Amazon Web Services ブログ
アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
本記事は 2026 年 2 月 23 日 に公開された「Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications」を翻訳したものです。
Amazon SageMaker Unified Studio でプロジェクトを作成する際、プロジェクトプロファイルを選択してプロビジョニングするリソースとツールを定義します。Amazon SageMaker Catalog はこれらを使ってデータメッシュパターンを実装します。ただし、プロジェクトと共にプロビジョニングされるリソースを利用したくない場合もあります。たとえば、既存のアプリケーションやデータプロダクトに変更を加えたくない場合などです。
本記事では、現在のデータリポジトリとコンシューマーアプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する方法を説明します。
ソリューション概要
本記事では、Amazon SageMaker Catalog 導入前に存在するデータプロデューサーとデータコンシューマーに基づくシナリオをシミュレートします。サンプルデータセットを既存データとしてみなし、AWS Lambda 関数は既存アプリケーションを代替します。実際のデータとワークロードでも同様の構成を利用することが可能です。
次の図は、ソリューションアーキテクチャの主要な構成を示しています。プロデューサーアカウントの Amazon Simple Storage Service (Amazon S3) バケットと AWS Glue Data Catalog で既存のデータリポジトリを表しています。コンシューマーアカウントの Lambda 関数で既存のコンシューマーアプリケーションです。
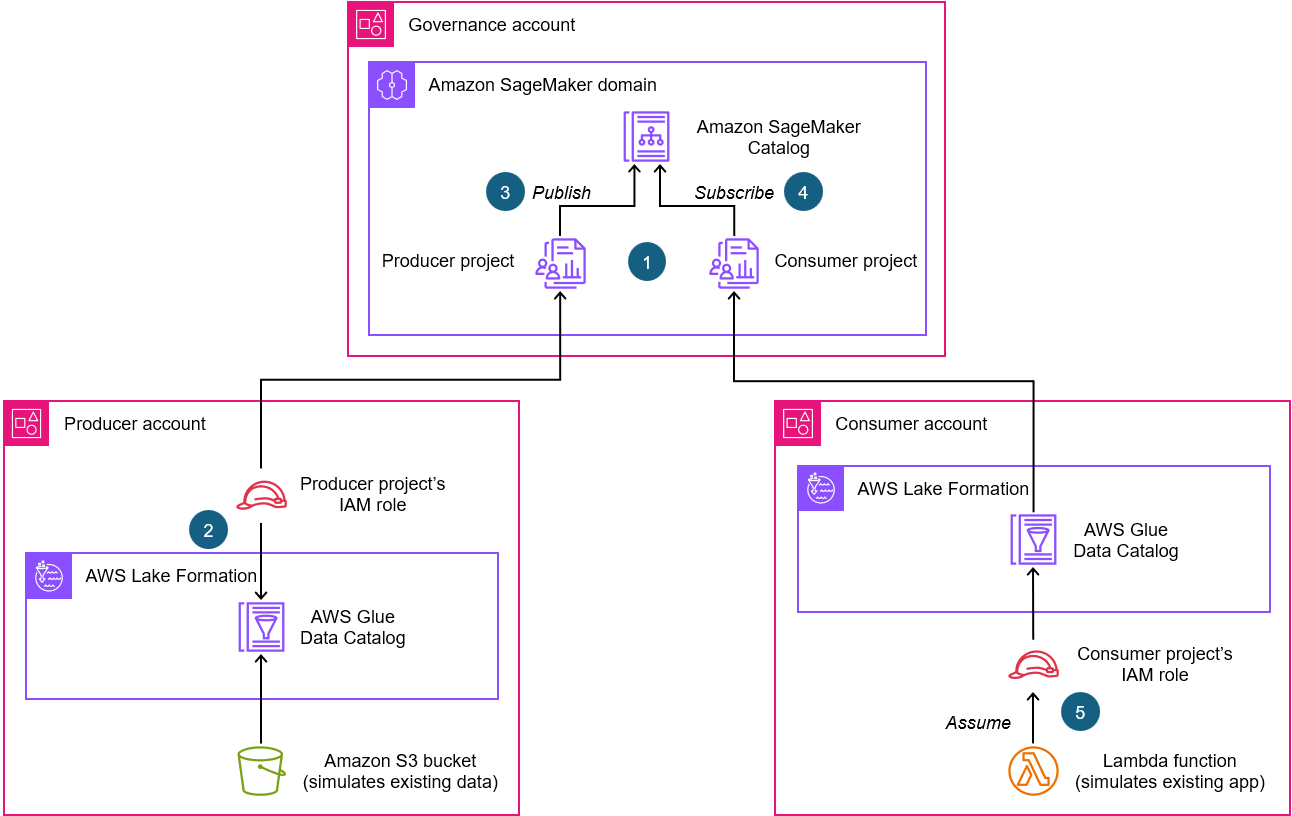
アーキテクチャで表現されている主要な構成要素は次のとおりです。
- Amazon SageMaker ドメインの一部として、プロデューサープロジェクト (プロデューサーアカウント) とコンシューマープロジェクト (コンシューマーアカウント) を作成します。他のリソースとともに、関連付けられたアカウントの各プロジェクトにプロジェクト AWS Identity and Access Management (IAM) ロールが作成されます。
- プロデューサーアカウントで、AWS Lake Formation でプロデューサープロジェクトの IAM ロールに既存のデータアセットへのアクセス許可を付与します。
- プロデューサープロジェクトから Amazon SageMaker Catalog にデータアセットを公開します。
- コンシューマープロジェクトからデータアセットをサブスクライブします。
- コンシューマーアカウントで、サブスクライブしたデータアセットにアクセスするために、Lambda 関数がコンシューマープロジェクトの IAM ロールを引き受けるよう設定します。
本アーキテクチャは、次の Amazon Web Services (AWS) のサービスと機能に基づいています。
- Amazon SageMaker Catalog でデータと AI を安全に検出、ガバナンス、コラボレーションできます。
- Amazon SageMaker Unified Studio はデータを検出して構築するための単一のデータと AI 開発環境です。Amazon SageMaker Unified Studio プロジェクトはデータと AI タスクを実行するための共同作業の境界です。
- Amazon SageMaker のレイクハウスアーキテクチャは Apache Iceberg と完全に互換性があります。Amazon S3 データレイク、Amazon Redshift データウェアハウス、サードパーティおよびフェデレーテッドデータソース全体でデータを統合します。
- AWS Lake Formation で分析と機械学習のためにデータを一元的にガバナンス、保護、共有できます。
- AWS Glue Data Catalog は、データアセットの永続的なメタデータストアです。テーブル定義、ジョブ定義、スキーマ、その他の制御情報が含まれており、AWS Glue 環境の管理に役立ちます。
- Amazon S3 は業界をリードするスケーラビリティ、データ可用性、セキュリティ、パフォーマンスを備えたオブジェクトストレージサービスです。
リソースのセットアップ
このセクションでは、ソリューションに必要なリソースと設定を準備します。
3 つの AWS アカウント
このソリューションを実行するには 3 つの AWS アカウントが必要で、AWS Organizations の同じ組織に属している必要があります。
- プロデューサーアカウント – 公開するデータアセットをホストします
- コンシューマーアカウント – プロデューサーアカウントから公開されたデータを消費するアプリケーションをホストします
- ガバナンスアカウント – Amazon SageMaker Unified Studio ドメインを設定する場所です
各アカウントには、2 つの異なるアベイラビリティーゾーンに少なくとも 2 つのプライベートサブネットを持つ Amazon Virtual Private Cloud (Amazon VPC) が必要です。手順については、「VPC とその他の VPC リソースを作成する」を参照してください。このソリューションを適用する予定のリージョンで両方の VPC を作成してください。
この例では、独立したガバナンスアカウントを利用していますが、Amazon SageMaker はプロデューサーアカウントまたはコンシューマーアカウントで設定および管理できるため、厳密には必須ではありません。3 つのアカウントを用意できないケースでも、本記事を使用して、現在のデータリポジトリとコンシューマーアプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装するために必要な主要な設定を理解できます。
プロデューサーアカウントでデータリポジトリを作成する
