず修正前のコードに対して実行し、修正を適用してから再テストします。プランは 3 つのタスクに構成されます。
タスク 1 : Kiro は C の内側の入力に対するバグ条件テストを書き、期待される動作 (P) をエンコードします。修正前のコードに対して実行します。テストは失敗します。これにより、バグが C の予測通りの場所に存在することが確認されます。
タスク 2 : Kiro は C の外側の入力に対して修正前のコードを実行し、実際の動作を記録して、その動作を主張する保持テストを書きます。各テストは修正前のコードに対してパスするはずです。
タスク 3 : Kiro は根本原因の仮説に基づいてコードを修正し、バグ条件テストと保持テストを再実行します。失敗していたバグ条件テストがパスするようになっていれば修正は成功です。保持テストは引き続きパスします。なぜなら他に何も変わっていないはずだからです。もしバグ条件テストが失敗した場合、仮説が間違っていたことになり、Kiro はフラグを立てて別の修正を試みる前に再調査します。保持テストが反転した場合、修正に副作用があることになり、Kiro はパッチのスコープを絞り込みます。どちらの結果も次のアクションにつながります。
これはテスト駆動開発のレッド・グリーンサイクルと差分テスト (differential testing) を組み合わせたものです。バグ条件テストは修正前はレッド、修正後はグリーンになります。保持テストは修正前のコードの動作を記録し、修正後のコードが同じ入力に対して同じ動作をすることを主張します。修正前のコードが仕様として機能します。
修正前のテスト
両方のテストスイートは Hypothesis を使ったプロパティベーステストを使用します。特定のツリーに対するテストを書く代わりに、Kiro は修正プロパティと保持プロパティを宣言し、Hypothesis を使って数百のランダムなツリーを生成してそれらを確認します。(Kiro におけるプロパティベーステストの詳細については、Kiro : コードは仕様と一致していますか? 〜プロパティベーステストで「正しさ」を測定する〜 をご覧ください)。
なぜプロパティベーステストなのか?バグ条件はツリーの構造、具体的には node.right.left が存在するかどうかに依存します。その構造は組み合わせ的に変化します。ユニットテストでは、それをカバーするために何十ものツリーを手動で構築する必要があります。プロパティベーステストはその空間を自動的に探索し、手書きのスイートではカバーしにくい構造的な組み合わせを含む数百のツリーを生成します。
バグ条件テストによる修正プロパティの確認
このテストは修正プロパティをエンコードします。C が成立するすべてのツリーに対して、delete は成功し、ノードを削除し、BST の不変条件を保持するはずです。修正前のコードでは、_find_min(None) が None.left を試みるため AttributeError で失敗します。
保持テストによる保持プロパティの確認
このテストは保持プロパティをエンコードします。C が成立しないすべてのツリー(葉の削除、1 つの子を持つノードの削除、node.right.left が存在する 2 つの子を持つノードの削除)に対して、動作は変化しません。修正前のコードではパスします。これがベースラインです。修正後も、このテストはパスし続けなければなりません。
修正
バグ条件テストが仮説を確認し、保持テストがベースラインを記録したところで、Kiro は 1 行の修正を書きます。
Kiro は両方のテストスイートを再実行します。バグ条件テストがパスするようになり、修正が機能していることが検証されます。保持テストは引き続きパスし、他に何も変わっていないことが検証されます。
大規模な適用: RocketMQ のメモリリーク
Kiro は大規模なコードベースでも同じように機能します。実際の例として、Apache RocketMQ の HeartbeatSyncer におけるメモリリークを見てみましょう(元の PR、SWE-PolyBench)。HeartbeatSyncer は接続されたコンシューマーを並行マップで追跡します。エントリは登録時に追加され、登録解除時に削除されます。しかし、削除は一度も成功しません。マップは際限なく増大します。
バグを特定して修正するために、Kiro は同じワークフローに従います。根本原因の仮説はキーの不一致です。
挿入キーはコンシューマーグループがプレフィックスとして付加されますが、削除時のキーには付加されません。そのため両者は絶対に一致しません。登録解除は全て何もしない操作になります。バグ条件 C は、args が null でなく ClientChannelInfo を含む、あらゆる有効な CLIENT_UNREGISTER イベントです。すべての登録解除イベントでメモリリークが発生します。
修正はやはり 1 行ですが、保持の検証はより困難です。同じリスナーを通るコードパスは5つあります。args が null の場合、args が ClienetChannelInfo でない場合、マルチグループ登録、などです。挿入ロジックや他のイベントタイプも変更されてはなりません。C の外側の各シナリオには独自の保持テストがあり、Kiro が修正を適用する前に書かれてパスしています。
まとめ
プロパティ指向コード進化により、あなたと Kiro は同じ契約のもとで作業します。Kiro が境界と仮説の草案を作成し、あなたはそれにフィードバックし、再定義し、スコープを絞り込み、または別のアプローチを求めることができます。コードが書かれる時点で、何を変え、何を変えないのかについて双方が合意しています。
契約が崩れた場合、ワークフローがそれを明確にします。バグレポートが曖昧すぎて C を導出できない場合、Kiro はコードが書かれる前にフラグを立てます。根本原因の仮説が間違っている場合、バグ条件テストがそれを検出します。修正に副作用がある場合、保持テストがそれを検出します。各失敗が次に何をすべきかを教えてくれます。
プロパティ指向コード進化は、期待される振る舞いを機能的でテスト可能なプロパティとして表現できる変更に対して最も効果を発揮します。例えばロジックエラー、エッジケース、ランタイム例外、データ処理のバグなどです。一方でパフォーマンスや競合状態のような非機能的な関心事については、非決定的であり時間的推論を必要とすることが多いため、プロパティの表現がより困難です。それらをテスト可能な主張として表現する最良の方法を見つけることは、未解決の課題です。
プロパティ指向コード進化はバグ修正だけに留まりません。機能追加やリファクタリングも同じ二重の意図を持っています。境界内で動作を変更し、それ以外のすべてを保持することです。その境界はテスト可能なプロパティで強制できます。バグ修正を超えてプロパティ指向コード進化を適用することは、私たちの研究の活発な領域です。
最後に覚えておいてください。次にバグを報告するとき、あなたは境界を引いているのです。Kiroと一緒にその境界を引けば、プロパティが修正を正しい方に留めてくれます。
参考文献
- State of AI vs. Human Code Generation Report
- Drift No More? Context Equilibria in Multi-Turn LLM Interactions
- Does your code match your spec?
- The Hypothesis Property-Based Testing Library
- QuickCheck
- SWE-PolyBench
- Differential testing
謝辞
プロパティ指向コード進化の方法論と Kiro のバグ修正ワークフローへの貢献に対して、Aaron Eline、Anjali Joshi、Margarida Ferreira に感謝します。
翻訳は Solutions Architect の瀬高が担当しました。