Amazon Web Services ブログ
Exafunction で AWS Inferentia による機械学習推論のベストプライス・パフォーマンスを実現
この記事は、 Exafunction supports AWS Inferentia to unlock best price performance for machine learning inference を翻訳したものです。
すべての業界で、機械学習 (ML) モデルはより深く、ワークフローはより複雑になり、ワークロードはより大規模に動作しています。 このようなモデルの精度を高めるために、多大な努力とリソースが投入されています。この投資がより優れた製品や体験に直接的につながるからです。 一方で、これらのモデルを本番環境で効率的に稼働させることは、パフォーマンスと予算の目標を達成するための鍵であるにもかかわらず、しばしば見過ごされる重要な課題です。 この投稿では、Exafunction と AWS Inferentia がどのように連携して、本番環境での ML モデルの簡単かつ費用対効果の高いデプロイを実現するのかについて説明します。
Exafunction は、企業が可能な限り効率的に大規模な ML を実行できるようにすることに重点を置いたスタートアップ企業です。 同社の製品の 1 つは ExaDeploy です。これは大規模な ML ワークロードをサービングできる easy-to-use な SaaS ソリューションです。ExaDeploy は、混合リソース (CPU およびハードウェアアクセラレータ) 全体で ML ワークロードを効率的に調整し、リソースの使用率を最大化します。また、自動スケーリング、コンピューティングコロケーション、ネットワークの問題、フォールトトレランスなどを処理して、効率的で信頼性の高いデプロイを確保します。AWS Inferentia ベースの Amazon EC2 Inf1 インスタンスは、クラウドで 推論あたりのコストを、クラウド内で最も低く提供する目的で構築されています。ExaDeploy はこの Inf1 インスタンスをサポートするようになりました。これにより、ユーザーはハードウェアベースのアクセラレータを節約することが可能です。また、最適化されたリソースの仮想化と大規模なオーケストレーションのソフトウェアベースの節約も可能です。
ソリューション概要
ExaDeploy がデプロイ効率をどのように解決するか
コンピューティングリソースを効率的に使用するには、適切なリソース割り当て、自動スケーリング、コンピューティングコロケーション、ネットワークコストとレイテンシの管理、フォールトトレランス、バージョン管理と再現性などを考慮する必要があります。 大規模になるほど非効率性はコストとレイテンシに大きく影響します。そして多くの大企業は、社内チームを立ち上げ、専門知識を積み上げることでこれらの非効率性に対処しています。 ただし、ほとんどの企業にとって、企業が求めているコアコンピテンシーではない一般化可能なソフトウェアを構築するということは、財務的および組織的なオーバーヘッドを負担することであり、現実的ではありません。
ExaDeploy は、自律走行車や自然言語処理 (NLP) アプリケーションなどの最も複雑なワークロードで見られる問題を含め、これらのデプロイ効率の問題点を解決するように設計されています。 一部の大規模なバッチ ML ワークロードでは、ExaDeploy を利用することで、レイテンシや精度を犠牲にすることなく、エンジニア 1 人日分の稼働という短い統合時間でコストを 85% 以上削減しました。 ExaDeploy は、システムを劣化させることなく、ハードウェアアクセラレータを持つ何千ものインスタンスを同時に自動スケーリングおよび管理できることが証明されています。
ExaDeploy の主な機能は次のとおりです。
- クラウドで実行: モデル、入力、または出力がプライベートネットワークの外に出ることはありません。 クラウドプロバイダーの割引を引き続き利用できます。
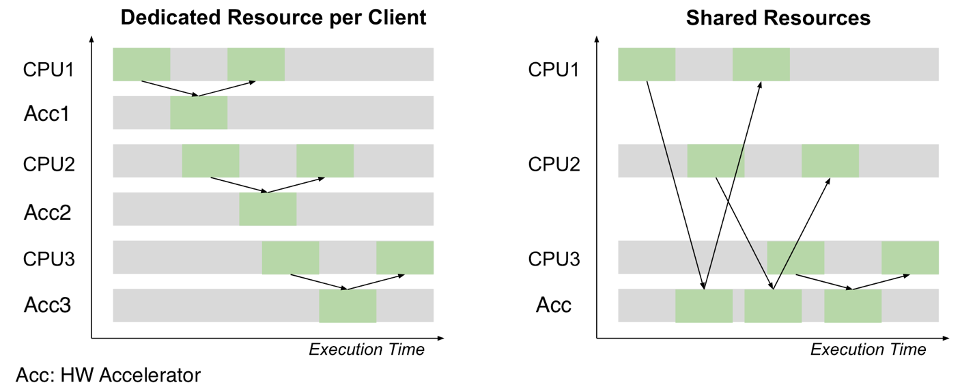
