Amazon Web Services ブログ
統合ワークロードに向けた MySQL と互換性がある Amazon Aurora を計画・最適化する方法
MySQL と互換性がある Amazon Aurora はデータベースワークロード統合を検討中のお客様から好評をいただいています。Aurora MySQL は、ハイエンドな商用データベースの速さや信頼性と、オープンソースデータベースのシンプルさと高い費用対効果とを組み合わせたリレーショナルデータベースエンジンです。また Aurora MySQL は、標準の MySQL Community Edition に比べ最大 5 倍のスループットを実現します。
今回のブログ記事では、大規模な統合データベースワークロードのために行う Amazon Aurora の最適化に役立つガイダンスをいくつかお伝えします。また、「統合の費用はどれくらいかかりますか?」や「データセットはどのくらいの大きさにできますか?」など、よくある質問にお答えします。 上記の質問はシンプルですが、必ずしも回答がシンプルになるわけではありません。回答は、お使いのデータセットやワークロードのパターンによって大きく異なります。
データベース統合の定義
統合のユースケースに関しては、以下の要素に的を絞り、それからコンテキストに応じた Aurora MySQL の操作方法について詳細を説明します。
- テーブルのサイズ。統合により、一般的にテーブルは大きくなります。アドテック、IoT、消費者向けアプリケーション分野の場合、通常は大きな同種アプリケーションのデータベースをそれぞれにデータのサブセットが含まれる大量のシャードに分割します。Aurora ではシャーディングを完全になくすことはできないかもしれませんが、より少数のシャードに統合して操作上のオーバーヘッドを減らすことができます。
- テーブルの数。テーブル数の増加も、統合の結果見られることです。この結果は、各テナントが通常、独自のデータベースまたはテーブルセットを有する場合にテナントの分離が必要な SaaS アプリケーションで一般的なものです。このタイプの複数のテナントは数が少なくより大きな Aurora クラスターにまとめられ、テナントあたりの操作コストを削減します。
- データベースの使用率。さらに多数の同時接続を行うなど、統合データベースワークロードの使用率が多くのメトリクスで増加します。
実際には、同じプロジェクト内の複数の要素で使用率が増加することになります。以下のガイドラインは、各要素でワークロードを最適化するのに役立つはずです。
「大きい」とは具体的にどのくらいのサイズですか?
Amazon Aurora には最大容量に制限があります。私たちの最も重要な成果は、Aurora クラスターで 64 TB という最大の保存容量です。最大容量により、Aurora クラスターに物理的に保存できるデータ量の上限が決められます。また、個々のテーブルの大きさについて上限が決められます。
加えて、MySQL と互換性があるデータベースエンジンとして、Aurora MySQL は MySQL と InnoDB ストレージエンジンから多くの特徴を受け継いでいます。これらの特徴には効果的な統合に影響を与えるものがあります。
大きなテーブルサイズを最適化する方法
Amazon Aurora は 16 KiB のページを使用してデータを保存します。ページは、テーブルと関連インデックスのコンテナとしての役割を果たすテーブルスペースにグループ化されます。デフォルトで、Aurora は別のテーブルスペースを各テーブルに使用するか、テーブルがパーティション化されている場合は各テーブルのパーティションに使用します。このようなテーブルスペースのほとんどに、以下のデータ構造が含まれています。
- テーブルの主キーまたは一意キーで並べられたテーブルレコードを含むクラスター化インデックス。どちらのキーも利用できない場合は、単調に増加している内部の行 ID を使用してレコードを識別し並べます。
- テーブルのセカンダリインデックス。