まず、次の手順に従ってサンプルデータセットを作成します。
- テキストエディタを開きます。
- 新しいファイルに次のテキストを貼り付けます。
- ファイルを
trees.csvとして保存します。これがサンプルデータファイルです。
サンプルデータセットを作成したら、プロデューサーアカウントに S3 バケットと AWS Glue データベースを作成します。これがデータリポジトリです。
プロデューサーアカウントで S3 バケットを作成し、trees.csv ファイルをアップロードします。
- プロデューサーアカウントで S3 コンソールにアクセスします。
- S3 バケットを作成します。手順については、「汎用バケットの作成」を参照してください。
- 作成した
trees.csvサンプルデータファイルを S3 バケットにアップロードします。手順については、「オブジェクトのアップロード」を参照してください。
プロデューサーアカウントで AWS Glue データベースとテーブルを作成します。
- プロデューサーアカウントで Glue コンソールにアクセスします。
- ナビゲーションペインの Data Catalog で、Databases を選択します。
- Add database を選択します。
- Name に
collectionsと入力します。 - Description に
This database contains collections of statistics for natural resourcesと入力します。 - Create database を選択します。
- ナビゲーションペインの Data Catalog で、Tables を選択します。
- Add table を選択します。
- テーブル作成のガイド付き手順で、Step 1: Set table properties に次の入力を行います。
- Name に
treesと入力します。 - Database で
collectionsを選択します。 - Description に
This table captures ratings data related to the characteristics of various tree speciesと入力します。 - Table format で Standard AWS Glue table (default) を選択します。
- Select the type of source で S3 を選択します。
- Data location is specified in で my account を選択します。
- Include path に
s3://<bucket-name>/<prefix>/と入力します。<bucket-name>は前の手順で作成した S3 バケットの名前、<prefix>はアップロードしたtrees.csvファイルのオプションのプレフィックスです。 - Data format で CSV を選択します。
- Delimeter で Comma (,) を選択します。
- Name に
- Next を選択します。
- Step 2: Choose or define schema で次のように入力します。
- Schema で Define or upload a schema を選択します。
- Edit schema as JSON を選択し、ポップアップに次のスキーマを入力します。
- Save を選択します。
- Next を選択します。
- Create を選択します。
コンシューマーアカウントで Lambda 関数を作成する
コンシューマーアカウントで Lambda 関数を作成します。データコンシューマーアプリケーションをシミュレートします。まず、コンシューマーアカウントで Lambda 関数に割り当てる IAM ポリシーと IAM ロールを作成します。
- コンシューマーアカウントで IAM コンソールにアクセスします。
- 次のポリシーを使用して IAM ポリシーを作成し、
smus_consumer_athena_executionという名前を付けます。プレースホルダー<AWS_Region>と<AWS_account_ID_number>をリージョンとコンシューマーアカウント ID 番号に置き換えてください。<workgroup_id>プレースホルダーは後で置き換えます。IAM ポリシー作成の手順については、「IAM ポリシーの作成 (コンソール)」を参照してください。 - AWS Lambda サービス用の IAM ロールを作成し、
smus_consumer_lambdaという名前を付けます。AWS マネージドアクセス許可AWSLambdaBasicExecutionRoleと、作成したばかりのsmus_consumer_athena_executionという名前のアクセス許可を割り当てます。手順については、「AWS サービスにアクセス許可を委任するロールの作成」を参照してください。
Lambda 関数の IAM ロールが配置されたら、コンシューマーアカウントで Lambda 関数を作成できます。
- コンシューマーアカウントで Lambda コンソールにアクセスします。
- ナビゲーションペインで Functions を選択します。
- Create function を選択し、次の情報を入力します。
- Function name に
consumer_functionと入力します。 - Runtime で Python 3.14 を選択します。
- Change default execution role セクションを展開します。
- Execution role で Use an existing role を選択します。
- Existing role で
smus_consumer_lambdaを選択します。
- Function name に
- Create function を選択します。
- Code タブの Code source で、既存のコードを次のコードに置き換えます。
- Deploy を選択します。
Lambda 関数に提供されたコードには、後で必要な情報を入手した後に置き換えるプレースホルダーがいくつか含まれています。プレースホルダーをまだ置き換えていないので、この時点では Lambda 関数をテストしないでください。
