Amazon Web Services ブログ
AWS CDK で作る AWS Inferentia と Amazon ECS を利用した推論環境(Part 2)
目次
前回の投稿では、Part 1 として検証用の Amazon EC2 Inf1 インスタンスを AWS CDK を用いて構築し、その上で Docker を用いてアプリケーションを構築しました。そして、作成した Docker イメージを Amazon ECR にプッシュするところまでを解説しました。本記事では、AWS Inferentia を用いて推論処理を行うアプリケーションを Amazon ECS でサービングするための環境を AWS CDK で作成します。
事前準備
構築にあたって前提とすることを以下に示します。設定ファイルと認証情報ファイルの設定についてはドキュメントをご参照ください。本投稿のサンプルコードをご利用される際には、セキュリティ観点での確認を必ず行なってください。サンプルコードは、2022年6月21日時点の情報に基づいて作成しており、情報の変更により動かなくなる可能性がありますがご了承ください。
- AWS Command Line Interface aws-cli/1.23.2 以降が利用可能な状態であること
- AWS CDK 2.23.0 以降が利用可能な状態であること
- 上記コマンドを実行するために、該当の IAM ロールに AWS 管理ポリシー “AdministratorAccess” がアタッチされること
- 必要に応じて権限を絞ってください
AWS Inferentia の制約を考慮した スケールする Amazon ECS を設計する
AWS Neuron Tools
AWS Neuron は AWS Inferentia のための SDK です。Part 1 で作成した Model Server で AWS Inferentia の Neuron コア が適切に利用されていることを確認します。neuron-top というコマンドを実行します。以下の 図1 のような 結果が得られます。NeuronCore Utilization では NC 0 から NC 3 までの 4 つの Neuron コア が確認できます。 Loaded Models は Neuron コア にロードされたモデル情報を示しており、NC 0 にモデルがロードされていることがわかります。それでは、Model Server に curl コマンドで継続してリクエストを送った際に Top コマンドの出力がどのように変化するかを確認してみます。NC 0 の使用率が変化していることが確認できます。正常に AWS Inferentia を利用した推論ができていることが確認できました。
図1: neuron-top コマンド表示画面(リクエストなし)

#!/bin/sh
while true
do
curl -X 'POST' \
'http://localhost/inferences' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"text": "お爺さんは森に狩りへ出かける",
"mask_index": 7
}'
done図2: neuron-top コマンド表示画面(リクエストあり)

AWS Inferentia の制約
AWS Inferentia は深層学習の推論処理のコストパフォーマンスを大幅に向上させる可能性がありますが、AWS Inferentia 内の Neuron コアを複数のコンテナから利用することができないという制約があります。図3 では、既に Container 0 が モデルをロードして AWS Inferentia を利用可能な状態の時に、新しく Container 1 が起動してモデルをロードしようとしている状況を可視化しています。この状況では、Container 1 はモデルをロードすることができずに以下のような Neuron Core is in Use エラーとなります。この制約を頭に留めた上で Amazon ECS を利用します。デフォルトでは、Neuron ランタイムはプロセスに指定された空き Neuron コアを全て占有して利用します。明示的に利用する Neuron コア を指定する NEURON_RT_VISIBLE_CORES、必要なコア数を指定する NEURON_RT_NUM_CORES 環境変数を指定することができます。
以下に、AWS Inferentia の制約 について整理します。
- 同一プロセスにおいて、利用可能なメモリサイズ内であれば複数モデルをロード可能
- AWS Inferentia チップあたり 約 8GB の DRAM、または Neuron コアあたり 約 2GB の DRAM を搭載
- 複数モデルの合計サイズは、チップあたり 約 8GB もしくは コアあたり 約 2GB に制限される
- 複数コンテナで AWS Inferentia チップ を共有することは不可
- コンテナ内のプロセスごとに別の Neuron コアを明示的に割り当てることは可能
- 例:プロセス 0 に NC 0 と NC 1、プロセス 1 に NC 2 と NC 3 を割り当てる
- ただし、プロセス 間で 同じ Neuron コアを共有することは不可
- inf1.6xlarge 等の複数の AWS Inferentia チップを搭載したインスタンスの場合
- 1 コンテナに 1 AWS Inferential チップを割り当てることが可能
- つまり、インスタンス に対しては 最大 AWS Inferentia チップ数分のコンテナを配置可能
NEURON_RT_VISIBLE_CORESで AWS Inferentia チップ数 x 4 コアを明示的にプロセスに割り当て可能