- クラスター化インデックスレコードに適合しない外部に保存された可変長フィールドの値 (BLOB、TEXT、VARCHAR、VARBINARY など)。
上記のテーブルアーキテクチャが意味することは、所定のテーブルに保存できる決まった最大行数がないということです。最大行数は、以下のとおり多くの要因によって決まります。
- お使いの主キーまたは一意キーを選択することでサポートされる一意値の最大数。たとえば、(多くの場合に選択される) 主キー用に符号なし INT データ型を使用する場合、テーブルは 232 または 42 億 9 千万を少し上回る最大行数をサポートします。
- セカンダリインデックスの数とサイズ。
- クラスター化インデックスレコードまたは外部ページに直接保存される可変長データの量。
- データページをいかに効果的に活用したか。
いかに効果的にテーブルを統合できるかを決める要素としては、実際にはスキーマデザインとクエリパターンが行数よりも重要です。テーブルの行数が増えるにつれ、クラスター化インデックスとセカンダリインデックスのサイズも大きくなり、これらのインデックスをトラバースするためにかかる時間も増えます。そのため、クエリのパフォーマンスはテーブルのサイズとともに低下します。さらに詳しくパフォーマンス低下を軽減するためのベストプラクティスと方法をいくつか見てみましょう。
テーブルのスキーマを多数のレコードで設計する
ページあたりのレコードの密度は、クエリパターンとスキーマのコンテキストではテーブルサイズが大きいとさらに相関を示すようになります。可変長データを除いた Aurora MySQL の行の最大長は、8 KB を少し下回るサイズです (データページの半分)。データベースはページを管理して、パフォーマンスを犠牲にすることなくストレージの効率性を維持します。MySQL Community Edition の InnoDB のように、Aurora MySQL は将来的な書き込みに対応し、ページ分割数を減らすためにページの空白部分を残します。また、書き込みの割合が 50 パーセント以下に落ちると、ページを結合しようとします。ページは完全に書き込まれることはないため、常に一定量のストレージのオーバーヘッドがあります。
最適なスキーマデザインを実現することが、有用なオーバーヘッドをストレージの無駄にしないようにするための最善の方法です。そのような無駄は高いリソース使用率とレイテンシーを生み、ワークロードのパフォーマンスが許容範囲を下回るものになってしまいます。
効果的なスキーマデザインの実現に非常に重要となるガイドラインは以下の 2 点です。
- 所定テーブル行の情報はすべて等しく価値があるものです。つまり、行の全フィールドのデータに同じ頻度でクエリを行い、操作する必要があります。同じ行に使用頻度が異なるデータを保存すると効率が落ちます。
- 必ず所定の列に保存された値を表すことができる最小のデータ型を選択してください。個別の行レベルでの節減は小さなものに思われるかもしれませんが、何十億列に及ぶと効果は大きくなり、顕著なものとなります。
スキーマに可変長フィールドが含まれる場合、Aurora MySQL は可能な限り多くのクラスター化インデックスレコード内の可変長データに保存を試み、外部ページに残りのデータを保存します。大きなデータレコードによりデータのレコード密度が低くなり、クエリパフォーマンスの低下を引き起こします。しかし、可変長フィールドなど、クエリが全レコードデータ (読み込みと書き込み) に大きな影響を与える場合は、それでも大きなレコードが必要な場合があるかもしれません。必要がない場合は、そのような大きなフィールドを別のテーブルにオフロードすると便利なことがあります。さらに、全体をデータベース外部の Amazon S3 などのオブジェクトストアに保存できます。
インデックスはクエリのパフォーマンスを向上させるのに効果的です。しかし、これには追加費用が必要であり、追加のストレージとメモリフットプリントを消費し、書き込みのパフォーマンスを低下させます。セカンダリインデックスレコードは、行の物理的なストレージ座標を直接ポイントしません。代わりに、その行の主キー値をポイントします。その結果、どのセカンダリインデックスレコードにも基になる行の主キー値の複製が含まれます。