管理者アクセス権を持つユーザーを作成する
Amazon SageMaker Unified Studio は、AWS IAM Identity Center ベースのドメインと IAM ベースのドメインという 2 つの異なるドメインタイプをサポートしています。本記事の執筆時点では、IAM Identity Center ベースのドメインのみが複数アカウントの関連付けをサポートしているため、本記事では IAM Identity Center を必要とするこのタイプのドメインを使用します。
ガバナンスアカウントで、IAM Identity Center を有効にし、Amazon SageMaker Unified Studio ドメインを作成および管理する管理ユーザーを作成します。管理者アクセス権を持つユーザーを作成します。
- ガバナンスアカウントで IAM Identity Center を有効にします。手順については、「IAM Identity Center の有効化」を参照してください。
- ガバナンスアカウントの IAM Identity Center で、ユーザーに管理者アクセス権を付与します。IAM Identity Center ディレクトリを ID ソースとして使用するチュートリアルについては、「デフォルトの IAM Identity Center ディレクトリでユーザーアクセスを設定する」を参照してください。
管理者アクセス権を持つユーザーとしてサインインします。
- IAM Identity Center ユーザーでサインインするには、IAM Identity Center ユーザーを作成したときにメールアドレスに送信されたサインイン URL を使用します。IAM Identity Center ユーザーを使用したサインインのヘルプについては、「AWS アクセスポータルにサインインする」を参照してください。
SageMaker Unified Studio ドメインを作成する
ガバナンスアカウントで Amazon SageMaker Unified Studio ドメインを作成するには、「Amazon SageMaker Unified Studio ドメインの作成 – クイックセットアップ」を参照してください。
ドメインが作成されたら、Amazon SageMaker Unified Studio ポータル (Web アプリケーション) に移動できます。ポータルでは分析と AI のためにデータと設定されたツールを使用できます。後で使用するため、Amazon SageMaker Unified Studio ポータルの URL を保存してください。
ソリューションの手順
前提条件が整ったので、次の 10 個の手順でソリューションを実装できます。
プロデューサーアカウントとコンシューマーアカウントを Amazon SageMaker Unified Studio ドメインに関連付ける
まず、プロデューサーアカウントとコンシューマーアカウントを新しく作成した Amazon SageMaker Unified Studio ドメインに関連付けます。プロデューサーアカウントとコンシューマーアカウントをドメインに関連付ける際は、AWS RAM share managed permission セクションで IAM users and roles can access APIs and IAM users can log in to Amazon SageMaker Unified Studio を選択してください。ステップバイステップの手順については、「Amazon SageMaker Unified Studio の関連アカウント」を参照してください。AWS アカウントが同じ組織に属している場合、関連付けリクエストは自動的に承認されます。ただし、AWS アカウントが同じ組織に属していない場合は、ガバナンスアカウントで他の AWS アカウントとの関連付けをリクエストし、プロデューサーアカウントとコンシューマーアカウントの両方で関連付けリクエストを承認します。
2 つのプロジェクトプロファイルを作成する
次に、プロデューサープロジェクト用とコンシューマープロジェクト用の 2 つのプロジェクトプロファイルを作成します。
Amazon SageMaker Unified Studio では、プロジェクトプロファイルは Amazon SageMaker ドメイン内のプロジェクトの上位テンプレートを定義します。プロジェクトプロファイルは、プロジェクトリソースの作成に使用される再利用可能な AWS CloudFormation テンプレートを提供するブループリントのコレクションです。
プロジェクトプロファイルは特定の AWS アカウントに関連付けられます。つまり、プロジェクトが作成されると、プロジェクトプロファイルにリストされているブループリントが関連付けられた AWS アカウントにデプロイされます。プロジェクトプロファイルを使用するには、プロジェクトプロファイルに関連付けられた AWS アカウントでブループリントを有効にする必要があります。
プロデューサープロジェクトプロファイルを作成する
プロデューサーアカウントに関連付けられたプロデューサープロジェクトプロファイルを作成します。このプロジェクトプロファイルでプロデューサープロジェクトを作成します。このプロファイルには、IAM ユーザーロールやセキュリティグループなどのプロジェクトリソースを作成する Tooling ブループリントがデフォルトで含まれています。
プロジェクトプロファイルを作成する前に、次の手順を使用してプロデューサーアカウントで Tooling ブループリントを有効にします。
-
- プロデューサーアカウントで SageMaker コンソールにアクセスします。
- ナビゲーションペインで Associated domains を選択します。
- セットアップ中に作成したドメインを選択します。
- Blueprints タブで、Tooling blueprint セクションの Enable を選択します。次の画像を参照してください。

- Virtual private cloud (VPC) でアカウントの VPC を選択します。
- Subnets で、異なるアベイラビリティーゾーンの少なくとも 2 つのサブネットを選択します。