- 共有アクセラレータリソース: ExaDeploy は、複数のモデルまたはワークロードがアクセラレータリソースを共有できるようにすることで、使用されるアクセラレータを最適化します。 また、複数のワークロードが同じモデルをデプロイしているかどうかを識別し、それらのワークロード間でモデルを共有して、使用されるアクセラレータを最適化することもできます。 その自動リバランス機能とノードドレイン機能により、使用率最大化、コスト最小化が得られます。
- スケーラブルなサーバーレスデプロイモデル: ExaDeploy は、アクセラレータリソースの飽和に基づいて自動スケーリングします。 0 までスケールダウン、また、数千のリソースまで動的にスケールアップします。
- さまざまな計算タイプのサポート: すべての主要な ML フレームワークだけでなく、任意の C++ コード、CUDA カーネル、カスタム ops、および Python 関数からディープラーニングモデルをオフロードできます。
- 動的なモデルの登録とバージョン管理: システムを再構築または再デプロイすることなく、新しいモデルまたはモデルバージョンを登録および実行できます。
- ポイントツーポイント実行: クライアントはリモートアクセラレータリソースに直接接続するため、低レイテンシと高スループットが可能になります。状態をリモートで保存することもできます。
- 非同期実行: ExaDeploy は、モデルの非同期実行をサポートします。これにより、クライアントはローカル計算とリモートアクセラレータリソース作業を並列処理できます。
- フォールトトレラントなリモートパイプライン: ExaDeploy を使用すると、フォールトトレランスを保証した形で、クライアントはモデル、前処理などのリモート計算をパイプラインに動的に構成します。ExaDeploy システムは、Pod またはノードの障害を自動リカバリおよびリプレイで処理するため、開発者はフォールトトレランスの確保について考える必要がありません。
- 設定不要なモニタリング: ExaDeploy は Prometheus メトリックと Grafana ダッシュボードを提供して、アクセラレータリソースの使用状況やその他のシステムメトリックを可視化します。
ExaDeploy における AWS Inferentia サポート
AWS Inferentia を搭載した Amazon EC2 Inf1 インスタンスは、ディープラーニングの推論ワークロード向けに設計されています。 これらのインスタンスは、現行世代の GPU 推論インスタンスと比較して、最大 2.3 倍のスループットと最大 70% のコスト削減を提供します。
ExaDeploy は AWS Inferentia をサポートするようになりました。これらを組み合わせて専用のハードウェアアクセラレーションと最適化されたリソースオーケストレーションを大規模に実現することで、パフォーマンスの向上とコスト削減を実現できます。 非常に一般的な最新の ML ワークロードであるバッチ型の混合コンピューティングワークロードを例として、ExaDeploy と AWS Inferentia を組み合わせた利点を見てみましょう。
仮定するワークロードの特性:
- 15 ミリ秒の CPU のみの前処理/後処理
- モデル推論 (GPU で 15 ミリ秒、AWS Inferentia で 5 ミリ秒)
- 10 クライアント、各クライアントが 20 ミリ秒ごとにリクエストを作成
- CPU : Inferentia : GPU の概算相対コストは 1 : 2 : 4 です (c5.xlarge、inf1.xlarge、および g4dn.xlarge の Amazon EC2 オンデマンド料金に基づく)
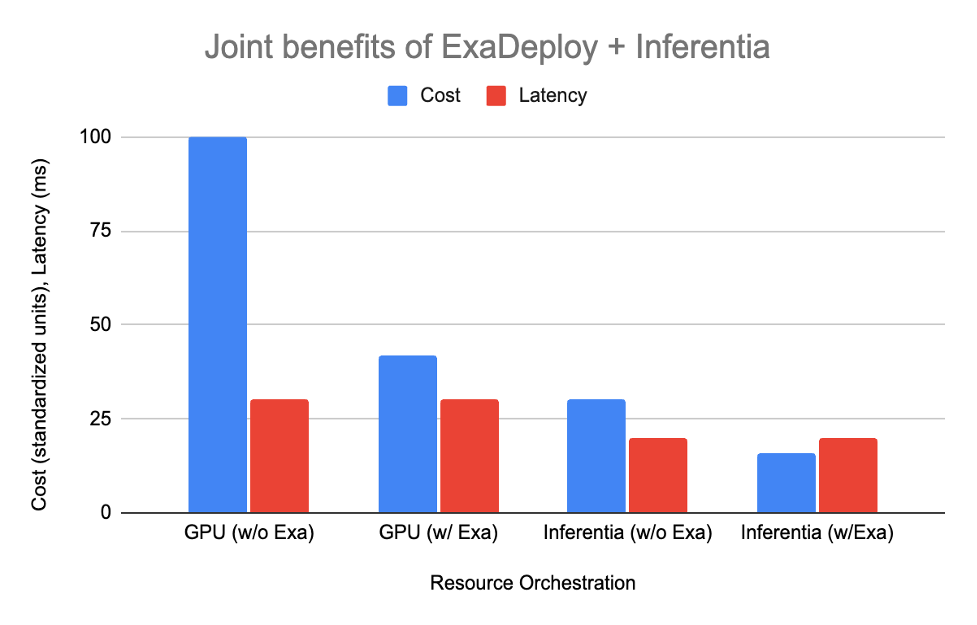
以下の表は、各オプションがどのように形成されるかを示しています。
| セットアップ | 必要なリソース | コスト | レイテンシ |
| ExaDeploy を使用しない GPU | クライアントあたり 2 CPU, 2 GPU (計 20 CPU, 20 GPU) | 100 | 30 ms |
| ExaDeploy を使用する GPU | 10 クライアントでシェアされる 8 GPU | 42 | 30 ms |