そのため、複合主キーも大きなインデックスレコードを生みだし、最終的にストレージと I/O の効率性を低下させます。必要なインデックスのみを使用し、複合インデックスにおいてインデックスの選択は結果を左右する重要なものであることにご注意ください。クエリパターンで次の選択ルールが可能な場合、インデックスをさらに少数の複合インデックスに置き換えることでインデックスの数を減らせる可能性があります。
最終的には、効果的なスキーマデザインを使用することで、許容範囲に満たないパフォーマンスになる前に行数を増やしたテーブルを保有できます。実際の最大行数は、データとデータのやり取りを行う方法によって決まります。
多数のレコードでテーブルのクエリを行う
パーティション (およびサブパーティション) は、大きなテーブルにおけるパフォーマンスの低下を軽減するツールです。各パーティションは別のテーブルスペースにデフォルトで保存されているため、パーティショニング表現が決定するとおりにクラスター化インデックス、セカンダリインデックス、特定のデータサブセット向けの外部ページがパーティションに含まれています。テーブルあたり最大 8,192 個のパーティションとサブパーティションを保有できます。しかし、パーティションの数が多いとパーティション自体にパフォーマンスの問題を引き起こします。このような問題には、メモリ使用率の増加やパーティションの数が多いクエリのパフォーマンスの問題などがあります。
パーティション内のインデックス構造が小さいほどトラバースが高速になります。クエリパターンが 1 つのパーティションやごく少数のパーティションに限定されている場合 (パーティション排除と呼ばれる最適化)、パフォーマンスにメリットが見られる可能性があります。しかし、パーティション化された列を含まない述語を持つクエリなど、少数の特定パーティションに限定されないクエリは低速化する可能性があります。この現象は、パーティションがあると 1 つの大きなインデックスではなく、複数の小さなインデックスをエンジンがトラバースする必要があるために起こります。そのため、パーティション化された大きなテーブルがパフォーマンスに与える影響は、パーティション排除やワークロードの選択をいかに効果的に利用できるかによって決まります。
大きなテーブルがあると、クエリオプティマイザーは正確な統計を持つことが重要です。正確な統計があることでクエリオプティマイザーは正しい基数を持つ最も限定的なインデックスを使用するため、クエリパフォーマンスが向上します。デフォルトで、Aurora MySQL は 20 のランダムインデックスページをサンプリングして統計と基数を評価します。ただし、巨大テーブルや列内に均一でない値が分散しているテーブルを取り扱う際には、この数は十分でない可能性があります。また、デフォルトで統計はディスクに残り、テーブルに大きな変更が加えられると自動的に再計算されます。行の 10 パーセント超に影響を与えるデータ操作言語 (DML) がその一例です。
巨大テーブルでこの規模の変更が加えられる頻度が少なくなると、統計は徐々に正確性を欠くようになる可能性があります。その結果、クリティカルポイントに到達してクエリオプティマイザーが実行プランを変更すると、影響を受けるクエリのパフォーマンスが時間をかけて低下し、突然低下することもあります。これが問題となる場合は、EXPLAIN ステートメントを使用してクエリ実行プランを見直し、想定する動作からの変更を特定します。
また、主要なワークロードのクエリに期待されるパフォーマンスの基準を定め、時間をかけてパフォーマンスをモニタリングすることをおすすめします。スロークエリログは、特定のしきい値を超えるクエリのログに有効ですが、時間をかけた緩やかな低下をキャプチャするにはそれほど有効ではありません。継続的にクエリのパフォーマンスをモニタリングするには、MySQL 5.6-互換性バージョンで MySQL パフォーマンススキーマを使用できます。ただし、これを有効にするとメモリ消費が増え、全体のシステムパフォーマンスが低下することもあります。