- Enable blueprint を選択します。
ガバナンスアカウントでプロジェクトプロファイルの作成に進みます。
- ガバナンスアカウントで SageMaker コンソールにアクセスします。
- ナビゲーションペインで Domains を選択します。
- 前提条件の一部として作成したドメインを選択します。
- Project profiles タブで Create を選択し、次の情報を入力します。
- Project profile name に
producer-project-profileと入力します。 - Project profile creation options で Custom create を選択します。
- Blueprints でブループリントを選択しないでください。
Toolingブループリントはすべてのプロジェクトプロファイルにデフォルトで含まれているためです。 - Account で Provide an account ID を選択します。
- Account ID にプロデューサーアカウント ID を入力します。
- Region で Provide region name を選択し、作業しているリージョンを選択します。
- Authorization で Allow all users and groups を選択します。
- Project profile readiness で Enable project profile on creation を選択します。
- Project profile name に
- Create project profile を選択します。
コンシューマープロジェクトプロファイルを作成する
コンシューマープロジェクトプロファイルも作成し、コンシューマーアカウントに関連付けます。このプロファイルでコンシューマープロジェクトを作成します。コンシューマープロジェクトプロファイルには、データ管理用の AWS Glue データベースとクエリ用の Amazon Athena ワークグループを備えたレイクハウス環境を作成するために必要な LakeHouseDatabase ブループリントが含まれています。Tooling ブループリントはプロジェクトプロファイルにデフォルトで含まれています。
プロジェクトプロファイルを作成する前に、コンシューマーアカウントで Tooling と LakeHouseDatabase ブループリントを有効にします。
- コンシューマーアカウントで SageMaker コンソールにアクセスします。
- ナビゲーションペインで Associated domains を選択します。
- 前提条件の一部として作成したドメインを選択します。
- Blueprints タブで、Tooling blueprint セクションの Enable を選択します。
- Virtual private cloud (VPC) でアカウントの VPC を選択します。
- Subnets で、異なるアベイラビリティーゾーンの少なくとも 2 つのサブネットを選択します。
- Enable blueprint を選択します。
- ナビゲーションペインで Associated domains を選択します。
- 前提条件の一部として作成したドメインを選択します。
- Blueprints タブで
LakeHouseDatabaseブループリントを選択します。 - Enable を選択します。
- Enable blueprint を選択します。
コンシューマーアカウントでブループリントが有効になったら、プロジェクトプロファイルの作成に進むことができます。
- ガバナンスアカウントで SageMaker コンソールにアクセスします。
- ナビゲーションペインで Domains を選択します。
- 前提条件の一部として作成したドメインを選択します。
- Project profiles タブで Create を選択し、次の情報を入力します。
- Project profile name に
consumer-project-profileと入力します。 - Project profile creation options で Custom create を選択します。
- Blueprints で
LakeHouseDatabaseを選択します。 - Account で Provide an account ID を選択します。
- Account ID にコンシューマーアカウント ID を入力します。
- Region で Provide region name を選択し、作業しているリージョンを選択します。
- Authorization で Allow all users and groups を選択します。
- Project profile readiness で Enable project profile on creation を選択します。
- Project profile name に
- Create project profile を選択します。
SageMaker Unified Studio のプロデューサープロジェクトとコンシューマープロジェクトを作成する
Amazon SageMaker Unified Studio では、プロジェクトはドメイン内の境界であり、他のユーザーと協力してビジネスユースケースに取り組むことができます。プロジェクトでは、データとリソースを作成して共有できます。Amazon SageMaker Unified Studio でプロデューサープロジェクトとコンシューマープロジェクトを作成するには、次の手順を使用します。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択します。
- Create project を選択し、次の情報を入力します。
- Project name に
Producerと入力します。 - Project profile で
producer-project-profileを選択します。
- Project name に
- Continue を選択します。
- Continue を選択します。
- Create project を選択します。
