Amazon Web Services ブログ
新規 – Amazon Redshift の同時実行スケーリング – 常に最高のパフォーマンス
![]() Amazon Redshift は、エクサバイト規模まで拡張可能なデータウェアハウスです。現在、何万ものAWS 顧客 (NTTドコモ、Finra、Johnson & Johnson を含む) が Redshift を使用してミッションクリティカルな BI ダッシュボードを実行し、リアルタイムのストリーミングデータの分析や、予測分析ジョブを実行しています。
Amazon Redshift は、エクサバイト規模まで拡張可能なデータウェアハウスです。現在、何万ものAWS 顧客 (NTTドコモ、Finra、Johnson & Johnson を含む) が Redshift を使用してミッションクリティカルな BI ダッシュボードを実行し、リアルタイムのストリーミングデータの分析や、予測分析ジョブを実行しています。
こうした中、ピーク時に同時実行クエリの数が増えると、問題が発生します。多くのビジネスアナリストが BI ダッシュボードに目を向けるようになったり、長期間実行されるデータサイエンスのワークロードが他のワークロードとリソースを奪い合うようになると、Redshift はクラスター内で十分なコンピューティングリソースが利用可能になるまでクエリをキューに入れます。こうすることで、すべての作業は確実に完了しますが、ピーク時にパフォーマンスが影響を受ける可能性があります。次の 2 つの選択肢があります。
- ピーク時のニーズに合わせてクラスタをオーバープロビジョニングする。この選択肢は当面の問題は解決しますが、必要以上にリソースとコストを浪費します。
- 一般的なワークロードに合わせてクラスターを最適化する。この選択肢を採用すると、ピーク時に結果を待つ時間が長くなり、ビジネス上の重要な決定が遅れる可能性があります。
新しい同時実行スケーリング
今回、第 3 の選択肢を提示したいと考えています。必要に応じてクエリ処理能力を追加するように Redshift を設定することができます。これは透過的かつ数秒の短時間で発生し、ワークロードが何百もの同時クエリに増加しても高速で一貫したパフォーマンスを提供します。追加の処理能力は数秒で準備ができるので、事前のウォームアップまたはプロビジョニングは必要ありません。1 秒あたりの請求額で、使用した分だけお支払いいただき、メインクラスターの実行中は 24 時間ごとに 1 時間の同時実行スケーリングクラスターのクレジットが累積されます。余分な処理能力は、不要になった時点で取り除かれるので、前述したバースト性のあるユースケースに対処するのに最適な方法です。
特定のユーザーまたはキューにバーストパワーを割り当てることができ、既存の BI および ETL アプリケーションを引き続き使用することができます。同時実行スケーリングクラスターは、さまざまな形式の読み取り専用クエリを処理するために使用され、柔軟に動作できます。詳細については、同時実行スケーリングを参照してください。
