Amazon Web Services ブログ
Tag: Machine Learning

フロンティアモデルの安全なリリースに向けた AWS の取り組み
Amazon Bedrock で Anthropic の Claude Fable 5 モデルが、悪用防止のためのさらに強力なガードレールを備えて再びご利用いただけるようになりました。本記事では、サイバー能力を持つフロンティアモデルを防御側に届けながら攻撃者による悪用を防ぐバランスの取り方、Project Glasswing を通じた Anthropic との連携、問題の重大度と対応の SLA など、フロンティアモデルを安全にお客様へ提供するための AWS の取り組みを紹介します。

もぐもぐ AWS – 現場の SA が語るお昼 30 分の技術トーク
昼休み30分でAWSの最新AI技術をキャッチアップ。現場のソリューションアーキテクトが配信。AIエージェント、Bedrock、セキュリティまで。参加無料。
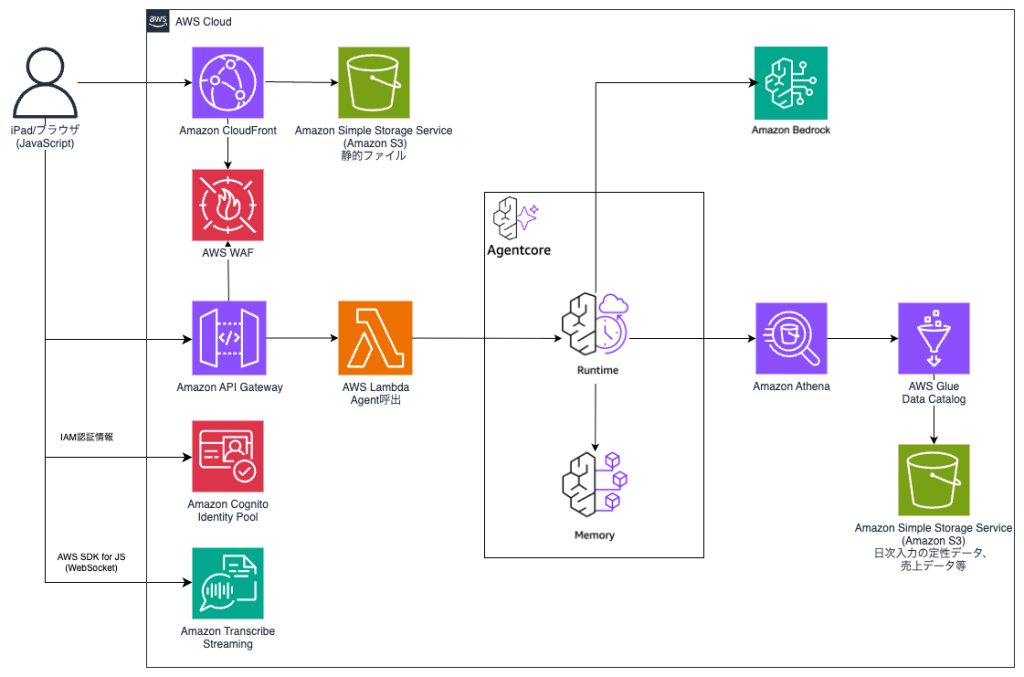
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

AI、技術的負債、そして AI を使いこなす力への道筋
エンタープライズが直面する3つの課題(技術資産の把握不足、AI導入の停滞、AIを実践的に使いこなす力の不足)に対し、AIを活用したドキュメントアーティファクトの自動生成を提案します。AWS Transform customでコードを分析し、リアルタイムに更新されるナレッジベースを構築することで、技術的負債の可視化とAIスキルの実践的習得を同時に実現できます。これをOKRとして組織に定着させるアプローチを推奨しています。

AI を活用した大規模なセキュリティ防御の構築 — 脅威が出現する前に
AWS が Anthropic と共同で取り組む Project Glasswing と Claude Mythos Preview の発表、自律型ペネトレーションテストを実現する AWS Security Agent の一般提供開始、Amazon Bedrock の自動推論によるハルシネーション防止など、AI を活用した大規模セキュリティ防御の最新の取り組みと、脅威が現実化する前に先手を打つ AWS のセキュリティ哲学を紹介します。

