Amazon Web Services ブログ
アプリ内にボイスインターフェースを開発する方法 Astro Technology
今回のブログは Astro Technology, Inc. の CTO である Roland Schemers 氏より寄稿いただきました。Astro は同社について次のように説明しています。「当社はユーザーやチーム向けに開発した人工知能を使用する Mac や iOS および Android 用のメールアプリを製作しています。アプリ内のメールボイスアシスタント、Astrobot Voice を使えば、Astro アプリを終了せずにメールを読んだり返信することができます。」
そして最近では Astrobot Voice という初のアプリに組み込まれているメールボイスアシスタントをリリースしたばかりです。これにより、iOS 向け Astro や Android 向けアプリを終了する必要なく、メールの読み取り、管理、返信が可能になりました。
Astro が 6 月に Amazon Alexa スキルをリリースしてから、我々はより多くのユーザーが音声でメール管理をできるようにしたいと考えました。そこで、今回のブログではなぜ我々がこうした選択を取ったのか技術面から説明し、どのようにこれを実現しどういったテクノロジーを使用したのかご説明します。
アプリ内ボイスを構築する理由は?
当社では Amazon Echo を愛用しています。実際、Astro の新入社員には「ようこそ」という意味はもちろん、我々の Alexa スキルを社内で試験運用することを兼ねて、各自に Echo Dot を提供しています。結果として私達のスキルが上々であることが分かり、より多くのユーザー、そしてさらに様々な場所で取り入れられる方法を新たに見つけることもできました。そこでアプリ内ボイスを構築できるか、その可能性を探ってみることにしたのです。
ソフトウェアの選択
アプリ内ボイスの構築方法を決定する上で、我々はいくつものオプションを検討しましたが、その上でいくつかのポイントを念頭に置きました。
- まず、当社のテキストベースアシスタント (api.ai で実行) または Alexa スキルからできるだけ多くのコードやロジックを再使用することです。
- そして、正確な音声認識を使用してスムーズなユーザーエクスペリエンスを製作すること。
- さらに、手間の掛かる作業はサーバーに任せることです。
我々のタイムラインとエンジニアリングのリソースを考えると最初のポイントは重要でした。当社は小規模のスタートアップ企業なので、そうした時間の節約は大いに役立つからです。
そして、2 つめのポイントであるスムーズなユーザーエクスペリエンスを作ることは特にチャレンジでした。スケールといった点で Amazon Alexa の自然言語処理のレベルは明らかに優勢でした。そのため、正確性を伴うエクスペリエンスを作ろうとする上で、AWS サービスやそのディープラーニングテクノロジーを活用したいという点は我々にとって明白でした。
そして 3 つめのポイントにおいては、Astrobot Voice に OS レベルの API とサーバー側における開発の組み合わせが必要であることが分かっていました。初期導入では、コストを抑えながら大方の手間が掛かる作業をサーバーが行うようにしました。大方の作業をサーバーに任せることのメリットには、iOS と Android アプリ両方で共有するコード、そしてアプリストアに Astro アプリの更新したバージョンをプッシュする必要なく、サーバーでフロー変更を行えるようにするといった点があります。
スタック
iOS
音声認識の iOS API には AVSpeechSynthesizer と SFSpeechRecognizer を使用しました。SFSpeechRecognizer は iOS 10+ でのみ利用することが可能なので、Astrobot Voice は iOS 10 および 11 でのみ使用できます。そのためアプリ開発者にとってこれが制限の要因になることもあるかもしれませんが、当社においては問題ありませんでした。
Android
Android では音声認識にスタンダード Android API を使用しました。これには Speech Recognizer と Text To Speech が含まれています。
iOS そして Android のどちらにおいても、サーバーが記録したテキストまたはテキストストリングを送信できるオプションもありました。コスト、時間的制約、レイテンシーを考慮した上で、当社では後者のオプションを選ぶことにしました。
サーバー
サーバー側では Amazon Lex を使用しました。api.ai ではなく Amazon Lex を選んだことで、すでに Alexa と同じロジックの多くを再使用し共有することができました。テキストベースバージョンの Astrobot と同じロジックをいくつか再使用することもできましたが、最終的には時間節約と、より良いエクスペリエンスを提供できる Amazon Lex を使用することにしました。そうすることで開発者 1 人あたり約 2~4 週間ほど時間を節約できました。Astrobot Voice の開発そして我々の Alexa スキルを磨いていく上で、今後も時間を節約していくことができるでしょう。
この先、Astro の有料バージョンを提供する際には (現在、当社アプリは無料)、音声入力には Amazon Lex そして音声出力には Amazon Polly を当社のオンデバイス音声認識と置換することで、さらに AWS サービスを活用して行きたいと考えています。そうすることでボットエクスペリエンスの質を改善することができます。
次に Astrobot Voice エクスペリエンスを作成するために、こうしたサービスがどのように連動するのか、その流れとアーキテクチャを図で示しました。
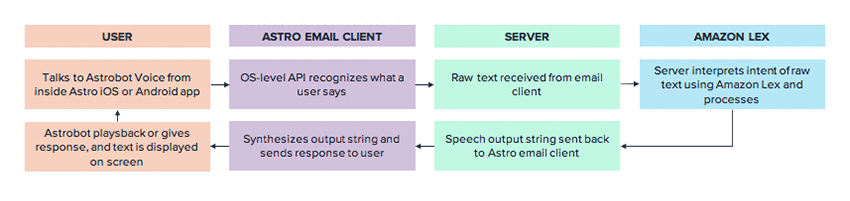

アプリ内ボイス開発者へのアドバイス
まず、ご自分のサービスまたはアプリにとって、音声機能が役立つものであることを確認してください。現在の音声技術の状態を考えると、今の時点でアプリに音声を加えることは優先事項ではないかもしれません。自然言語の理解や自動音声認識の可用性に比べ、アプリを使用する上で音声はまだデフォルトで必要なものとは言い難いでしょう。ですから、製品ロードマップで優先権を得るには、その必要性を明らかにしたユースケースが必要です。1 日の始まり、車内にいる時など、当社においてはメールと音声の必要性がユースケースにおいて明らかでした。
次に、使用するテクノロジーについて熟考し、自分で新たに考案しようとすることは避けることをお勧めします。開発プロセスを行いやすくしたり、世界でも優れたものと認めてもらえるようにするためのサービスやリソースは数多く出回っています。その一方で、意図的な検出で特定のサービスに縛られないよういするため、サーバー側で分離できるようにしておくことも大切です。こうしたサービスは、まだ比較的新しいものであるため常に進化しています。そのため、今後 (もしかすると想像よりも早く) サービスを変更する必要が出てくるかもしれません。Astrobot においては (音声とテキストベースの両方)、サーバーロジックで特に大きな変更を施す必要なく Luis.ai、wit.ai、api.ai、そして Amazon Lex を試すことができました。
当社ではボイスアシスタントを組み込んだ初のメールアプリを提供できたことを嬉しく思い、他のアプリも音声技術の改善を遂げていくことを心待ちにしています。多くの場合、音声は情報をより素早く取得そして新しい情報を作成できる方法です。次に何が出てくるのかとても楽しみです。