図3: Neuron Core is in Use Error

Web Server と Model Server の通信
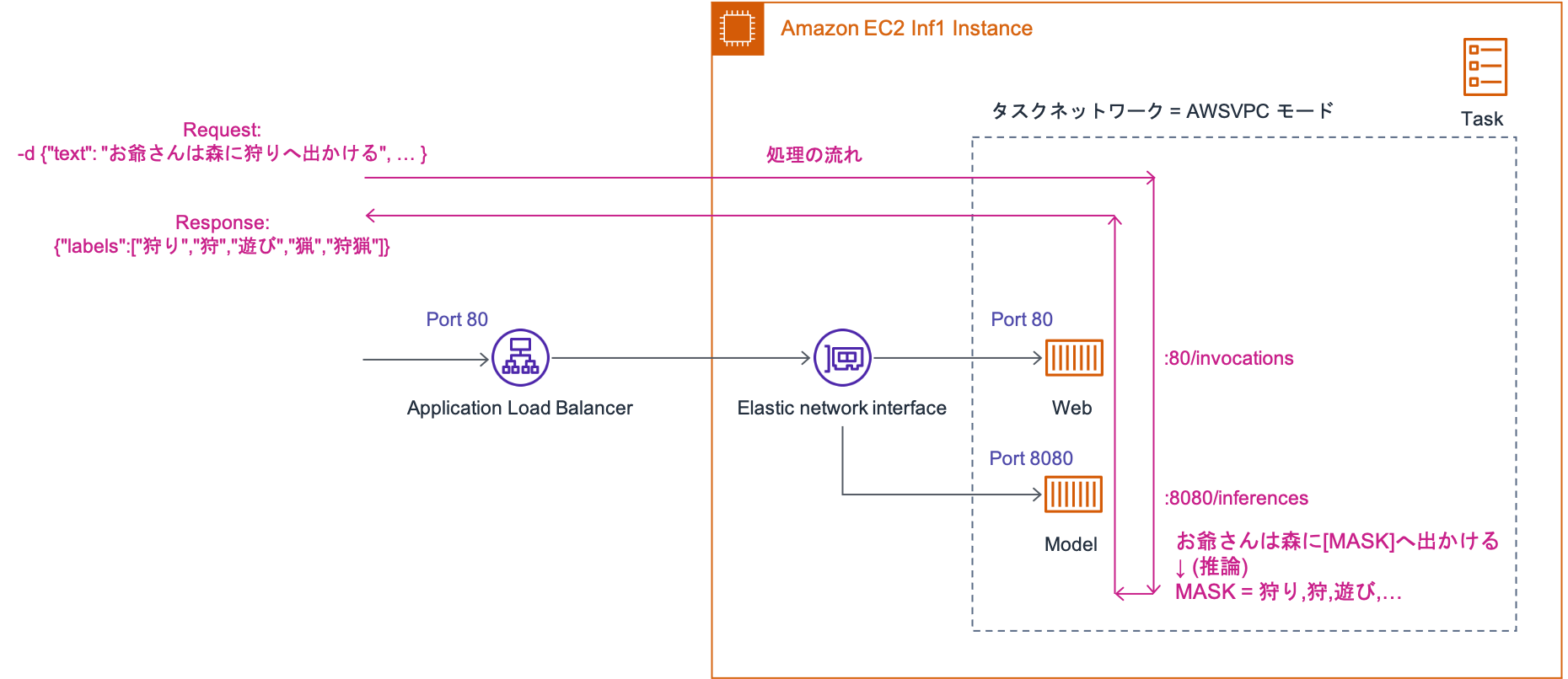
Part 1 では 検証環境である Amazon EC2 Inf1 インスタンス 上で、Docker の bridge ネットワークを用いて Web Server から Model Server にリクエストを出しました。Amazon ECS で Web Server から Model Server にリクエストを出すための方法は何パターンか存在します。① Model Server の前段に Application Load Balancer (以降、ALB)を挟む方法、② Amazon ECS サービスディスカバリ を利用する方法、そして、③ Amazon ECS タスクネットワーク において awsvpc ネットワークモードを利用して タスク内通信を localhost インターフェイス経由で行う方法、などがあります。今回は、実装の手数を減らすために ③ の方法を用いますが、本番環境での構成については要件に応じた最適な方法をご検討ください。本投稿の実装では Web Server と Model Server を同じ タスクに載せる方針で実装を進めますが、Model Server と Web Server を独立してそれぞれスケールさせることを考える場合にはタスクを分割することも選択肢になります。
図4 に示すように、ALB は Port 80 で Listen しており、リクエストは Amazon ECS タスク 内の Web Server に渡されます。Web Server では 環境変数として ENDPOINT_URL を設定することができ、Port 8080 で Listen している Model Server にリクエストを出すために、http://localhost:8080/inferencesを設定します。localhost インターフェイス経由で通信ができるのは awsvpc ネットワークモードを指定しているからです。
図4: Amazon ECS ネットワーキング設定 と 処理の流れ
Amazon ECS クラスター のデプロイとスケーリング
AWS Inferentia と Amazon ECS を用いた推論環境の初期構築負荷を低減させるためのサンプル実装を示すことが本記事の目的の一つであるため、固定台数インスタンスではなく、スケールする形でのサンプル実装を行ってみます。デプロイについては、AWS CodeDeploy を用いて Blue/Green デプロイ する方法などもありますが、今回は AWS CDK の cdk deploy コマンドでの手動デプロイを行いたいので、簡単のために Amazon ECS の ローリング更新 デプロイタイプを利用します。
Amazon ECS 設定概要
図5 に示すように、AWS CDK で新しく Amazon VPC を作成する際に、デフォルトクォータの上限 にかかってしまうことがあるため、Amazon ECS クラスター をデフォルト VPC 上で構築します。もちろん新しく Amazon VPC を作成して、その上で Amazon ECS クラスター を構築しても構いません。図6 では、Amazon ECS サービス (以降、ECS サービス)の設定情報を図示しており、Amazon ECS キャパシティープロバイダー (以降、キャパシティープロバイダー)を利用します。そして、今回の設定の重要なポイントとして、Amazon ECS タスク配置の制約事項 において、制約タイプとして distinctInstance を指定します。この制約を与えると、各タスクを別々のコンテナインスタンスに配置します。AWS Inferentia の制約 で説明した通り、AWS Inferentia の 1 チップをコンテナ間で共有することはできません。そのため今回利用する inf1.xlarge では 1 インスタンス あたりに 1 タスク という制約を守る必要があります。inf1.6xlarge 等の複数の AWS Inferentia チップを搭載しているインスタンスはこの限りではなく、1 インスタンスに最大で AWS Inferentia チップ数分のタスク、もしくはコンテナを配置可能です。この制約を守るため、今回の実装では上述した distinctInstance を利用しました。そして、タスク内に 複数の Model Server を起動することができないため、Amazon ECS のタスク定義 (以降、タスク定義)では 1 タスク あたりに 1 Model Server としています。
キャパシティープロバイダーの設定として、マネージドスケーリング を有効にしています。この設定を有効にすることで、タスクを適切に起動できるように Auto Scaling グループ は新しいインスタンスを起動・停止して スケールアウト・イン します。Amazon ECS のローリング更新デプロイタイプがサービスに適用されている場合、新たに変更されたアプリケーションのデプロイが開始されると、minimumHealthyPercent、maximumPercent の設定に従って ECS サービススケジューラは現在実行中のタスクを新しいタスクに置き換えようとします。その際に、タスク配置制約により配置できるインスタンスが存在せずにタスク起動できない PROVISIONING 状態のタスクを検知すると、キャパシティプロバイダーは追加のインスタンスを起動します。インスタンスが起動されると、 ECS サービススケジューラは現在実行中のタスクから新しいタスクへの置き換えを行います。AWS Inferentia を利用する際は、デプロイ時に一時的であっても 1 インスタンスあたり 2 タスク 配置されてはなりませんが、Amazon ECS のマネージドスケーリングは distinctInstance の制約を常に考慮してくれるため、 1 インスタンス あたり 1 タスクという配置が守られます。