統計の正確性を向上するには以下の 2 つの方法があります。
- テーブルの経過時間と関連するインデックス統計を、情報スキーマ (
INNODB_TABLE_STATSとINNODB_INDEX_STATS) を使用してモニタリングし、その後ANALYZE TABLEを実行して適切に統計を更新する方法。 - お使いの DB インスタンスのDB パラメータグループをカスタマイズし、サンプリングされているページ数を増やして正確性を向上させる方法 (以下の表を参照)。ただし、サンプリングされたページを増やすと統計をコンピューティングするためにかかる時間も増えます。
| DB パラメータ | 値 | 説明 |
| innodb_stats_persistent_sample_pages | 256 | 統計がディスクに残る際にサンプリングされたページのグローバルパラメータ。このパラメータはテーブルごとに設定することもできます。 |
| innodb_stats_transient_sample_pages | 256 | 上記に類似しているものの、統計がディスクに残らない場合に使用されるグローバルパラメータ。 |
大きなテーブルのデータスキーマの頻繁な変更に対応する
どのくらいのテーブルの大きさであればデータ定義言語 (DDL) の操作が問題を生じませんか? サイズは 1 つの要因ですが、テーブルがどの程度アクティブであるかの方が重要な場合があります。テーブルが毎秒で何千もの書き込みを持続している場合、数百万レコード以下の比較的小さなテーブルでも DDL 操作を実行するのに問題となる可能性があります。
ワークロードやワークロードの更新が頻繁に行われる DDL 操作とスキーマの変更に依存している場合、このような操作が巨大テーブルを使用できる機能を制限する可能性があります。この動作は、MySQL Community Edition の操作方法に似ています。オフラインの DDL 操作はデータを正しいスキーマで新規テーブルスペースに複製します。そのため、十分な空き容量を確保する必要があります。また、操作範囲のテーブルをロックしますが、これを行うと通常のワークロードでは混乱をきたします。実行可能な場合はオンライン DDL 操作を行い、テーブルデータを直接変更します。ただし、この操作は一時スペースでテーブルへの新規書き込みをバッファ処理し、書き込みがマージされた場合のみテーブルをロックします。長時間実行やオンラインの DDL 操作が行われているテーブルに大量の書き込みを生成するワークロードにより、マージされる変更量は比較的大きなものとなります。このサイズではマージフェーズのロックにさらに時間がかかります。極端なケースでは、テーブル変更操作の完了前に一時スペースを使い果たすことがあり、オンライン DDL 操作の完了を大いに妨げます。
Aurora MySQL は Fast DDL もサポートしており、null 値になりうる列を瞬間的な操作に近いものとしてテーブルの最後に加えることができます。この機能は、前述の DDL に関するデメリットの一部を軽減するのに役立ちます。通常の DDL または Fast DDL 操作では効率的に処理できない DDL 操作については、Percona Online Schema Change Tool を使用して操作を実行することを検討してもよいでしょう。このツールをお客様のユースケースに利用する場合、混乱を抑えて DDL 操作を実行できますが、巨大テーブルでは操作時間が長くなります。
多数のテーブルを最適化する方法
統合されたワークロードにより、多数のテーブルが Aurora クラスターに保存される可能性もあります。実際には、合理的に 1 つの Aurora クラスターに統合できるテーブル数はワークロードとアクセスパターンによって決まります。