Amazon、Nova モデル強化に向けプライベート AI バグバウンティプログラムを開始
Amazon は、Amazon Nova 基盤モデルを含む AI モデルおよびアプリケーションを対象としたプライベート AI バグバウンティプログラムを開始しました。このプログラムでは、セキュリティ研究者やパートナー大学の専門家と連携し、プロンプトインジェクションやジェイルブレイク、CBRN 関連の脅威の検出など重要な領域でモデルをテストします。参加者は有効な脆弱性の報告に対して 200 ドル から 25,000 ドル の報奨金を獲得でき、次世代の AI セキュリティ研究者の育成も目指しています。
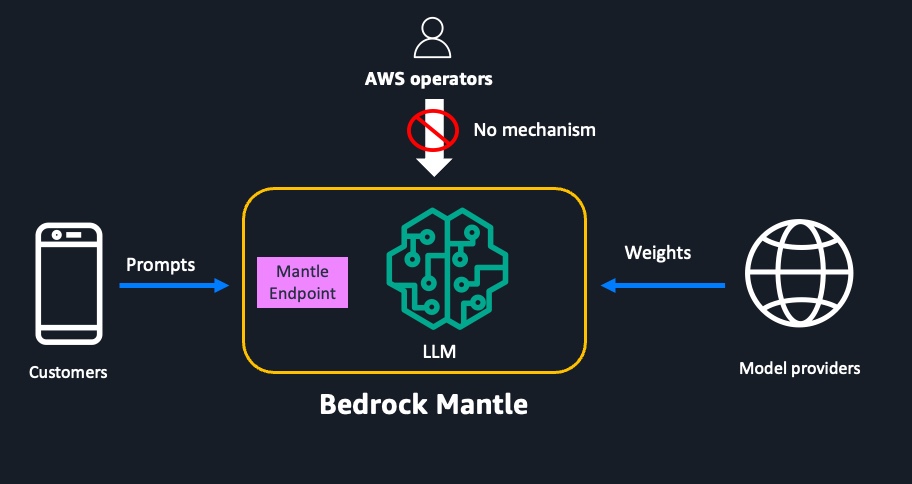
Amazon Bedrock の次世代推論エンジン Mantle におけるゼロオペレーターアクセス
AWS は生成 AI のセキュリティ基準をさらに引き上げました。お客様が機密データを扱う生成 AI アプリケーションを安心して構築できるよう、Amazon Bedrock の次世代推論エンジン Mantle では、オペレーターが顧客データにアクセスできない設計を一から構築しました。本ブログでは、AWS Nitro System で培った技術を活用し、生成 AI ワークロードに最高レベルのセキュリティを提供するゼロオペレーターアクセス設計の詳細をご紹介します。
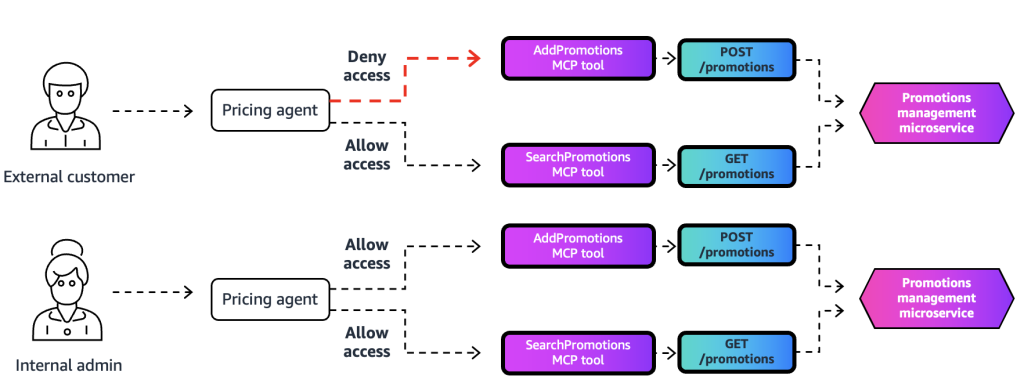
Amazon Bedrock AgentCore ゲートウェイインターセプター: きめ細かなアクセス制御の実現
企業が AI エージェントを採用してワークフローを自動化する中で、組織全体で数千のツールへの安全なアクセスを管理することが重要な課題となっています。数百のエージェントや自動化されたワークフローが、異なる部門にまたがる数千の Model Context Protocol (MCP) ツールにアクセスする統合 AI プラットフォームでは、各呼び出し元が許可されたツールのみにアクセス できるようにする必要があります。また、ユーザー ID やエージェントのコンテキストに基づいてツールへのアクセスを動的にフィルタリングし、マルチホップのワークフローを通じて機密データを保護しながら、パフォーマンスを維持することが求められます。これらの課題 に対応するため、Amazon Bedrock AgentCore Gateway はゲートウェイインターセプターという新機能を提供開始し、きめ細かなセキュリティ、動的なアクセス制御、柔軟なスキーマ管理を可能にします。

東京大学 松尾・岩澤研究室主催の AI エンジニアリング実践講座にて、1400 名を超える受講者に AWS 上でのクラウド開発を体験していただきました [ 後片づけ編 ]
本ブログシリーズでは、2025 年 4 月から 7 月にかけて実施した東京大学 松尾・岩澤研究室の AI エンジニアリング実践講座において、 AWS クラウドを活用した実践的な学習環境を用意し、1400 名を超える受講申し込み者に対して、個別のAWSアカウントを提供する大規模なオンライン講義を開講した取り組みを全 3 回に分けてまとめたものです。
3 回目は、環境の後片付けの実施方法とそこで得た知見について共有します。

東京大学 松尾・岩澤研究室主催の AI エンジニアリング実践講座にて、1400 名を超える受講者に AWS 上でのクラウド開発を体験していただきました [ 演習、運用編 ]
本ブログシリーズでは、2025 年 4 月から 7 月にかけて実施した東京大学 松尾・岩澤研究室の AI エンジニアリング実践講座において、 AWS クラウドを活用した実践的な学習環境を用意し、1400 名を超える受講申し込み者に対して、個別のAWSアカウントを提供する大規模なオンライン講義を開講した取り組みを全 3 回に分けてまとめたものです。
2 回目は、各受講生に割り当てる AWS アカウントに対する権限の適用と管理方法について詳しく説明します。