Amazon Web Services ブログ
AWS Storage ソリューションを使用した Discover でのデジタル変革
どのような組織でも直面する最大の課題の 1 つは、デジタル変革の概念に対する取組みです。組織やその従業員にとってそれが何を意味するのかを定義することさえ、困難な作業となり得ます。多くの組織にとって、その変革には、クラウドジャーニーと、他の新しい (またはやや新しい) テクノロジーの調査の開始が伴います。Discover で学んだことの 1 つは、ジャーニーの「デジタル」の部分にとらわれ過ぎて、「変革」の側面を見失ってしまわないようにしなければならないということです。最終的な目標は、テクノロジーそれ自体のために、新しいテクノロジーをもたらすことではありません。目標とするのは、顧客との約束をより効果的に実現する組織の能力を変革するテクノロジーです (顧客が社内か社外かにかかわらず)。
Discover のリーダーシップチームが分析とデータサイエンスの取り組みに注力し始めたことは、その顧客の約束を念頭に置いてのことでした。財務分野でビジネスを行うということは、長期にわたって、分析とデータサイエンスに極めて優れていなければならなかったということを意味します。私たちは何年にもわたって分析を活用して、詐欺の検出、意思決定、マーケティングなどに関する競争上の優位性を獲得してきました。その結果、これらすべての関連するビジネスユニットを中心に、個別の分析に関するプラクティスが生まれました。それらのほとんどすべてにおいて、要件、スキルレベル、好まれるツールはさまざまでした。Discover には最先端の研究を行う非常に才能のある人々がたくさんいます。リーダーシップチームの観点から見ると、これらの人々とチームをまとめることで、分析作業全体の改善が促進されることは当然のことのように思われました。技術的な観点からは、これらの人々とチームをまとめ上げる方法を見出すことには困難がありました。
このブログ投稿では、私たちが開発した Air9 と呼ばれるプラットフォームであるソリューションについて詳しく説明します。この困難を解決する際に、最初に合意した設計原則の 1 つは、多様性に強みがあるということでした。これには、チームとその経験の多様性だけでなく、さまざまなアプローチやツールも含まれます。この確立された分析コミュニティに、データサイエンスに対するフリーサイズのアプローチを持ち込むつもりはありませんでした。これにより、すべてのユーザー、ツール、およびデータを単一のプラットフォームに一元化するという単純な計画が導き出されました。これは、最終的に Air9 となるプラットフォームです。
このブログ投稿をさらに読み進める前に、同じコンテンツの多くをカバーする AWS re:Invent 2019 での Discover のプレゼンテーションのこの動画をチェックしてください。
適切なストレージソリューションを選択する
Air9 プラットフォームの構築に向けたジャーニーでは、多くのデータサイエンスツールがコンテナ化に当然に用いられていたので、Kubernetes は自然に調和しました。専用のコンテナとポッドを備えることで、分離されたワークロードが可能になりました。この分離により、ユーザーはカスタムパッケージをインストールし、共有コンピューティングクラスターのようなマルチテナント環境で管理するのが難しい環境を調整できました。Amazon EC2 Auto Scaling を活用することで、需要に応じて、当社のコンピューティング機能を拡大および縮小することが可能になりました。
一元化されたデータサイエンスプラットフォームへのクリーンなアプローチのように見えたものは、ストレージレイヤーの設計を開始したときにすぐに問題に直面しました。当社の分析チームは、非常に大きなデータセットを持っています。データサイエンティストをご存知であれば、データウェアハウスに対して調査を行うのではなく、ローカルのデータセットの使用を非常に好むことをご存知でしょう。クラウドデータウェアハウスには大規模なデータセットがいくつかありましたが、データサイエンティストには個々の作業を行うためのローカルストレージが必要でした。また、チーム間 (およびチーム全体) でデータを共有するためのメカニズムも必要でした。このストレージレイヤーは、回復力があり、時間の経過に伴う大きな成長をサポートできる必要がありました。