AWS Inferentia を Amazon ECS で利用する際の タスク定義の設定についてはドキュメントをご参照ください。
図5: Amazon ECS クラスター の設定概要図

図6: Amazon ECS サービス の設定概要図

AWS CDK で実運用を想定した Amazon ECS を構築する
上記で説明した AWS Inferentia と Amazon ECS を利用した環境を AWS CDK を用いて構築します。
注意点
- Security Group の Inbound Port 80, 8080 がオープンされているためセキュリティ観点での必要性に応じてインバウンドルールのソース等の設定をご変更ください。
ap-northeast-1 の利用を前提として AMI ID を設定しているため、別リージョンを利用する場合には適切なAMI IDをご指定ください。DLAMI ID の検索方法はドキュメントをご参照ください。 - 記事の見やすさの都合上コードが途中で見切れているため、スクロールして最後まで貼り付けてください。
手順
ローカル PC 、AWS Cloud9、Part 1で作成した検証環境 などで事前準備が完了している状態であることをご確認ください。
mkdir ecs && cd ecs
cdk init sample-app --language typescriptcdk init を実行すると 環境一式が生成されます。 lib/ecs-stack.ts というファイルが生成されているので、エディタで以下のように修正を行います。
import { Stack, StackProps, Tag } from "aws-cdk-lib";
import * as ecs from "aws-cdk-lib/aws-ecs";
import * as cdk from "aws-cdk-lib";
import * as ec2 from "aws-cdk-lib/aws-ec2";
import * as ecr from "aws-cdk-lib/aws-ecr";
import * as autoscaling from "aws-cdk-lib/aws-autoscaling";
import * as elbv2 from "aws-cdk-lib/aws-elasticloadbalancingv2";
import { Construct } from "constructs";
export class EcsStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const region: string = process.env.CDK_DEFAULT_REGION || "ap-northeast-1";
const modelRepoName: string = "model";
const webRepoName: string = "web";
const healthCheckPath: string = "/";
// https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-inference.html
const imageID: string = "ami-07fd409cba79d3a25"; // for ap-northeast-1
const vpc = ec2.Vpc.fromLookup(this, "VPC", {
isDefault: true
});
const securityGroup = new ec2.SecurityGroup(this, "SecurityGroup", {
vpc,
description: "Allow (TCP port 8080 and HTTP (TCP port 80) in",
allowAllOutbound: true,
});
securityGroup.addIngressRule(
ec2.Peer.anyIpv4(),
ec2.Port.tcp(8080),
"Allow TCP 8080 Access"
);
securityGroup.addIngressRule(
ec2.Peer.anyIpv4(),
ec2.Port.tcp(80),
"Allow HTTP Access"
);
const cluster = new ecs.Cluster(this, "EcsCluster", {
vpc: vpc,
containerInsights: true,
});
const instanceType = ec2.InstanceType.of(
ec2.InstanceClass.INFERENCE1,
ec2.InstanceSize.XLARGE
);
const autoScalingGroup = new autoscaling.AutoScalingGroup(this, "ASG", {
vpc,
instanceType: instanceType,
machineImage: new ec2.GenericLinuxImage({
[`${region}`]: imageID,
}),
minCapacity: 1,
maxCapacity: 2,