| ExaDeploy を使用しない AWS Inferentia | クライアントあたり 1 CPU, 1 AWS Inferentia (計 10 CPU, 10 Inferentia) | 30 | 20 ms |
| ExaDeploy を使用する AWS Inferentia | 10 クライアントでシェアされる3 AWS Inferentia, クライアントあたり 1 CPU | 16 | 20 ms |
ExaDeploy on AWS Inferentia の例
このセクションでは、BERT PyTorch モデルで inf1 ノードを使用した例を通じて、ExaDeploy を構成する手順について説明します。 bert-base モデルの平均スループットは 1140 サンプル/秒でした。これは、この単一モデル、単一ワークロードのシナリオで、ExaDeploy によってオーバーヘッドがほとんどまたは全く発生しなかったことを示しています。
ステップ 1: Amazon Elastic Kubernetes Service (Amazon EKS) クラスターをセットアップする
Amazon EKS クラスターは、Terraform AWS モジュールで起動できます。 この例では、AWS Inferentia を搭載した inf1.xlarge を使用しました。
ステップ 2: ExaDeploy をセットアップする
2 番目のステップは、ExaDeploy をセットアップすることです。 通常、inf1 インスタンスへの ExaDeploy のデプロイは簡単です。 セットアップは、GPU インスタンスの場合とほぼ同じ手順に従います。 主な違いは、モデルタグを GPU から AWS Inferentia に変更し、モデルを再コンパイルすることです。 例えば、ExaDeploy の API を使用して g4dn から inf1 インスタンスに移行する場合、変更する必要があるコードは約 10 行だけでした。
- 簡単な方法の 1 つは、Exafunction の Terraform AWS Kubernetes モジュールまたは Helm チャートを使用することです。 これらは、コア ExaDeploy コンポーネントをデプロイして、Amazon EKS クラスターで実行します。
- モデルをシリアル化された形式 (TorchScript、TF saved model、ONNX など) にコンパイルします。AWS Inferentia についてはこのチュートリアルに従います。
- コンパイル済みのモデルを ExaDeploy のモジュールリポジトリに登録します。
モデルのためのデータを準備します(これは ExaDeploy 固有のものではありません)。
- モデルをクライアントからリモートで実行します
ExaDeploy と AWS Inferentia: 良好な関係性
AWS Inferentia は、モデル推論のスループットの限界を押し広げ、クラウドで 1 推論あたりで最も低いコストを実現しています。 ただし、企業が Inf1 の価格性能比のメリットを大規模に享受するには、適切なオーケストレーションが必要です。 ML サービングは複雑な問題であり、社内で対処すると、会社の目標から外れた専門知識が必要になり、製品のタイムラインが遅れることがよくあります。 Exafunction の ML デプロイソフトウェアソリューションである ExaDeploy は、業界のリーダーとして台頭してきています。 最も複雑な ML ワークロードにも対応しながら、スムーズな統合エクスペリエンスと世界クラスのチームからのサポートを提供します。 ExaDeploy と AWS Inferentia を組み合わせることで、大規模な推論ワークロードのパフォーマンスを向上させ、コストを削減できます。
結論
この投稿では、パフォーマンスを必要とする ML のための AWS Inferentia を Exafunction がどのようにサポートしているかを示しました。 Exafunction を使用したアプリケーションの構築の詳細については、Exafunction を参照してください。 Inf1 でディープラーニングワークロードを構築するためのベストプラクティスについては、Amazon EC2 Inf1 インスタンスにアクセスしてください。
この記事は、ソリューションアーキテクトの赤澤が翻訳を担当しました。原文はこちらです。