Producer プロジェクトを作成したら、Project overview に表示される Project role ARN をテキストファイルにメモします。次の画像を参照してください。プロジェクトロール名は、プロジェクトロール Amazon Resource Name (ARN) の arn:aws:iam::<account_ID>:role/ に続く文字列です。プロジェクトロール名と ARN の両方を後で使用します。
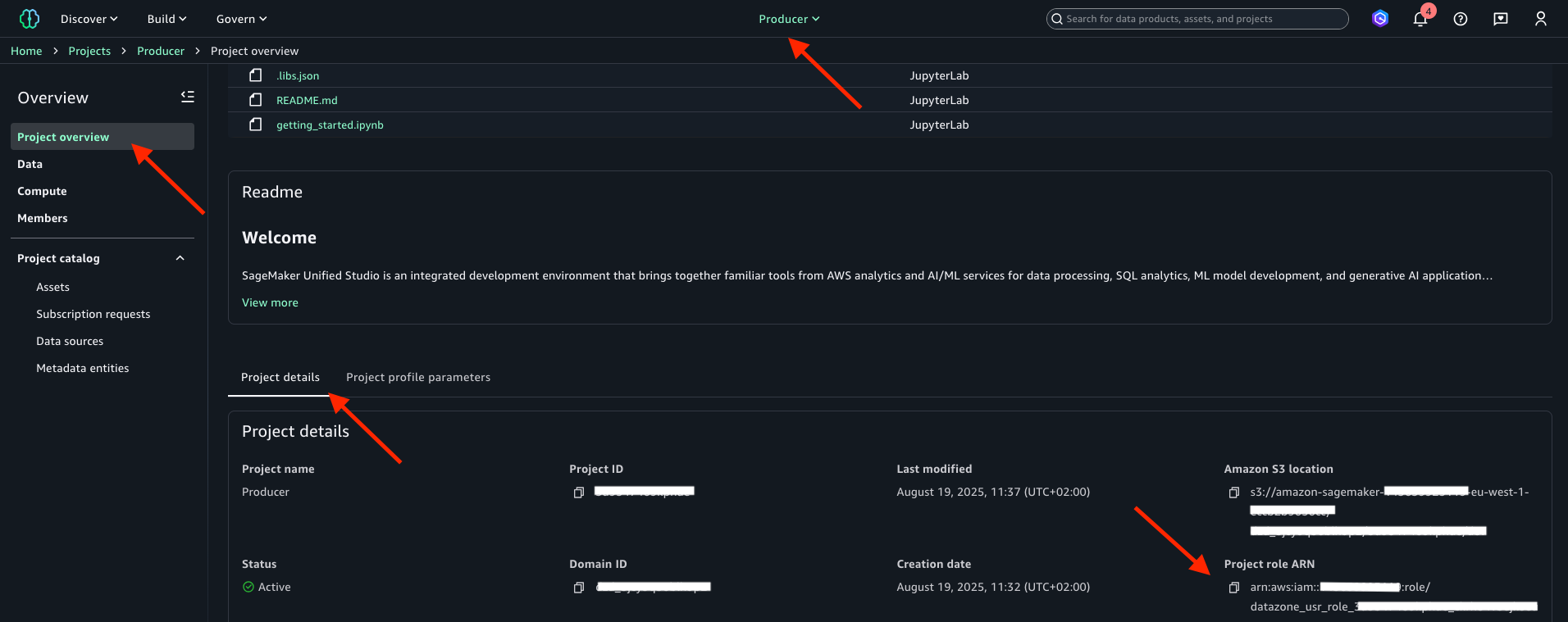
前の手順を繰り返して Consumer プロジェクトを作成します。Project name に Consumer と入力し、Project profile で consumer-project-profile を選択してください。作成後、Project role ARN をテキストファイルにメモします。プロジェクトロール名は、プロジェクトロール ARN の arn:aws:iam::<account_ID>:role/ に続く文字列です。プロジェクトロール名と ARN の両方を後で使用します。
プロデューサーアカウントから独自データを持ち込む
Amazon SageMaker Unified Studio の Producer プロジェクトに独自のデータを持ち込み(取り込み)ます。AWS はこれを実現するためのいくつかのオプションを提供しています。最初のオプションは Amazon SageMaker レイクハウスでの自動オンボーディング(導入)で、データセットの Amazon SageMaker レイクハウスメタデータを Amazon SageMaker Catalog に取り込みます。このオプションでは、新しい Amazon SageMaker Unified Studio ドメインの作成の一部として、または既存のドメインに対して Amazon SageMaker レイクハウスデータをオンボードできます。
Amazon SageMaker レイクハウスデータの自動オンボーディングの詳細については、「Amazon SageMaker Unified Studio でのデータのオンボーディング」を参照してください。他のオプションとして、プロジェクトの Data ページと Compute ページを使用するか、GitHub で提供されているスクリプトを使用して、既存のリソースを Amazon SageMaker Unified Studio プロジェクトに持ち込むことができます。Data ページと Compute ページの使用、またはスクリプトの使用の詳細については、「既存のリソースを Amazon SageMaker Unified Studio に持ち込む」を参照してください。本記事では、Amazon SageMaker レイクハウス機能を使用して trees AWS Glue テーブルを Producer プロジェクトにインポートします。
テーブルの Amazon S3 ロケーションを登録する
trees テーブルへのきめ細かいアクセス制御に Lake Formation アクセス許可を使用するには、trees テーブルの Amazon S3 ロケーションを Lake Formation に登録する必要があります。次のアクションを実行します。
- プロデューサーアカウントで Lake Formation コンソールにアクセスします。
- ナビゲーションペインの Administration で、Data lake locations を選択します。
- Register location を選択し、次の情報を入力します。
- S3 URI に
s3://<bucket-name>/<prefix>/と入力します。<bucket-name>は前提条件で作成した S3 バケットの名前、<prefix>は前提条件の一部としてアップロードしたtrees.csvファイルのオプションのプレフィックスです。 - IAM role で
AWSServiceRoleForLakeFormationDataAccessを選択します。 - Permission mode で Lake Formation を選択します。
- S3 URI に
- Register location を選択します。
Producer プロジェクトロールにデータベースのアクセス許可を付与する
Producer プロジェクトに関連付けられた IAM ロールにデータベースアクセスを付与します。このロールはプロジェクトロールと呼ばれ、プロジェクト作成時に IAM で作成されました。
Amazon SageMaker Unified Studio の Producer プロジェクトから AWS Glue Data Catalog の collections データベースにアクセスするには、次のアクションを実行します。
- プロデューサーアカウントで Lake Formation コンソールにアクセスします。
- ナビゲーションペインの Data Catalog で、Databases を選択します。
collectionsデータベースを選択します。- Actions メニューから Grant を選択し、次の情報を入力します。
- IAM users and roles で、
Producerプロジェクトのロール名を選択します。これは、ステップ 3「SageMaker Unified Studio のプロデューサープロジェクトとコンシューマープロジェクトを作成する」でメモしたProducerプロジェクトロール ARN の一部であるdatazone_usr_role_で始まる文字列です。 - Database permissions で Describe を選択します。
- IAM users and roles で、
- Grant を選択します。
Producer プロジェクトロールにテーブルのアクセス許可を付与する
Producer プロジェクトに関連付けられた IAM ロールに trees テーブルアクセスを付与します。これらのアクセス許可を付与するには次の手順に従います。
- プロデューサーアカウントで Lake Formation コンソールにアクセスします。
- ナビゲーションペインの Data Catalog で、Tables and MVs を選択します。