Discover のテクノロジー組織は常に、新しいソリューションに対する「自分で構築できる」アプローチを好む傾向にあり、ビルダーとしてこれらの課題を楽しんでいます。チームは、データサイエンスプラットフォームのストレージレイヤーとして、オープンソースの分散ストレージソリューションの活用に乗り出しました。ビルドを好む傾向にある組織の重要な特徴の 1 つは、迅速に失敗し、アイデアを反復し、機能していないアイデアから次に進むタイミングを知る能力を有していることです。シャードキー、I/O パターン、成長予測、リカバリポイントの目標についての話し合いを余儀なくさせるいくつかの大きな頭痛の種を抱えつつ、社内の分散ストレージシステムに数週間を費やした後でも、大きく進捗しているようには見えませんでした。その間に、当社は、プラットフォームの初歩的な実装を提供し、ベータユーザーからかなりの量のデータがストレージソリューションに入力され始めました。この時点までのすべての課題を踏まえると、チームは、ソリューションが実現可能で持続可能であるかどうかについて不確かでした。最終的には、他の保管オプションを探すことを決定し、以下のコストチャートがとどめとなりました。

図 1: 請求に問題があります
通常、データサイエンスプラットフォームは、計算集約型の環境です。独自のストレージプラットフォームの運用に関連するコストがコンピューティングコストを超えるのを目にしたとき、何かがおかしいことがわかりました (図 1)。結局、過剰なコストは分散ストレージのレプリケーションファクターに起因するものでしたが、コストを削減する (レプリケーションファクターを削減する) トレードオフは、当社が満足できるものではありませんでした。
当社は、Amazon EC2 のスケーラビリティを活用してこのプラットフォームのコンピューティング側で成功を収めてきたので、ストレージ向けの AWS マネージドサービスを見直しました。Amazon Elastic File System (Amazon EFS) は、スケーラビリティとコストに関しては、請求額に見合うように見えました。Kubernetes コミュニティのすばらしい成果のおかげで、EFS にはすでにストレージクラス機能があり、EFS をプラットフォームに統合することを加速することができました。
Amazon EFS を活用するためのアプローチでは、データを保存するための 2 つのメカニズム、ホームディレクトリ、およびチームディレクトリをユーザーに提供します。これらのストレージ機能は、EFS ストレージクラスを使用して PersistentVolumes に対する PersitentVolumeClaims として実装されます。Amazon Simple Storage Service (Amazon S3) を使用すると、バックアッププロセスをカスタマイズして、安全な保管のために、2 つ目のデータのコピーを持つことができます。これは、Amazon S3 の無制限に見えるストレージ機能と低コストによって、容易なことでした。全体として、ストレージの原価は少なくとも 50% 削減され、このプラットフォームのストレージの管理に費やされる時間は 90% 削減されました。
データサイエンスプラットフォームを保護する
AWS マネージドサービスの広く知られていない優れた点の 1 つは、多額の技術的な投資を要することなく、安全にすべてを実行できることです。暗号化プロセスを実装して、環境内で保管されているとき、およびクラウド環境とオンプレミスのデータセンターの間を移動するときに、データセットを安全に保護できます。実際、実装は非常に簡単で、開発環境では初日から高度なセキュリティが確保されていました。当社が独自に実装していたなら数週間を要したことでしょう。セキュリティ機能を維持するために非常に多くの時間が費やされたであろうことは言うまでもありません。
暗号化は重要ですが、適切な承認および認証メカニズムがなければあまり効果的ではありません。そのために、当社はセキュリティチームのガイダンスに従い、オンプレミスシステムに期待するのと同様の承認をミラーリングします。ユーザーが選択したツール用のコンテナベースの環境を作成する場合、当該ユーザーのみがその環境にログインできます。これは、LDAP 統合、Linux-PAM モジュール、および nslcd Linux パッケージを介して実装されます。ストレージメカニズムは、標準の POSIX ファイルシステムのアクセス許可とユーザー/グループの所有権を実装します。これらのローカルユーザーを PAM 経由でコンテナにマッピングし、PVC に適切なアクセス許可を追加することにより、セキュリティチームがオンプレミスソリューションに必要なすべての承認および認証機能を備えた環境を作成しました (図 2)。AWS が提供する素晴らしい暗号化機能と組み合わせることで、当社は、分析コミュニティのために非常に安全なデータ環境を提供しています。