});
const capacityProvider = new ecs.AsgCapacityProvider(this, "CapacityProvider", {
autoScalingGroup: autoScalingGroup,
capacityProviderName: "capacity-provider",
enableManagedScaling: true,
targetCapacityPercent: 100,
enableManagedTerminationProtection: false,
});
cluster.addAsgCapacityProvider(capacityProvider);
const modelLogging = new ecs.AwsLogDriver({ streamPrefix: "model-server" });
const webLogging = new ecs.AwsLogDriver({ streamPrefix: "web-server" });
const modelImage = ecs.ContainerImage.fromEcrRepository(
ecr.Repository.fromRepositoryName(this, "ModelImage", modelRepoName),
);
const webImage = ecs.ContainerImage.fromEcrRepository(
ecr.Repository.fromRepositoryName(this, "webImage", webRepoName),
);
const taskDefinition = new ecs.Ec2TaskDefinition(this, "TaskDef", {
networkMode: ecs.NetworkMode.AWS_VPC,
});
const linuxParameters = new ecs.LinuxParameters(this, 'LinuxParameters');
linuxParameters.addDevices({
containerPath: "/dev/neuron0",
hostPath: "/dev/neuron0",
permissions: [ecs.DevicePermission.READ, ecs.DevicePermission.WRITE],
});
linuxParameters.addCapabilities(ecs.Capability.IPC_LOCK);
const modelContainer = taskDefinition.addContainer("model", {
// https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_ecs.ContainerDefinitionOptions.html
image: modelImage,
memoryLimitMiB: 2048,
cpu: 0,
essential: true,
logging: modelLogging,
environment: {
ECS_IMAGE_PULL_BEHAVIOR: "default",
PORT: "8080",
VERSION: "1"
},
memoryReservationMiB: 1000,
linuxParameters: linuxParameters,
});
const webContainer = taskDefinition.addContainer("web", {
image: webImage,
memoryLimitMiB: 2048,
cpu: 0,
essential: true,
logging: webLogging,
environment: {
ECS_IMAGE_PULL_BEHAVIOR: "default",
ENDPOINT_URL: "http://localhost:8080/inferences",
VERSION: "1"
},
memoryReservationMiB: 1000,
});
webContainer.addPortMappings({
containerPort: 80,
hostPort: 80,
protocol: ecs.Protocol.TCP
});
modelContainer.addPortMappings({
containerPort: 8080,
hostPort: 8080,
protocol: ecs.Protocol.TCP
});
taskDefinition.defaultContainer = webContainer
const service = new ecs.Ec2Service(this, "Service", {
cluster: cluster,
taskDefinition: taskDefinition,
capacityProviderStrategies: [
{ capacityProvider: capacityProvider.capacityProviderName, weight: 1 }
],
maxHealthyPercent: 200,
minHealthyPercent: 100,
});
service.addPlacementConstraints(
ecs.PlacementConstraint.distinctInstances(),
)
const lb = new elbv2.ApplicationLoadBalancer(this, "LB", {
vpc,
internetFacing: true,
