Amazon Web Services ブログ
FactSet が Amazon DynamoDB から Amazon S3 Parquet へのデータのエクスポートを自動化して、データ分析プラットフォームを構築する方法
この記事は、FactSet のリードソフトウェアエンジニアである Arvind Godbole と AWS プリンシパルソリューションアーキテクトの Tarik Makota によるゲスト投稿です。「FactSet は、世界中の何万人もの投資専門家向けの柔軟でオープンなデータとソフトウェアソリューションを作成し、投資家が重要な決定を下すために使用する金融データと分析に即座にアクセスできるようにします。FactSet では、製品が提供する価値を常に向上するために取り組んでいます」
私たちが検討してきた分野の 1 つは、クライアントの検索結果の関連性です。さまざまなクライアントの使用例と 1 日あたりの検索回数が多いため、匿名化された使用データを保存し、そのデータを分析してカスタムスコアリングアルゴリズムを使用して、結果を高めることができるプラットフォームが必要でした。計算をホストするために Amazon EMR を使用するのは明らかな選択肢でしたが、匿名化されたデータを Amazon EMR が使用できる形式に変える方法について疑問が生じました。そこで私たちは AWS と協力し、Amazon DynamoDB を使用して Amazon EMR で使用するデータを準備することにしました。
この記事では、FactSet が DynamoDB テーブルからデータを取得し、そのデータを Apache Parquet に変換する方法について説明します。Amazon S3 に Parquet ファイルを保存して、Amazon EMR でほぼリアルタイムの分析を可能にします。途中で、データ型変換に関連する課題に直面しました。これらの課題をどのように克服できたかについて説明しようと思います。
ワークフローの概要
ワークフローには次の手順が含まれています。
- 匿名化されたログデータは DynamoDB テーブルに保存されます。これらのエントリには、ログの生成方法に応じて異なるフィールドがあります。テーブルに項目を作成するたびに、DynamoDB ストリームを使用してレコードを書き出します。ストリームレコードには、DynamoDB テーブルの単一項目からの情報が含まれます。
- AWS Lambda 関数は DynamoDB ストリームにフックされ、DynamoDB テーブルに保存されている新しい項目をキャプチャします。GitHub の lambda-streams-to-firehose プロジェクトから Lambda 関数を構築して、DynamoDB ストリームイメージを JSON に変換し、それを文字列化して Amazon Kinesis Data Firehose にプッシュします。
- Kinesis Data Firehose は、AWS Glue データカタログテーブルに含まれるデータを使用して JSON データを Parquet に変換します。
- Kinesis Data Firehose は、Parquet ファイルを S3 に保存します。
- AWS Glue クローラーは、DynamoDB 項目のスキーマを検出し、関連するメタデータをデータカタログに保存します。
次の図は、このワークフローを示しています。
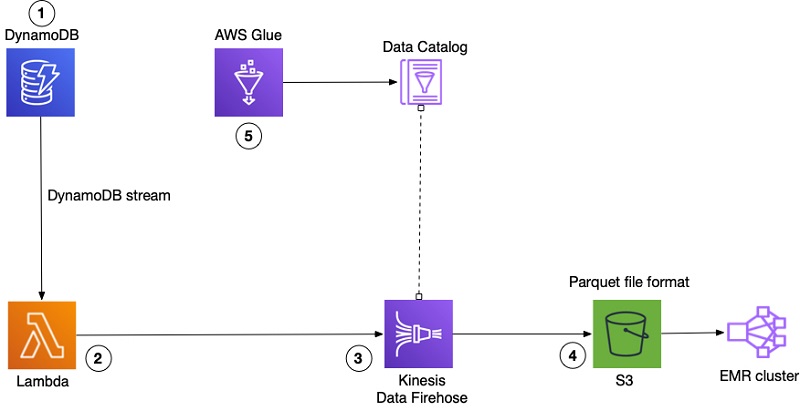
AWS Glue は、データの準備と分析に役立つツールを提供します。クローラーは、DynamoDB テーブルで実行して、テーブルデータのインベントリを取得し、その情報をデータカタログに保存できます。他のサービスは、データカタログを、テーブルデータの場所、スキーマ、タイプのインデックスとして使用できます。メタデータをデータカタログに追加する方法は他にもありますが、重要なのは、メタデータを簡単に更新および変更できることです。詳細については、AWS Glue データカタログの作成を参照してください。