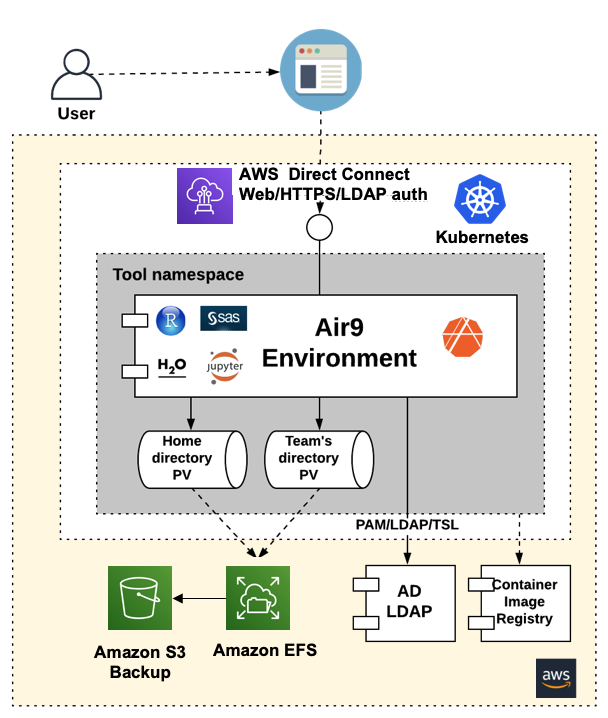
図 2: アプリケーションおよびストレージレイヤーでの承認のための AD/LDAP の活用
Amazon EFS でパフォーマンスを最適化する
当社は、セキュリティから始めました (Discover での標準的なアプローチと同様です)。チームが対処すべきリストの項目は増え続けており、そのリストの最上位にはパフォーマンスがありました。分析チームが実行していたオペレーションの多くは、I/O を多用するプロセスを採り入れていました。Amazon EFS では、適切に設定することより、いくつかの素晴らしいパフォーマンス特性を使用できますが、最終的には、当社の超高性能ストレージレイヤーのニーズを満たすことはできませんでした。ありがたいことに、AWS はこれを早い段階で認識し、オプションを追加したので、当社は最先端のユーザーの要求事項を満たすことができました。
Amazon EFS は、当社のユーザーのニーズの大部分を満たしましたが、I/O に依存するオペレーションを有するユーザーのために、当社は、パフォーマンスストレージ階層を作成しました (図 3)。この層は、NVMe インスタンスストアを使用して特別にプロビジョニングされた Amazon EC2 インスタンスから派生しています。インスタンスストアを使用してストライプ/RAID-0 アレイを作成し、これらのローカルアレイを Kubernetes に公開しました。Kubernetes は、ラベルとセレクターを使用して、このストレージレイヤーに対して特に要求されたユーザー環境に PVC を提供します。RAID-0 はその寿命の長さで知られているわけではないため、バックアップソリューションとして機能させるべく、Amazon S3 を再度導入しました。これにより、パフォーマンス志向のユーザーは、EFS を利用した PVC から分析を実行しているユーザーと同じレベルの回復力を得ることができるようになりました。
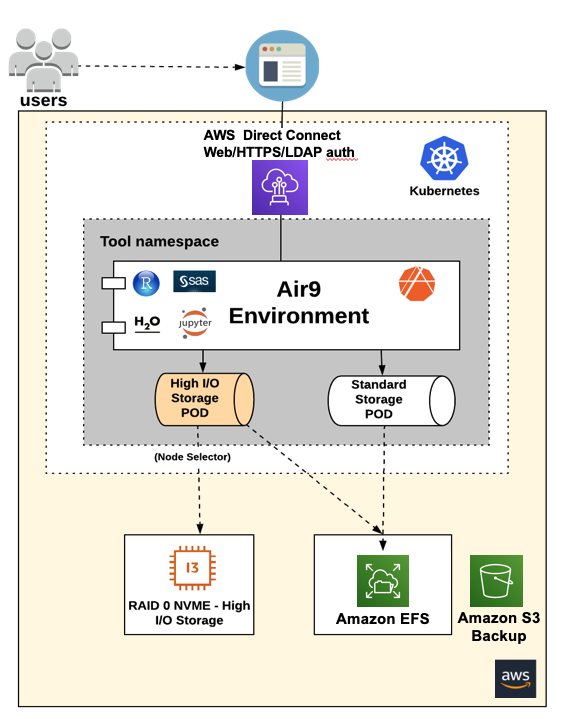
図 3: RAID-0 の NVMe インスタンスストアを高性能ストレージ層として使用
Discover のデジタル変革のさらなるジャーニーへ

図 4: Discover の Air9 の詳細アーキテクチャ
当社は、全社のデータサイエンティストの 85% が互いに関与し、コード、データ、分析テクニックを共有するコラボレーションプラットフォームを構築しました。多くのユースケースで、オンプレミスシステムに比べて実行時間が 10 倍から 20 倍改善されました。 当社は、プラットフォームが限界に追い込まれ、想像もしなかったような方法で使用されるのを見てきました。Amazon EFS と Amazon S3 のおかげで、50% を超えるストレージコストを削減しつつ、これらすべてを達成することができました。
Discover のデジタル変革ジャーニーは続き、Air9 データサイエンスプラットフォームについての取り組みも進んでいます。当社は、その過程で多くのことを学びました。当社は、自社について、当社の長所と短所について、そして、ユーザーにとって、問題解決のための革新と新しいアプローチにおいてクラウドソリューションがいかに効果的であるかについて学びました。このジャーニーで直面した問題にかかわらず、AWS は、当社の質問やリクエストに常に対応してくれる素晴らしいパートナーであり続けました。Discover と AWS のパートナーシップは、デジタル変革の実現に大きな役割を占めてきました。そして、私たちは、引き続き、未来をともに築いていけることを楽しみにしています。
このブログ投稿で Discover の AWS のサービスの使用方法をお読みいただきありがとうございました。ここで取り上げた内容について質問やフィードバックがある場合は、コメントをお寄せください。AWS のチームが当社に確実に届けてくれます!