securityGroup: securityGroup,
});
const listener = lb.addListener("PublicListener", {port: 80, open: true});
listener.addTargets("ECS", {
port: 80,
targets: [service.loadBalancerTarget({
containerName: "web",
containerPort: 80,
})],
healthCheck: {
interval: cdk.Duration.seconds(60),
path: healthCheckPath,
timeout: cdk.Duration.seconds(5),
healthyThresholdCount: 2,
},
deregistrationDelay: cdk.Duration.seconds(5),
});
new cdk.CfnOutput(this, "LoadBalancerDNS", { value: lb.loadBalancerDnsName, });
}
}bin/ecs.ts というファイルを以下のように変更します。cdk 実行時の AWS アカウント とリージョンを指定します。
#!/usr/bin/env node
import * as cdk from 'aws-cdk-lib';
import { EcsStack } from '../lib/ecs-stack';
const app = new cdk.App();
new EcsStack(app, 'EcsStack', {
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION
},
});ファイルの修正が全て完了したので、npm run build コマンドでビルドを行います。prettier のエラーが出る場合は、prettier の設定 もしくは エラー内容を修正してください。build が成功していれば lib/ecs-stack.d.ts などのファイルが生成されています。そして、以下の環境変数を設定してから cdk deploy コマンドを実行します。
export CDK_DEFAULT_REGION="ap-northeast-1"
export CDK_DEFAULT_ACCOUNT="(ご自身のAWS アカウントID をご指定ください)"cdk deploy が完了すると以下のような出力が得られます。出力結果の EcsStack.LoadBalancerDNS が 作成した ALB の DNS です。
EcsStack.LoadBalancerDNS の 出力された値を指定し、以下のコマンドを実行すると 検証で見慣れた {"labels":["狩り","狩","遊び","猟","狩猟"]} という結果が得られます。結果が正しく表示されれば、Amazon ECS へのデプロイは完了です。結果が出ない、エラーするといった場合には、Amazon CloudWatch のアプリケーションログや、Amazon ECS の状態をご確認ください。
ローリング更新 が正常に行われることの確認を実施します。先ほど作成した lib/ecs-stack.ts の該当箇所を以下のように変更します。Model Server の タスク定義 の環境変数 VERSION を 1 から 2 に変更します。そして、再度 cdk deploy を実行してください。デプロイが正常に完了して再度上記の curl コマンドを実行すると、問題なく結果が取得できるはずです。これは、1 インスタンス あたりに 1 タスク の配置という制約を守りつつ ローリング更新 を行っているため、Neuron is in use Error が発生しないためです。試しに、ECS インスタンスを 1台にした状態で、タスク配置制約である distinctInstance 設定を削除して、VERSION を 2 から 3 に変更して cdk deploy を実施してみてください。適切なレスポンスが返ってきません。
...
const modelContainer = taskDefinition.addContainer("model", {
// https://docs.aws.amazon.com/cdk/api/v1/docs/@aws-cdk_aws-ecs.ContainerDefinitionOptions.html
image: modelImage,
memoryLimitMiB: 2048,
cpu: 0,
essential: true,
logging: modelLogging,
environment: {
ECS_IMAGE_PULL_BEHAVIOR: "default",
PORT: "8080",
- VERSION: "1"
+ VERSION: "2"
},
...まとめ
ブログの Part 1 では、AWS Inferentia の検証環境として Amazon EC2 Inf1 インスタンスを AWS CDK で構築し、構築したインスタンス上で モデルのコンパイル、推論 の動作を確認を行いました。Part 2 では、AWS Inferentia を Amazon ECS で利用するための制約や設定方法を解説し、AWS CDK を用いてアプリケーションを構築し、構築されたアプリケーションの動作を確認を行いました。本記事が少しでも AWS Inferentia を利用した推論環境の初期構築にかかるコストを下げるための一助になれば幸いです。
作業を終了される場合は、Part 1 / 2 で作成した環境全てを cdk destroy コマンドで削除してください。