問題: データ型の格差
多くの場合、さまざまなテクノロジーを使用してソリューションを構築するには、これらのテクノロジー間でデータ型をマッピングおよび変換する必要があります。クラウドも例外ではありません。この場合、DynamoDBに保存されているログアイテムには、String Setタイプの属性が含まれていました。Kinesis がデータを Parquet に変換しようとしたときに、文字列設定値によりデータ変換の例外が発生しました。問題を調査した結果、次のことがわかりました。
- クローラーが DynamoDB テーブルのインデックスを作成すると、Set データ型 (
StringSet,NumberSet) が Glue メタデータカタログにset<string>およびset<bigint>として保存されます。 - Kinesis Data Firehose は、Apache Parquet への変換を実行するときに同じカタログを使用します。変換には、有効な Hive データ型が必要です。
set<string>およびset<bigint>は有効な Hive データ型ではないため、変換が失敗し、例外が生成されます。例外は、次のコードに似ています。
ソリューション: データマッピングを作成する
AWS チームと協力しながら、Kinesis Data Firehose コンバーターが成功するためには、データカタログに有効な Hive データ型が必要であることを確認しました。複雑なデータ型に関しては、Hive は set<data_type> はサポートしていませんが、次のものをサポートしています。
ARRAY<data_type>MAP<primitive_type, data_typeSTRUCT<col_name : data_type [COMMENT col_comment], ...>UNIONTYPE<data_type, data_type, ...>
私たちの場合、set<string> と set<bigint> を array<string> と array<bigint> に変換する必要があることを意味します。最初の手順は、データカタログで直接手動でタイプを変更することでした。データカタログを更新して、発生したすべての set<data_type> を array<data_type> に変更した後、Parquet への Kinesis 変換が正常に完了しました。
私たちのビジネス例では、同じテーブルに異なる属性を持つアイテムを格納できるデータストアと、新しい属性をオンザフライで追加する必要があります。DynamoDB のスキーマレスの性質とオンデマンドでスケールアップおよびスケールダウンする機能を利用して、基となるインフラストラクチャの管理ではなく機能に集中できるようにしました。詳細については、DynamoDB テーブルを正規化または非正規化する必要がありますか?を参照してください。
データに静的スキーマがある場合、手動で変更するだけで十分です。私たちのビジネス例を考えると、手動ソリューションは拡張できませんでした。DynamoDB テーブルに新しい属性を導入するたびに、メタデータを再作成し、変更を上書きするクローラーを実行する必要がありました。
サーバーレスイベントアーキテクチャ
データカタログへのデータ型の更新を自動化するために、Amazon EventBridge と Lambda を使用して、データ型マッピングの変更を実装しました。EventBridge は、イベントを使用してアプリケーションを接続するサーバーレスイベントバスです。イベントは、データカタログテーブルのステータスなど、システムの状態が変化したことを示すシグナルです。