treesテーブルを選択します。- Actions メニューから Grant を選択し、次の情報を入力します。
- IAM users and roles で、
Producerプロジェクトのロールを選択します。これは、ステップ 3「SageMaker Unified Studio のプロデューサープロジェクトとコンシューマープロジェクトを作成する」でメモしたProducerプロジェクトロール ARN の一部であるdatazone_usr_role_で始まる文字列です。 - Table permissions で Select と Describe を選択します。
- Grantable permissions で Select と Describe を選択します。
- IAM users and roles で、
- Grant を選択します。
IAMAllowedPrincipals の既存のアクセス許可を取り消す
アクセスに Lake Formation アクセス許可を適用するには、データベースとテーブルの両方で IAMAllowedPrincipals グループのアクセス許可を取り消す必要があります。詳細については、「Lake Formation コンソールを使用したアクセス許可の取り消し」を参照してください。
-
- プロデューサーアカウントで Lake Formation コンソールにアクセスします。
- ナビゲーションペインの Permission で、Data permissions を選択します。
- Principal が
IAMAllowedPrincipalsに設定され、Resource がcollectionsまたはtreesに設定されているエントリを選択します。次の画像を参照してください。
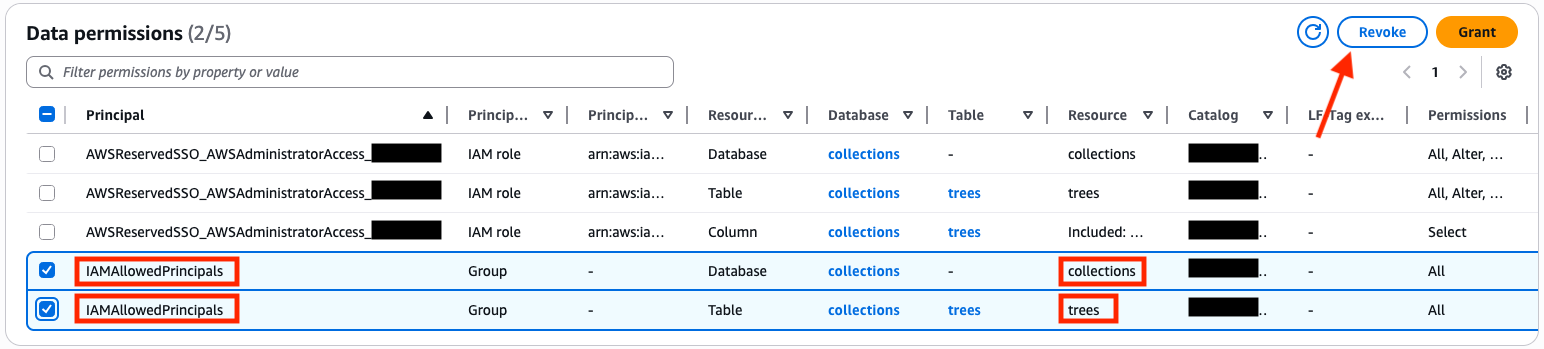
- Revoke を選択します。
revokeと入力します。- 再度 Revoke を選択します。
Producer プロジェクトでデータが利用可能であることを確認する
Producer プロジェクトで collections データベースと trees テーブルにアクセスできることを確認します。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンメニューを選択し、
Producerプロジェクトを選択します。 - ナビゲーションペインの Overview で、Data を選択します。
- Lakehouse を選択します。
- AwsDataCatalog を選択します。
collectionsを選択します。- tables を選択します。
treesテーブルの横にある 3 点アクションメニューを選択し、Preview data を選択します。次の画像を参照してください。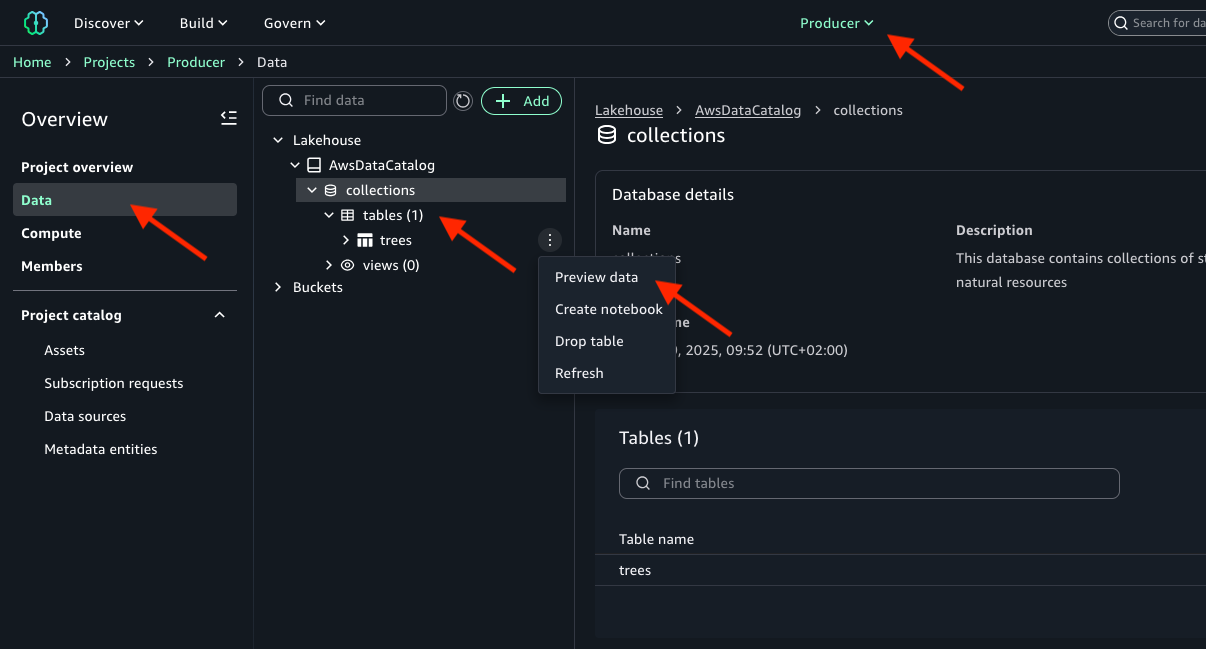
- 次の画像に示すように、
treesテーブルのデータが表示されます。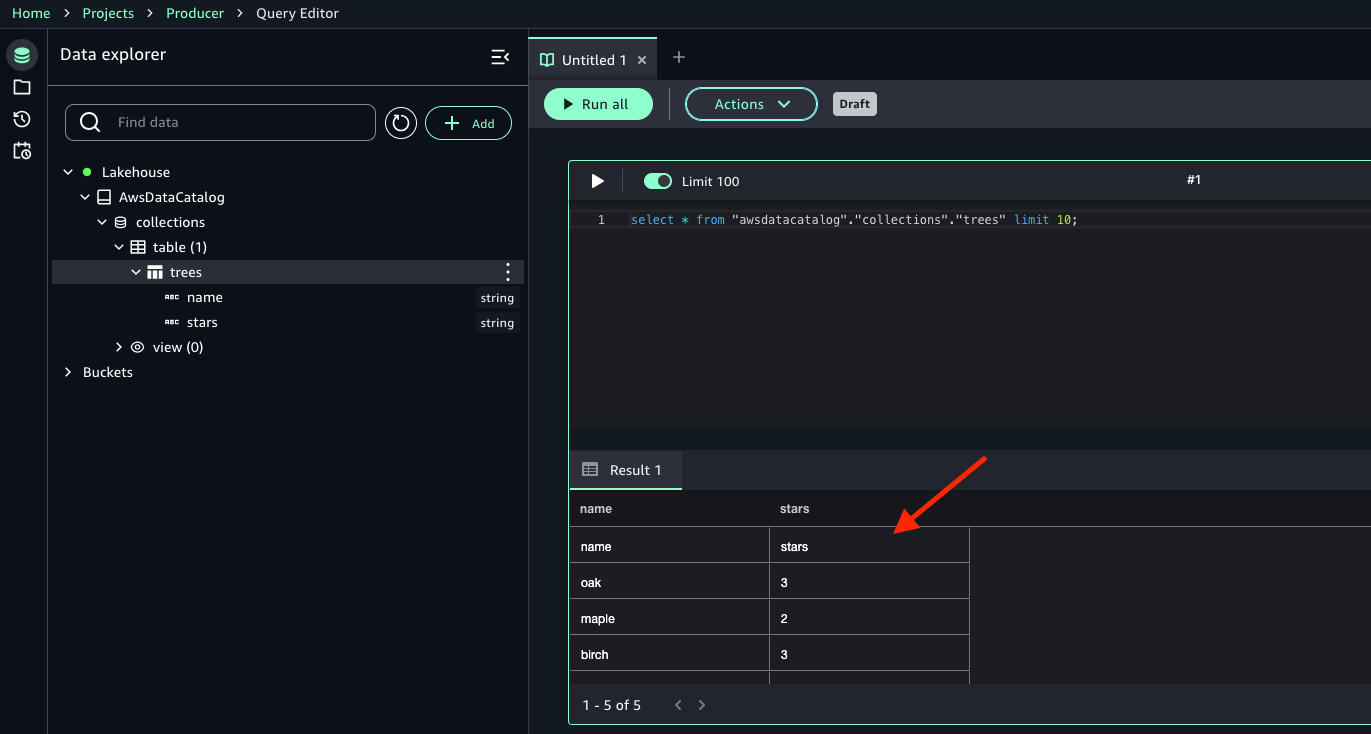
Amazon SageMaker Catalog アセットを作成する
プロジェクトでアクセス可能であっても、Amazon SageMaker Catalog で trees テーブルを操作するには、データソースを登録して Amazon SageMaker Catalog アセットを作成する必要があります。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択し、
Producerプロジェクトを選択します。 - プロジェクトページのナビゲーションペインの Project catalog で、Data sources を選択します。
- Create Data Source を選択し、次のように選択します。
- Name に
collectionsと入力します。 - Data source type で AWS Glue (Lakehouse) を選択します。
- Database name で
collectionsを選択します。 - Next を選択します。
- Next を選択します。
- Next を選択します。
- Create を選択します。
- Name に
- データソースが作成されたら、
collectionsデータソースページで Run を選択します。これによりメタデータがインポートされ、Amazon SageMaker Catalog アセットが作成されます。 collectionsデータソースの Data source runs タブで、実行が Completed とマークされ、treesアセットが Successfully created と表示されます。次の画像を参照してください。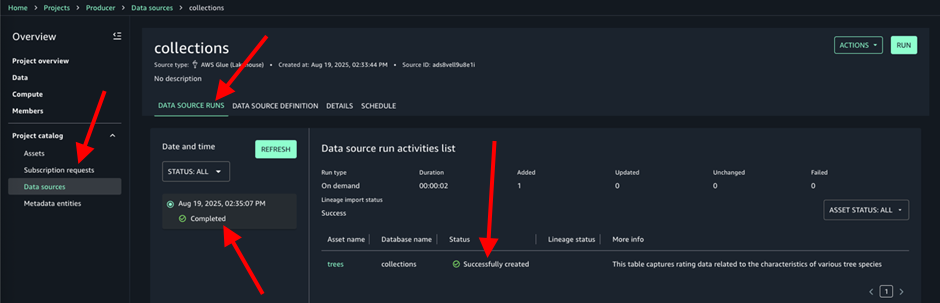
Amazon SageMaker Catalog でデータアセットを公開する
データアセットを手動で公開することは、他のユーザーがカタログを通じてデータアセットにアクセスできるようにするために実行する必要がある 1 回限りの操作です。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択し、
Producerプロジェクトを選択します。 - プロジェクトページの Project catalog で、Assets を選択します。
- Inventory タブで利用可能な
treesデータアセットを選択します。次の画像を参照してください。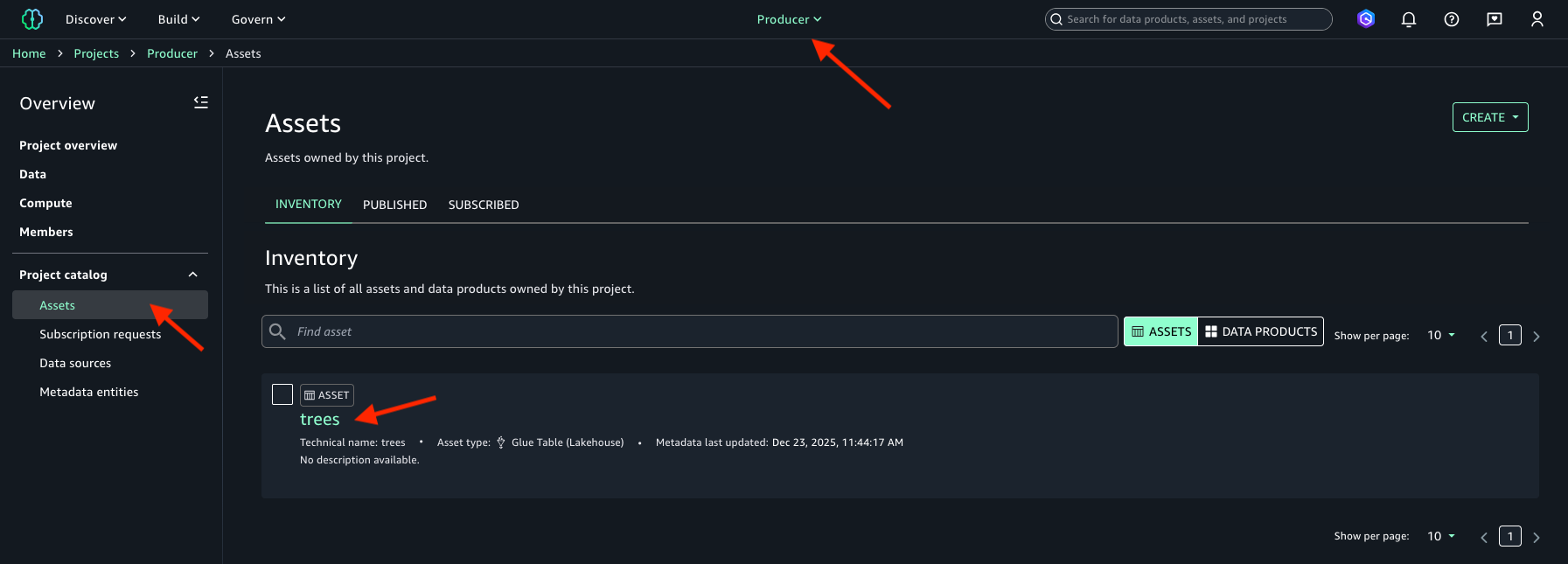
- (オプション) データソースの作成時に自動メタデータ生成が有効になっている場合、アセットのメタデータ (アセットのビジネス名など) を確認して承認または拒否できます。Automated Metadata Generation バナーで Accept All または Reject All を選択できます。
- Publish Asset を選択します。次の画像を参照してください。
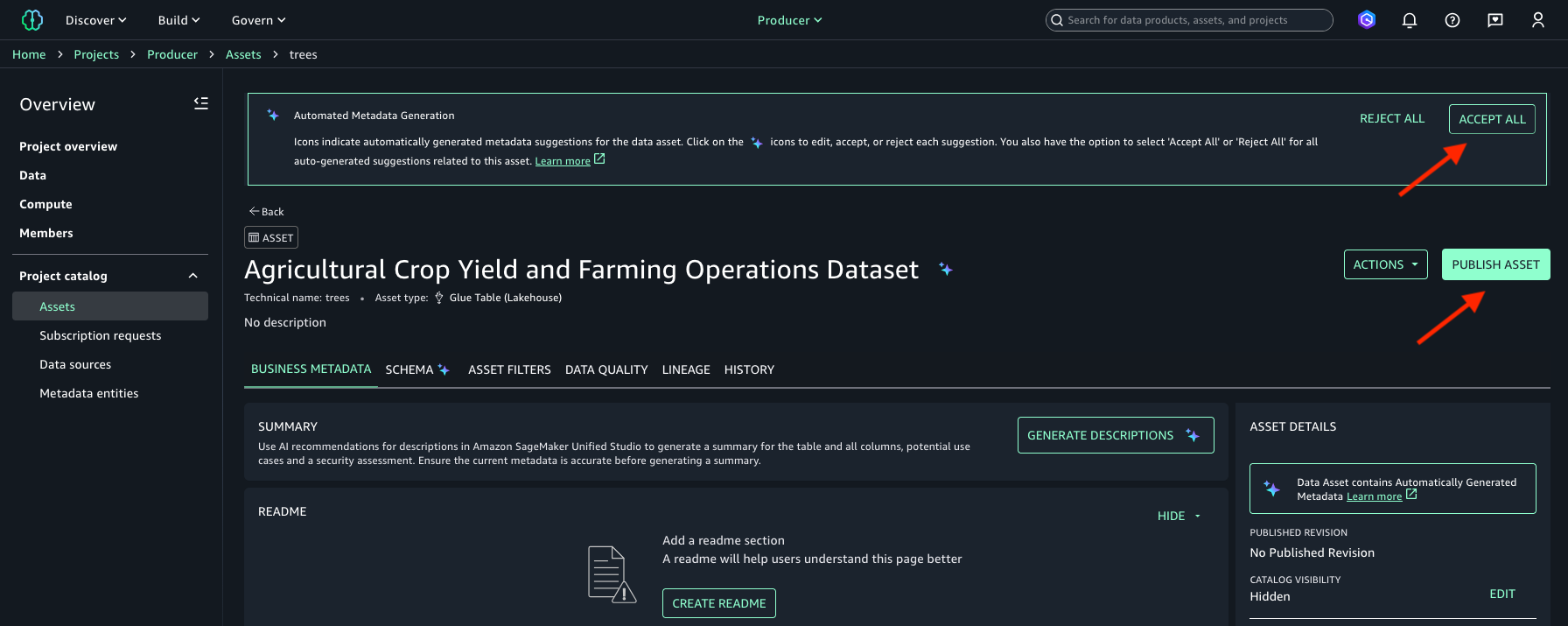
- Publish Asset を選択します。
Amazon SageMaker Catalog でデータアセットをサブスクライブする