ファイルシステムの特徴がデータベースのスケーラビリティ (サイズ、テーブル数) を制限する MySQL Community Edition とは異なり、 Aurora MySQL は特定用途向けに作られた分散型のログ構造ストレージサービスを使用します。そのため、MySQL でカスタムテーブルスペースの設定を使用する理由の多くは、Aurora に適用されないファイルシステムに固有の制限を軽減することにあります。多数のテーブルを持つことによるファイルシステムに関する影響は操作面、エラー回復面のいずれにもありません。Aurora カスタム DB クラスターパラメータグループを使用して inndb_file_per_table オプションをオフにできますが、おすすめしません。このオプションはパフォーマンスや回復時間に影響を与えなくなっているからです。
ただし、Aurora のテーブル数が多い場合はメモリ使用率に影響を与えます。デフォルトのパラメータを持つ Aurora クラスターのメモリ消費は次のとおりです。
| 使用される DB インスタンスメモリ | コンシューマー |
| 3/4 | 最近アクセスされたデータページを保存するバッファプール (ページキャッシュ)。この設定は DB パラメータグループで変更できます。ただし、バッファプールのサイズ縮小は通常望ましいことではありません。バッファプールの効果を追跡するための関連する Amazon CloudWatch メトリクスは、バッファプールキャッシュのヒット率とストレージへの IOPS 読み込みです。 |
| 1/24 | クエリキャッシュ。MySQL Community Edition はバージョン 5.7.20 でクエリキャッシュが非推奨となり使用できなくなりましたが、Aurora には再生したクエリキャッシュがあります。このクエリキャッシュが Community Edition での実装の制限を受けることはありません。クエリがキャッシュ可能でなくても問題がなく、他のバッファやキャッシュで使用メモリを回収する場合を除き、クエリキャッシュを有効にしておくことをおすすめします。 |
| 残り | 残りの利用可能なメモリ (約 20.8 パーセント) はさまざまなその他の予測が難しいコンシューマーが使用します。たとえば、グローバルまたは接続やセッション、OS やマネージドサービスプロセスに特有のデータベースエンジンバッファやキャッシュなどです。このメモリの一部に空きがあるか空きにできる可能性があります。 |
多数のテーブルを使用する際にテーブルに関係するキャッシュを最適化する
2 つのキャッシュが、多数のテーブルを有するワークロードと特に関連があります。このキャッシュの設定を誤ると、パフォーマンスや安定性の問題を引き起こす可能性があります。
テーブルキャッシュ (またはテーブルオープンキャッシュ) は開かれたテーブルのハンドラーの構造体をユーザーアクティビティの結果として保存します。各セッションでテーブルは個別に開かれるため、複数の同時セッションがアクセスしている場合、キャッシュには同じテーブルの複数アイテムが含まれることがあります。Aurora では、このキャッシュのデフォルトのサイズを r4 クラスの DB インスタンスのために最大 6,000 個のオープンテーブルに増やしました。ただし、これはソフトリミットです。このキャッシュは、SQL ステートメントに関係するテーブル数 (およびテーブル内のパーティション数) に基づき、かなりのメモリコンシューマーとなる可能性があります。この現象はワークロードがデータベースで実行している同時セッションの数により増幅されます。