次の図は、新しいアーキテクチャを使用した以前のワークフローを示しています。
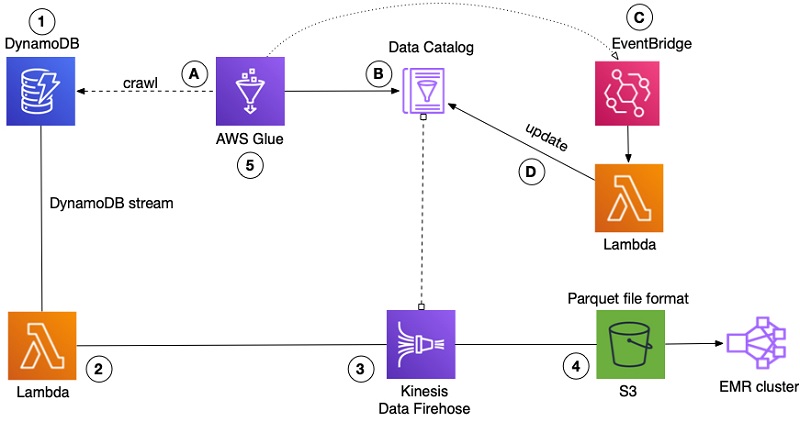
- クローラーはそのままで、DynamoDB テーブルをクロールしてメタデータを取得します。
- クローラーによって取得されたメタデータは、データカタログに保存されます。以前のメタデータは更新または削除され、変更 (手動または自動) は上書きされます。
- EventBridge のイベント
GlueTableChangedは、データカタログテーブルへの変更をリッスンします。テーブルに変更があったというイベントを受け取った後、Lambda 関数をトリガーします。 - Lambda 関数は、AWS SDK を使って、
glue.update_table()API を使用して Glue カタログテーブルを更新し、set<data_type>の出現をarray<data_type>に置き換えます。
EventBridge をセットアップするには、イベントパターンを「サービスごとに事前定義されたパターン」に設定します。サービスプロバイダーについては、サービスとして AWS と Glue を選択しました。「Glue データカタログテーブルの状態の変更」イベントタイプを選択しました。次のスクリーンショットは、データカタログを更新する Lambda 関数にイベントを送信する EventBridge 構成を示しています。

次は、ベースライン Lambda コードです。
Lambda 関数は簡単です。この記事では基本的なスケルトンを提供します。これをテンプレートとして使用して、特定のデータに独自の機能を実装できます。
まとめ
データ型の変換やマッピングなどの単純な作業は、データがサービスの境界を越えるときに予期しない結果や課題を引き起こす可能性があります。AWS の利点の 1 つは、ニーズに合わせて堅牢でスケーラブルなソリューションを作成できるさまざまなツールです。イベント駆動型アーキテクチャを使用して、データ型変換エラーを解決し、プロセスを自動化して、問題を解決することで前に進みました。
著者について
 Arvind Godbole は、FactSet Research Systems のリードソフトウェアエンジニアです。彼は、リアルタイムの金融アプリケーションから検索インフラストラクチャに至るまで、高性能で高可用性のクライアント向け製品やサービスを構築した経験があります。彼は現在、クライアントワークフローに関する洞察を得るための分析プラットフォームを構築しています。彼はカリフォルニア大学サンディエゴ校でコンピュータ工学の修士号を取得しています。
Arvind Godbole は、FactSet Research Systems のリードソフトウェアエンジニアです。彼は、リアルタイムの金融アプリケーションから検索インフラストラクチャに至るまで、高性能で高可用性のクライアント向け製品やサービスを構築した経験があります。彼は現在、クライアントワークフローに関する洞察を得るための分析プラットフォームを構築しています。彼はカリフォルニア大学サンディエゴ校でコンピュータ工学の修士号を取得しています。
 Tarik Makota は、アマゾン ウェブ サービスのプリンシパルソリューションアーキテクトです。彼は、米国北東部の AWS の顧客に技術的ガイダンス、設計アドバイス、および思想的リーダーシップを提供しています。彼はロチェスター工科大学でソフトウェア開発および管理の修士号を取得しています。
Tarik Makota は、アマゾン ウェブ サービスのプリンシパルソリューションアーキテクトです。彼は、米国北東部の AWS の顧客に技術的ガイダンス、設計アドバイス、および思想的リーダーシップを提供しています。彼はロチェスター工科大学でソフトウェア開発および管理の修士号を取得しています。