同時実行スケーリングの使用
この機能は、既存のクラスターに対して数分で有効にできます。 テスト目的で新しい Redshift パラメーターグループから始めることをお勧めします。そこで、まず 1 つ作成することから始めます。
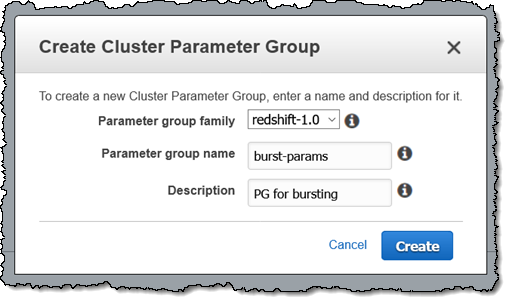
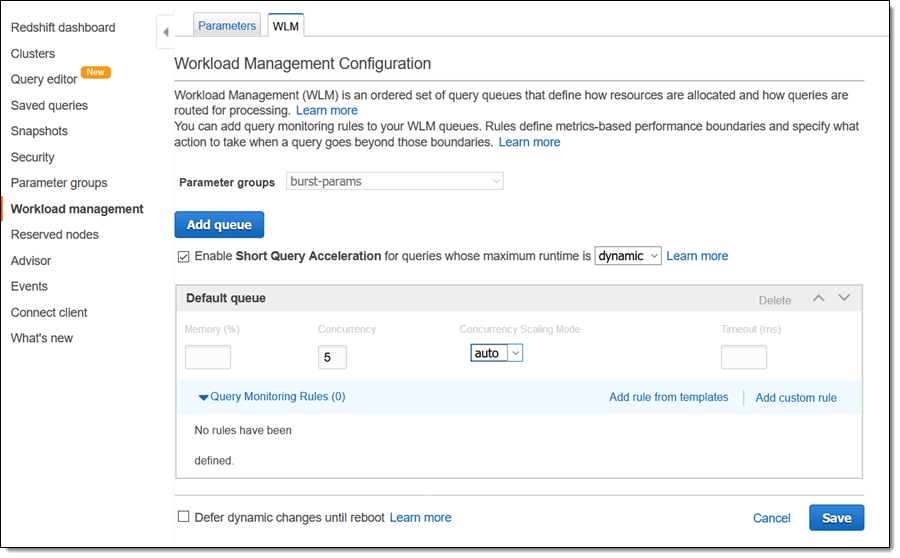
次に、クラスターの Workload Management Configuration を編集し、新しいパラメータグループを選択し、[Concurrency Scaling Mode] を [auto] に設定して、[Save] をクリックします。
 テストデータのソースとして、TPC-DS から派生したクラウドデータウェアハウスのベンチマークを使用し、クエリをテストします。DDL をダウンロードし、AWS 認証情報でカスタマイズし、psql を使用してクラスターに接続してテストデータを作成します。
テストデータのソースとして、TPC-DS から派生したクラウドデータウェアハウスのベンチマークを使用し、クエリをテストします。DDL をダウンロードし、AWS 認証情報でカスタマイズし、psql を使用してクラスターに接続してテストデータを作成します。
DDL はテーブルを作成し、S3 バケットに保存されたデータを使用してそれらのテーブルにロードします。
それから、クエリをダウンロードし、たくさんの PuTTY ウィンドウを開いて、Redshift クラスターに意味のある負荷をかけられるようにします。
最初の一連の並列クエリを実行してから時間をかけていくと、クラスターの [Cluster Performance] タブにそれらのクエリーが表示されます。
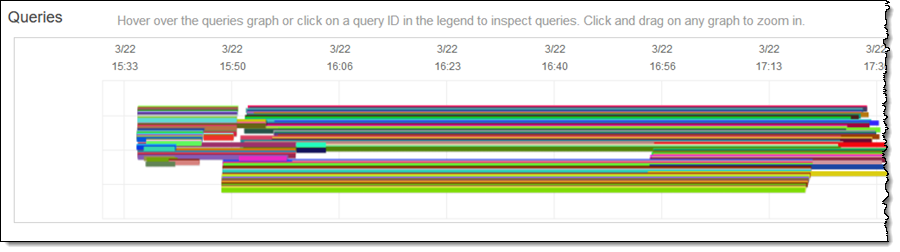
追加の処理能力が必要に応じてオンラインになり、不要になると [Database Performance] タブで消えます。
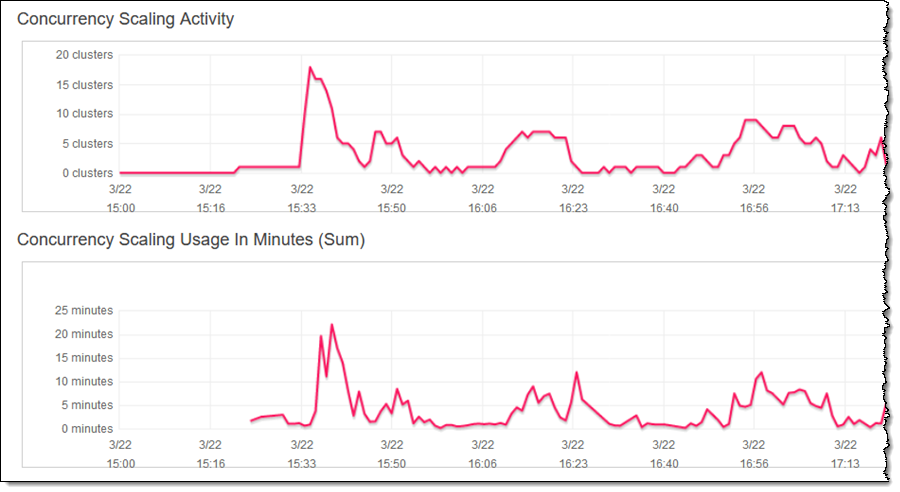
ご覧のとおり、このクラスターは、すべてのクエリをできるだけ迅速に処理するために必要に応じて拡張しています。同時実行スケーリングの使用量には、何秒の追加処理能力を消費したかが示されます (前述したように、各クラスターは 24 時間毎に 1 時間の同時実行クレジットを累積します)。
max_concurrency_scaling_clusters パラメーターを使用して、使用可能な同時実行スケーリングクラスターの数をコントロールすることができます (デフォルトの制限は 10 ですが、必要に応じて増加を要求できます)。
本日より、利用可能です
同時実行スケーリングクラスターは、本日から 米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド)、アジアパシフィック (東京) の各リージョンで利用可能です。今年後半には、さらに多くのリージョンで利用可能になる予定です。
— Jeff;