テーブル定義キャッシュは、メモリ内でよくアクセスされるテーブルのためにテーブル (スキーマ、メタデータ) の定義を保存します。アクティブなテーブルを持つほど、テーブルの定義がキャッシュされやすくなります。Aurora では、保存するキャッシュのデフォルトのサイズを r4 クラスの DB インスタンスのために最大 20,000 個の定義に増やしました。そのため、このキャッシュはかなりのメモリコンシューマーとなる可能性があります。何十万ものテーブルを使用するワークロードにより、大半のテーブルがアクティブの場合はデフォルトの値を超えてこのキャッシュのサイズを増やす誘因もあります。このキャッシュサイズもソフトリミットです。MySQL データベースエンジンが親子の外部キー関連テーブルのテーブル定義を削除することはありません。そのため、キャッシュの合計サイズはキャッシュサイズ制限を上回ることがあります。
よって、効率的なメモリ使用により、実質的に所定サイズのインスタンスを使用して Aurora クラスターで操作できるテーブル数を制限することができます。キャッシュのフットプリントを軽減するには、さらに大きな DB インスタンスクラスを使用してキャッシュを受け入れる必要がある可能性があります。あるいは、クエリキャッシュまたはバッファプールに割り当てられたメモリ量を減らして相殺する必要がある可能性があります。すると今度は、メモリ量を減らしたことでワークロードのパフォーマンスに別の面で影響を与える可能性があります。メモリに入れる動作中のデータセット量が少ないからです。しかし、「多すぎる」テーブル数を正確に特定するのは困難です。 以下の例では、このような現象の一部をよく表しています。
以下の図は、40 の同時接続のみを使用した、1,000 テーブルを有するデータベースでの sysbench の読み込みと書き込み OLTP テストの強化されたモニタリングメトリクスで報告された空きメモリを示しています。このワークロードは人気のインスタンスクラスである、61 GB メモリの Aurora MySQL 5.6 互換性 db.r4.2xlarge DB インスタンスを 10 分間のみ実行しました。
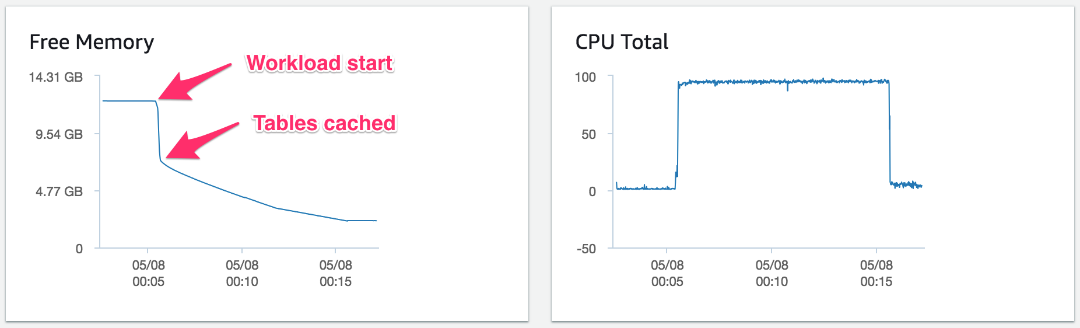
このテストに関し、次のコマンドがデータベースとテーブルをテスト実行前に作成します。
テスト開始時に、システムの空きメモリが突然 12.2 GB 超から 5 GB 減っています。また、CPU リソースはテスト中にほぼすべて消費されました。MySQL Community Edition とは異なり、Aurora はバッファプールを事前に割り当て、上記のテストではすでにウォームアップされていました。私たちは、比較的少数のアクティブテーブル (1,000) と同時接続 (40) のテストを行いました。メモリ消費は、テーブルキャッシュと多数のアクティブテーブルが関わる際に起こる各接続の増幅効果によるものがほとんどでした。
DB インスタンスのパラメータグループ内の table_open_cache パラメータがテーブルキャッシュのサイズを制御します。デフォルトで、このパラメータは以下の式を使用して設定されます。
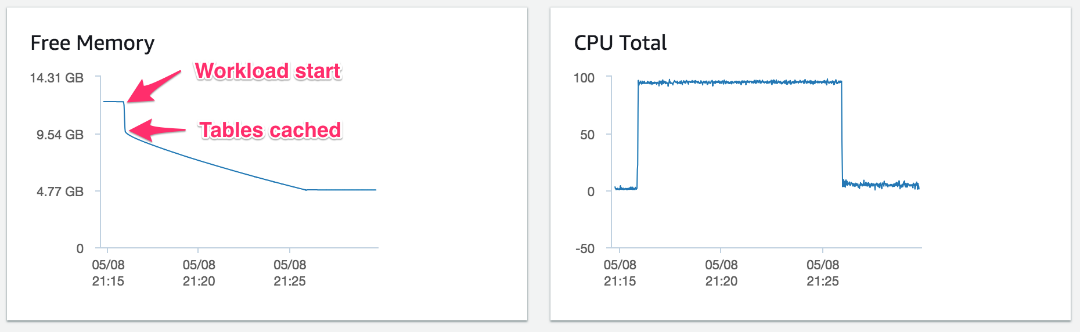
比較のため、以下の図で類似のテストを示しています。唯一異なるのは、このテストでは 500 テーブルにのみアクセスしているという点です。ここで、テストが始まるとシステムの空きメモリも突然 12.2 GB 超から約 2.5 GB 減っています。
以下の例では、多数のテーブルが使用される際のテーブル定義キャッシュの影響を示しています。このテストのワークロード例では 10 万の簡易なテーブルを作成します。各テーブルには自動で増加する整数の主キー、タイムスタンプ列、浮動小数点列、2 つの短い文字列があります。テストでは単独の接続を使用し、15.25 GB メモリの Aurora MySQL 5.7 互換性 db.r4.large DB インスタンスで実行して各簡易テーブルに 1 行挿入します。Aurora クラスターで実行するアクティビティは他になく、空のクラスターで開始されます。
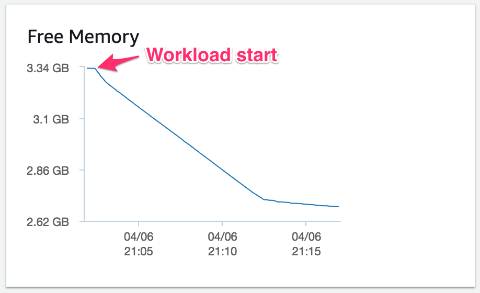
ワークロードが増えるにつれ、どのくらい空きメモリが減るかを確認できます。空きメモリは、さらに最大 700 MB のメモリを全体で消費して (ほとんどがテーブル定義キャッシュによるもの) 、キャッシュ制限に達すると安定します。