Consumer プロジェクトでデータアセットを消費するには、サブスクリプションリクエストを作成してデータアセットをサブスクライブします。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択し、
Consumerプロジェクトを選択します。 - Discover メニューで Catalog を選択します。
- 検索ボックスに
treesと入力し、検索から返されたデータアセットを選択します。ステップ 7「Amazon SageMaker Catalog でデータアセットを公開する」で Automated Metadata Generation バナーの Accept All を選択した場合、データアセットには自動メタデータ推奨機能によって生成された別のビジネス名が付けられます。データアセットのテクニカルネームはtreesです。次の画像を参照してください。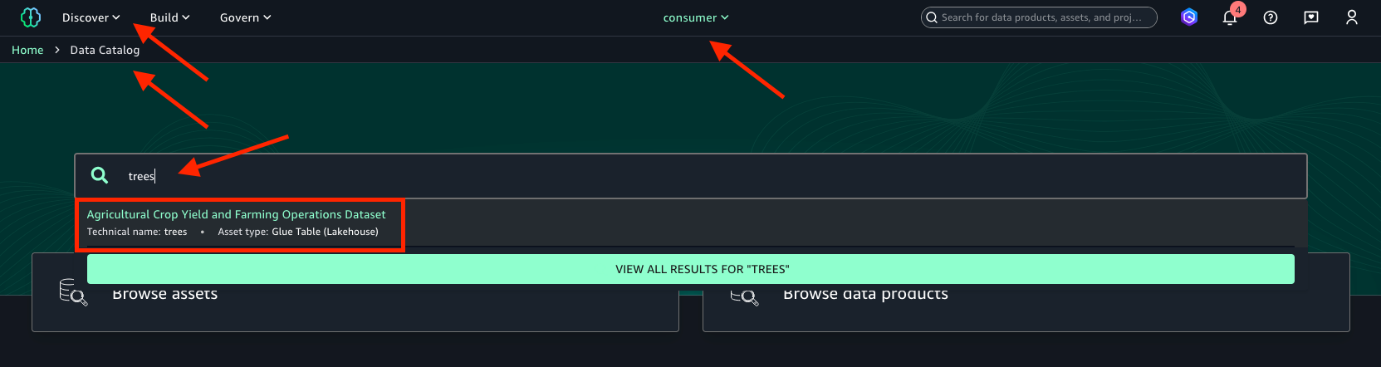
- Subscribe を選択します。
- Comment に、
This data asset is needed for model training purposesなどの正当な理由を入力します。 - 再度 Subscribe を選択します。
デフォルトでは、アセットサブスクリプションリクエストにはデータ所有者による手動承認が必要です。ただし、Consumer プロジェクトのリクエスターが Producer プロジェクトのメンバーでもある場合、サブスクリプションリクエストは自動的に承認されます。サブスクリプションリクエストの承認の詳細については、「Amazon SageMaker Unified Studio でサブスクリプションリクエストを承認または拒否する」を参照してください。
サブスクライブしたデータアクセスにアクセスするように Lambda IAM ロールを設定する
Lambda 関数がサブスクライブしたデータアセットにアクセスできるようにするには、Lambda 関数が Consumer プロジェクトロールを引き受けることを許可する必要があります。Consumer プロジェクトの IAM ロール信頼関係を編集します。
- コンシューマーアカウントで IAM コンソールに移動します。
- ナビゲーションペインの Access management で、Roles を選択します。
Consumerプロジェクトの IAM ロールを選択します。これは、ステップ 3「SageMaker Unified Studio のプロデューサープロジェクトとコンシューマープロジェクトを作成する」でメモしたConsumerプロジェクトロール ARN の一部であるdatazone_usr_role_で始まる文字列です。- Trust relationships タブで、Edit trust policy を選択します。
- バックアップのため、既存の信頼ポリシーのコピーをテキストファイルに作成します。
- Edit trust policy ウィンドウで、信頼ポリシーの他の既存のステートメントを削除または上書きしないようにしつつ、次のステートメントを既存の信頼ポリシーに追加します。プレースホルダー
<account_id>をコンシューマー AWS アカウント ID に置き換えてください。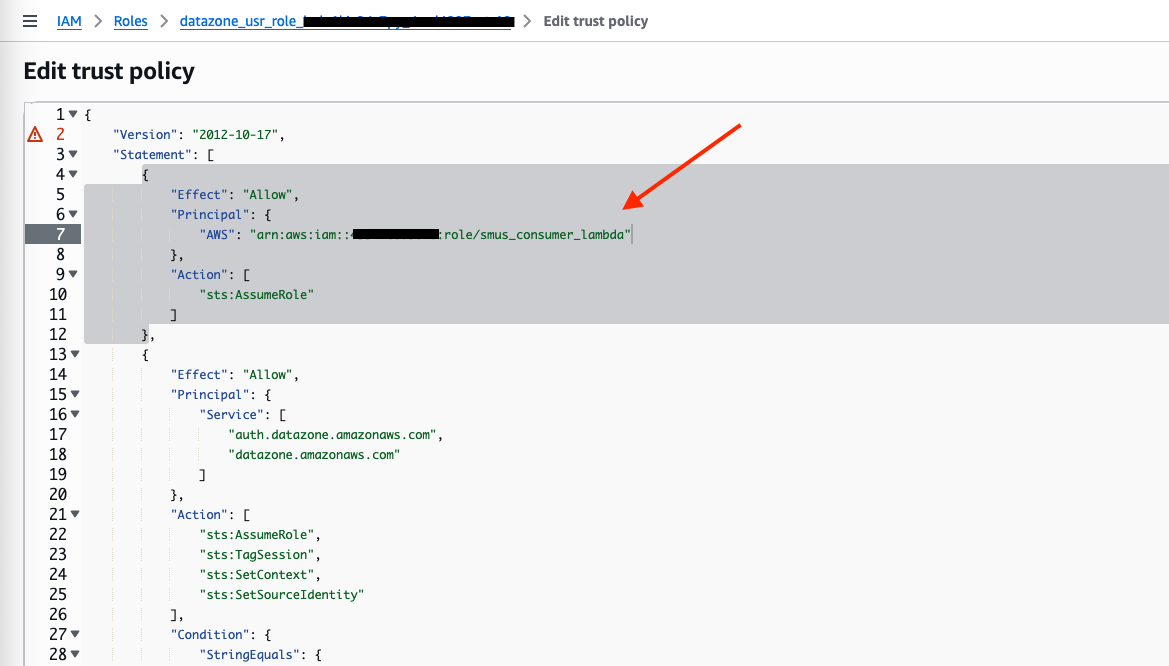
- Update policy を選択します。
サブスクライブしたデータアセットへの Lambda 関数のアクセスをテストする
Lambda 関数をテストする前に、関数コードと IAM ポリシーのプレースホルダーを置き換える必要があります。置き換える必要があるプレースホルダーは 3 つあります: <role_arn>、<database_name>、<workgroup_id> です。<role_arn> については、ステップ 3「SageMaker Unified Studio のプロデューサープロジェクトとコンシューマープロジェクトを作成する」でメモした Consumer プロジェクトのロール ARN という実際の値がすでにあります。次のセクションでは、他のプレースホルダーの値を取得する手順を説明します。
AWS Glue Data Catalog データベース名を取得する
Consumer プロジェクトと共に作成された AWS Glue Data Catalog データベースの名前を取得します。次に、この値を使用して consumer_function Lambda 関数コードの <database_name> プレースホルダーを置き換えます。AWS Glue Data Catalog データベース名を取得するには、次の手順に従います。
-
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択し、
Consumerプロジェクトを選択します。 - プロジェクトページの Overview で、Data を選択します。
- Lakehouse を選択します。
- AwsDataCatalog を選択します。
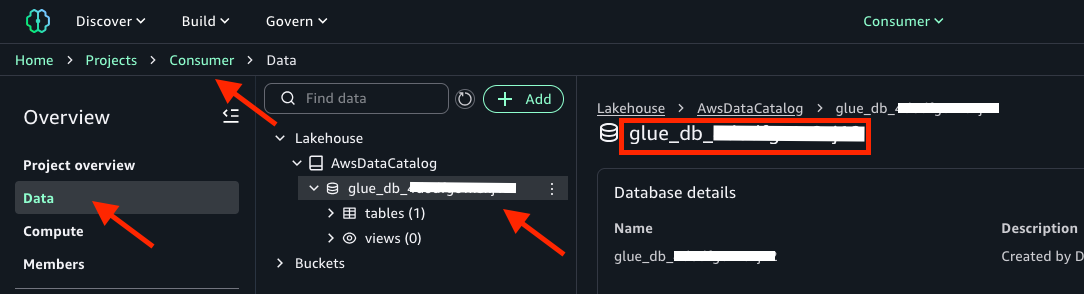
- データベースの名前をコピーします。次の画像のように、
glue_dbで始まる英数字の文字列である必要があります。
Athena ワークグループ ID を取得する
Consumer プロジェクトと共に作成された Athena ワークグループの ID を取得します。次に、この値を使用して consumer_function Lambda 関数コードと smus_consumer_athena_execution IAM ポリシーの <workgroup_id> プレースホルダーを置き換えます。Athena ワークグループ ID を取得するには、次の手順を使用します。
- Amazon SageMaker Unified Studio ポータルにアクセスします。
- Select a project ドロップダウンリストを選択し、
Consumerプロジェクトを選択します。 - プロジェクトページの Overview で、Compute を選択します。
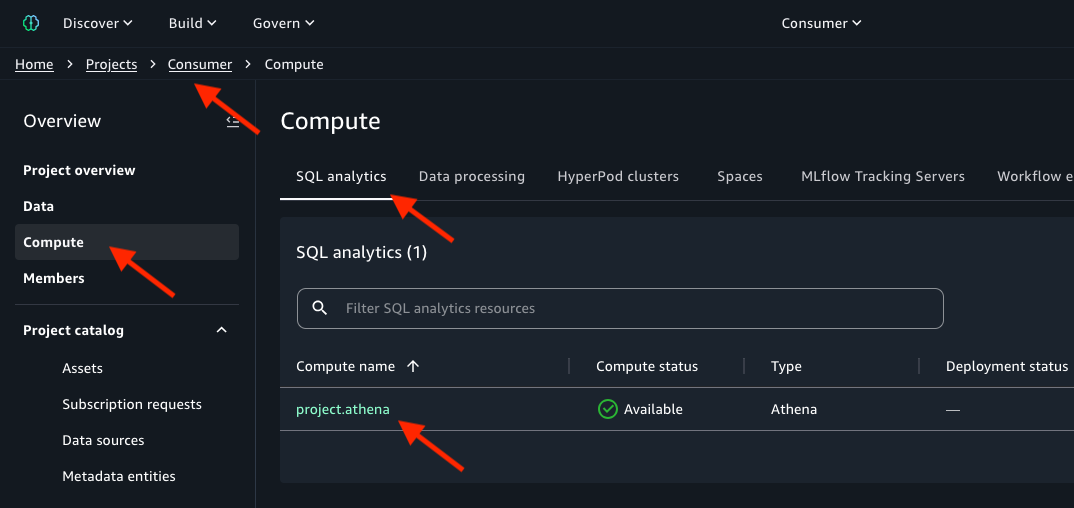