DB インスタンスのパラメータグループ内の table_definition_cache パラメータがテーブル定義キャッシュのサイズを制御します。デフォルトで、このパラメータは以下の式を使用して設定されます。
結論として、実際に統合できるテーブル数は複数の要因によって決まります。アクティブに使用されているテーブル数、利用可能なメモリ量、サポートが必要な同時接続数がその要因です。
増加したデータベースリソース使用率を最適化する方法
このブログ記事のはじめに、大きなテーブルまたはテーブル数の多さが CPU やメモリのようなサーバーリソース使用率に影響を与える点についていくつか説明しました。しかし、ワークロードの統合自体が使用率の増加を引き起こします。データベースのシャード数が減ると、残りのデータベースシャードのそれぞれにさらに多くの同時接続が確立される可能性があります。各統合データベースは、クエリボリュームの増加の読み込みや書き込みを行い作業量が増えます。
Amazon Aurora for MySQL は内部サーバー接続プール機能やスレッドの多重送信機能を備えており、何千もの同時接続を処理する際に競合を減らし、スケーラビリティを向上させるのに役立ちます。各 Aurora DB インスタンスには最大 16,000 の同時接続を設定することができます。ただし、ワークロードと DB インスタンスクラス の選択により、実質的な最大数をそれよりも少ない数に制限する可能性があります。
それぞれの接続、セッション、スレッドはさまざまなバッファ、キャッシュ、現在実行している特定の SQL ステートメントに基づいたその他のメモリ構造でさまざまなメモリ量を消費します。この消費は確定的なものではなく、このブログ記事のはじめに説明した他の構造のように、同量の利用可能なメモリを得るために競合します。効果的な接続管理とスケーリングのベストプラクティスを理解するにあたり、ホワイトペーパー the Amazon Aurora MySQL DBA Handbook for Connection Management は優れたリソースです。さらに大きく、高いスループットのワークロードを実現するための接続使用率の最適化について有効なアドバイスが記載されています。
まとめ
複数のデータベースワークロードを統合するソリューションとして MySQL と互換性がある Amazon Aurora を検討する際は、多くの要素が関連します。すべてを網羅するリストはありませんが、統合を実装するお手伝いをする際に確認する一般的な検討事項を上記のトピックに記載しています。それぞれのワークロードは異なるため、実際の統合を行う際の制限はケースにより異なります。
ベストプラクティスとして、デフォルトからの設定変更を生産スケールで徹底的にテストし、パフォーマンスと信頼性において定量可能なプラスの影響が確認できる場合のみ実装する必要があります。このベストプラクティスは、MySQL Community Edition から設定を引き継ぐ際に特に有効です。Aurora では同じ動作をしない可能性があるためです。ワークロード統合プロジェクトの実行方法について詳細は、AWS データベースブログの記事 Reduce Resource Consumption by Consolidating Your Sharded System into Aurora をご覧ください。
著者について
 Vlad Vlasceanu はアマゾン ウェブ サービスのスペシャリストソリューションアーキテクトです。 AWS の顧客と協力してデータベースプロジェクトに関する助言や技術支援を行い、AWS を使用する場面でソリューションの価値を向上させる手助けをしています。
Vlad Vlasceanu はアマゾン ウェブ サービスのスペシャリストソリューションアーキテクトです。 AWS の顧客と協力してデータベースプロジェクトに関する助言や技術支援を行い、AWS を使用する場面でソリューションの価値を向上させる手助けをしています。