- SQL analytics タブで project.athena を選択します。次の画像を参照してください。
- Workgroup ARN をコピーしてテキストファイルに保存します。Athena ワークグループ ID は、Workgroup ARN の
arn:aws:athena:<region>:<account_ID>:workgroup/に続く文字列です。
smus_consumer_athena_execution IAM ポリシーのプレースホルダーを置き換える
smus_consumer_athena_execution IAM ポリシーの <workgroup_id> プレースホルダーを置き換えるには、次の手順を使用します。
- コンシューマーアカウントで IAM コンソールにアクセスします。
- ナビゲーションペインで Policies を選択します。
- 検索フィールドに
smus_consumer_athena_executionと入力します。 smus_consumer_athena_executionポリシーを選択します。- Edit を選択します。
<workgroup_id>を前にメモした値に置き換えます。- Next を選択します。
- Save changes を選択します。
Lambda 関数コードのプレースホルダーを置き換えてテストする
consumer_function Lambda 関数コードの <role_arn>、<database_name>、<workgroup_id> プレースホルダーを置き換え、trees テーブルのデータにアクセスする関数の機能をテストします。
- コンシューマーアカウントで Lambda コンソールにアクセスします。
- ナビゲーションペインで Functions を選択します。
consumer_functionを選択します。- Code タブで、
<role_arn>、<database_name>、<workgroup_id>プレースホルダーを前にメモした各値に置き換えます。 - Deploy を選択します。
- Test タブで、Event name に
mytestと入力します。 - Test を選択します。
- 実行が完了した後に表示される Executing function というタイトルの緑色のバナーで Details を選択します。
- 実行ログに
treesテーブルの内容が報告されます。次の画像を参照してください。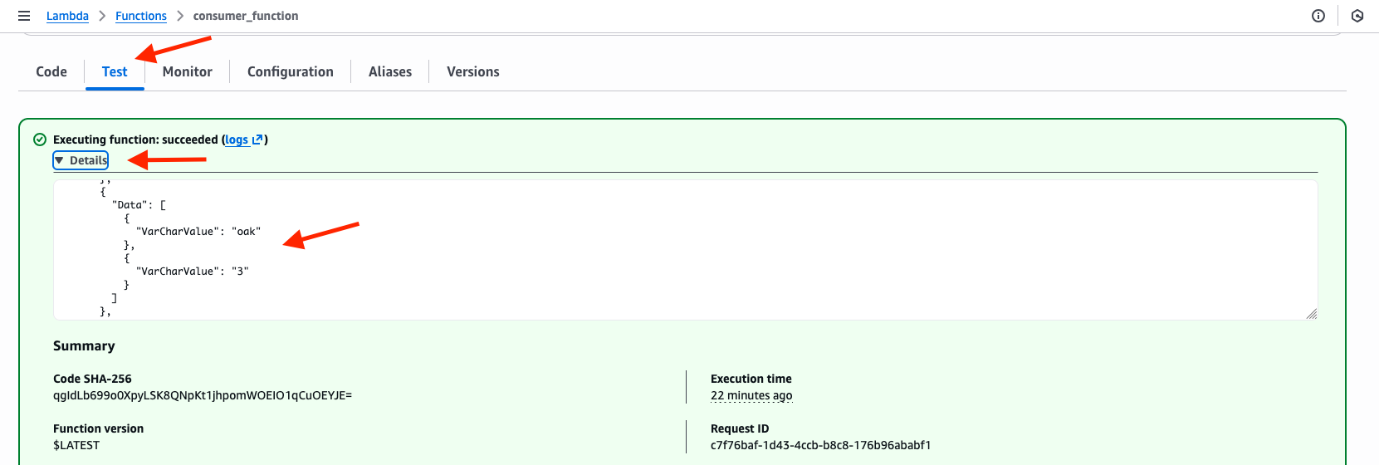
Lambda 関数の実行がタイムアウトで失敗する場合は、次のように関数のタイムアウト設定を変更します。
- コンシューマーアカウントで Lambda コンソールにアクセスします。
- ナビゲーションペインで Functions を選択します。
consumer_functionを選択します。- Configuration タブで Edit を選択します。
- Timeout に 15 秒以上の値を入力します。
- Save を選択します。
タイムアウトを増やした後、関数を再度テストします。
クリーンアップ
作成したリソースが不要になった場合は、追加料金が発生しないように削除してください。まず、ガバナンスアカウントで Amazon SageMaker Unified Studio ドメインを削除します。詳細については、「ドメインの削除」を参照してください。
プロデューサーアカウントから AWS Glue collections データベースを削除するには、次の手順に従います。
- プロデューサーアカウントで Glue コンソールにアクセスします。
- ナビゲーションペインの Data Catalog で、Databases を選択します。
collectionsデータベースを選択します。- Delete を選択します。
- Delete を選択します。
プロデューサーアカウントから S3 バケットを削除するには、バケットを空にしてからバケットを削除できます。バケットを空にする方法については、「汎用バケットを空にする」を参照してください。バケットの削除については、「汎用バケットの削除」を参照してください。
コンシューマーアカウントから Lambda 関数を削除するには、次の手順に従います。
- コンシューマーアカウントで Lambda コンソールにアクセスします。
- ナビゲーションペインで Functions を選択します。
consumer_functionLambda 関数を選択します。- Actions メニューを選択し、Delete function を選択します。
confirmと入力します。- Delete を選択します。
クリーンアップの最後に、コンシューマーアカウントで smus_consumer_lambda という名前の IAM ロールを削除し、次に smus_consumer_athena_execution という名前の IAM ポリシーを削除します。IAM ロールの削除については、「ロールまたはインスタンスプロファイルの削除」を参照してください。IAM ポリシーの削除については、「IAM ポリシーの削除」を参照してください。
まとめ
本記事では、既存のアプリケーションとデータリポジトリを再設計せずに、データガバナンスのために Amazon SageMaker Catalog を採用する方法について説明しました。Amazon SageMaker Unified Studio で既存のデータをオンボードし、カタログで公開し、Amazon SageMaker Unified Studio プロジェクトのコンテキスト外にデプロイされたリソースからデータをサブスクライブして利用する方法を説明しました。このソリューションは、Amazon SageMaker Catalog でデータメッシュパターンの実装を加速し、組織内でデータを安全に公開、検索、アクセスするのに役立ちます。
詳細については、「Amazon SageMaker とは」を参照し、Amazon SageMaker ワークショップ を実行して、データ、分析、AI の統合エクスペリエンスを試してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Akira Shimosako がレビューしました。